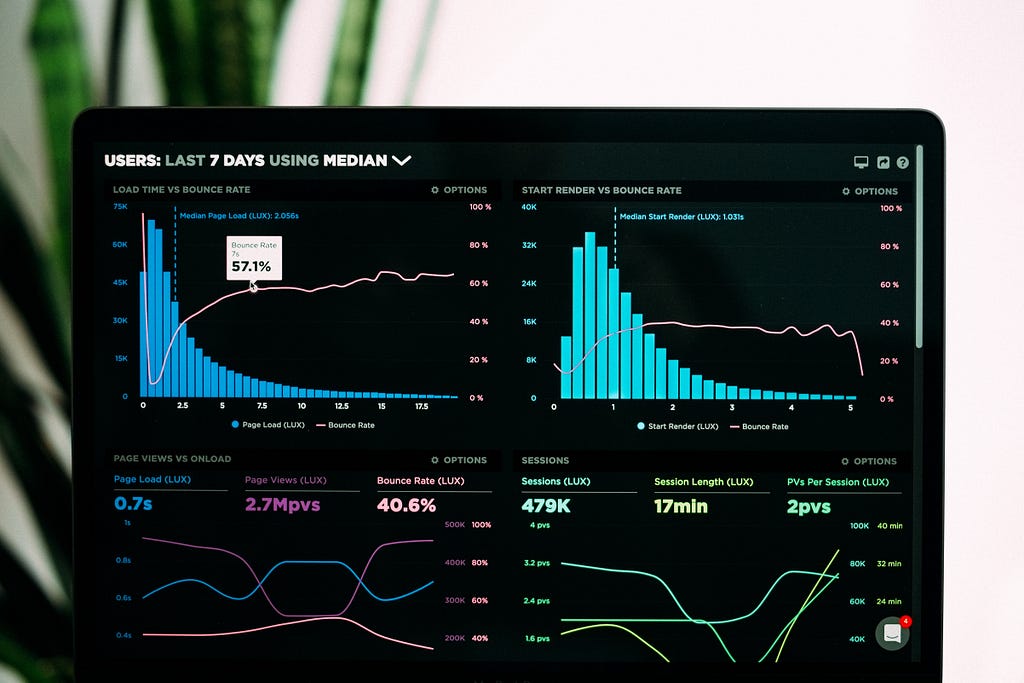
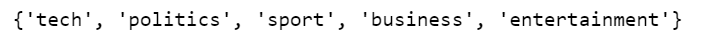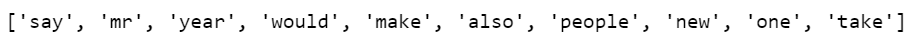Conversion of categorical features into a numerical format.
In real world NLP problems, the data needs to be prepared in specific ways before we can apply a model. This is when we use encoding. For NLP, most of the time the data consist of a corpus of words. This is categorical data.
Understanding Categorical Data:
Categorical data are variables that contain label values. This data is mostly in the form of words. These are words that form the vocabulary. The words from this vocabulary need to be turned into vectors to apply modelling.
Some examples include:
A “country” variable with the values: “USA”, “Canada“, “India”, “Mexico” and “China”.
A “city” variable with the values: “San Francisco“, “Toronto” and “Mumbai“.
The categorical data above needs to be converted into vectors using a vectorization technique. This is One-hot encoding.
Vectorization is an important aspect of feature extraction in NLP. These techniques try to map every possible word to a specific integer. scikit-learn has DictVectorizer to convert text to a one-hot encoding form. The other API is the CountVectorizer, which converts the collection of text documents to a matrix of token counts. We could also use word2vec to convert text data to the vector form.
One-hot Encoding:
Consider that you have a vocabulary of size N. In the one-hot encoding technique, we map the words to the vectors of length n, where the nth digit is an indicator of the presence of the particular word. If you are converting words to the one-hot encoding format, then you will see vectors such as 0000…100, 0000…010, 0000…001, and so on. Every word in the vocabulary is represented by one of the combinations of a binary vector. The nth bit of each vector indicates the presence of the nth word in the vocabulary.
