Natural Questions: a New Corpus and Challenge for Question Answering Research
Open-domain question answering (QA) is a benchmark task in natural language understanding (NLU) that aims to emulate how people look for information, finding answers to questions by reading and understanding entire documents. Given a question expressed in natural language (“Why is the sky blue?”), a QA system should be able to read the web (such as this Wikipedia page) and return the correct answer, even if the answer is somewhat complicated and long. However, there are currently no large, publicly available sources of naturally occurring questions (i.e. questions asked by a person seeking information) and answers that can be used to train and evaluate QA models. This is because assembling a high-quality dataset for question answering requires a large source of real questions and significant human effort in finding correct answers.
To help spur research advances in QA, we are excited to announce Natural Questions (NQ), a new, large-scale corpus for training and evaluating open-domain question answering systems, and the first to replicate the end-to-end process in which people find answers to questions.1 NQ is large, consisting of 300,000 naturally occurring questions, along with human annotated answers from Wikipedia pages, to be used in training QA systems. We have additionally included 16,000 examples where answers (to the same questions) are provided by 5 different annotators, useful for evaluating the performance of the learned QA systems. Since answering the questions in NQ requires much deeper understanding than is needed to answer trivia questions — which are already quite easy for computers to solve — we are also announcing a challenge based on this data to help advance natural language understanding in computers.
The Data
