Collaborating with Humans Requires Understanding Them
AI agents have learned to play Dota, StarCraft, and Go, by training to beat an
automated system that increases in difficulty as the agent gains skill at the
game: in vanilla self-play, the AI agent plays games against itself, while in
population-based training, each agent must play against a population of other
agents, and the entire population learns to play the game.
This technique has a lot going for it. There is a natural curriculum in
difficulty: as the agent improves, the task it faces gets harder, which leads
to efficient learning. It doesn’t require any manual design of opponents, or
handcrafted features of the environment. And most notably, in all of the games
above, the resulting agents have beaten human champions.
The technique has also been used in collaborative settings: OpenAI had one
public match where each team was composed of three OpenAI Five agents alongside
two human experts, and the For The Win (FTW) agents trained to play Quake were
paired with both humans and other agents during evaluation. In the Quake
case, humans rated the FTW agents as more collaborative than fellow humans
in a participant survey.
However, when we dig into the weeds, we can see that this is not a panacea. In
the 2.5 minute discussion after the OpenAI Five cooperative game (see
4:33:05 onwards in the video), we can see that some issues did arise1:
Sheever: Actually it was nice; my Viper gave his life for me at some point.
He tried to help me, thinking “I’m sure she knows what she’s doing”.
Obviously I didn’t, but you know, he believed in me. I don’t get that a
lot with [human] teammates.Christy: They are perfectly selfless.
Sheever: Yeah, they are.
Michael: They also expect you to be.
Sheever: Yeah. (laughing) Didn’t work out that way.
[…]
–>
Blitz: It was interesting because I could tell that we were doing something
wrong, because they weren’t coming with us. I was like, “this is clearly an
‘us’ issue”, and I didn’t really know how to fix that. Regardless of what lane
I went to, it just felt like I was making the wrong play, and it felt kind of
bad in that regard. But it was cool because I knew that when I did make a move
and they decided to go with me, that they deemed that was the correct thing to
do. It felt like I was trying to solve a puzzle while playing the game.
Observers could also tell that the AIs were not collaborating well with
their human teammates. The agents were simply behaving as though they had AI
teammates, rather than Sheever and Blitz. The agents’ models of their teammates
were incorrect2. While this means they will sacrifice themselves when
it is in the team’s interest, it also means that they’ll leave without any
notice assuming that Sheever and Blitz will coordinate perfectly, as the AIs
would.
So is self-play actually a good algorithm to use to create collaborative
agents? We decided to put it to the test.
Overcooked
To investigate this further, we wanted a simple collaborative environment that
nonetheless has a wide variety of potential strategies, so that the optimal
strategy is not obvious. This led us to consider the game Overcooked, in
which players collaborate to cook up recipes quickly and serve them to hungry
customers. The game is particularly hard to coordinate in, primarily because of
the significant time pressure (which is not an issue for AI agents). Here’s an
example of good human play (starting at 15 seconds):
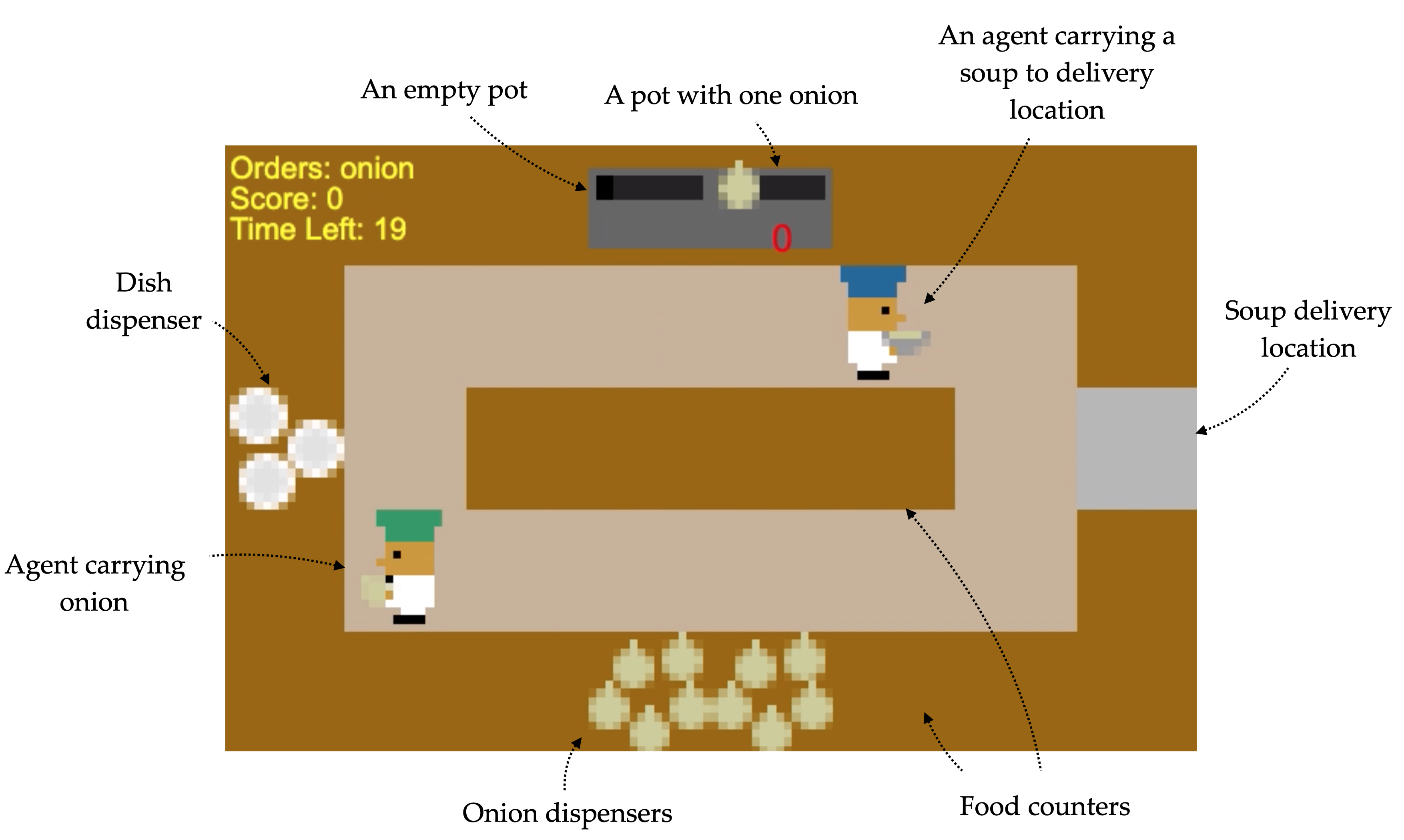
We created a simplified version of Overcooked, that allows us to focus on
particular coordination challenges that underlie joint planning for teams. In
our version, players must create and deliver soups. They must get onions from
the onion supply, place three of them in a pot, wait for the soup to cook, put