Using this technique normal sentences can be represented as vectors. This vector is made based on the vocabulary size and the encoding schema. Numerical operations can be performed on this vector form.
Applications of One-hot encoding:
The word2vec algorithm accepts input data in the form of vectors that are generated using one-hot encoding.
Neural networks can tell us if an input image is of a cat or a dog. Since the neural network only uses numbers, it can’t output the words “cat” or “dog”. Instead, it uses one-hot encoding to represent is prediction in a semantic manner.
Thanks for reading! 😊 If you enjoyed it, test how many times can you hit 👏 in 5 seconds. It’s great cardio for your fingers AND will help other people see the story.
Why do we need one-hot encoding? was originally published in Acing AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
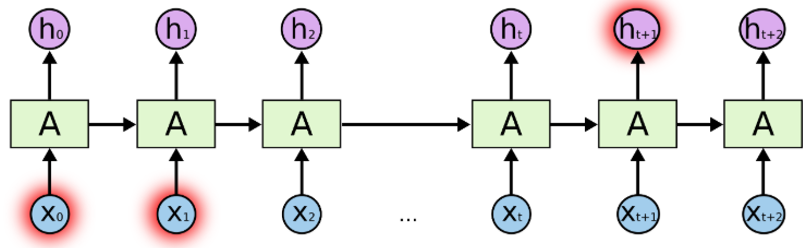
This works well for short sentences, when we deal with a long article, there will be a long term dependency problem.
Therefore, we generally do not use vanilla RNNs, and we use Long Short Term Memory instead. LSTM is a type of RNNs that can solve this long term dependency problem.
In our document classification for news article example, we have this many-to- one relationship. The input are sequences of words, output is one single class or label.
Now we are going to solve a BBC news document classification problem with LSTM using TensorFlow 2.0 & Keras. The data set can be found here.
First, we import the libraries and make sure our TensorFlow is the right version.
There are 2,225 news articles in the data, we split them into training set and validation set, according to the parameter we set earlier, 80% for training, 20% for validation.
Tokenizer does all the heavy lifting for us. In our articles that it was tokenizing, it will take 5,000 most common words. oov_token is to put a special value in when an unseen word is encountered. This means we want <OOV> to be used for words that are not in the word_index. fit_on_text will go through all the text and create dictionary like this:
We can see that “<OOV>” is the most common token in our corpus, followed by “said”, followed by “mr” and so on.
After tokenization, the next step is to turn those tokens into lists of sequence. The following is the 11th article in the training data that has been turned into sequences.
When we train neural networks for NLP, we need sequences to be in the same size, that’s why we use padding. If you look up, our max_length is 200, so we use pad_sequences to make all of our articles the same length which is 200. As a result, you will see that the 1st article was 426 in length, it becomes 200, the 2nd article was 192 in length, it becomes 200, and so on.
In addition, there is padding_type and truncating_type, there are all post, means for example, for the 11th article, it was 186 in length, we padded to 200, and we padded at the end, that is adding 14 zeros.
print(train_padded[10])
Figure 2
And for the 1st article, it was 426 in length, we truncated to 200, and we truncated at the end as well.
Now we are going to look at the labels. Because our labels are text, so we will tokenize them, when training, labels are expected to be numpy arrays. So we will turn list of labels into numpy arrays like so:
Before training deep neural network, we should explore what our original article and article after padding look like. Running the following code, we explore the 11th article, we can see that some words become “<OOV>”, because they did not make to the top 5,000.
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_article(text): return ' '.join([reverse_word_index.get(i, '?') for i in text]) print(decode_article(train_padded[10])) print('---') print(train_articles[10])
Figure 3
Now its the time to implement LSTM.
We build a tf.keras.Sequential model and start with an embedding layer. An embedding layer stores one vector per word. When called, it converts the sequences of word indices into sequences of vectors. After training, words with similar meanings often have the similar vectors.
