Optimizing portfolio value with Amazon SageMaker automatic model tuning
Financial institutions that extend credit face the dual tasks of evaluating the credit risk associated with each loan application and determining a threshold that defines the level of risk they are willing to take on. The evaluation of credit risk is a common application of machine learning (ML) classification models. The determination of a classification threshold, though, is often treated as a secondary concern and set in an ad hoc, unprincipled manner. As a result, institutions may be creating underperforming portfolios and leaving risk-adjusted return on the table.
In this blog post, we describe how to use Amazon SageMaker automatic model tuning to determine the classification threshold that maximizes the portfolio value of a lender choosing a subset of borrowers to lend to. More generally, we describe a method of choosing an optimal threshold, or set of thresholds, in a classification setting. The method we describe doesn’t rely on rules of thumb or generic metrics. It is a systematic and principled method that relies on a business success metric specific to the problem at hand. The method is based upon utility theory and the idea that a rational individual makes decisions so as to maximize her expected utility, or subjective value.
In this post, we assume that the lender is attempting to maximize the expected dollar value of her portfolio by choosing a classification threshold that divides loan applications into two groups: those she accepts and lends to, and those she rejects. In other words, the lender is searching over the space of potential threshold values to find the threshold that results in the highest value for the function that describes her portfolio value.
This post uses Amazon SageMaker automatic model tuning to find that optimal threshold. The accompanying Jupyter notebook demonstrates the code supporting this use case. This is a novel use of the automatic model tuning functionality, which is typically used to choose the hyperparameters that optimize model performance. This post uses it as a general tool to maximize a function over some specific parameter space.
This approach has several advantages over the typical threshold determination approach. Typically, a classification threshold is set (or allowed to default) to 0.5. This threshold doesn’t generate the maximum possible result in the majority of use cases. In contrast, the approach described here chooses a threshold that generates the maximum possible result for the specific business use case being addressed. In the use case in this post, choosing the optimal threshold in the way we describe increases portfolio value by 2.1%.
Also, this approach moves beyond using general rules of thumb and expert judgment in determining an optimal threshold. It lays out a structured framework that can be systematically applied to any classification problem. Additionally, this approach requires the business to explicitly state its cost matrix based on the specific actions to be taken on model predictions and their benefits and costs. This evaluation process moves well beyond simply assessing the classification results of the model. This approach can drive challenging discussions in the business, and force differing implicit decisions and valuations onto the table for open discussion and agreement. This drives the discussion from a simple “maximize this value”, to a more informative analysis that allows more complex economic trade-offs, which provides more value back to the business.
| About this blog post | |
| Time to read | 20 minutes |
| Time to complete | 1.5 hours |
| Cost to complete | ~ $2 |
| Learning level | Advanced (300) |
| AWS services | Amazon SageMaker |
Background
Assume that a lender is attempting to construct a portfolio from a pool of potential loans. To tackle this use case, the lender must first assess the credit risk associated with each loan in the pool by calculating a probability of default for each loan; the higher the probability of default associated with a loan, the higher the credit risk associated with a loan. To calculate a loan’s probability of default, the lender uses an ML classification model, such as a logistic regression or random forest.
Given that the lender has estimated a default probability model, how does she choose the threshold that sets the maximum default probability that a loan can have and she be willing to extend the loan? Users of classification models often set the value of a threshold to the conventional default value of 0.5. Even if they do attempt to set a use case-specific threshold, they do so based upon maximizing some threshold-based metric such as precision or recall. One issue with these metrics is that they ignore certain parts of the discrete outcomes described in the classification matrix. For example, precision overlooks true and false negative outcomes. Additionally, these metrics do not incorporate the dollar costs and benefits associated with each cell of the classification matrix. For example, in the case we examine in this post, the interest rate and loss given a default associated with each loan would be ignored in the calculation of typical threshold-based measures. This situation is less than ideal because, ultimately, what a business values is not the precision or recall of its model, but the dollar value of the incremental profit from using a specific model and threshold.