the soup in a plate, and then deliver the plate to a serving location. Players
need to employ both a good strategy (e.g. “you get the onions, I’ll grab the
dish”) as well as low level motion coordination (e.g. “let’s go clockwise so we
don’t crash into each other”). Despite its apparent simplicity, it is quite
challenging to act well in the environment: we developed a near-optimal
hierarchical A* planner, but the planning problem is difficult enough that our
planner can only solve two of our five layouts in a reasonable amount of time.
Let’s suppose you and your friend Alice are playing on the layout above, and
you are trying to beat Bob and Charlie (who are playing on the same layout).
You’ve got a good strategy: at the start, Alice puts onions onto the counter in
the middle, while you go to the top to transfer the onions into the pot. As you
glance over at Bob and Charlie, you notice that they haven’t figured out this
strategy: they pick up each onion separately, and make a long trudge around the
layout to put the onion in the pot. Well, all the better for you; it looks like
you’re going to beat them even more soundly than you thought:
<!–



Figure 1: (left) LED Array Microscope constructed using a standard
commercial microscope and an LED array. (middle) Close up on the LED array dome
mounted on the microscope. (right) LED array displaying patterns at 100Hz.
–>


Left: Alice (green) and you (blue) passing onions. Right: Bob (green) and
Charlie (blue) taking the long way.
But what if Alice doesn’t know about your strategy? In that case you head up
towards the pots, but to your chagrin Alice isn’t passing you onions – she’s
picked up a single onion and is making the long trudge over to place it in the
pot. You stand in front of the pot, staring at her pointedly, hoping she’ll
pass you some onions, but she continues to carry onions alone. You sigh, and
head back to get an onion yourself. Meanwhile, Bob and Charlie didn’t waste any
time, and so they win.


Left: Alice (green) and you (blue) fail to coordinate. Right: Bob (green) and
Charlie (blue) taking the long way.
Interestingly, even though you knew a good strategy that the others did not,
Bob and Charlie still managed to beat you and Alice. This is the key
difference. In competitive settings (like between your team and Bob’s), if
your opponent is suboptimal and you don’t know it, you’ll simply beat them even
more soundly. In contrast, in collaborative settings, if your partner is
suboptimal and you don’t know it, team performance can be arbitrarily poor:
even worse than if you were exactly like your partner, with all their
suboptimalities.
As we saw above, self-play makes poor assumptions about its human partners (or
opponents, for that matter). Failing to accurately model your opponents doesn’t
matter much, since it is a competitive setting, but failing to accurately model
your partners in collaborative settings can be arbitrarily bad.
Understanding the differences
In the language of game theory, competition corresponds to a zero-sum game
(my gain is your loss and vice versa), while collaboration corresponds to a
common payoff game (my gain is your gain and vice versa).3
Two player zero sum games. Self-play algorithms train the agent by having
the agent play games with itself, and updating so that it will be more likely
to win such games in the future. So, we would expect training to converge to an
equilibrium where the agent cannot improve its strategy when playing either
side of the game. For two player zero sum games, every such equilibrium
corresponds to a min-max policy. That is, the agent tries to maximize
the value it is going to get, assuming that its opponent is trying to
minimize the value the agent gets (which corresponds to maximizing their own
value, since the game is zero-sum).