The Bidirectional wrapper is used with a LSTM layer, this propagates the input forwards and backwards through the LSTM layer and then concatenates the outputs. This helps LSTM to learn long term dependencies. We then fit it to a dense neural network to do classification.
We use relu in place of tahn function since they are very good alternatives of each other.
We add a Dense layer with 6 units and softmax activation. When we have multiple outputs, softmax converts outputs layers into a probability distribution.
In our model summary, we have our embeddings, our Bidirectional contains LSTM, followed by two dense layers. The output from Bidirectional is 128, because it doubled what we put in LSTM. We can also stack LSTM layer but I found the results worse.
print(set(labels))
We have 5 labels in total, but because we did not one-hot encode labels, we have to use sparse_categorical_crossentropy as loss function, it seems to think 0 is a possible label as well, while the tokenizer object which tokenizes starting with integer 1, instead of integer 0. As a result, the last Dense layer needs outputs for labels 0, 1, 2, 3, 4, 5 although 0 has never been used.
If you want the last Dense layer to be 5, you will need to subtract 1 from the training and validation labels. I decided to leave it as it is.
I decided to train 10 epochs, and it is plenty of epochs as you will see.
This post aims to explain the concept of Word2vec and the mathematics behind the concept in an intuitive way while implementing Word2vec embedding using Gensim in Python.
The basic idea of Word2vec is that instead of representing words as one-hot encoding (countvectorizer / tfidfvectorizer) in high dimensional space, we represent words in dense low dimensional space in a way that similar words get similar word vectors, so they are mapped to nearby points.
Word2vec is not deep neural network, it turns text into a numeric form that deep neural network can process as input.
How the word2vec model is trained
Move through the training corpus with a sliding window: Each word is a prediction problem.
The objective is to predict the current word using the neighboring words (or vice versa).
The outcome of the prediction determines whether we adjust the current word vector. Gradually, vectors converge to (hopefully) optimal values.
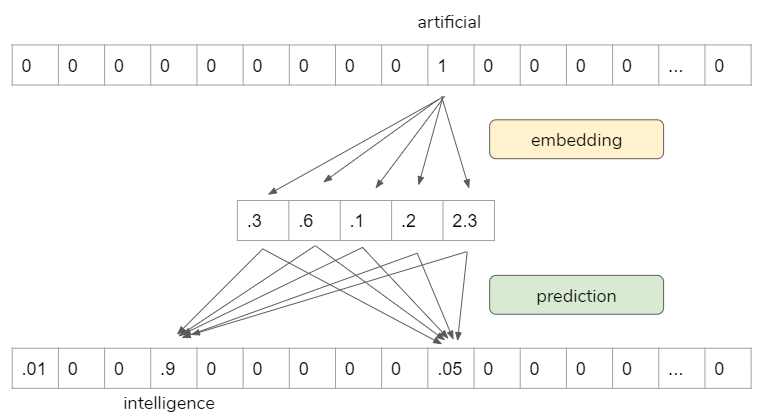
For example, we can use “artificial” to predict “intelligence”.
