Real-time music recommendations for new users with Amazon SageMaker
This is a guest post from Matt Fielder and Jordan Rosenblum at iHeartRadio. In their own words, “iHeartRadio is a streaming audio service that reaches tens of millions of users every month and registers many tens of thousands more every day.”
Personalization is an important part of the user experience, and we aspire to give useful recommendations as early in the user lifecycle as possible. Music suggestions that are surfaced directly after registration let our users know that we can quickly adapt to their tastes and reduce the likelihood of churn. But how do we personalize content to a user that doesn’t yet have any listening history?

This post describes how we leverage the information a user provides at registration to create a personalized experience in real-time. While a new user does not have any listening history, they do typically select a handful of genre preferences and indicate some of their demographic information during the onboarding process. We first show an analysis of these attributes that reveals useful patterns we use for personalization. Next, we describe a model that uses this data to predict the best music for each new user. Finally, we demonstrate how we serve these predictions as recommendations in real-time using Amazon SageMaker immediately after registration, which leads to a significant improvement in user engagement in an A/B test.
New user listening patterns
Before building our model, we wanted to determine if there were any interesting patterns in the data that might indicate that there is something to learn.
Our first hypothesis was that users of different demographic backgrounds would tend to prefer different types of music. For example, perhaps a 50-year-old male is more likely to listen to Classic Rock than a 25-year-old female, all else being equal. If there is any truth to this on average, we may not need to wait for a user to accrue listening history in order to generate useful recommendations — we could simply use the genre preferences and demographic information the user provided at registration.
To perform the analysis, we focused on listening behavior two months after a user registered and compared it with the information given by the user during registration. This two-month gap ensures we focus on active users who have explored our offerings. We should have a pretty good idea of what the user likes by this point in time. It also ensures that most of the noise from initial onboarding and marketing has subsided.
The following diagram shows the timeline of a user’s listening behavior from onboarding until two months after registration.

We then compared distributions of listening across genres of our new male users vs. our new female users. The results confirm our hypothesis that there are patterns in music preferences that correlate with demographic information. For example, you’ll notice that Sports and News & Talk are more popular with males. Using this data is likely to improve our recommendations, especially for users that don’t yet have listening history.
The following graph summarizes user gender as it relates to preferred genres.

Our second hypothesis was that users with similar tastes might express what genres they’re looking for differently. Moreover, iHeartRadio might have a slightly different definition of a genre as compared to how our users perceive that genre. This indeed seemed to be the case for certain genres. For example, we noticed that many users told us they like R&B music when in fact they listened to what we classify internally as Hip Hop. This is more a function of genres being somewhat subjective, in which different users have different definitions for the same genre.
Predicting genres
Now that we had some initial analytical evidence that demographics and genre preferences are useful in predicting new user behavior, we set out to build and test a model. We hoped that a model could systematically learn how demographic background and genre preferences relate to listening behavior. If successful, we could use the model to surface the correct genre-based content when a new user onboards to our platform.
As in the analysis phase, we defined a successful prediction as the ability to surface content the user would have naturally engaged with two months after signing up. As a result, users that go into the training data for our model are active listeners that have had the time to explore the offerings in our app. Thus, the target variable is the top genre a user listens to two months after registration, and the features are the user’s demographic attributes and combination of genres selected during registration.
As in most modeling exercises, we started with the most basic modeling technique, which in this case was multi-label logistic regression. We analyzed a sampling of the feature coefficients from the trained model and their relationship with subsequent listening in the following heat map. The non-demographic model features are the multi-hot encoding of genres that the user selected during onboarding. The brighter the square (i.e. larger weight), the more correlated a model feature is with the genre the user listens to in the second month after registration.