Therefore, instead of using a generic metric, it is likely more profitable and meaningful to the business to design a threshold-based metric that captures the cost and benefit structure of the specific business use case at hand. The lender we describe in this post is deciding whether to lend or not to set of borrowers. Therefore, a metric that incorporates the expected interest earned and losses from each loan given a predicted probability of default is much more relevant to the business and its decision-making process than some generic metric such as precision or recall. Specifically, the portfolio value metric that we define classifies each loan into one of four buckets: True Positive (TP), False Negative (FN), True Negative (TN), and False Positive (FP); and then calculates the value of each bucket of loans using the following guidelines:
TP value = -Fixed_Cost
FN value = -Fixed_Cost – Loss_Given_Default * Outstanding_Principal_Balance
TN value = -Fixed_Cost + Interest_Rate * Outstanding_Principal_Balance
FP value = -Fixed_Cost
Fixed_Cost captures the costs associated with processing a loan, whether it is approved or not.
Outstanding_Principal_Balance is the principal remaining at the time of default or full repayment.
Interest_Rate is a borrower-specific rate that is set based upon the probability of default associated with a specific loan application plus the expected return desired by the lender.
Loss_Given_Default is the proportion of principal expected to be lost if a loan defaults.
To calculate the total value of a specific bucket of loans, the value of all loans is summed. This total is what the lender is attempting to maximize by choosing a threshold.
Once the lender has clearly defined a quantitative measure of portfolio value, she must then choose the threshold that maximizes that measure. We use Amazon SageMaker automatic model tuning to find the optimal threshold. Amazon SageMaker automatic model tuning is a powerful tool for not only tuning the hyperparameters of an ML model, but also for maximizing an arbitrary function. In this case, we use automatic model tuning in two ways:
- Finding the choice of a threshold that maximizes the lender’s portfolio value.
- Mapping out the relationship between threshold and portfolio value more generally.
Understanding the relationship between the threshold choice and portfolio value allows us to more fully understand the economic trade-offs of increasing or decreasing the threshold. This is important as lenders frequently want to consider additional goals beyond simply maximizing the dollar value of their portfolio. Some lenders have idiosyncratic, secondary goals. For example, a lender may want to maximize her portfolio value while also emphasizing lending to a particular sector of the economy or certain subgroup of the overall population. Knowing how the portfolio’s value changes when the threshold moves allows the lender to set a reasonable threshold that addresses both her primary goal of portfolio maximization and her additional secondary goals.
We make several assumptions in this work. We assume that the lender has access to the capital necessary to extend all the loans associated with default probabilities below a chosen threshold. The problem is unconstrained in that sense. Additionally we assume that if a loan is approved, the applicant accepts the terms of the loan no matter what interest rate the lender offers. Lastly, we assume that the lender is risk-neutral, that is, we assume that the lender’s utility function is the identity function. In other words, the utility that a lender gains from a certain portfolio value is equal to the portfolio value itself.
The Amazon SageMaker notebook containing the executable code is available on this GitHub repo. You need to run this notebook within an Amazon SageMaker notebook instance to use Amazon SageMaker automatic model tuning. To do this, download the Jupyter notebook associated with this post from the preceding GitHub link. Create an Amazon SageMaker notebook instance and upload the Jupyter notebook onto this notebook instance. Lastly, open the notebook and step through the code. For more information, see Create a Notebook Instance. This post provides an HTML version so that you can review the code without needing to execute it.
Solution overview
The next sections walk through the following steps:
- Preparing a set of loan data for model training.
- Training a random forest classifier using the Amazon SageMaker built-in Scikit-learn Estimator.
- Analyzing the performance of the initial model.
- Using automatic model tuning to find the threshold that gives the highest portfolio value.
- Analyzing portfolio performance compared to the portfolio that uses the default threshold.
- Incorporating additional business goals and analyzing their impact on the portfolio.
Loan data
The data consists of a set of US Small Business Administration (SBA)-guaranteed loans from 1987 to 2014. These are loans extended to US-based small businesses by private banks, though the US SBA guarantees a large percentage of the principal in the event of borrower default. On average, the SBA guarantees about 70% of the principal for each of the loans in this dataset. This sizable guarantee offsets much of the credit risk associated with each loan and encourages private banks to extend credit to small businesses to which they might not otherwise. For the data itself, and a more detailed description of the data, see the supplementary material of Li, Mickel, and Taylor. You should also read the license associated with the use of this research paper.