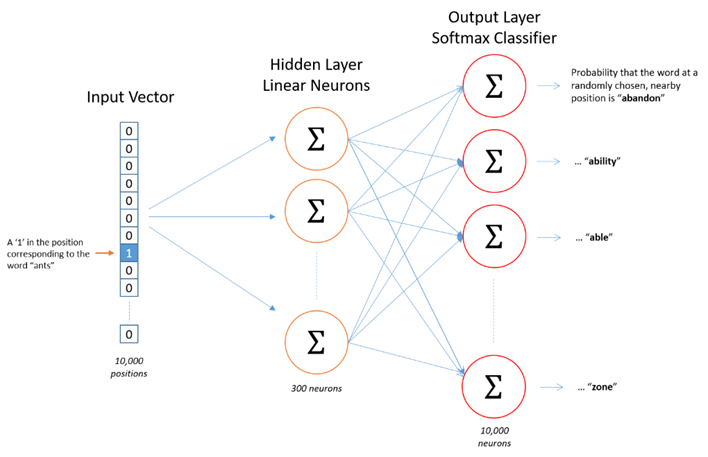
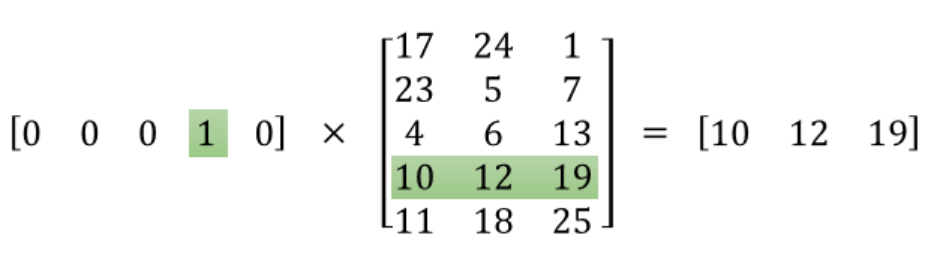
The following is the math behind word2vec embedding. The input layer is the one-hot encoded vectors, so it gets “1” in that word index, “0” everywhere else. When we multiply this input vector by weight matrix, we are actually pulling out one row that is corresponding to that word index. The objective here is to pull out the important row(s), then, we toss the rest.
When we use Tensorflow / Keras or Pytorch to do this, they have a special layer for this process called “Embedding layer”. So, we are not going to do math by ourselves, we only need to pass one-hot encoded vectors, the “Embedding layer” does all the dirty works.
Pre-process the text
Now we are going to implement word2vec embedding for a BBC news data set.
min_count: Minimum number of occurrences of a word in the corpus to be included in the model. The higher the number, the less words we have in our corpus.
window: The maximum distance between the current and predicted word within a sentence.
size: The dimensionality of the feature vectors.
workers: I know my system is having 4 cores.
model.build_vocab: Prepare the model vocabulary.
model.train: Train word vectors.
model.init_sims(): When we do not plan to train the model any further, we use this line of code to make the model more memory-efficient.
Please note, the above results could change if we change min_count. For example, if we set min_count=100, we will have more words to work with, some of them may be more similar to the target words than the above results; If we set min_count=300, some of the above results may disappear.
We Use t-SNE to represent high-dimensional data in a lower-dimensional space.
It is obvious that some words are close to each other, such as “team”, “goal”, “injury”, “olympic” and so on. And those words tend to be used in the sport related news articles.
Other words that cluster together such as “film”, “actor”, “award”, “prize” and so on, they are likely to be used in the news articles that talk about entertainment.
Again. How the plot looks like pretty much depends on how we set min_count.
Johannes Giorgis is a Senior Data Engineer at Loop Insights. His story is fascinating how he has gone from a big company to a fast paced data based startup. I met Johnny while we took the deep learning Nanodegree at Udacity together. We have stayed in touch ever since. Over the last few years of knowing about Johnny I have realized that “still water runs deep” is an apt proverb for him. He shares his learning via his blog. Going through the interview with him, he details how it is an important for folks to understand to know where their ML models fit in the larger scheme of a software system.
Vimarsh Karbhari(VK): What top three books about AI/ML/DS have you liked the most? What books have had the most impact in your career?
Johannes Giorgis(JG):
Artificial Intelligence: A Modern Approach was an eye opener to the field of Artificial Intelligence. I read through that book back when I was first enrolled in Udacity’s Artificial Intelligence Nanodegree.
Next on my list is Data Science from Scratch — I’m excited about this book as it focuses on the base algorithms that power a lot of data science today. Re-writing these algorithms and applying them in the context of being a new data scientist at a company gives us that one level deeper perspective that we lose when we rely on higher level libraries’ functions.
VK:What tool/tools (software/hardware/habit) that you have as a Data Scientist has the most impact on your work?
