Extract and visualize clinical entities using Amazon Comprehend Medical
Amazon Comprehend Medical is a new HIPAA-eligible service that uses machine learning (ML) to extract medical information with high accuracy. This reduces the cost, time, and effort of processing large amounts of unstructured medical text. You can extract entities and relationships like medication, diagnosis, and dosage, and you can also extract protected health information (PHI). Using Amazon Comprehend Medical allows end users to get value from raw clinical notes that is otherwise largely unused for analytical purposes because it’s difficult to parse. There is immense value associated with extracting information from these notes and integrating it with other medical systems like an Electronic Health Record (EHR) and a Clinical Trial Management System (CTMS). This allows you to generate a longitudinal view of the patient considering information in raw notes that would otherwise be discarded.
As with all our API-level services, the focus of Amazon Comprehend Medical is ease of use for developers. We provide a pre-trained model that can be invoked using an API call or the console. The results are returned as a structured JSON file that can be parsed and integrated with other structural clinical datasets. To know more about Amazon Comprehend Medical, see the product documentation.
In this example, I demonstrate how you can use Amazon Comprehend Medical to extract clinical entities and visualize them on a Kibana dashboard. The solution is provided as an AWS CloudFormation template so you can deploy it easily in your own environments.
Solution architecture
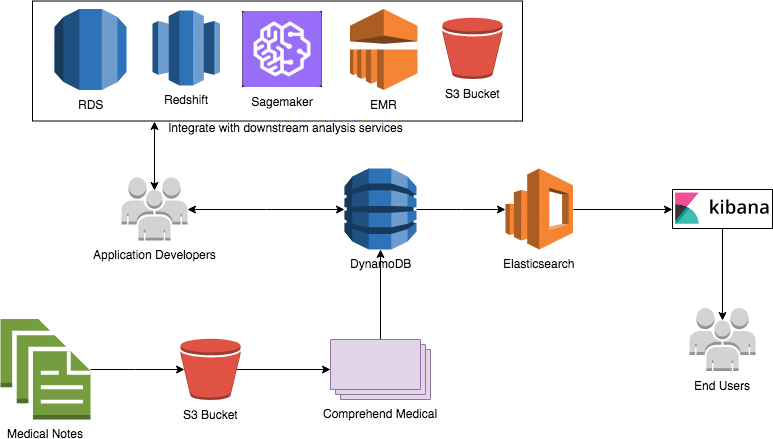
The architecture diagram showcases the various components of the solution. Here are the details of each component:
- You can use Amazon S3 as a platform to store your raw clinical notes.
- Use Amazon Comprehend Medical API to loop through your notes and extract various clinical entities and relationships from the notes. You can also filter the extracted elements to exclude all protected health information (PHI) from the notes. This is useful for use cases that require non-identifiable elements in a note for downstream analysis.
- The extracted entities JSON file is parsed and inserted into an Amazon DynamoDB table. This table can serve as a repository of all clinical entities over time and can be used for downstream integration by developers.
- The DynamoDB table has a stream attached to it. This stream is parsed using an AWS Lambda function that is triggered by an event on the stream.
- The Lambda function inserts the records into an Amazon Elasticsearch Service (Amazon ES) domain. This domain can be kept up to date with all clinical entity information.
- A Kibana dashboard is built on top of Amazon ES to visualize the clinical entities. This will serve as an entry point for end users looking for analytical information and search capabilities on the notes.
Instructions for deploying the solution
We will use an AWS CloudFormation stack to deploy the solution. The CloudFormation stack creates the resources needed by the solution. These include:
- An S3 bucket
- A DynamoDB table
- A Lambda function
- Necessary AWS Identity and Access Management (IAM) roles
This example uses the us-east-1 (N. Virginia) AWS Region.
Log into the AWS Management Console with your IAM username and password. Right click on the “Launch Stack” icon below and open it in a new tab.
![]()
On the Select Template page, choose Next.
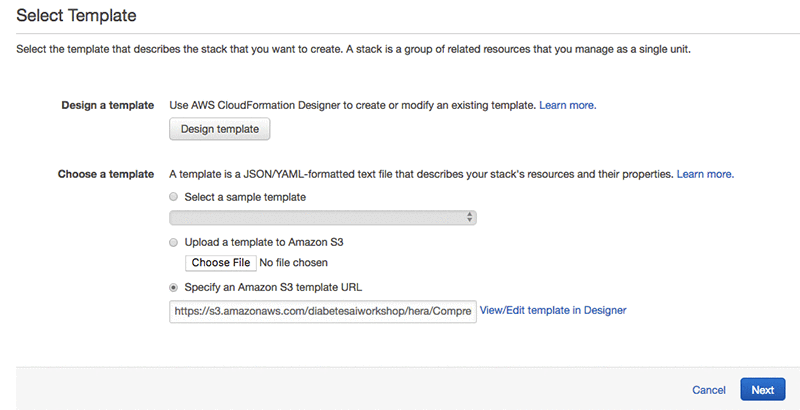
On the next page provide a name for the stack. Enter a name and choose Next.
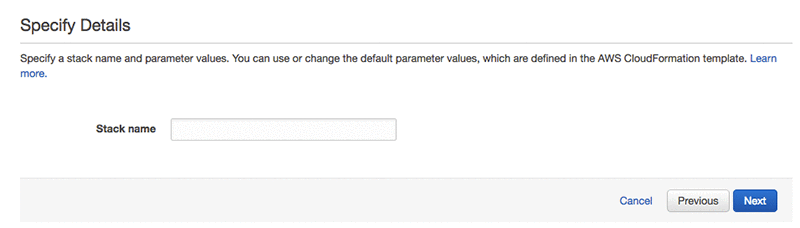
On the options page, leave everything as the default and choose Next.
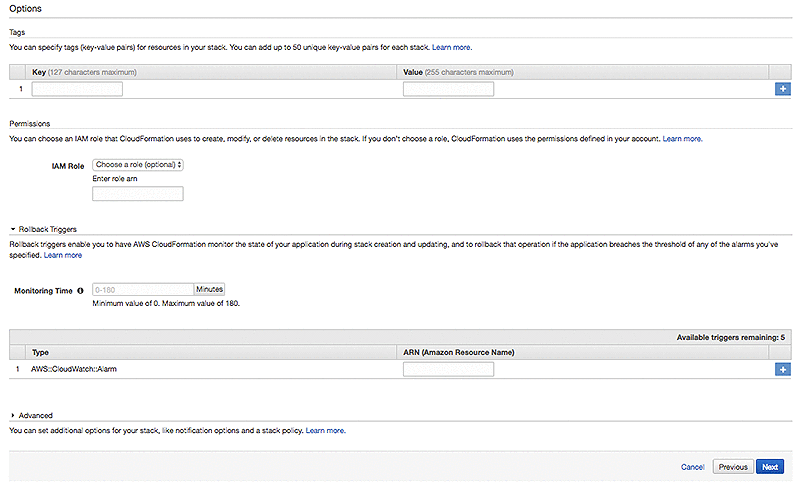
On the Review page, scroll down and select the checkbox “I acknowledge that AWS CloudFormation might create IAM resources wit custom names.” Choose Create.
Wait for the stack to complete executing. You can examine various events from the stack creation process in the Events tab. After the stack creation is complete, look at the Resources tab to see all the resources created by the CloudFormation template. Open the Outputs tab to look at the output of the CloudFormation stack.
Setting up Amazon Elasticsearch Service and AWS Lambda
Now we’ll use Amazon Comprehend Medical to extract entities from a collection of clinical notes and visualize them on a Kibana dashboard.
Log into the AWS Management Console and follow these steps to complete this part of the workshop:
- Open the Amazon Elasticsearch Service. You should see the domain that you created for this example. Choose it.
- On the Overview tab, copy the Endpoint url and paste it on a notepad. You will use this in step 10 below.
- Choose the Modify access policy