Our goal is to construct a model that predicts the probability that a specific loan will default, thus the target variable is MIS_Status. MIS_Status takes on two values: “P I F” if a loan has been paid in full, or “CHGOFF” if a loan has defaulted and the bank has taken the resulting loss.
The accompanying notebook shows that the target variable is imbalanced—about 18% of the observations have defaulted. Our approach in dealing with this imbalance is to estimate the model with the data as-is, and then set the decision threshold to optimize the economic value of our credit portfolio.
Training the model
Next we train a random forest classifier using the Amazon SageMaker built-in Scikit-learn estimator. We chose a random forest after comparing its performance to both that of a Logistic Regression and a Gradient Boosted Classifier. With the Amazon SageMaker built-in estimator, you can build and deploy custom Scikit-learn models without needing to create and manage a custom Docker container.
For more information, see Using Scikit-learn with the Amazon SageMaker Python SDK.
For the code detailing the training of the random forest, see the “Training the Model” section of the notebook associated with this post.
Analyzing model performance (part 1)
For comparison, we create a naïve model, classifying all observations to the majority class, that is, predicting that no loans will default. Does the random forest perform better than the naive model?
We have not yet determined the optimal threshold to classify the prediction of the random forest model into default or non-default classes. Therefore, the only performance metrics available to us to answer the above question are those based upon the predicted class probabilities output by our model. Metrics based on class predictions, for example, accuracy, precision or recall, are dependent on our as-yet-undefined threshold. So to answer this question initially, we compare the log loss of the random forecast and naive models. Log loss calculates how far predicted class probabilities are off from the true labels. Therefore, log loss is metric that can be determined without reference to a threshold.
We will more thoroughly analyze model performance, using the more familiar threshold-based metrics, after we have calculated the optimal threshold.
Calculating log loss
Does the random forest perform better than the naive model? Remember that a smaller log loss indicates a smaller error and better performance. The following output from the model runs shows the results:
The answer is yes, the random forest improves on the log loss of the naive model by a significant amount. This implies that the random forest model assigned predicted class probabilities to each observation that are much closer to the truth than the naive model’s predictions.
Plotting the model predictions
In each of the following plot sets, the top histogram plots the distribution of predicted scores for all actual negatives, that is, the predicted scores for borrowers that do not default. In essence, it represents the score distributions associated with specificity. The bottom histogram plots predicted scores for actual positives, that is, the predicted scores for borrowers that do default, thus representing the score distributions for sensitivity.
The correctly classified observations on each plot are colored blue, and the incorrectly classified observations are colored orange. We use the default threshold value of 0.5 to color these plots. This is the typical threshold used to classify the results of a classification model, chosen without attempting to maximize the user’s success—or value—metric.
The threshold choice does not affect the actual predicted scores, shape, or level of the plots, only the coloring. It does, however, effect metric results, including sensitivity, specificity, and most commonly used model performance metrics.
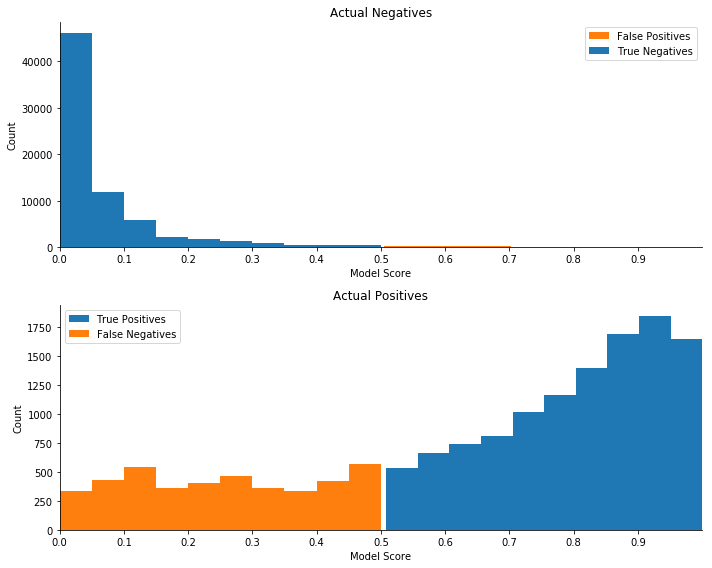
These two graph shows that while the scores for the true negatives are clustered close to 0, the scores for the false negatives are distributed relatively evenly from 0 to the current cutoff at 0.5. The dataset doesn’t include data items that would allow strong discrimination between true and false negatives.
