NVIDIA Shows Its Prowess in First AI Inference Benchmarks
Those who are keeping score in AI know that NVIDIA GPUs set the performance standards for training neural networks in data centers in December and again in July. Industry benchmarks released today show we’re setting the pace for running those AI networks in and outside data centers, too.
NVIDIA Turing GPUs and our Xavier system-on-a-chip posted leadership results in MLPerf Inference 0.5, the first independent benchmarks for AI inference. Before today, the industry was hungry for objective metrics on inference because its expected to be the largest and most competitive slice of the AI market.
Among a dozen participating companies, only the NVIDIA AI platform had results across all five inference tests created by MLPerf, an industry benchmarking group formed in May 2018. That’s a testament to the maturity of our CUDA-X AI and TensorRT software. They ease the job of harnessing all our GPUs that span uses from data center to the edge.
MLPerf defined five inference benchmarks that cover three established AI applications — image classification, object detection and translation. Each benchmark has four aspects. Server and offline scenarios are most relevant for data center uses cases, while single- and multi-stream scenarios speak to the needs of edge devices and SoCs.

NVIDIA topped all five benchmarks for both data center scenarios (offline and server), with Turing GPUs providing the highest performance per processor among commercially available products.
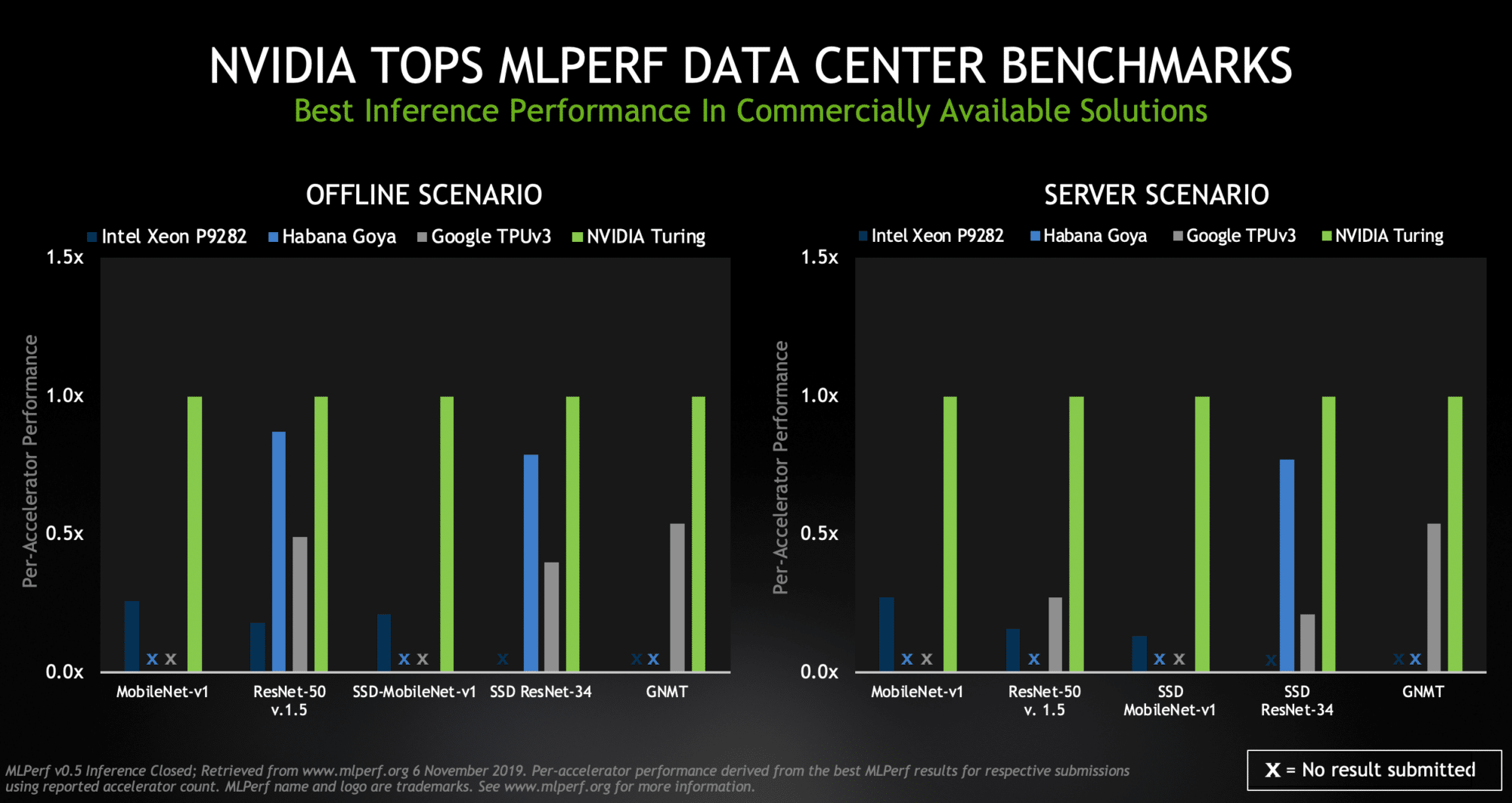
The offline scenario represents data center tasks such as tagging photos, where all the data is available locally. The server scenario reflects jobs such as online translation services, where data and requests are arriving randomly in bursts and lulls.
