Cinnamon AI saves 70% on ML model training costs with Amazon SageMaker Managed Spot Training
Developers are constantly training and re-training machine learning (ML) models so they can continuously improve model predictions. Depending on the dataset size, model training jobs can take anywhere from a few minutes to multiple hours or days. ML development can be a complex, expensive, and iterative process. Being compute intensive, keeping compute costs low for ML development is vital and a key enabler to achieving scale.
Amazon SageMaker is a fully managed service to build, train, tune, and deploy ML models at scale. Amazon SageMaker Managed Spot Training enables you to save up to 90% in training costs by using Amazon EC2 Spot Instances for training.
EC2 Spot Instances are a great way to optimize compute costs for ML training workloads, they use spare Amazon EC2 capacity which is available for up to a 90% discount over On-Demand Instances. When there is a spike in requests for a particular On-Demand instance type in a specific availability zone (AZ), AWS can reclaim the Spot Instances with a two-minute notification.
This post describes how Cinnamon AI reduced their ML training costs by 70% and increased the number of daily training jobs by 40% without increasing their budgets by using Amazon SageMaker Managed Spot Training.
Amazon SageMaker Managed Spot Training
Managed Spot Training uses EC2 Spot Instances to run training jobs instead of On-Demand Instances. With Managed Spot Training, Amazon SageMaker manages the Spot capacity and handles interruptions. In case of a Spot interruption, Managed Spot Training pauses the training job and reliably resumes as Spot capacity becomes available. As a result, Managed Spot Training is best suited for model training jobs with flexible starting times and run durations. You can configure your training job to use checkpoints. When enabled, Amazon SageMaker copies checkpoint data from a local path to Amazon S3 and resumes interrupted training jobs from the last checkpoint instead of restarting. Managed Spot Training eliminates the need for you to build additional tooling to poll for Spot capacity or manage interruptions. You can use Managed Spot Training when training models built using the popular ML frameworks, Amazon SageMaker built-in algorithms, and custom-built models.
To enable the feature, choose Enable managed spot training on the Amazon SageMaker console. See the following screenshot.
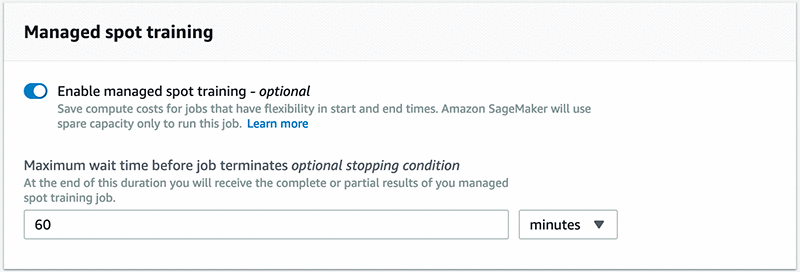
If you are using Amazon SageMaker SDK, set train_use_spot_instances to true in the Estimator constructor. You can also specify a stopping condition that controls how long Amazon SageMaker waits for Spot Instances to become available.
Cinnamon AI saves 70% on model training costs
With the massive opportunity that cognitive and artificial intelligence (AI) systems present, many companies are developing AI-powered products to build intelligent services. One such innovator is Cinnamon AI, a Japan-based startup with a mission to “extend human potential by eliminating repetitive tasks” through their AI service offerings.
Cinnamon AI’s flagship product, Flax Scanner, is a document reader that uses natural language processing (NLP) algorithms to automate data extraction from unstructured business documents such as invoices, receipts, insurance claims, and financial statements. It converts these documents into database-ready files. The goal is to eliminate the need for humans to read such documents to extract the required data, thus saving businesses millions of hours in time and reducing their operational costs. This service also works on hand-written documents and with Japanese characters.
Cinnamon AI has also developed two other ML-powered services called Rossa Voice and Aurora. Rossa Voice is a high-precision, real-time voice recognition service that has applications around voice fraud detection and to transcribe records at call centers. And Aurora is a service that automatically extracts necessary information from long sentences in documents. You can use this service to find important information from specifications and contract documents.