This distribution may point to a significant amount of potential income being missed from this portfolio of approved and rejected loans. Using the default threshold score of 0.5 for approving a loan is not optimal for this dataset. Let’s explore how the portfolio value can be further increased by optimizing the threshold.
Calculating portfolio value based upon a 0.5 threshold
Lastly, we calculate the portfolio values for the naive model and the random forest model based upon a 0.5 threshold. These portfolio values act as reference points to determine if choosing an optimal threshold increases the value of the loan portfolio.
Note that any non-zero threshold results in the same portfolio value in the naive model because the probability of default for all loans is 0. The following output shows the calculated portfolio values:
Determining the optimal classification threshold with automatic model tuning
Could we do even better, by choosing a different threshold? And how do we go about finding the optimal threshold to balance the lender’s risk and reward?
In this section, the optimal threshold for classifying loans as default or non-default is determined with Amazon SageMaker automatic model tuning. The optimal threshold is the threshold that maximizes the user’s value metric. In this case, the metric that is being maximized is total portfolio value, as described previously.
To use Amazon SageMaker automatic model tuning to optimize the classification threshold, we construct a Docker container that takes the random forest model trained previously and the test set as input. Given a threshold, the container calculates the total value of the portfolio if the lender extended all loans classified as non-default, and the borrower accepted them. Amazon SageMaker automatic model tuning generates a range of thresholds between 0 and 1 and chooses the threshold that maximizes portfolio value. For the code detailing the automatic model tuning job, see the “Determining the Optimal Classification Threshold with Automatic Modeling Tuning” section of the notebook associated with this post.
Running the automatic model tuning job
To use the Amazon SageMaker automatic model tuning feature, we first need to define the metric that we want Amazon SageMaker to optimize, the parameter space we want the tuning job to search over to find the optimal threshold, and any additional metrics we want calculated during the tuning job.
In the notebook associated with this blog post, we define the metrics we wish each job to return. As we’d like to explore the characteristics of the portfolio generated in some detail, we generate a list of metrics that describe the approved and rejected loans. These metrics are reported from each training job that runs via automatic model tuning. The additional metrics allow us to explore the characteristics of the maximized portfolio.
Of all the metrics we define, we need to specify which metric the automatic model tuning job should use to optimize the threshold. We do this by specifying the objective_metric_name in the following HyperparameterTuner object. In the same object, we specify the hyperparameter range to search over; in this case, we specify all continuous values between 0 and 1 to search over for the optimal threshold.
Lastly, we specify that we want Amazon SageMaker to run 200 individual training jobs. Each of these 200 training jobs uses a specific threshold value to calculate a different portfolio value. After Amazon SageMaker calculates the 200 portfolio values, each based upon a different threshold, it outputs the threshold that maximizes portfolio value.
This job takes up to 1 hour to run.
Analyzing model performance (part 2)
In this section, we continue analyzing the performance of the naive and random forest models, but now that we have determined the optimal threshold, we are able to incorporate threshold-based metrics in the analysis.
Plotting the automatic model tuning job results
The flatness in the following scatter plots is due to the precision of predictions, which is a function of the number of trees in the random forest model. Because there are 100 trees in the random forest model, the precision of the predictions is two decimal places. This implies that all thresholds, for example, >.32 and <=.33, give the same result.
Plotting prediction distributions given the optimal threshold
Now that we know the optimal threshold, we are able to plot the probability predictions of the random forest model and classify each as correct or incorrect. The top histogram plots the distribution of predicted scores for all actual negatives, that is, predicted scores for actual non-defaulters. The bottom histogram plots predicted scores for actual defaulters. The correctly classified observations on each plot are blue, and the incorrectly classified observations are orange.
