Building machine learning workflows with AWS Data Exchange and Amazon SageMaker
Thanks to cloud services such as Amazon SageMaker and AWS Data Exchange, machine learning (ML) is now easier than ever. This post explains how to build a model that predicts restaurant grades of NYC restaurants using AWS Data Exchange and Amazon SageMaker. We use a dataset of 23,372 restaurant inspection grades and scores from AWS Data Exchange alongside Amazon SageMaker to train and deploy a model using the Linear Learner Algorithm.
Background
ML workflows are an iterative process that require many decisions to be made such as whether or not training data is needed, what attributes to capture, what algorithms to use, and where to deploy a trained model. All of these decisions effect the outcome of a learning system. Once a problem is defined, you must choose from four distinct types of learning systems. Some learning systems depend entirely on training data where others require no training data at all, but rather a well-defined environment and action space. When an algorithm relies on training data, the quality and sensitivity of the final model depends heavily on the characteristics of the training set. It is here that many enter the tedious loop of trying to find the right balance of features that will result in a well-balanced and accurate model. An overview of each learning system can be seen below:
- Supervised – In supervised learning the training set includes labels so the algorithm knows the correct label given a set of attributes. For example, the attributes could be the color and weight of a fish where the label is the type of fish. Eventually the model learns how to assign the correct or most probable label. A typical supervised learning task is classification, which is the task of assigning inputs such as text or images to one of several predefined categories. Examples include detecting spam email messages based upon the message header and content, categorizing cells as malignant or benign based upon the results of MRI scans, and classifying galaxies based upon their shapes (Tan et al. 2006). The algorithms used in this category typically consist of k-nearest neighbors, linear regression, logistic regression, support vector machines, and neural networks.
- Unsupervised – Unsupervised learning uses algorithms that discover relationships in unlabeled data. The algorithms must explore the data and find the relationships based on the known features. Some of the common algorithms used within unsupervised learning include clustering (K-means, DBSCAN, and hierarchical cluster analysis) where you are grouping similar data points, anomaly detection where you are trying to find outliers, as well as association rule learning where you are trying to discover the correlation between features (Aurélien 2019). In practice, this could be seen by clustering cities based on crime rates to find out which cities are alike or clustering products at a grocery store based on customer age to discover patterns.
- Semi-supervised – Semi-supervised learning uses training data that consists of both labeled and unlabeled data. The algorithms are often a combination of both unsupervised and supervised algorithms. If you were to have a dataset with unlabeled data the first step would be to label the data. Once the dataset has been labeled, you can train your algorithm with traditional supervised learning techniques to map your features to known labels. Photo-hosting services often use this workflow by using your skills to label an unknown face. Once the face is known another algorithm can scan all your photos to identify the now known face.
- Reinforcement – Reinforcement learning (RL) differs from the previous learning systems because it doesn’t have to learn from training data. Instead, the model learns from its own experience in the context of a well-defined environment. The learning system is called an agent and that agent can observe the environment, select and perform actions based on a policy, and get rewards in return. The agent eventually learns to maximize its reward over time based on its previous experience. For more information or to get some clarity about RL, see the documentation on Amazon SageMaker RL.
Steps to build the restaurant grade prediction model
When beginning an ML project, it is important to think about the whole process and not just the final product. In this project, we go through the following steps:
- Define the problem you want to solve. In this case, we want to make better informed choices on where to eat in NYC based on cleanliness.
- Find a dataset to train your model. We want a dataset that contains restaurant inspection grades and scores in NYC.
- Review the data. We want to make sure the data we need is present and that there is enough to train the model.
- Prepare and clean the dataset for training in Amazon SageMaker. We want to only include the needed data such as borough and food category and ensure the correct format is used.
- Select a model for multi-class classification. In our case we are training with the Linear Learner Algorithm.
- Deploy the model to Amazon SageMaker. With the model deployed to Amazon SageMaker we can invoke the endpoint to get predictions.
Data is the foundation of ML; the quality of the final model depends on the quality of the data used for training. In our workflow, half of the steps are related to data collection and preparation. This theme can be seen in most ML projects and is often the most challenging part. Additionally, you have to think about the characteristics of your data to prevent an overly sensitive or perhaps a not sensitive enough model. Furthermore, not all data is internal. You may have to use either free or paid third-party data to enrich internal datasets and improve the quality of the model, but finding, licensing, and consuming this third-party data has been a challenge for years. Fortunately, you now have AWS Data Exchange.
Using AWS Data Exchange
AWS Data Exchange can simplify the data collection process by making it easy to find, subscribe to, and use third-party data in the cloud. You can browse over 1,500 data products from more than 90 qualified data providers in the AWS Marketplace. Previously, there was the need for access to more data to drive your analytics, train ML models, and make data-driven decisions, but now with AWS Data Exchange, you have all of that in one place. For more information, see AWS Data Exchange – Find, Subscribe To, and Use Data Products.
