Understanding Word2vec Embedding in Practice

Word embedding, vector space model, Gensim
This post aims to explain the concept of Word2vec and the mathematics behind the concept in an intuitive way while implementing Word2vec embedding using Gensim in Python.
The basic idea of Word2vec is that instead of representing words as one-hot encoding (countvectorizer / tfidfvectorizer) in high dimensional space, we represent words in dense low dimensional space in a way that similar words get similar word vectors, so they are mapped to nearby points.
Word2vec is not deep neural network, it turns text into a numeric form that deep neural network can process as input.
How the word2vec model is trained
- Move through the training corpus with a sliding window: Each word is a prediction problem.
- The objective is to predict the current word using the neighboring words (or vice versa).
- The outcome of the prediction determines whether we adjust the current word vector. Gradually, vectors converge to (hopefully) optimal values.
For example, we can use “artificial” to predict “intelligence”.
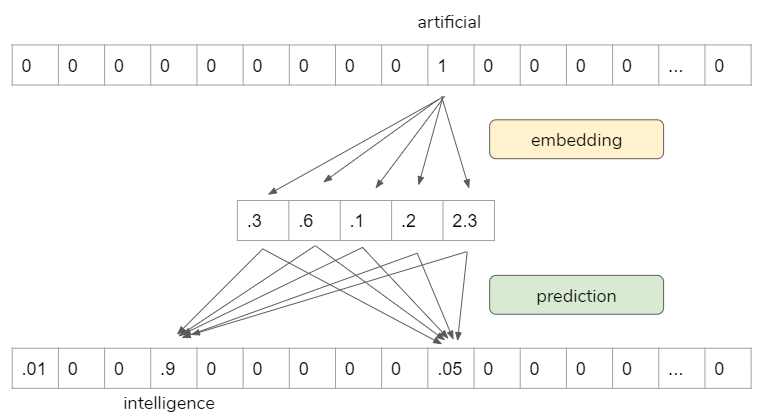
However, the prediction itself is not our goal. It is a proxy to learn vector representations so that we can use it for other tasks.
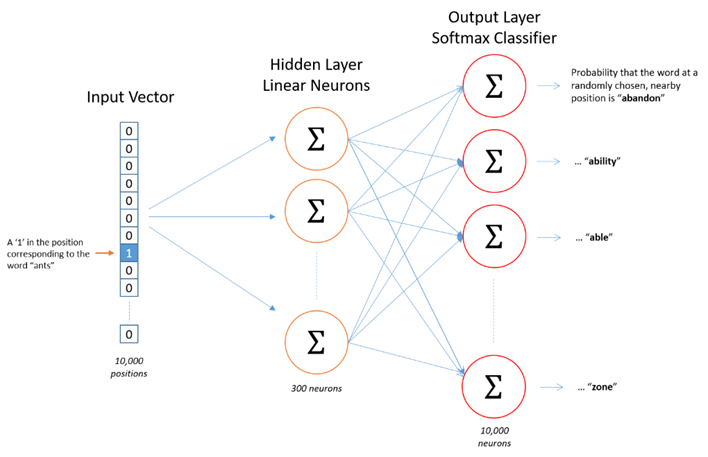
Word2vec Skip-gram Network Architecture
This is one of word2vec models architectures. It is just a simple one hidden layer and one output layer.
The Math
The following is the math behind word2vec embedding. The input layer is the one-hot encoded vectors, so it gets “1” in that word index, “0” everywhere else. When we multiply this input vector by weight matrix, we are actually pulling out one row that is corresponding to that word index. The objective here is to pull out the important row(s), then, we toss the rest.
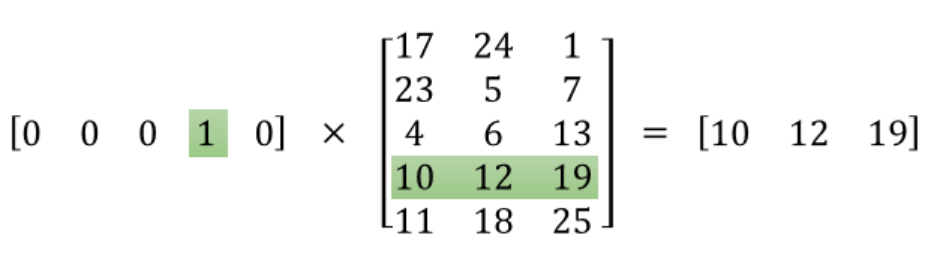
This is the main mechanics on how word2vec works.
When we use Tensorflow / Keras or Pytorch to do this, they have a special layer for this process called “Embedding layer”. So, we are not going to do math by ourselves, we only need to pass one-hot encoded vectors, the “Embedding layer” does all the dirty works.
Pre-process the text
Now we are going to implement word2vec embedding for a BBC news data set.
- We use Gensim to train word2vec embedding.
- We use NLTK and spaCy to pre-process the text.
- We use t-SNE to visualize high-dimensional data.
https://medium.com/media/18a345d97b747c8f1e6b1da2c040cc4c/href
- We use spaCy for lemmatization.
- Disabling Named Entity Recognition for speed.
- Remove pronouns.
https://medium.com/media/b9cc027d08ca5cc7405113fac1e56640/href
- Now we can have a look top 10 most frequent words.
https://medium.com/media/4323e4c7dfa425044b0a8bf300c310d2/href
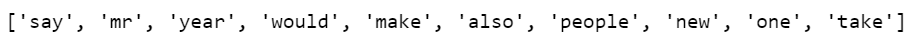
Implementing Word2vec embedding in Gensim
- min_count: Minimum number of occurrences of a word in the corpus to be included in the model. The higher the number, the less words we have in our corpus.
- window: The maximum distance between the current and predicted word within a sentence.
- size: The dimensionality of the feature vectors.
- workers: I know my system is having 4 cores.
- model.build_vocab: Prepare the model vocabulary.
- model.train: Train word vectors.
- model.init_sims(): When we do not plan to train the model any further, we use this line of code to make the model more memory-efficient.
https://medium.com/media/a1f70ba732dbe1f8d3df7e3c9827fe81/href
Explore the model
- Find the most similar words for “economy”
w2v_model.wv.most_similar(positive=['economy'])

- Find the most similar words for “president”
w2v_model.wv.most_similar(positive=['president'])

- How similar are these two words to each other?
w2v_model.wv.similarity('company', 'business')
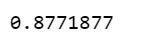
Please note, the above results could change if we change min_count. For example, if we set min_count=100, we will have more words to work with, some of them may be more similar to the target words than the above results; If we set min_count=300, some of the above results may disappear.
- We Use t-SNE to represent high-dimensional data in a lower-dimensional space.
https://medium.com/media/dcc0ba898b2e4d11c9a1503608b690dc/href

- It is obvious that some words are close to each other, such as “team”, “goal”, “injury”, “olympic” and so on. And those words tend to be used in the sport related news articles.
- Other words that cluster together such as “film”, “actor”, “award”, “prize” and so on, they are likely to be used in the news articles that talk about entertainment.
- Again. How the plot looks like pretty much depends on how we set min_count.
The Jupyter notebook can be found on Github. Enjoy the rest of the week.
Understanding Word2vec Embedding in Practice was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.