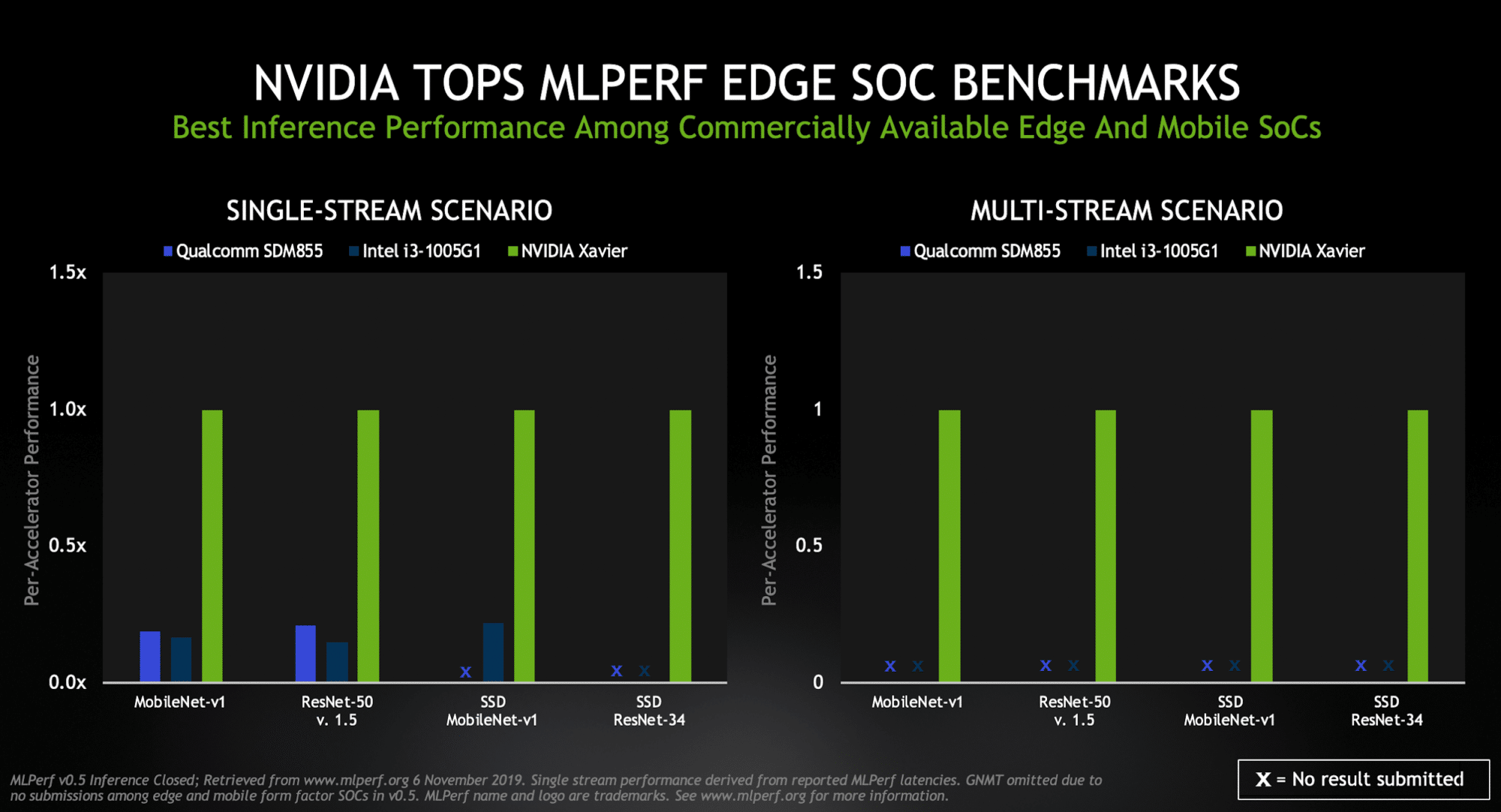
For its part, Xavier ranked as the highest performer under both edge-focused scenarios (single- and multi-stream) among commercially available edge and mobile SoCs.
An industrial inspection camera identifying defects in a fast-moving production line is a good example of a single-stream task. The multi-stream scenario tests how many feeds a chip can handle — a key capability for self-driving cars that might use a half-dozen cameras or more.
The results reveal the power of our CUDA and TensorRT software. They provide a common platform that enables us to show leadership results across multiple products and use cases, a capability unique to NVIDIA.
