De-duplicate the Duplicate Records from Scratch
Identify similar records, Sparse matrix multiplication
Online world is full of duplicate listings. In particular, if you are an online travel agency, and you accept different suppliers that provide you information for the same property.
Sometimes the duplicate records are obvious that makes you think: How is it possible?
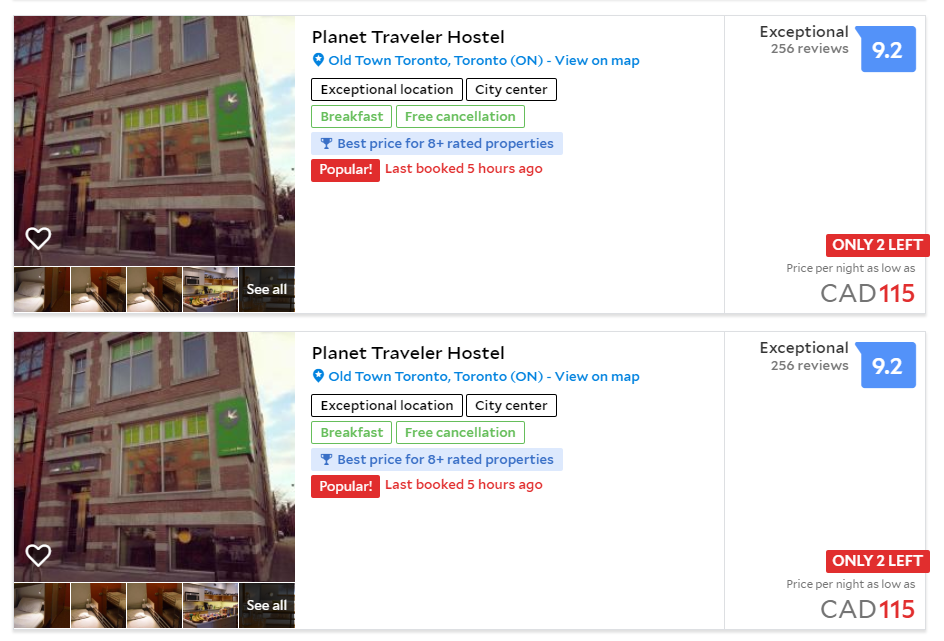
Another time, the two records look like they are duplicates, but we were not sure.

Or, if you work for a company that has significant amount of data about companies or customers, but because the data comes from different source systems, in which are often written in different ways. Then you will have to deal with duplicate records.
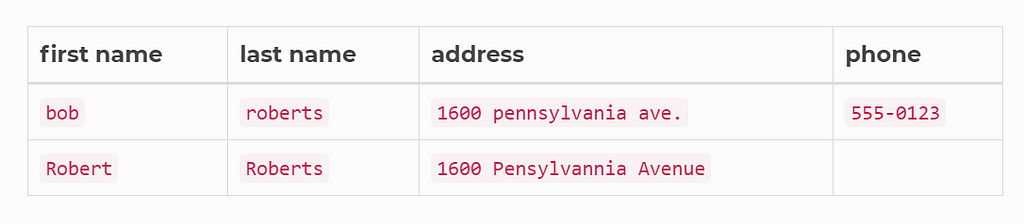
The Data
I think the best data set is to use my own. Using the Seattle Hotel data set that I created a while ago. I removed hotel description feature, kept hotel name and address features, and added duplicate records purposely, and the data set can be found here.
An example on how two hotels are duplicates:
https://medium.com/media/9f825cf1034adde99e086628cbd06561/href