Cinnamon AI had a goal to reduce their ML development costs, so they decided to consolidate their disparate development environments into a single platform and then continuously optimize on costs. They chose AWS to develop their ML services on because of AWS’s breadth of services, cost effective pricing options, granular security controls, and technical support. As a first step, Cinnamon AI migrated all their ML workloads from on-premises environments and other cloud providers onto AWS. Next, the team optimized their EC2 usage and started using Amazon SageMaker to train their ML models. More recently, they started using the Managed Spot Training feature to use Spot Instances for training, which helped them optimize their cost profile significantly.
“The Managed Spot Training feature of Amazon SageMaker has had a profound impact on our AWS cost savings. Our AWS EC2 costs reduced by up to 70% after using Managed Spot Training,” said Tetsuya Saito, General Manager of Infrastructure and Information Security Office at Cinnamon AI. “In addition, Managed Spot Training does not require complicated methods and can be used simply from the SageMaker SDK.”
The following graph shows Cinnamon AI’s model training cost savings journey over six months. In June 2019, after moving their ML workloads onto AWS, they started using EC2 On-Demand Instances for model training. You can use this as a point of reference from a training cost perspective. Over the next few months, they optimized their EC2 On-Demand usage mainly through instance right sizing and using GPU instances (P2, P3) for large training jobs. They also adopted Amazon SageMaker for model training with On-Demand Instances and reduced their training costs by approximately 20%. Furthermore, they saw substantial cost savings of 70% by using Managed Spot Training to use Spot Instances for model training in November 2019. Their cost optimization effort also resulted in their ability to increase the number of daily model training jobs by 40%, while maintaining a reduced cost profile.
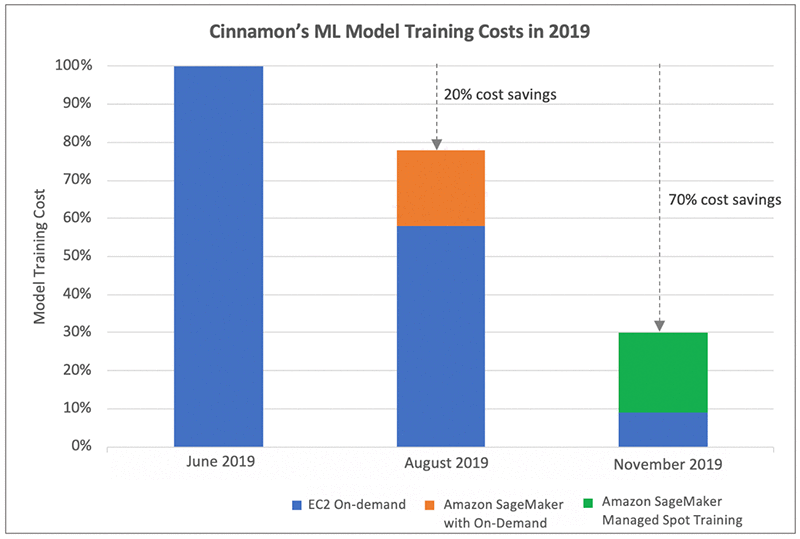
Cinnamon AI’s Model Development Environment
As Cinnamon AI is developing multiple ML-powered products and services, their data types vary based on the application and include 2D images, audio, and text with dataset sizes ranging from 100 MB to 40 GB. They predominantly use custom deep learning models and their frameworks of choice are TensorFlow, PyTorch, and Keras. They use GPU instances for time-consuming neural network training jobs, with run times ranging from a few hours to days, and use CPU instances for smaller model training experiments.
The following architecture depicts Cinnamon AI’s ML environment and workflow at a high level.