JG: Pandas! I’m always excited to utilize my Pandas skills to clean, format and explore datasets. Recently, I’ve taken up learning Docker for web related tasks at work. I’m hoping to incorporate it into my data science workflow/toolkit to help me create a reproducible data science development workspace. Being able to quickly share the environment under which you built a model is a huge advantage.
VK:Can you share about the Data Science related failures/projects/experiments that you have learned from the most?
JG: I and my friend got together to explore the respective tech meetups in our cities — Vancouver and San Francisco. We initially explored the Meetup API to see what it allowed us to do. From there, we built some helper functions to get data for multiple groups, transform it into Pandas Dataframes so we could move forward with cleaning and exploring the data. Jumping straight into a problem, looking up enough documentation, tutorials to move you forward one inch at a time was an invaluable lesson. I often find myself stuck in tutorial hell, where I’m unable to apply what I’ve just learnt to anything that will help me retain it.
By focusing on a project or problem that I’m interested in exploring or solving, I avoid getting stuck with tutorials. — Johnny
VK:If you were to write a book what would be the title of the book? What would be the main topics you would cover in the book?
JG: I am interested in writing a book that explores how a company can build its data capabilities. From no data teams, to some or plenty of data to a fully fledged data infrastructure that enables analytics and Machine Learning exploration. Then taking that to the next level and being able to deploy machine learning and AI in an effective way to solve business problems.
Too many resources out there focus on doing the sexy data science/ML model building part, which in reality is what data scientists tend to spend the least amount of time on. A majority of the time is spent in capturing the data, cleaning and transforming it into something they can actually use. In the real world, data is messy, it’s not in one single place, etc. Being able to take that and build a data infrastructure that enables data scientists, analysts and machine learning engineers to do their work is an area that fascinates me.
Tied to that is also the deployment of machine learning/AI systems. Again, lots of resources walk you through how to build a model, but not enough show you how to make it useful — build a web app and deploy it to heroku, dockerize it and deploy it to a cloud environment, etc. The value of these systems will only be realized by making it available to people whether you are building a side project for fun or building a business. Everyone doesn’t need to know about scale, ML platforms, etc but it is an important aspect to understand so folks can know where their ML models fit in the larger scheme of a software system.
Going hand in hand with all this is how can you evangelize an organization to become more data-driven, to communicate the importance of using and building data capabilities to executives and decision-makers.
VK: In terms of time, money or energy what are the best investments you have made which have given you compounded rewards in your career?
JG: Having moved to Vancouver while still exploring the field of AI, Meetups have been invaluable to me. I met so many people that were on the same journey as me, some I could learn from and others I could help. Going out and meeting folks is a great way to connect, to understand the problems people are solving and even to find new roles!
Conferences are also a great learning and networking opportunity. You tend to be surrounded by folks you don’t usually have the chance to meet in person, so take advantage and connect. It is also a place to learn in more detail what other companies are working on, the challenges they have faced and how they solved it. I attended Data Science Go earlier this year in San Diego and I met lots of exciting and passionate people. I’m looking forward to attending next year as well as finding more relevant Data conferences to attend.
Working on a project on my own accord separate from an online class has also been very rewarding. Courses are great for covering the basics and getting you started but projects allow you to sink your teeth into and really wrap your head around how to get stuff done with the skills you’ve learnt. I’ve worked on exploring Tech Meetups in Vancouver, scraping data from multiple pages to create my own catalog, etc. While working on these projects, I get more ideas on how to extend them, which in turn requires me to learn more skills to achieve that.
Podcasts are another resource I spend a lot of time using — there are lots of good Data Science focused podcasts that explore different aspects — practical applications, theoretical papers, how to build your career, leadership, ethics, data engineering, etc.
VK:In the last year, what has improved your work life which could benefit others?
JG: I joined a startup earlier this year so I have been adjusting to the speed change coming from a much larger company. Every task in a startup can seem like it is a priority 1, so being able to prioritize tasks and communicate the expectation of how long they will take is a crucial skill I’ve needed to develop.