The most common way of duplication is how the street address is input. Some are using the abbreviations and others are not. For the human reader it is obvious that the above two listings are the same thing. And we will write a program to determine and remove the duplicate records and keep one only.
TF-IDF + N-gram
- We will use name and address for input features.
- We all familiar with tfidf and n-gram methods.
- The result we get is a sparse matrix that each row is a document(name_address), each column is a n-gram. The tfidf score is computed for each n-gram in each document.
https://medium.com/media/a1c7cfdffab34416823d13fb25ff8c93/href
Sparse_dot_topn
I discovered an excellent library that developed by ING Wholesale Banking, sparse_dot_topn which stores only the top N highest matches for each item, and we can choose to show the top similarities above a threshold.
It claims that it provides faster way to perform a sparse matrix multiplication followed by top-n multiplication result selection.
The function takes the following things as input:
- A and B: two CSR matrix
- ntop: n top results
- lower_bound: a threshold that the element of A*B must greater than output
The output is a resulting matrix.
https://medium.com/media/ab9ab56ff91a20aec471569f9879d406/href
After running the function. The matrix only stores the top 5 most similar hotels.
The following code unpacks the resulting sparse matrix, the result is a table where each hotel will match to every hotel in the data(include itself), and cosine similarity score is computed for each pair.
https://medium.com/media/4586d0709b6d121c5000fe965da68916/href
We are only interested in the top matches except itself. So we are going to visual examine the resulting table sort by similarity scores, in which we determine a threshold a pair is the same property.
matches_df[matches_df['similarity'] < 0.99999].sort_values(by=['similarity'], ascending=False).head(30)
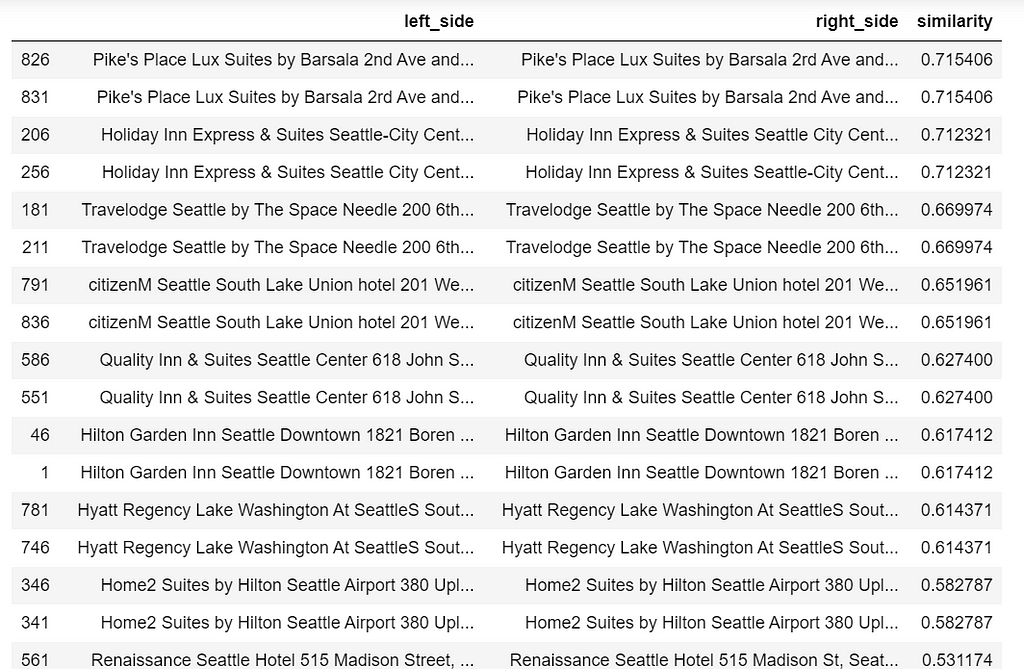
I decided my safe bet is to remove any pairs where the similarity score is higher than or equal to 0.50.
matches_df[matches_df['similarity'] < 0.50].right_side.nunique()

After that, we now have 152 properties left. If you remember, in our original data set, we did have 152 properties.
Jupyter notebook and the dataset can be found on Github. Have a productive week!
De-duplicate the Duplicate Records from Scratch was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.