AWS Data Exchange makes it easy to get started with ML. You can jump-start your projects using one or a combination of the hundreds of datasets available. You can also enrich your internal data with external third-party data. All the datasets are available using a single cloud-native API that delivers your data directly to Amazon S3, which we will see in our workflow. This saves you and your team valuable time and resources, which you can now use for more value-added activities. With this combination, you can take data from AWS Data Exchange and feed it into Amazon SageMaker to train and deploy your models.
Using Amazon SageMaker
Amazon SageMaker is a fully managed service that enables you to quickly and easily build, train, and deploy ML models. You can take the NYC restaurant data from AWS Data Exchange and use the features of Amazon SageMaker to train and deploy a model. You will be using fully managed instances that run Jupyter notebooks to explore and preprocess the training data. These notebooks are pre-loaded with CUDA and cuDNN drivers for popular deep learning platforms, Anaconda packages, and libraries for TensorFlow, Apache MXNet, and PyTorch.
You will also be using supervised algorithms such as the linear learner algorithm to train the model. Finally, the model is deployed to an Amazon SageMaker endpoint to begin servicing requests and predicting restaurant grades. By combining the power of AWS Data Exchange with Amazon SageMaker, you have a robust set of tools to start solving the most challenging ML problems, and you are perfectly positioned to start building multi-class classifiers.
Solution overview
The solution in this post produces a multi-class classifier that can predict the grade of restaurants in New York City based on borough and food category. The following diagram shows the complete architecture.

First, take the data from AWS Data Exchange and place it into an S3 bucket. Point an AWS Glue crawler at it to create a Data Catalog of the data. With the Data Catalog in place, use Amazon Athena to query, clean, and format the data for training. When the data has transformed, load the training set back into S3. Finally, create a Jupyter notebook in Amazon SageMaker to train, deploy, and invoke your predictor.
Storing data in S3
Getting training data is often a time-consuming and challenging part of an ML project. In this case, you need to make sure that you can actually find a large enough dataset that has inspection information for restaurants in NYC, and that it contains the right attributes. Fortunately, with AWS Data Exchange you can start searching the product catalog for data. In this case, you are interested in the quality of restaurants in New York City, so enter New York Restaurant Data in the search bar and filter for free datasets. There is a product from Intellect Design Arena, Inc. offered for free, titled NY City Restaurant Data with inspection grade & score (Trial).
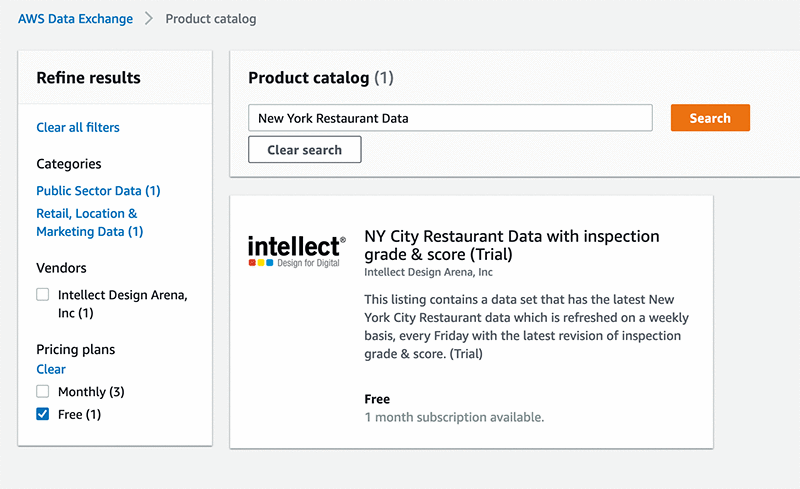
After you subscribe to the dataset, you need to find a way to expose the data to other AWS services. To accomplish this, export the data to S3 by choosing your subscription, your dataset, and a revision, and exporting to S3. When the data is in S3, you can download the file and look at the data to see what features are captured. The following screenshot shows the revision page which allows you to export your data using the “Export to Amazon S3” button.

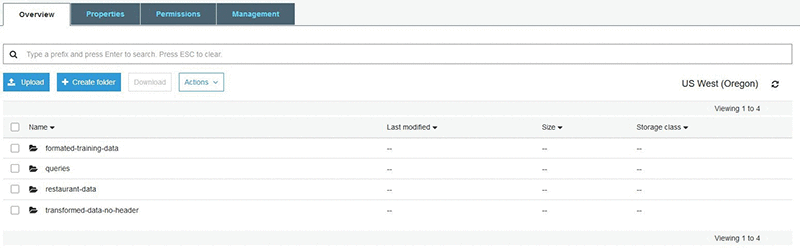
You can now download the file and look at the contents to understand how much data there is and what attributes are captured. For this example, you are only concerned with three attributes: the borough (labeled BORO), cuisine description, and the grade. A new file is created that only contains the data relevant to this use case and loaded back into S3. With the data in S3, other AWS services can quickly and securely access the data. The following screenshot captures an example of what your S3 bucket might look like once your folders and data have been loaded.