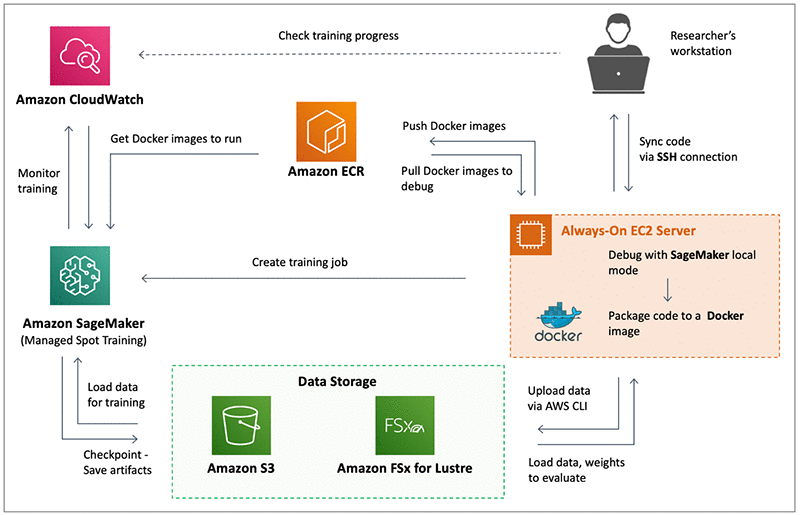
The AI researchers develop code on their workstations and then synchronize it to a shared always-on EC2 server (On-Demand instance). This instance is used to call Amazon SageMaker local mode to run, test, and debug their scripts and models on small datasets. After the executed code is tested, it is packaged into a Docker image and stored in Amazon ECR. This enables researchers to share their work across teams and to pull the required Docker image from ECR on their respective Amazon SageMaker training instances. Also, on the EC2 server, the researchers can use the Amazon SageMaker Python SDK to initialize an Amazon SageMaker Estimator and then launch training jobs in Amazon SageMaker.
Almost all of Cinnamon AI’s training jobs run on Spot Instances in Amazon SageMaker via Managed Spot Training, with checkpointing enabled to save the state of the models. Amazon SageMaker saves the checkpoints to Amazon S3 while the training is in progress, and they can use them to resume training in events of Spot interruptions. In addition to S3, Cinnamon AI uses Amazon FSx for Lustre to feed data to Amazon SageMaker for training ML models. Using Amazon FSx for Lustre has reduced the data loading time to the SageMaker training instance compared to directly loading the data from S3. They can access the data in S3 and Amazon FSx for Lustre by both the EC2 instance and the SageMaker training instance. Amazon SageMaker publishes training metrics to Amazon CloudWatch, which Cinnamon AI researchers use to monitor their training jobs.
Conclusion
Managed Spot Training is a great way to optimize model training costs for jobs with flexible starting times and run durations. The Cinnamon AI team has successfully taken advantage of the cost-saving strategies with Amazon SageMaker and has increased the number of daily experiments and reduced training costs by 70%. If you are not using Spot Instances for model training, try out Managed Spot Training. For more information, see Managed Spot Training: Save Up to 90% On Your Amazon SageMaker Training Jobs. You can get started with Amazon SageMaker here.
About the Authors
 Sundar Ranganathan is a Principal Business Development Manager on the EC2 team focusing on EC2 Spot for AI/ML in addition to Big Data, Containers, and DevOps workloads. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.
Sundar Ranganathan is a Principal Business Development Manager on the EC2 team focusing on EC2 Spot for AI/ML in addition to Big Data, Containers, and DevOps workloads. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.
 Yoshitaka Haribara, Ph.D., is a Startup Solutions Architect in Japan focusing on machine learning workloads. He helped Cinnamon AI to migrate their workload on to Amazon SageMaker.
Yoshitaka Haribara, Ph.D., is a Startup Solutions Architect in Japan focusing on machine learning workloads. He helped Cinnamon AI to migrate their workload on to Amazon SageMaker.
Additional contributions by by Shoko Utsunomiya, a Senior Solution Architect at AWS.



 Ben Fields is a Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include AI/ML, containers, and big data. You can often find him out climbing at the nearest climbing gym, playing ice hockey at the closest rink, or enjoying the warmth of home with a good game.
Ben Fields is a Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include AI/ML, containers, and big data. You can often find him out climbing at the nearest climbing gym, playing ice hockey at the closest rink, or enjoying the warmth of home with a good game.
 Hervé Nivon is a Solutions Architect who helps startup customers grow their business on AWS. Before joining AWS, Hervé was the CTO of a company generating business insights for enterprises from commercial unmanned aerial vehicle imagery. Hervé has also served as a consultant at Accenture.