Sure enough, we were able to identify some initial patterns. First, we found that on the whole, when a user selects only 1 genre, they end up listening to that genre. However, for users who select certain genres such as Kids & Family, Mix & Variety, or R&B, the trend is more muted. Second, it’s interesting to note that when looking at age, our model learns that younger users tend to prefer Top 40 & Pop and Alternative whereas older users prefer International, Jazz, News & Talk, Oldies, and Public Radio. Third, we were fascinated by the fact the model could learn that users who select classical music also tend to listen to World, Public Radio, and International genres.
Although useful to explore how our features relate to listening behavior, logistic regression has several drawbacks. Perhaps most importantly, it does not naturally handle the case in which users select more than one genre, because interactions in a linear model are implicitly additive. In other words, it can’t weigh the interactions across genre selections appropriately. For us, this is a major issue because users that do reveal their genre preferences typically select more than one; on average users select around four genres.
We explored a few more advanced techniques such as tree-based models and feed-forward neural networks that would make up for the shortcomings of logistic regression. We found that tree-based methods gave us the best results while also having limited complexity as compared to the neural networks we built. They also gave us meaningful lifts as compared to logistic regression and were less prone to overfitting the training set. In the end, we decided on using LightGBM given its speed, ability to prevent overfitting, and superior performance.
We were excited to see that the offline metrics of our model were significantly better than our simple baseline. The baseline recommendation for a user is the most popular genre that they selected, regardless of their demographic membership, which is how our live content carousels have worked in the app historically. We found that sending new users three genre-based model recommendations capture their actual preferred genre 77% of the time, based on historical offline data. This corresponds to a 15% lift as compared to the baseline.
Surfacing predictions in real-time
Now that we have a model that seems to work, how do we surface these predictions in real-time? Historically at iHeartRadio, most of our models had been trained and scored in batch (e.g. daily or weekly) using Airflow and served from a key-value database like Amazon DynamoDB. In this case, however, our new user recommendations only provide value if we score and serve them in real-time. Immediately after the user registers, we have to be ready to serve appropriate genre-based predictions to the user based on registration information that of course we don’t know in advance. If we wait until the next day to serve these recommendations, it’s too late. That’s where Amazon SageMaker comes in.
Amazon SageMaker allows us to host real-time model endpoints that can surface predictions for users immediately after registration. It also offers convenient model training functionality. It allows for a few options to deploy models, ranging from using an existing built-in algorithm container (such as random forest or XGBoost), using pre-built container images, extending a pre-built container image, or building a custom container image. We decided to go with the last option of packaging our own algorithm into a custom image. This gave us the most flexibility because, as of this writing, a built-in algorithm container for LightGBM does not exist. Therefore, we packaged our own custom scoring code and built a Docker image that was pushed to Amazon Elastic Container Registry (Amazon ECR) for use in model scoring.
We masked the Amazon SageMaker endpoint behind an Amazon API Gateway so external clients could ping it for recommendations, while leaving the Amazon SageMaker backend secure in a private network. The API Gateway passes the parameter values to an AWS Lambda function, which in turn parses the values and sends them to the Amazon SageMaker endpoint for a model response. Amazon SageMaker also allows for automatic scaling of model scoring instances based on the volume of traffic. All we need to define is the desired number of requests per second for each instance and a maximum number of instances to scale up to. This makes it easy to roll-out the use of our endpoint to any variety of use-cases throughout iHeartRadio. In the 10 days we ran the test, our endpoint had 0 invocation errors and an average model latency of around 5 milliseconds.
For more information about Amazon SageMaker, see Using Your Own Algorithms or Models with Amazon SageMaker, Amazon SageMaker Bring Your Own Algorithm Example, and Call an Amazon SageMaker model endpoint using Amazon API Gateway and AWS Lambda.
Online results
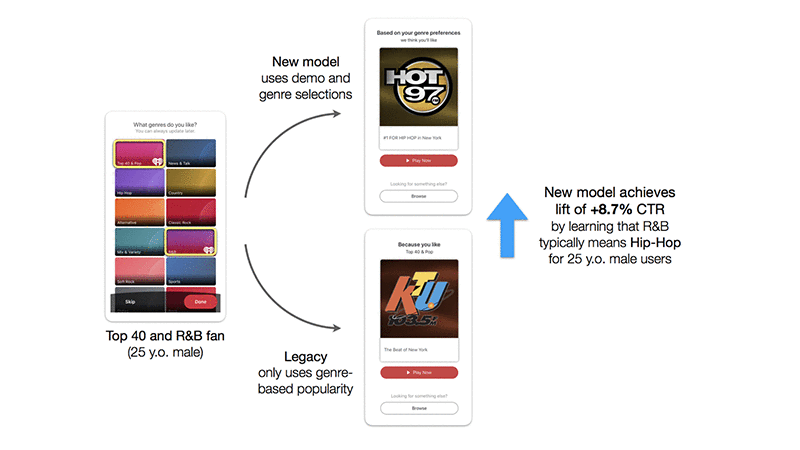
We showed above that our model performed well in offline tests, but we also had to put it to the test in our production app. We tested it by using our model hosted on Amazon SageMaker to recommend a relevant radio station to our new users in the form of an in-app-message directly after registration. We compared this model to business rules that would simply recommend the most popular radio station that was classified into one of the user-selected genres. We ran the A/B test for 10 days with an even split between the groups. The group of users hit with our model predictions had an 8.7% higher click-through rate to the radio station! And of the users who did click, radio listening time was just as strong.
The following diagram shows the real-time predictions result in an 8.7% lift in CTR over the baseline and an example of what the A/B testing groups would have looked like.
Next steps and future work
We’ve shown that new users respond to the relevant content served by our genre prediction model hosted on an Amazon SageMaker endpoint. In our initial proof-of-concept, we introduced the treatment to only a portion of our new registrants. Next steps include expanding this test to a larger user-base and surfacing these recommendations by default in our content carousels for new users with little to no listening history. We also hope to expand the use of these types of models and real-time predictions to other personalization use-cases, such as the ordering of various content carousels and tiles throughout our app. Lastly, we are continuing to explore technologies that allow for seamlessly serving model predictions in real-time including Amazon SageMaker as described in this post as well as others such as FastAPI.
Thanks go out to the Data Science and Data Engineering teams for their support throughout testing the Amazon SageMaker POC and helpful feedback on the post, especially Brett Vintch and Ravi Theja Mudunuru. This post is also available from iHeartMedia on Medium.
About the authors
Matt Fielder is the EVP Engineering at iHeartRadio
Jordan Rosenblum is a Senior Data Scientist at iHeartRadio Digital