We competed in data center scenarios with two GPUs. Our TITAN RTX demonstrated the full potential of our Turing-class GPUs, especially in demanding tasks such as running a GNMT model used for language translation.
The versatile and widely used NVIDIA T4 Tensor Core GPU showed strong results across several scenarios. These 70-watt GPUs are designed to easily fit into any server with PCIe slots, enabling users to expand their computing power as needed for inference jobs known to scale well.
MLPerf has broad backing from industry and academia. Its members include Arm, Facebook, Futurewei, General Motors, Google, Harvard University, Intel, MediaTek, Microsoft, NVIDIA and Xilinx. To its credit, the new benchmarks attracted significantly more participants than two prior training competitions.
NVIDIA demonstrated its support for the work by submitting results in 19 of 20 scenarios, using three products in a total of four configurations. Our partner Dell EMC and our customer Alibaba also submitted results using NVIDIA GPUs. Together, we gave users a broader picture of the potential of our product portfolio than any other participant.
Fresh Perspectives, New Products
Inference is the process of running AI models in real-time production systems to filter actionable insights from a haystack of data. It’s an emerging technology that’s still evolving, and NVIDIA isn’t standing still.
Today we announced a low-power version of the Xavier SoC used in the MLPerf tests. At full throttle, Jetson Xavier NX delivers up to 21 TOPS while consuming just 15 watts. It aims to drive a new generation of performance-hungry, power-pinching robots, drones and other autonomous devices.
In addition to the new hardware, NVIDIA released new TensorRT 6 optimizations used in the MLPerf benchmarks as open source on GitHub. You can learn more about the optimizations in this MLPerf developer blog. We continuously evolve this software so our users can reap benefits from increasing AI automation and performance.
Making Inference Easier for Many
One big takeaway from today’s MLPerf tests is inference is hard. For instance, in actual workloads inference is even more demanding than in the benchmarks because it requires significant pre- and post-processing steps.
In his keynote address at GTC last year, NVIDIA founder and CEO Jensen Huang compressed the complexities into one word: PLASTER. Modern AI inference requires excellence in Programmability, Latency, Accuracy, Size-of-model, Throughput, Energy efficiency and Rate of Learning, he said.
That’s why users are increasingly embracing high-performance NVIDIA GPUs and software to handle demanding inference jobs. They include a who’s who of forward-thinking companies such as BMW, Capital One, Cisco, Expedia, John Deere, Microsoft, PayPal, Pinterest, P&G, Postmates, Shazam, Snap, Shopify, Twitter, Verizon and Walmart.
This week, the world’s largest delivery service — the U.S. Post Service— joined the ranks of organizations using NVIDIA GPUs for both AI training and inference.
Hard-drive maker Seagate Technology expects to realize up to a 10 percent improvement in manufacturing throughput thanks to its use of AI inference running on NVIDIA GPUs. It anticipates up to a 300 percent return on investment from improved efficiency and better quality.
Pinterest relies on NVIDIA GPUs for training and evaluating its recognition models and for performing real-time inference across its 175 billion pins.
Snap uses NVIDIA T4 accelerators for inference on the Google Cloud Platform, increasing advertising effectiveness while lowering costs compared to CPU-only systems.
A Twitter spokesman nailed the trend: “Using GPUs made it possible to enable media understanding on our platform, not just by drastically reducing training time, but also by allowing us to derive real-time understanding of live videos at inference time.”
The AI Conversation About Inference
Looking ahead, conversational AI represents a giant set of opportunities and technical challenges on the horizon — and NVIDIA is a clear leader here, too.
NVIDIA already offers optimized reference designs for conversational AI services such as automatic speech recognition, text-to-speech and natural-language understanding. Our open-source optimizations for AI models such as BERT, GNMT and Jasper give developers a leg up in reaching world-class inference performance.
Top companies pioneering conversational AI are already among our customers and partners. They include Kensho, Microsoft, Nuance, Optum and many others.
There’s plenty to talk about. The MLPerf group is already working on enhancements to its current 0.5 inference tests. We’ll work hard to maintain the leadership we continue to show on its benchmarks.
- MLPerf v0.5 Inference results for data center server form factors and offline and server scenarios retrieved from www.mlperf.org on Nov. 6, 2019, from entries Inf-0.5-15,Inf-0. 5-16, Inf-0.5-19, Inf-0.5-21. Inf-0.5-22, Inf-0.5-23, Inf-0.5-25, Inf-0.5-26, Inf-0.5-27. Per-processor performance is calculated by dividing the primary metric of total performance by number of accelerators reported.
- MLPerf v0.5 Inference results for edge form factors and single-stream and multi-stream scenarios retrieved from www.mlperf.org on Nov. 6, 2019, from entries Inf-0.5-24, Inf-0.5-28, Inf-0.5-29.
The post NVIDIA Shows Its Prowess in First AI Inference Benchmarks appeared first on The Official NVIDIA Blog.