Hervé Nivon is a Solutions Architect who helps startup customers grow their business on AWS. Before joining AWS, Hervé was the CTO of a company generating business insights for enterprises from commercial unmanned aerial vehicle imagery. Hervé has also served as a consultant at Accenture.






 Anubhav Mishra is a Product Manager with AWS. He spends his time understanding customers and designing product experiences to address their business challenges.
Anubhav Mishra is a Product Manager with AWS. He spends his time understanding customers and designing product experiences to address their business challenges. Hammad Mirza works as a Software Development Engineer at Amazon AI. He works on building and maintaining scalable distributed systems for Amazon Lex. Outside of work, he can be found spending quality time with friends and family.
Hammad Mirza works as a Software Development Engineer at Amazon AI. He works on building and maintaining scalable distributed systems for Amazon Lex. Outside of work, he can be found spending quality time with friends and family. Goutham Venkatesan works as a Software Development Engineer at Amazon AI. He works on enhancing the Lex customer experience building distributed systems at scale. Outside of work, he can be found traveling to sunny destinations & sipping coconuts on the beach.
Goutham Venkatesan works as a Software Development Engineer at Amazon AI. He works on enhancing the Lex customer experience building distributed systems at scale. Outside of work, he can be found traveling to sunny destinations & sipping coconuts on the beach. Kriti Bharti is the Product Lead for Amazon Textract. Kriti has over 15 years’ experience in Product Management, Program Management, and Technology Management across multiple industries such as Healthcare, Banking and Finance, and Retail. In her spare time, you can find Kriti spending pawsome time with Fifi and her cousins, reading, or learning different dance forms.
Kriti Bharti is the Product Lead for Amazon Textract. Kriti has over 15 years’ experience in Product Management, Program Management, and Technology Management across multiple industries such as Healthcare, Banking and Finance, and Retail. In her spare time, you can find Kriti spending pawsome time with Fifi and her cousins, reading, or learning different dance forms.


 Ajay Vohra is a Principal Solutions Architect specializing in perception machine learning for autonomous vehicle development. Prior to Amazon, Ajay worked in the area of massively parallel grid-computing for financial risk modeling, and automation of application platform engineering in on-premise data centers.
Ajay Vohra is a Principal Solutions Architect specializing in perception machine learning for autonomous vehicle development. Prior to Amazon, Ajay worked in the area of massively parallel grid-computing for financial risk modeling, and automation of application platform engineering in on-premise data centers.
 Krzysztof Chalupka is an applied scientist in the Amazon ML Solutions Lab. He has a PhD in causal inference and computer vision from Caltech. At Amazon, he figures out ways in which computer vision and deep learning can augment human intelligence. His free time is filled with family. He also loves forests, woodworking, and books (trees in all forms).
Krzysztof Chalupka is an applied scientist in the Amazon ML Solutions Lab. He has a PhD in causal inference and computer vision from Caltech. At Amazon, he figures out ways in which computer vision and deep learning can augment human intelligence. His free time is filled with family. He also loves forests, woodworking, and books (trees in all forms). Vikram Madan is the Product Manager for Amazon SageMaker Ground Truth. He focusing on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys running long distances and watching documentaries.
Vikram Madan is the Product Manager for Amazon SageMaker Ground Truth. He focusing on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys running long distances and watching documentaries. Ankit Dhawan is a Senior Product Manager for Amazon Polly, a technology enthusiast, and a huge Liverpool FC fan. When not working on delighting our customers, you will find him exploring the Pacific Northwest with his wife and dog. He is an eternal optimist, loves reading biographies, and playing poker. You can indulge him in a conversation on technology, entrepreneurship, or soccer anytime of the day.
Ankit Dhawan is a Senior Product Manager for Amazon Polly, a technology enthusiast, and a huge Liverpool FC fan. When not working on delighting our customers, you will find him exploring the Pacific Northwest with his wife and dog. He is an eternal optimist, loves reading biographies, and playing poker. You can indulge him in a conversation on technology, entrepreneurship, or soccer anytime of the day.






 About the Author
About the Author