VK: What advice would you give to someone starting in this field? What advice should they ignore?
JG: This was an advice I heard while attending Data Science Go — focus on the area that you are interested in. Specifically, if you aren’t interested in working with images, don’t learn Convolutional Neural Networks. If you aren’t interested in Marketing, don’t bother learning Marketing related analytics. Sometimes it is easier to figure out what we aren’t interested in rather than what we are interested in. So go through this process to narrow down the areas you may be interested in.
This field is quite vast — although more specialized roles are being created, a data scientist could either do data infrastructure, build machine learning models, do analytics or conduct statistical experiments or some combination of these and more. Although there is talk of the unicorn full stack data scientist, you must realize that this will take years to achieve (if you are aiming to do it well).
Start blogging! Start learning how you can communicate your findings, your challenges in written form. Share what you are learning. Just as there is someone in ahead of you, there is someone behind you who can learn from you.
VK:How do you determine saying no to experiments/projects?
JG: Right now, I’m really interested in building ML/AI projects that will have a meaningful business impact.
Some experiments/projects sound super cool from a technical perspective, but don’t provide any immediate business value. These are the projects I say no to. — Johnny
Currently, I work for an IoT based Data Analytics company. Our IoT device sits in retail stores at the Point of Sale — theoretically, we could use it to provide translation services between a cashier and a customer. It could be a very cool project to build such a model that could work on the edge effectively. However, it wouldn’t have a business impact as that is not the business problem we are trying to solve.
VK:In your opinion what is the ideal Organizational placement for a data team?
JG: This really depends. Again, another take away I had from Data Science Go (did I mention you learn a lot at conferences 🙂 ) was from a talk that focused on the roles of a Data Science team, which determined where the team sat in the organization.
Depending on the organization and its needs, data science teams could sit in the engineering team helping them build ML pipelines/products, or in a centralized/embedded team serving as a center of excellence for data science/analytics, or in the research department exploring next generation of AI products, etc.
VK:If you could redo your career today, what would you do?
JG: I would have worked on my soft skills earlier. I would have joined a Toastmasters group, started attending Meetups and offered to give talks.
Along with this, I would have focused on building applications in my free time, honing my software engineering skills while building my Operations/Cloud Architecture and deployment skills.
VK:What online blogs/people do you follow for getting advice/ learning more about DS?
JG: Some of the blogs I follow and podcasts I listen to are below.
Thanks for reading! 😊 If you enjoyed it, test how many times can you hit 👏 in 5 seconds. It’s great cardio for your fingers AND will help other people see the story.
Some of the best technology companies showcase their innovation from time to time on their blogs. These blogs are a great source to read when you are preparing for company specific data science interviews. From a company perspective, the blogs help attract data professionals. In the last few years, companies are in a race to hire data talent and have started showcasing their data science technology and techniques by having separate data science/ machine learning or AI sections on their blogs.
At Acing Data Science, we consume a lot of papers, blogs, videos and podcasts about data science. Lots of companies write about data science but below are our top picks of the company data science blogs. These blogs cover one or few aspects of data science in a very helpful way helping the whole data science community in general.
Google: Google is where some of the very early research in data science and AI began. Their AI blog is one of the most mature and complete manifestation of what an AI blog would look like. The blog covers everything from publications, stories, open source data science frameworks, data sets, tools, learning courses and finally careers at this AI institution.
Uber: Uber AI Labs has a fantastic set of articles which gives us a speak peak into the great work going on within Uber. Uber’s also gives building blocks about its coveted ML-as-a-service platform Michaelangelo. Uber has also open sourced many data engineering and data science frameworks and mentioned them on its blog.
Facebook: Facebook has been doing great work in computer vision and conversational AI. They have open sourced Pytorch which is increasingly cited in papers on ArXiv. Their blog also covers publications, experiments and techniques within Facebook which helps advance the data science field forward.
