A Magnetosphere for Neural Networks
The LogAdam Optimizer
Planetary defence against massive gradient spikes

Neural networks learn by iteratively updating their weights.
This is usually not a problem — an amount based on the gradient of the error is back-propagated through the network, weights are updated and progress is made. All is peaceful for the AI.
Occasionally, however, the neural network can enter an area where the loss function has an immense sharp gradient. This amount, when propagated back through the network, destroys the delicate patterns found in earlier steps and the damage seriously sets back training and the performance of the model.
Drawing an analogy to the Sun, the Sun allows for life to evolve on Earth, and at the same time we have a magnetosphere that protects the planet from the occasional massive solar flare. In the same way, neural networks need a magnetosphere.
One approach is to cap extreme gradients by just clipping them, setting a maximum limit to the gradient. However this has a couple drawbacks — the first is that it is challenging to find an appropriate limit (an extra hyperparameter to worry about), and secondly, the neural network loses information about the magnitude of the gradient if it is beyond that limit.
Instead, what if we just scaled the gradient to its logarithm? In that case, each order of magnitude increase in the gradient only adds a constant amount to the back-propagated signal. This is the magnetosphere for your neural network. It can handle massive gradients with ease.
Specifically, we join the two logarithmic functions below at the origin to create a smooth monotonic scale that we use to dampen the gradient, and, in doing so, we protect the network.
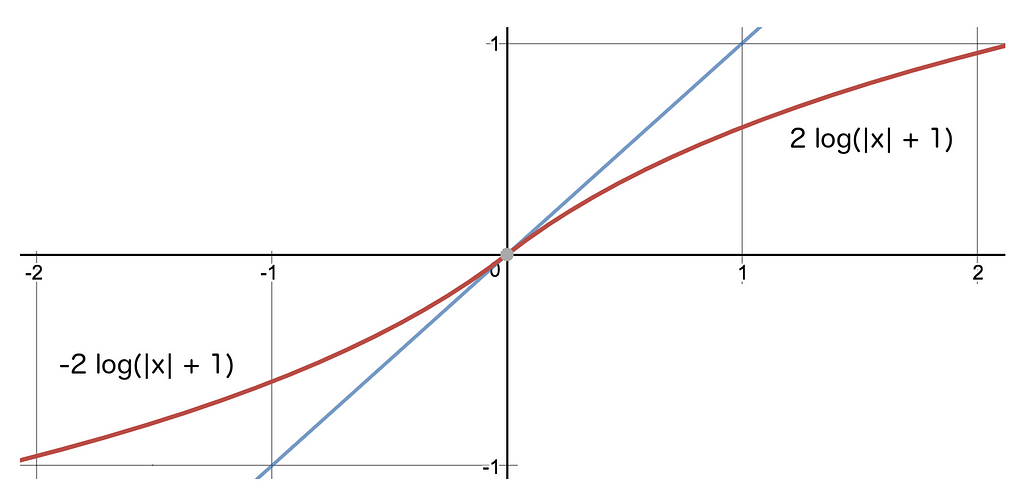
In TensorFlow, the gradient of the loss function can be dampened as follows, before sending it back through the network:
TensorFlow:
protected_grad = tf.sign(grad) * tf.log( tf.abs(grad) + 1. )
You can use this technique with any optimizer but often one of the best is the AdamOptimizer. Extending it in this simple way gives us the LogAdamOptimizer.
Does it work? Absolutely! I am using this approach in a 46-layer GAN to generate flowers, here are some samples from around iteration 140k where all gradients are ‘log-dampened’ gradients (i.e. using a LogAdam optimizer):

Enjoy, happy training.
I’ll have more to post about GAN training — follow if you are interested in learning more about them!
Dave MacDonald