An interesting fact about minimax policies is that an agent playing a minimax
policy is guaranteed to get at least as much value as if it were playing
itself. This is because of the dynamic we saw above: in competitive games, if
your opponent is suboptimal, you’ll beat them even more soundly. Indeed, it
seems almost obvious: if your opponent isn’t optimal, then they must be taking
an action that isn’t maximizing their value, which means it isn’t minimizing
your value, which means you’re going to do better than you expected.
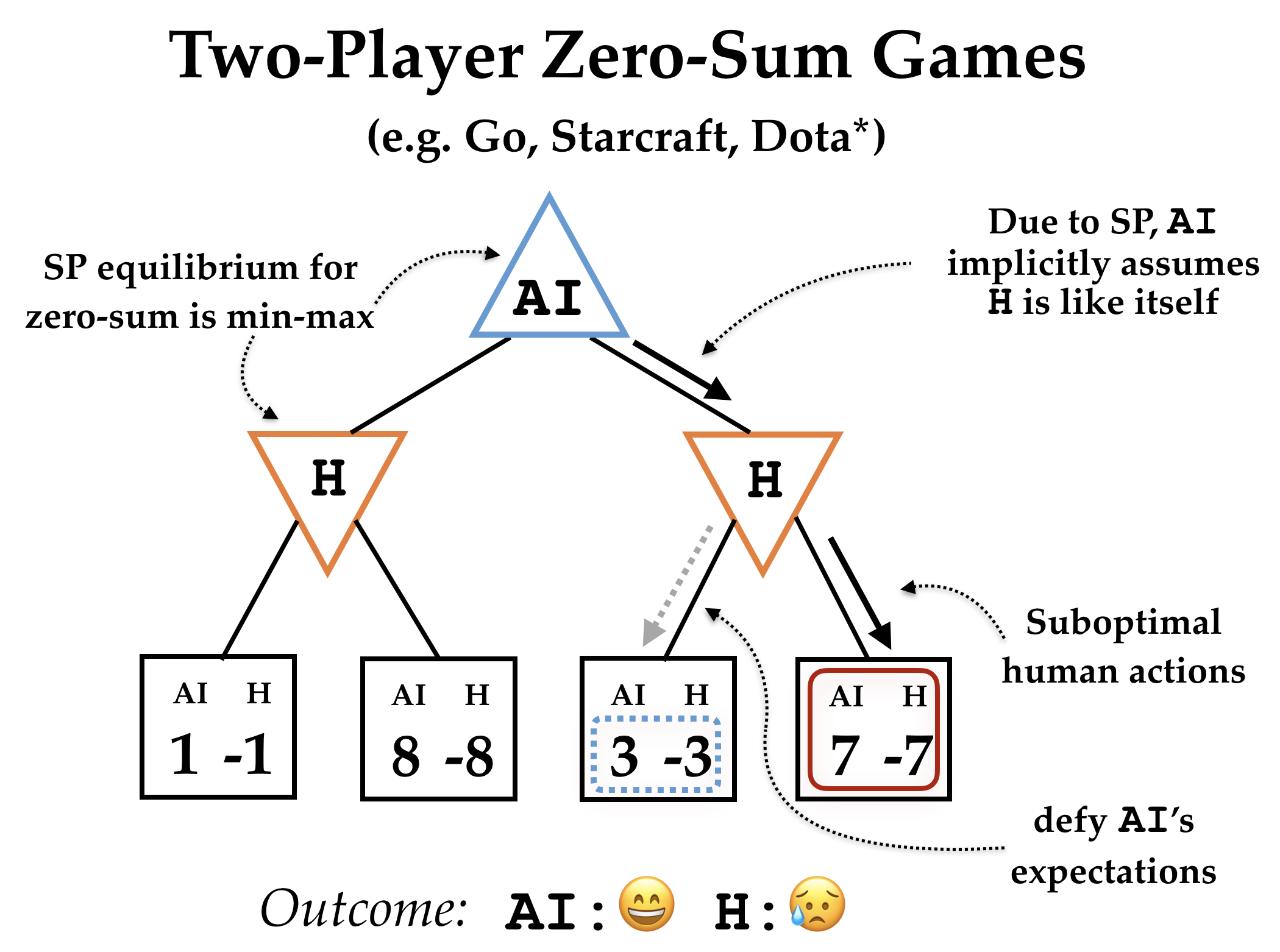
We can see this dynamic in the very simple game tree on the right. When
choosing an action, the agent reasons that if it takes the left path, the human
could go left, in which case it gets 1 reward, whereas if it takes the right
path, the human could go left, in which case it gets 3 reward. So, it goes
right. However, if the human then makes the suboptimal choice to go right, the
robot gets 7 reward instead: more than the 3 it expected.4
Common payoff games. Now let’s consider common payoff games, where both the
agent and the human get exactly the same reward. The self-play agent is still
going to end up in an equilibrium where it can’t improve its strategy when
playing either side of the game. The agent is going to reach a max-max policy,
where the agent tries to maximize its own value, assuming that its partner is
also trying to maximize the same value. Unlike min-max policies, max-max
policies do not provide a lower bound on reward obtained when the partner
doesn’t maximize value, and in fact performance can become arbitrarily bad.