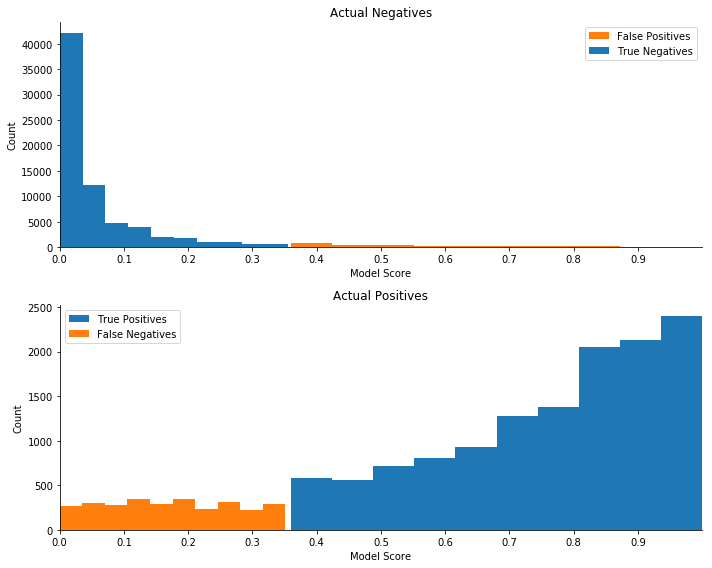
The plot shows that the optimal threshold is below 0.5 and to the left of the bulk of the actual positives. The threshold seems to be at the point where the rate of change of true negatives as the threshold increases is slowing and the rate of change of false negatives is speeding up. The automatic model tuning job seems to have chosen a threshold that balances the two rates of change. To better understand the choice of optimal threshold, we would need to dig deeper into the portfolio value calculation and understand the costs and benefits associated with a change in threshold.
Determining maximum portfolio value
The following graphs plot the output of the automatic model tuning job. That is, they plot the portfolio value (on the y-axis) given a specific threshold (on the x-axis). Each point on a plot represents the outcome of a single training job from the overall automatic model tuning job. Recall that the goal is to find the classification threshold that optimizes the overall portfolio value. In each plot, the optimal threshold is the vertical, orange line.
The graph on the far left plots all 200 training job outcomes. The middle graph plots the top 100 training jobs as ranked by portfolio value, and the far-right graph plots the top 50 training jobs, also ranked by portfolio value.
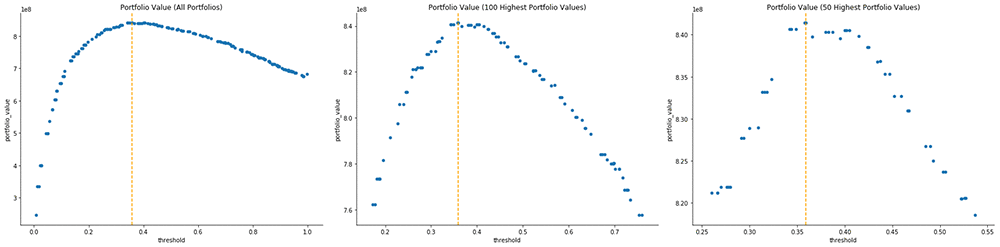
Interestingly, the magnitude of the rate of change as we increase the threshold beyond its optimum value is generally much lower than the magnitude of the rate of change as we increase the threshold from 0 to its optimal value. This asymmetry is due to the SBA guarantee. The guarantee limits the downside risk that the lender takes on as she loosens her borrowing standards. If the SBA guarantee were not in place, we would expect the right side of this graph to decrease much more steeply.
Looking at the right two graphs, we zoom in on the peak of the curve and see that it is more symmetric around the optimal threshold. Additionally, the curve is not strictly decreasing after the optimal threshold; at times, the curve increases briefly. The following output shows the portfolio values for each model:
The top portfolio value returned from the random forest model with an optimized threshold is higher than both that generated by the naive model and by the random forest model with a 0.5 threshold. The increased portfolio value by adjusting the threshold is $17.7M, or 2.1%—a substantial increase in potential return.