AirBnB AI & Machine Learning: Airbnb has one of the best AI and ML company blogs. They have done some amazing work using deep learning models on search, listing photos and a host of other things. Airbnb data scientists are split across teams which is detailed by Elena Grewal. It shows some of the best ways to think about building and managing teams within product companies.
Instacart Data Science | Instacart ML: Instacart handles 200 million plus grocery items on their platform. The blog showcases their data engineering prowess. It also shows some of the techniques they apply to critical business areas like delivery, cost prediction, real-time availability of grocery items and even some great data visualizations using their data.
OpenAI blog: OpenAI’s mission is to ensure that artificial general intelligence benefits all of humanity. OpenAI has some great papers and findings on their blog which are on the cutting edge of AI.
StitchFix: Stichfix is the most under rated data science blog for their data visualizations. Their algorithms tour is one of the best ways I have seen data scientists explain what their product does. Their blog (multi-threaded) does not have a separate section for data science but they cover the interesting things they do within Stitchfix.
This is by no means an exhaustive list of company blogs to follow and read. These blogs have some of the best data science content helpful for all data professionals!
Subscribe to our Acing AI newsletter, I promise not to spam and its FREE!
Thanks for reading! 😊 If you enjoyed it, test how many times can you hit 👏 in 5 seconds. It’s great cardio for your fingers AND will help other people see the story.
The sole motivation of this blog article is to learn about the different AI company blogs and its technologies. All data is sourced from online public sources. I aim to make this a living document, so any updates and suggested changes can always be included. Please provide relevant feedback.
Great Data Science Company Blogs was originally published in Acing AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Identify similar records, Sparse matrix multiplication
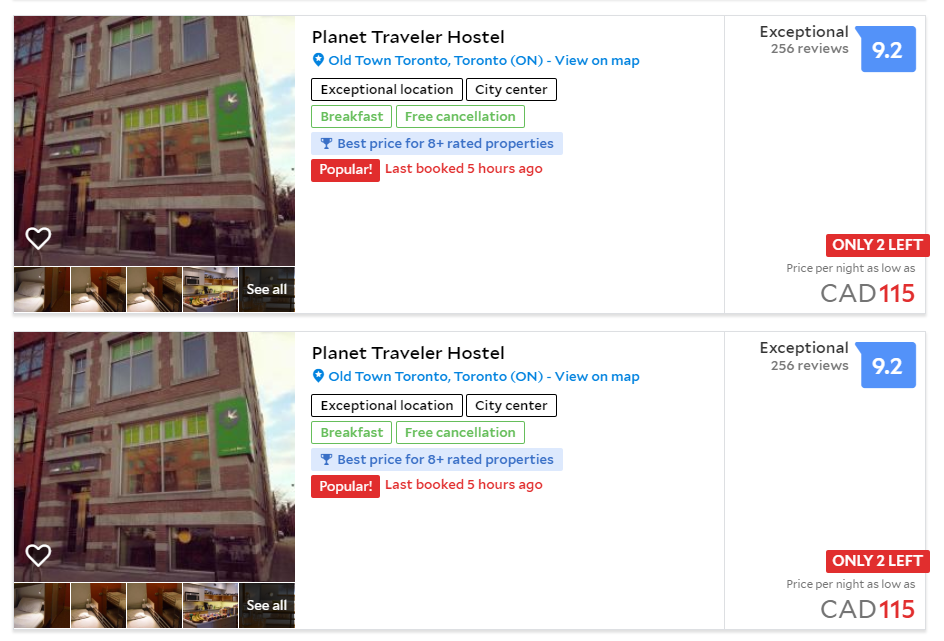
Online world is full of duplicate listings. In particular, if you are an online travel agency, and you accept different suppliers that provide you information for the same property.
Sometimes the duplicate records are obvious that makes you think: How is it possible?
Photo credit: agoda
Another time, the two records look like they are duplicates, but we were not sure.
Photo credit: expedia
Or, if you work for a company that has significant amount of data about companies or customers, but because the data comes from different source systems, in which are often written in different ways. Then you will have to deal with duplicate records.