Create a Data Catalog with AWS Glue crawlers
The data in its current form is not formatted correctly for training in Amazon SageMaker, so you need to build an Extract, Transform, Load (ETL) pipeline to get this dataset into the proper format. Later in the pipeline, you use Athena to query this data and generate a formatted training set, but currently the data is just a CSV file in a bucket and we need a way to interact with the data. You can use AWS Glue crawlers to scan your data and generate a Data Catalog that enables Athena to query the data within S3. For more information, see Defining Crawlers. After the AWS Glue crawler runs, you now have a Data Catalog that Athena can use to query data. The details of your data are captured and can be seen by clicking on the newly created Data Catalog. The following screenshot shows the Data Catalog interface, which contains all the information pertaining to your data.

Querying data in Athena and creating a training set
Now that you have a dataset in S3 and the data catalog from the AWS Glue crawler, you can use Athena to start querying and formatting the data. You can use the integrated query editor to generate SQL queries that allow you to explore and transform the data. For this example, you created a SQL query to generate the following training set. This is to simplify the training process because you are moving from text-based attributes to numerically based attributes. When using the linear learner algorithm for multi-class classification, it is a requirement that the class labels be numerical values from 0 to N-1, where N is the number of possible classes. After you run the query in Athena, you can download the results and place the new dataset into S3. You are now ready to begin training a model in Amazon SageMaker. See the following code:
The SQL query creates a numerical representation of the attributes and class labels, which can be seen in the following table.
| boro_label | cat_label | class_label | |
| 1 | 5 | 8 | 0 |
| 2 | 5 | 8 | 0 |
| 3 | 5 | 8 | 0 |
| 4 | 5 | 8 | 0 |
| 5 | 5 | 8 | 0 |
| 6 | 5 | 8 | 0 |
| 7 | 5 | 8 | 0 |
| 8 | 5 | 8 | 0 |
| 9 | 5 | 8 | 0 |
| 10 | 5 | 8 | 0 |
| 11 | 5 | 8 | 0 |
| 12 | 5 | 8 | 0 |
| 13 | 5 | 8 | 0 |
| 14 | 5 | 8 | 0 |
| 15 | 5 | 8 | 0 |
Training and deploying a model in Amazon SageMaker
Now that you have clean data, you will use Amazon SageMaker to build, train, and deploy your model. First, create a Jupyter notebook in Amazon SageMaker to start writing and executing your code. You then import your data from S3 into your Jupyter notebook environment and proceed to train the model. To train the model, use the linear learner algorithm that comes included in Amazon SageMaker. The linear learner algorithm provides a solution for both classification and regression problems, but in this post, you are focusing on classification. The following Python code shows the steps to load, format, and train your model:
After the training job is complete, you can deploy the model onto an instance. This provides you with an endpoint that listens for prediction requests. See the following Python code:
Invoking an Amazon SageMaker endpoint
Now that you have a trained model deployed, you are ready to start invoking the endpoint to get predictions. The endpoint provides a score for each class type and a predicted label based on the highest score. You now have an endpoint that you can integrate into your application. The following Python code is an example of invoking the endpoint in an Amazon SageMaker notebook:
After the endpoint is invoked, a response is provided and formatted into a readable prediction. See the following code:
Cleaning up
To prevent any ongoing billing, you should clean up your resources. Start with AWS Data Exchange. If you subscribed to the dataset used in this example, set the subscription to terminate at the end of the one-month trial period. Delete any S3 buckets that are storing data used in this example. Delete the AWS Glue Data Catalog that you created as a result of the AWS Glue crawler. Also, delete your Amazon SageMaker notebook instance and the endpoint that you created from deploying your model.
Summary
This post provided an example workflow that uses AWS Data Exchange and Amazon SageMaker to build, train, and deploy a multi-class classifier. You can use AWS Data Exchange to jump-start your ML projects with third-party data, and use Amazon SageMaker to create solutions for your ML tasks with built-in tools and algorithms. If you are in the early stages of your ML project or are looking for a way to improve your already existing datasets, check out AWS Data Exchange. You could save yourself hours of data wrangling.
References
- Géron Aurélien. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. OReilly, 2019.
- Tan, Pang-Ning, et al. Introduction to Data Mining. Pearson, 2006.
About the author
 Ben Fields is a Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include AI/ML, containers, and big data. You can often find him out climbing at the nearest climbing gym, playing ice hockey at the closest rink, or enjoying the warmth of home with a good game.
Ben Fields is a Solutions Architect for Strategic Accounts based out of Seattle, Washington. His interests and experience include AI/ML, containers, and big data. You can often find him out climbing at the nearest climbing gym, playing ice hockey at the closest rink, or enjoying the warmth of home with a good game.