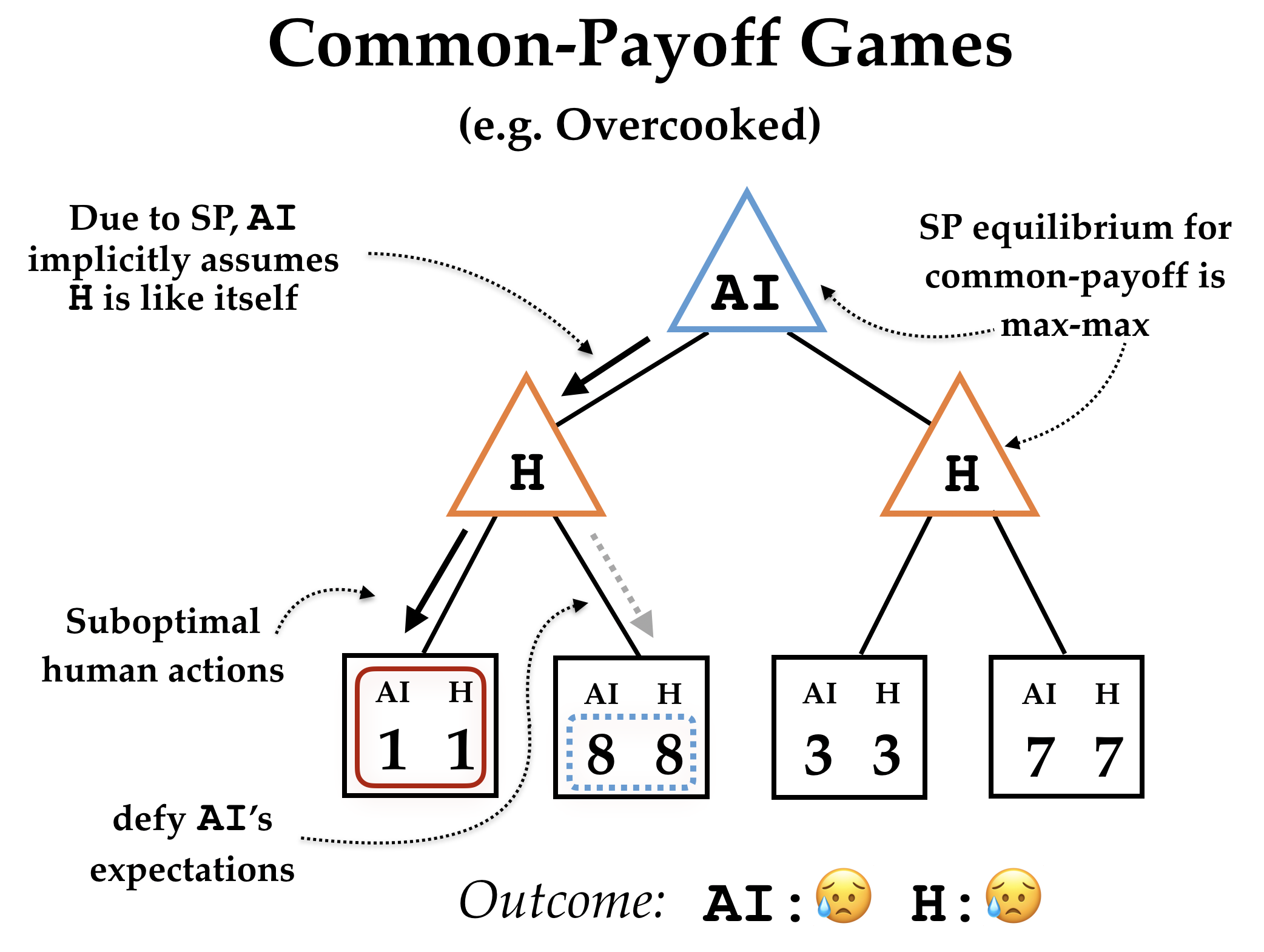
Consider the game tree on the right. Since the agent models the human as a
maximizer, it assumes that they can coordinate to reach the situation with 8
reward, and so goes left. However, if our suboptimal human ends up going left,
then the agent only gets 1 reward: the worst possible outcome!
Caveat. This argument applies to algorithms that reach equilibria. In
practice, due to the difficulty in training neural networks, our agents do not.
For example, neural nets are often very vulnerable to distribution shift. Since
humans likely play differently from the agent has seen during self-play
training, the agents could have had no idea what to do, which might cause them
to behave randomly. (This argument applies to both competitive and
collaborative settings.)
In what follows, we train an agent not with an optimal partner through
self-play, but with a model of a (suboptimal) human partner that we obtain from
human gameplay. We’ll call such agents “human-aware”.
Hypotheses
With all of this conceptual groundwork, we can make some testable hypotheses
for the Overcooked environment in particular. Firstly, since playing with
humans induces a distribution shift, and since it is a collaborative game,
where self-play doesn’t provide an opponent-independent guarantee:
H1. A self-play agent will perform much more poorly when partnered with a
human (relative to being partnered with itself).