Photo credit: dedupe.io
The Data
I think the best data set is to use my own. Using the Seattle Hotel data set that I created a while ago. I removed hotel description feature, kept hotel name and address features, and added duplicate records purposely, and the data set can be found here.
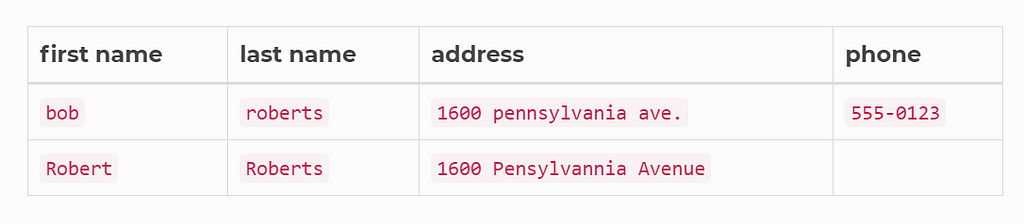
The most common way of duplication is how the street address is input. Some are using the abbreviations and others are not. For the human reader it is obvious that the above two listings are the same thing. And we will write a program to determine and remove the duplicate records and keep one only.
TF-IDF + N-gram
We will use name and address for input features.
We all familiar with tfidf and n-gram methods.
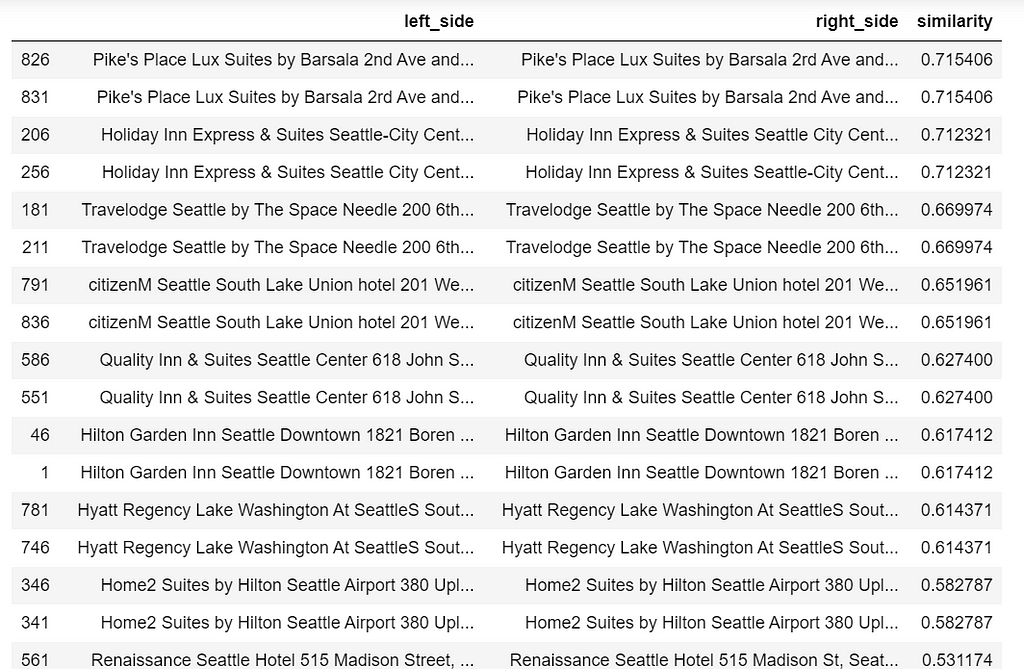
The result we get is a sparse matrix that each row is a document(name_address), each column is a n-gram. The tfidf score is computed for each n-gram in each document.
After running the function. The matrix only stores the top 5 most similar hotels.
The following code unpacks the resulting sparse matrix, the result is a table where each hotel will match to every hotel in the data(include itself), and cosine similarity score is computed for each pair.
We are only interested in the top matches except itself. So we are going to visual examine the resulting table sort by similarity scores, in which we determine a threshold a pair is the same property.