NQ is the first dataset to use naturally occurring queries and focus on finding answers by reading an entire page, rather than extracting answers from a short paragraph. To create NQ, we started with real, anonymized, aggregated queries that users have posed to Google’s search engine. We then ask annotators to find answers by reading through an entire Wikipedia page as they would if the question had been theirs. Annotators look for both long answers that cover all of the information required to infer the answer, and short answers that answer the question succinctly with the names of one or more entities. The quality of the annotations in the NQ corpus has been measured at 90% accuracy.
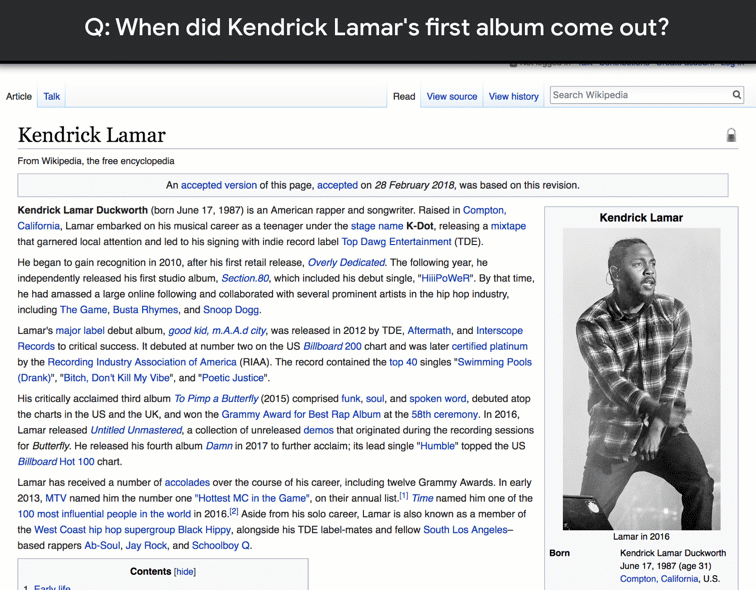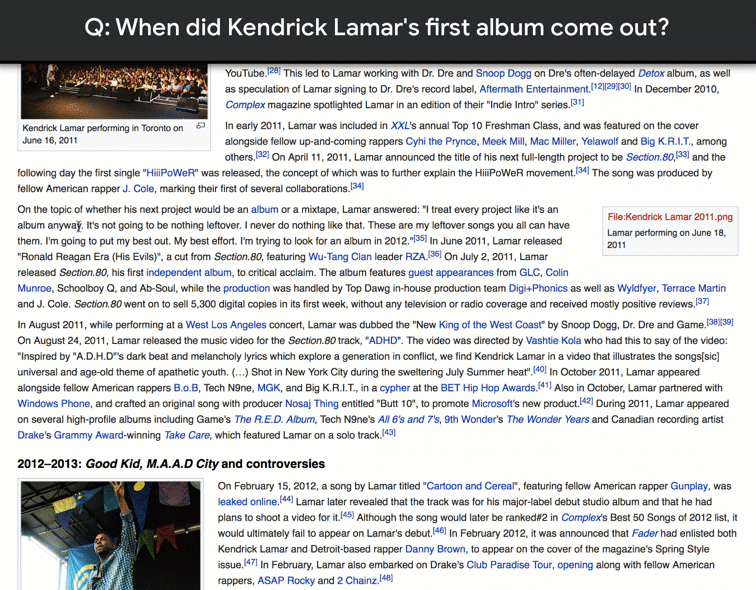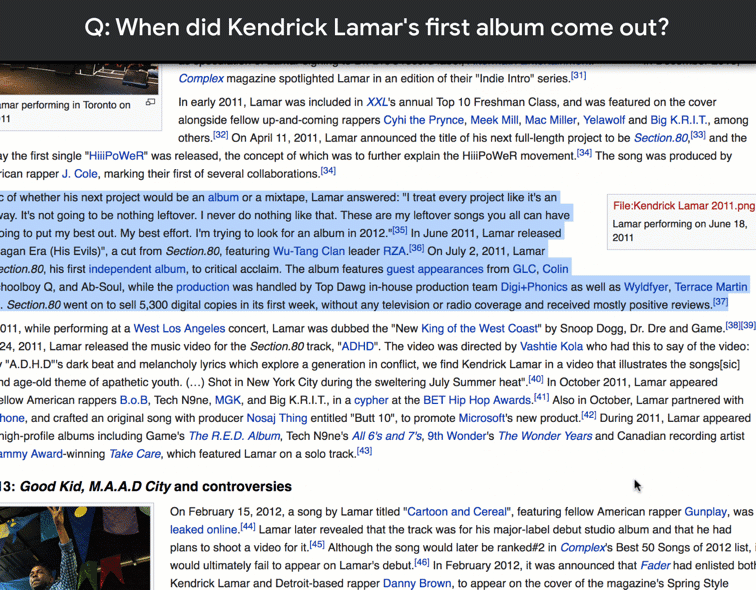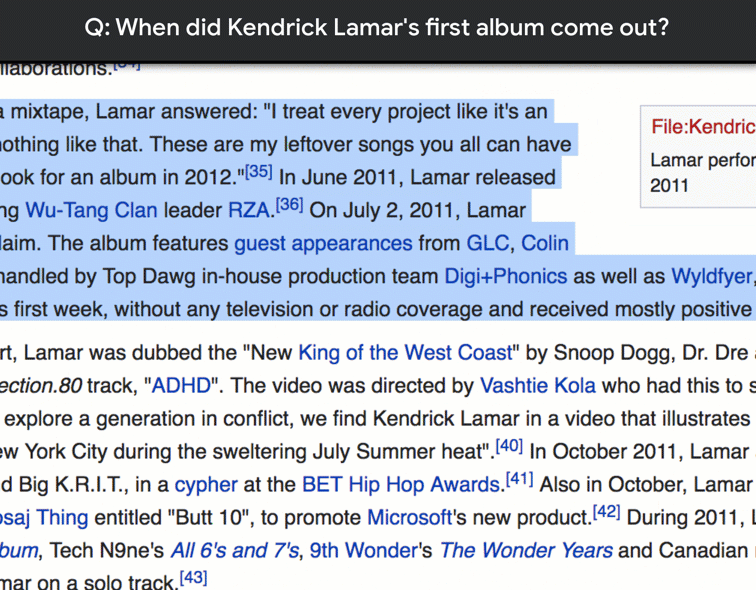
Our paper “Natural Questions: a Benchmark for Question Answering Research“, which has been accepted for publication in Transactions of the Association for Computational Linguistics, has a full description of the data collection process. To see some more examples from the dataset, please check out the NQ website.
The Challenge
NQ is aimed at enabling QA systems to read and comprehend an entire Wikipedia article that may or may not contain the answer to the question. Systems will need to first decide whether the question is sufficiently well defined to be answerable — many questions make false assumptions or are just too ambiguous to be answered concisely. Then they will need to decide whether there is any part of the Wikipedia page that contains all of the information needed to infer the answer. We believe that the long answer identification task — finding all of the information required to infer an answer — requires a deeper level of language understanding than finding short answers once the long answers are known.
It is our hope that the release of NQ, and the associated challenge, will help spur the development of more effective and robust QA systems. We encourage the NLU community to participate and to help close the large gap between the performance of current state-of-the-art approaches and a human upper bound. Please visit the challenge website to view the leaderboard and learn more.
1 A reader just alerted us to DuReader, a dataset from Baidu that contains real queries and full documents. We will add this to our paper, in which we discuss NQ in relation to previous work.↩