- On the Select a template dropdown, select Allow or deny access to one or more AWS accounts or IAM users.

- In the pop-up window, paste the Account ID in the Account ID or ARN textbox. Click Ok

- An access policy will be generated for you automatically. Review it and choose Submit.

- Navigate to the AWS Lambda console.
- On the list of functions, select the function created for the workshop.
- Scroll down to the section that contains the function code.
- On line 13, you will see a variable named host set to the Elasticsearch Host Name. Replace that with the hostname that was copied in step 2, earlier. Make sure to put it between single quotes.

- Choose Save.
Setting up the local environment
You will run a python program to extract entities from raw notes using Amazon comprehend medical and then insert those entities into a DynamoDB table. Before you run this program, you will have to setup your environment. Make sure you have competed the following setup tasks before executing the program:
- Have the AWS command line interface (CLI) installed and configured with an identity and access management (IAM) user with Administrator privileges. Click on this link to see the steps to configure your AWS CLI.
- Create a folder on your computer and download this zip file into it. Unzip the file.
- This will create a new folder Blog_Code. Navigate to the notes folder inside the Blog_Code folder and open up one of the note files and examine its contents to see how the unstructured notes look like. Here is a screenshot of file1.txt.

- Go back to the <> directory and open the python file and paste the name of your DynamoDB table between the single quotes replacing “your_table_name_here” on line 7 as shown in the screenshot below:

- You are now ready to execute the python program. Execute the program by typing:
The program will extract entities from the downloaded notes and insert them into DynamoDB. Once completed, you will see the following message:

Visualizing entitles on Kibana
- On the AWS Management Console, navigate to the DynamoDB console.
- Choose Tables on the left navigation pane.
- Choose the table name created for you by the CloudFormation stack. You can get the name of the table in the Outputs tab of the CloudFormation stack, in the CloudFormation console
- On the Overview tab, you can see the value Latest stream ARN, which denotes that this DynamoDB table has a stream associated with it.
- Choose the Items
- You can see the extracted entities from the notes. We get the attributes like Category, Type and also a confidence score. In addition, we also get a list of attributes and traits associated with the entities.