Since a human-aware agent will have a better model of their partner than a
self-play agent:
H2. When partnered with a human, a human-aware agent will achieve higher
performance than a self-play agent, though not as high as a self-play agent
partnered with itself.
Of course, a human-aware agent will require access to a dataset of human
gameplay. Couldn’t we use the dataset to train an agent using imitation
learning? Unfortunately, this would copy over the human’s suboptimalities: what
we actually want is an agent that knows how the human is suboptimal and deals
with it appropriately.
H3. When partnered with a human, a human-aware agent will achieve higher
performance than an agent trained via imitation learning.
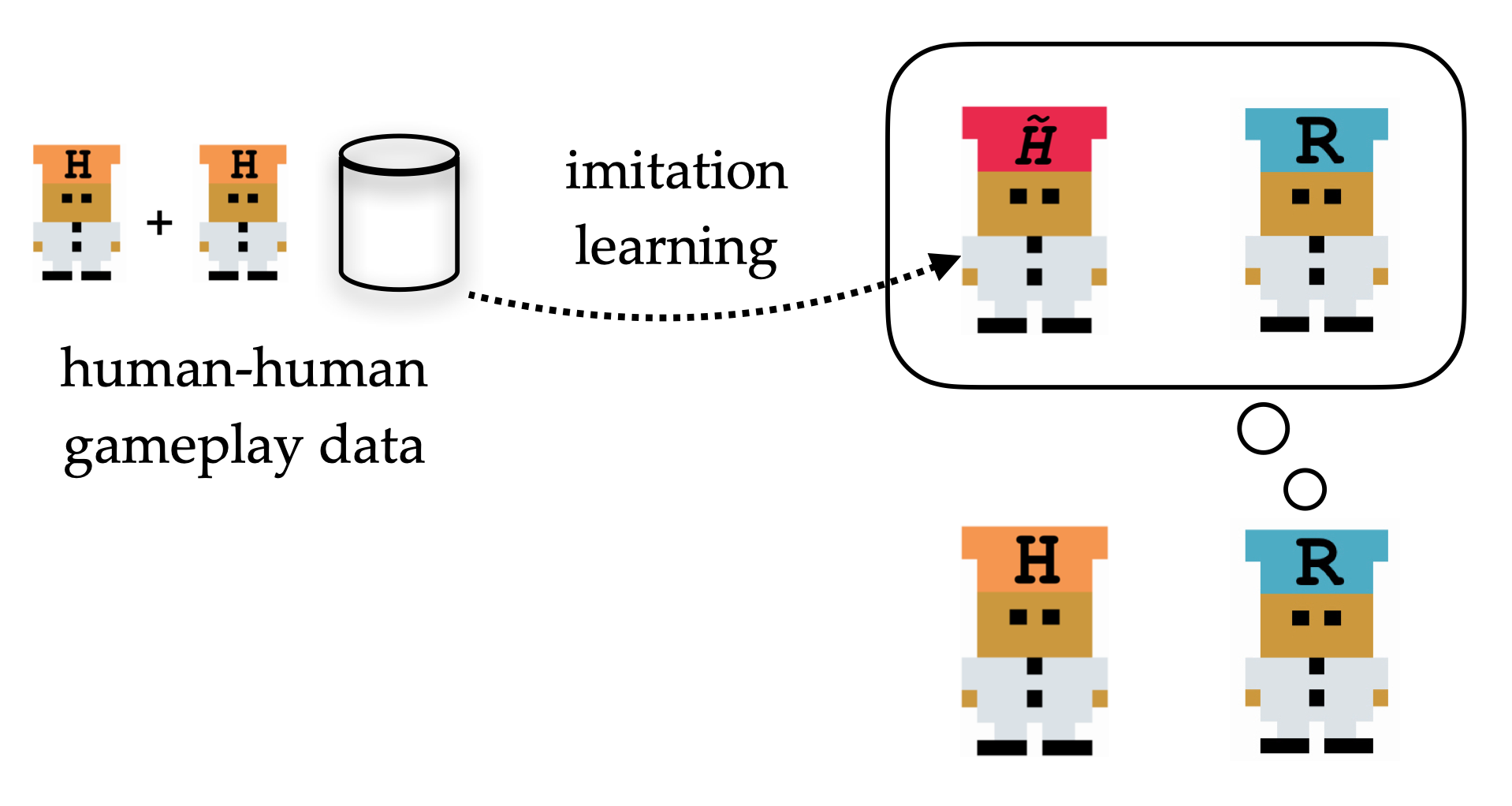
To test these hypotheses, we need an implementation of a human-aware agent. In
this work, we take the most basic approach: given a dataset of human-human
gameplay, we train a human model using behavior cloning, and then train an
agent that plays well with this (fixed) human model using deep RL
(specifically, PPO). There are many ways to improve on this basic approach, as
we discuss in the Future Work section, but we expect that even this will be
enough to outperform self-play in our Overcooked environment.
Experiments
To test our hypotheses, we created five different Overcooked layouts, shown
below.

From left to right: Cramped Room, Asymmetric Advantages, Coordination Ring,
Forced Coordination, Counter Circuit.
Since the agent can play either of the two players, this creates ten scenarios.