Interestingly, the optimal threshold is less than 0.5, so the lender can increase the overall value of her portfolio by decreasing the credit risk of the loans in the portfolio (by decreasing the threshold). If the lender had used a 0.5 threshold (the typical default value), she would likely have created a portfolio likely with more credit risk and lower portfolio value. If the SBA guarantee were not in place for these loans, the portfolio value at a threshold of 0.5 would likely have been much lower.
Analyzing the return associated with maximum portfolio value
This section shifts from focusing on the dollar return of the portfolio to the percentage return. The following set of graphs is similar to the previous set except that the graphs plot the net return on the portfolio associated with each of the 200 training jobs in the automatic model tuning run. The orange, vertical line is again the optimal threshold—optimal in the sense of maximizing portfolio value, not portfolio return—and the x-axis is the threshold. The y-axis is the portfolio return.

From left to right, these graphs plot all 200 training job outcomes, the top 100 outcomes (based upon portfolio values), and the top 50 outcomes (based upon portfolio values). These return curves are much flatter than the portfolio value curves in the previous set of graphs. This is because the lender actively set interest rates on each of the loans she extends so that the return on the overall portfolio is expected to be about 5%. Additionally, note that the optimal threshold does not mark the peak in portfolio return. This is because, when maximizing portfolio value, it doesn’t matter whether adding more loans increases the percentage return on the portfolio, only that adding more loans adds to the dollar return on the portfolio. We can add lower percentage return loans to the portfolio and still add positive value in dollar terms, and that is what we are attempting to maximize.
The following output shows the results of calculating the return:
Likewise, the portfolio return from the random forest model with an optimized threshold is much higher than that generated by the naive model, though the returns from the two random forest models are similar. This is because in both of those models, the lender can set borrower-specific interest rates to compensate for borrower-specific levels of credit risk. If the threshold increases and higher risk loans enter the portfolio, the lender can set higher interest rates on those loans and on average keep her return the same.
Adjusting the optimal threshold based upon additional business considerations
Now we investigate how to determine if we should make marginal adjustments to the optimal threshold. Why would we want to adjust the optimal threshold calculated previously? There may be certain idiosyncratic goals that a lender wants to achieve that a generic portfolio value calculation doesn’t capture. For example, a lender may want to maximize her portfolio value while also emphasizing lending to a certain sector of the economy or subgroup of the overall population. Adding this additional constraint to the portfolio value calculation itself may be difficult, if not impossible. Tackling these problems in two steps—finding the generic optimum and then adjusting that optimum based upon idiosyncratic preferences—is likely much easier and more intuitive of a calculation.
As an example, say that the lender would like to extend more credit to the Construction sector of the economy. She wishes to determine if she should increase the optimal threshold to achieve this goal. Essentially she needs to determine the price she is willing to pay to include one more Construction sector loan in the portfolio, and the effect on portfolio value of including that loan. If the price is greater than the cost, then she should increase the threshold.
More specifically, to answer the question of whether the lender should increase the threshold by 0.01 (the smallest increment possible in our case), she needs to do the following:
- Determine the price P that she is willing to pay for each additional Construction loan.
- Calculate the decrease in portfolio value resulting from increasing the threshold by 0.01.
- Calculate the number of Construction sector loans added to the portfolio when the threshold increases.
- Calculate the average cost of each additional Construction loan by dividing the change in portfolio value by the number of Construction loans added. This is the mean cost C of each additional Construction loan in dollar terms.
- Compare price P that the lender is willing to pay for each additional Construction to the cost C that she must actually pay for each additional Construction loan.
- If the willingness-to-pay price is greater than the cost (P >= -C), increase the threshold by 0.01.
- Otherwise, keep the threshold as-is.
- Continue to iterate on steps 2 to 5, until it is no longer advantageous to increase the threshold.
For the code detailing the following calculations, see the notebook associated with this post.
Step 1: Determining the lender’s willingness-to-pay
The lender must first determine the amount of portfolio value she is willing to forfeit for each additional Construction sector loan. Assume the lender’s willing-to-pay P in this example is $75,000.