- Now, let’s visualize these entities in Kibana. To do this, we will use an open source proxy called aws-es-kibana. Please follow the steps on the GitHub repo to install the proxy on your computer.
- Once installed, run the following command:
You can find the domain endpoint in the outputs tab of the CloudFormation stack. You should see the following output:

- Copy the url for Kibana and paste it in your browser window. This will open up the Kibana dashboard. On the Index pattern text box, type lambda-index and choose Create.

- You will see the field and attribute names in Kibana on which we will build some visualizations.

- Kibana provides multiple options to build visualizations that can be integrated into a dashboard. You can experiment with those options in the Visualize and Dashboard links on the left navigation pane of Kibana. To get you started, we have pre-built a dashboard for you as a basic example. Follow these steps to import the dashboard file and visualize the results.
- On the left navigation pane, click Management and then click Saved Objects.

- Click Import on the top right corner and navigate to the Entity_Dashboard.json file under the folder Blog_Code you downloaded and extracted earlier.

- You will see a pop-up message with a question asking if you want to overwrite. Choose Yes, overwrite all.

- You will see another pop-up window saying some index patterns do not exist. Make sure lambda-index is selected in the drop-down Newindex pattern list and click Confirm all changes. You should see a new dashboard called EntityDashboard.

- On the left navigation pane, click Dashboard and then on the EntityDashboard Link. You will see the dashboard with visualizations generated from the extracted entities.

There are three visualizations in the dashboard. The top left visualization aggregates the counts of different categories. As you can see, our sample notes had Medical Condition as the highest category. The top right visualization is a pie chart capturing the distribution of entity types. The bottom visualization is a term cloud that tells you what are the most common terms extracted from the notes. You can experiment with different visualizations and options to build you own visual dashboards.
Conclusion
In the example in this blog post, you saw how to use Amazon Comprehend Medical to extract clinical entities and visualize them on a Kibana dashboard. We foresee many use cases being enabled by this ability to extract entities. Some examples include:
- Patient and Population Health Analytics: Unstructured data is difficult to mine.
Example: Clinical team in the ICU makes over 120 decisions about care per day, How do you keep up? - Revenue Cycle Management: Medical Coding: Process of coding or classifying patient records according to the International Classification of Diseases (ICD) is one of the most complex transactions.
- Pharmacovigilance: Multiple avenues of reporting adverse drug reactions or adverse events.
- PHI Compliance: Difficult to maintain HIPAA compliance and technical requirements for PHI.
- Clinical Trial Management: Identify the right patients for clinical trials quickly.
You can also combine Amazon Comprehend Medical with upstream services like Optical Character Recognition (OCR) systems to extract information from medical forms and pass it to comprehend medical for analysis. For downstream analysis, customers can integrate the output into a clinical data warehouse to improve reporting on Centers for Medicare and Medicaid services (CMS) quality measures.
Amazon Comprehend Medical also enables you to build machine learning models on raw clinical data in EHR systems for common problems like mortality risk prediction and predicting readmissions. These are models that are largely built using structured clinical data and by adding attributes from raw clinical notes can improve the results.
Explore related blog posts discussing Amazon Comprehend Medical:
- Amazon Comprehend Medical – Natural Language Processing for Healthcare Customers
- Identifying and working with sensitive healthcare data with Amazon Comprehend Medical
There are many possibilities, and we are excited to see how you use Amazon Comprehend Medical for your use cases.
Disclaimer: Please keep in mind the following guidelines and limits for Amazon Comprehend Medical. https://docs.aws.amazon.com/comprehend/latest/dg/guidelines-and-limits-med.html
The notes used in this blog post are borrowed from https://www.mtsamples.com/
About the Author
 Ujjwal Is a Principal Machine Learning Specialist Solution Architect in the Global Healthcare and Lifesciences team at Amazon Web Services. He works on the application of machine learning and deep learning to real world industry problems like medical imaging, unstructured clinical text, genomics, precision medicine, clinical trials and quality of care improvement. He has expertise in scaling machine learning/deep learning algorithms on the AWS cloud for accelerated training and inference. In his free time, he enjoys listening to (and playing) music and taking unplanned road trips with his family.
Ujjwal Is a Principal Machine Learning Specialist Solution Architect in the Global Healthcare and Lifesciences team at Amazon Web Services. He works on the application of machine learning and deep learning to real world industry problems like medical imaging, unstructured clinical text, genomics, precision medicine, clinical trials and quality of care improvement. He has expertise in scaling machine learning/deep learning algorithms on the AWS cloud for accelerated training and inference. In his free time, he enjoys listening to (and playing) music and taking unplanned road trips with his family.