We first test in simulation: we train a human model using behavior cloning on a
dataset of human-human gameplay. This model will stand in for our test-time
human, and so is called H_{proxy}. We manipulate the agent that must play
alongside H_{proxy}, where the options are an agent trained via self-play
(SP), an agent trained to imitate (BC), and a human-aware agent trained to play
well alongside a human model (PPO_{BC}). Note that the human-human gameplay
used to train BC is entirely separate from that used to train H_{proxy}.
We also report the performance of self-play with itself (SP + SP), which serves
as a rough upper bound on the optimal team performance, as well as a
human-aware agent that is given access to the test-time human model
(PPO_{H_{proxy}} + H_{proxy}), which serves as a rough upper bound on
the optimal performance when the agent must play with the test-time human.
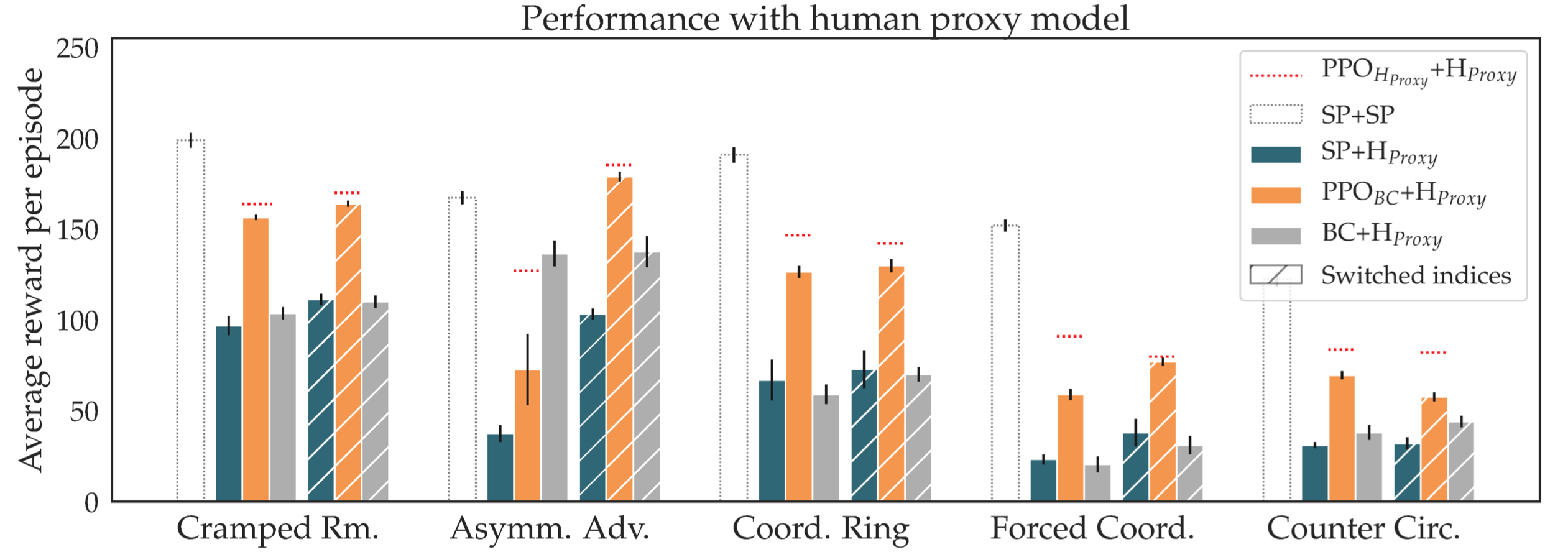
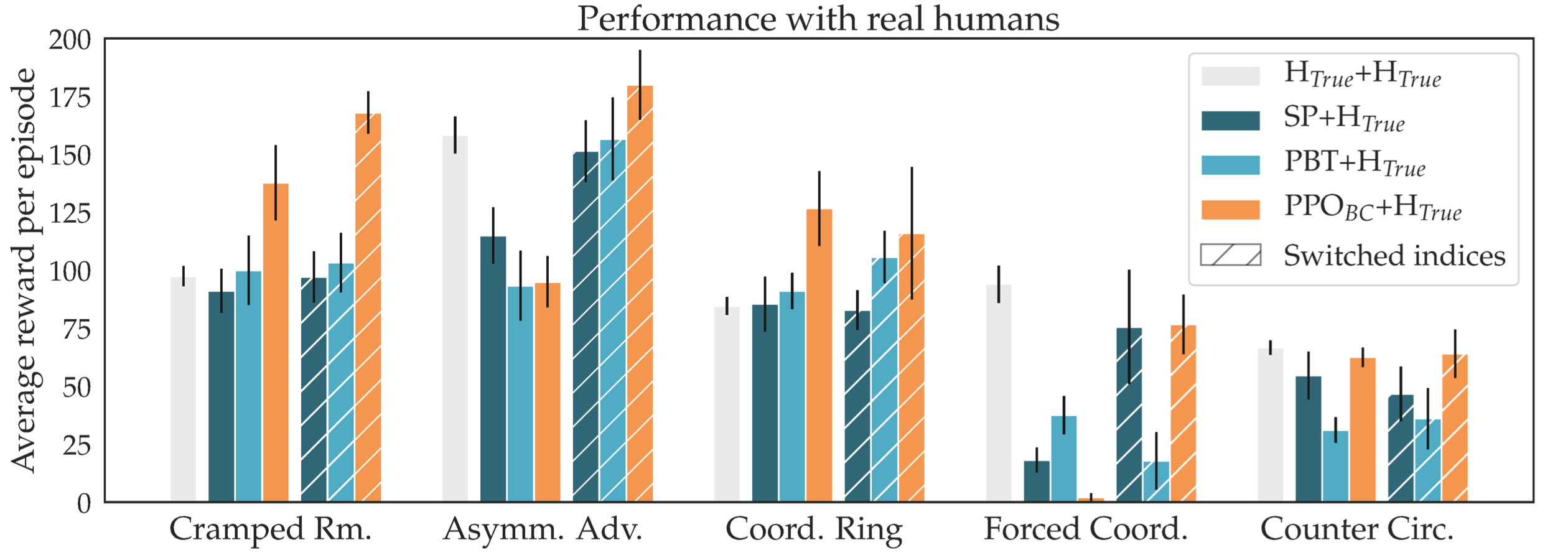
The results are shown below. We see that all three hypotheses are supported. It
is interesting to note that even vanilla behavioral cloning often outperforms
self-play agents when paired with H_{proxy}.