Step 2: Determining the decrease in portfolio value
The lender must calculate the portfolio value at the optimal threshold and the next highest threshold value, and then calculate the difference to determine how much the portfolio value decreases as she increases the threshold by the minimum unit. This calculates as follows:
Step 3: Determining the increase in number of construction loans
Next, calculate the number of Construction sector loans that are added to the portfolio when the threshold increases by 0.01. The result is as follows:
Step 4: Determining the cost of each construction loan
The cost is calculated according to the following formula:
Step 5: Comparing the cost to willingness-to-pay
If the price P is greater than or equal to the cost C x -1 (because the cost is negative), move the threshold. In this example, the lender should move the threshold because the cost of $63,084 is less than the lender’s willingness-to-pay of $75,000, and make those 26 additional loans.
The lender would not stop with this one step. She would continue to ask if she should increase the threshold by another 0.01 and iterate through the previous steps until she reaches a point at which she chooses not to increase the threshold.
We assume that the lender always has access to the required capital if her willingness-to-pay is greater than the cost of an additional Construction sector loan. If desired, we can include a capital budget W for the lender as well. This change would modify the final step so that the lender checks both if P >= -C and if there is a sufficient amount of capital remaining in W to cover the sum of the principal of the additional loans.
Other model metrics
How do the naive, random forest with 0.5 threshold, and random forest with optimal threshold models compare according to the more traditional performance metrics, such as accuracy, precision, and recall?
The following table reports the accuracy, precision, and recall for all three models:
| Accuracy | Precision_0 | Precision_1 | Recall_0 | Recall_1 | |
| Naive Model | 0.822721 | 0.822721 | NaN | 1.000000 | 0.000000 |
| Random Forest Model (0.5 Threshold) | 0.935302 | 0.944246 | 0.883336 | 0.979177 | 0.731683 |
| Random Forest Model (Optimal Threshold) | 0.934975 | 0.960350 | 0.817026 | 0.960626 | 0.815937 |
According to this table, which model is the best? That question can’t be truly answered unless we know the benefits and costs to the lender associated with each cell of the confusion matrix, that is, the benefits associated with the true positives and true negatives and the costs associated with the false positives and false negatives.
It’s clear from the preceding table that both random forest models strictly dominate the naive model (assuming that the cost of a false positive isn’t significantly larger than the cost of a false negative). Additionally, there isn’t a clear-cut winner between the two random forest models. The answer depends upon the relative costs of misclassification to the lender. We know from the business context of the problem described in the introduction that there is a significantly higher cost associated with a false negative than with a false positive. Given that information, it is more valuable for the lender to minimize false negatives, and as such, Recall_1 or Precision_0 are the most salient metric.
This discussion illustrates the fact that determining the so-called best model requires knowledge of the business use case that this ML model addresses, and the benefits and costs associated with each potential classification outcome; only then can we determine the metric that best captures what success means to the business. Additionally, precision and recall only include information about two of the four cells of the confusion matrix, but the lender cares about the net benefits associated with all four cells. Using these typical metrics ignores half of the outcomes that the lender cares about and also ignores the specific costs and benefits associated with all outcomes. Because of this, these metrics are lacking, and one should calculate a single problem-specific metric that incorporates the specific costs and benefits associated with all cells of the confusion matrix to determine the optimal threshold. In this post, this metric is portfolio value.
This optimization approach can be used more generally to test whether a threshold is optimal for the problem and data at hand.
Cleaning Up
If you created a new Amazon SageMaker notebook instance to run the code, remember to stop or delete it to minimize costs.
Conclusion
This post showed how to find the optimal threshold in a binary classification problem. Specifically, we describe how to use Amazon SageMaker automatic model tuning to determine the classification threshold that maximizes the portfolio value of a lender when choosing which subset of borrowers to extend credit to. More generally, the method of choosing an optimal threshold we describe can be applied to situations in which you need to choose multiple thresholds. The main modification needed is to incorporate multiple thresholds into the problem-specific, threshold-based metric. After doing that, you could use Amazon SageMaker automatic model tuning to find a vector of thresholds, as opposed to a single threshold, that maximizes your metric.
The threshold determination approach we describe has several substantial advantages. First, it makes the logic and rationale used in determining a threshold explicit. Second, it requires the business to clearly state its cost matrix, based on the specific actions to take on the model predictions and their associated benefits and costs. Making the logic and cost structure explicit can drive challenging discussions in the business, and force differing implicit decisions and valuations onto the table for open discussion and agreement. In addition, though explainable ML is beyond the scope of this post, the explicit statement of the logic and cost structure of threshold determination encouraged by our approach fits well with the goals of that line of research.
Lastly, this approach can also potentially be used to address the issue of imbalanced data. The issue with imbalanced data is often not that one target class has a much larger representation in the data than another target class, it’s that the misclassification costs (that is, the cost of a false positive versus a false negative), are dramatically different from one another. Instead of using sampling to balance the training data, you can clearly define the misclassification costs in the problem-specific metric, and use that metric to find an optimal threshold. This approach makes the issue less a technical one of using a trick of modifying the distribution of data to more of a business one of clearly specifying the cost structure of a problem. That may address the true issue of imbalanced data more directly, which is the issue of imbalanced misclassification costs.
For any of your business use cases that requires setting a classification threshold, consider using Amazon SageMaker automatic model tuning and the method this post describes. To get started, open the Amazon SageMaker console and the code from the GitHub repo that generated results in this post. If you have thoughts on business use cases that you could apply this method to, or any questions, please leave them in the comments. For more information on training models that have asymmetric classification costs, see Training models with unequal economic error costs using Amazon SageMaker.
Sources and references:
Friedman, Milton, and L. J. Savage. “The Utility Analysis of Choices Involving Risk.” Journal of Political Economy 56, no. 4 (1948): 279–304.
Data sourced from: Li, Min, Amy Mickel, and Stanley Taylor. “‘Should This Loan Be Approved or Denied?’: A Large Dataset with Class Assignment Guidelines.” Journal of Statistics Education 26, no. 1 (January 2, 2018): 55–66. https://doi.org/10.1080/10691898.2018.1434342.
Metz, Charles E. “Basic Principles of ROC Analysis.” Seminars in Nuclear Medicine 8, no. 4 (October 1978): 283–98. https://doi.org/10.1016/S0001-2998(78)80014-2
Wu, Yirong, Craig K. Abbey, Xianqiao Chen, Jie Liu, David C. Page, Oguzhan Alagoz, Peggy Peissig, Adedayo A. Onitilo, and Elizabeth S. Burnside. “Developing a Utility Decision Framework to Evaluate Predictive Models in Breast Cancer Risk Estimation.” Journal of Medical Imaging 2, no. 4 (October 2015). https://doi.org/10.1117/1.JMI.2.4.041005.
Zadrozny, Bianca, and Charles Elkan. “Learning and Making Decisions When Costs and Probabilities Are Both Unknown,” 204–13. ACM Press, 2001. https://doi.org/10.1145/502512.502540.
Veronika Megler and Scott Gregoire. “Training models with unequal economic error costs using Amazon SageMaker,“ AWS Machine Learning Blog, 18 Sept 2018.
About the Authors
 Scott Gregoire is a Data Scientist with AWS Professional Services. He holds a PhD in Economics from the University of Texas at Austin and has advised clients in sectors ranging from international finance to retail. Currently, he is working with customers to develop innovative machine learning solutions on AWS.
Scott Gregoire is a Data Scientist with AWS Professional Services. He holds a PhD in Economics from the University of Texas at Austin and has advised clients in sectors ranging from international finance to retail. Currently, he is working with customers to develop innovative machine learning solutions on AWS.
 Veronika Megler, PhD, is a senior consultant for AWS Professional Services. She enjoys adapting innovative big data, AI and ML technologies to help customers solve new problems, and to solve old problems more efficiently and effectively.
Veronika Megler, PhD, is a senior consultant for AWS Professional Services. She enjoys adapting innovative big data, AI and ML technologies to help customers solve new problems, and to solve old problems more efficiently and effectively.