Qualitative results
How exactly is the human-aware agent getting better results? One reason is that
it is more robust to different plans the human could have. In Coordination
Ring, PBT and SP agents often insist upon moving in a particular direction.
When the human wants to go the other way, they collide and get stuck. In
contrast, the human-aware agent simply chooses whichever path the human isn’t
taking.
<!–


–>
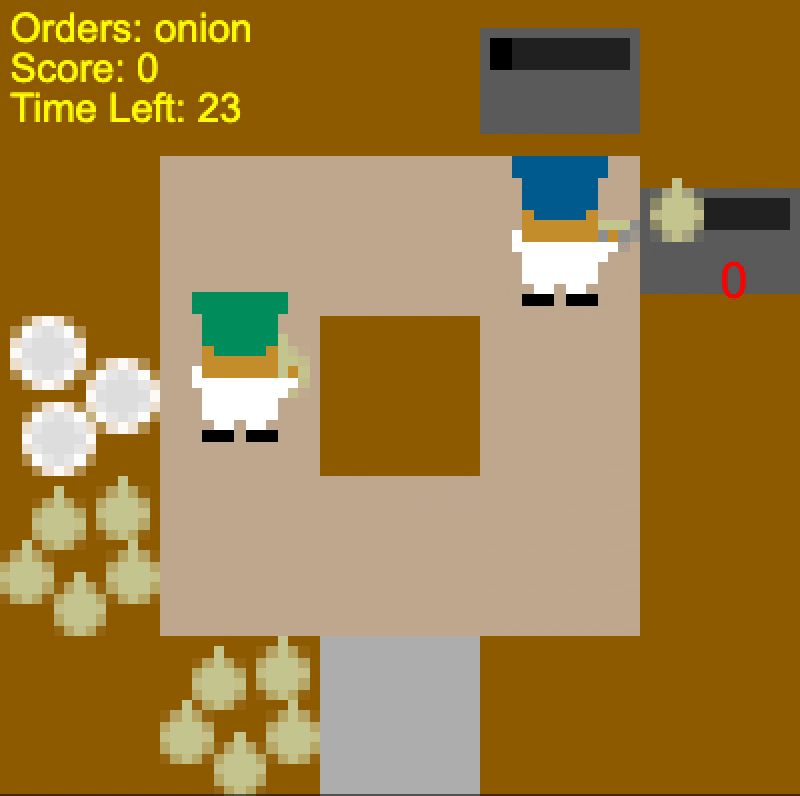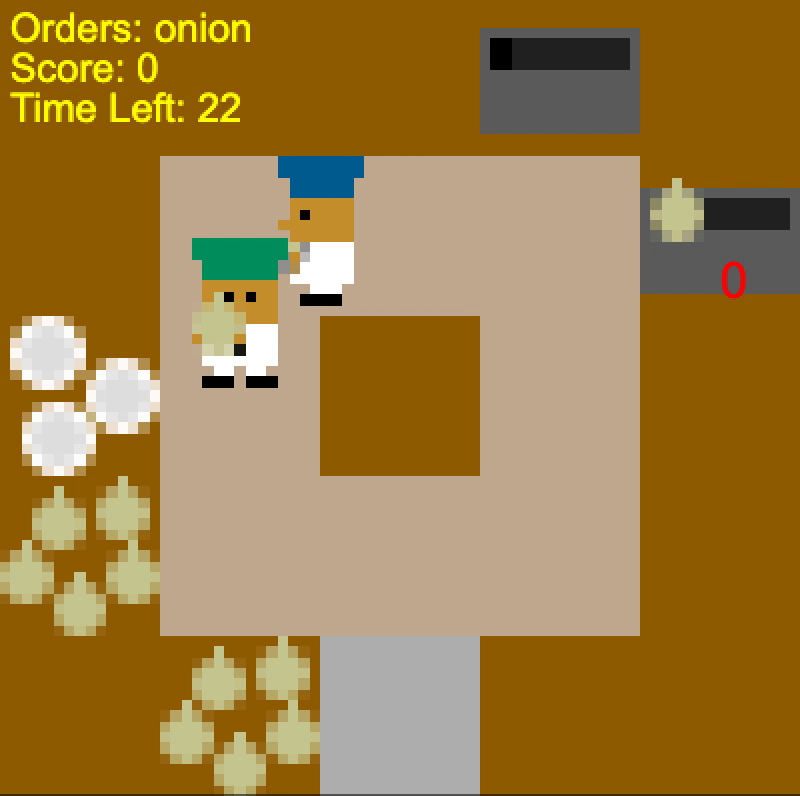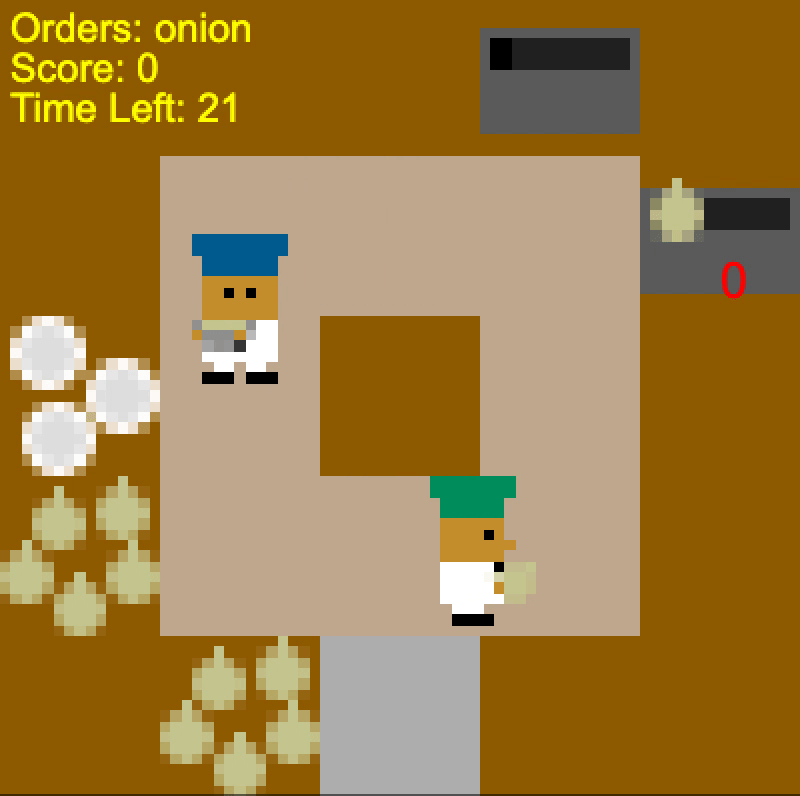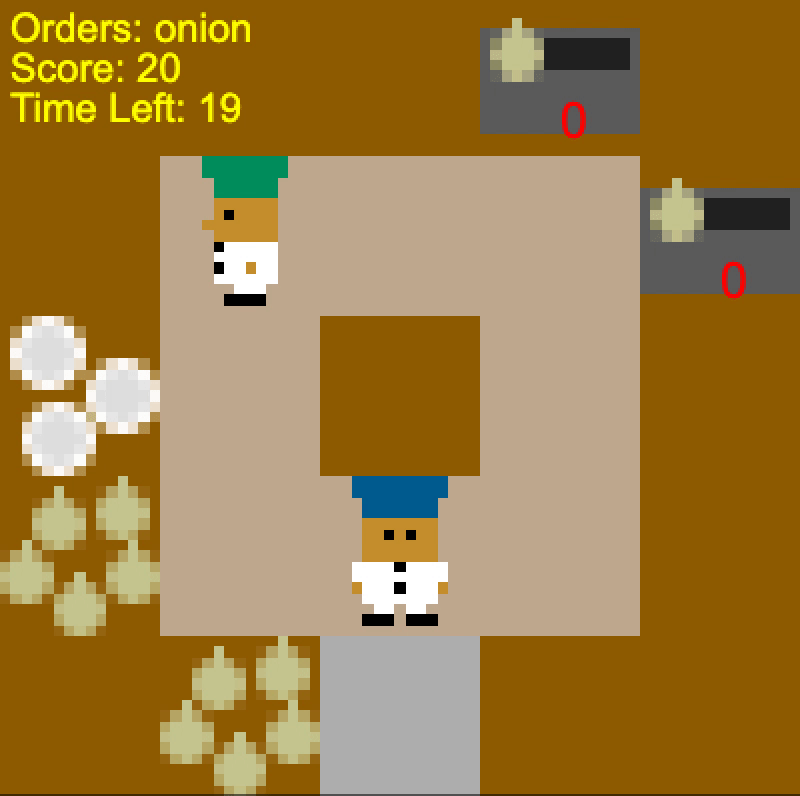


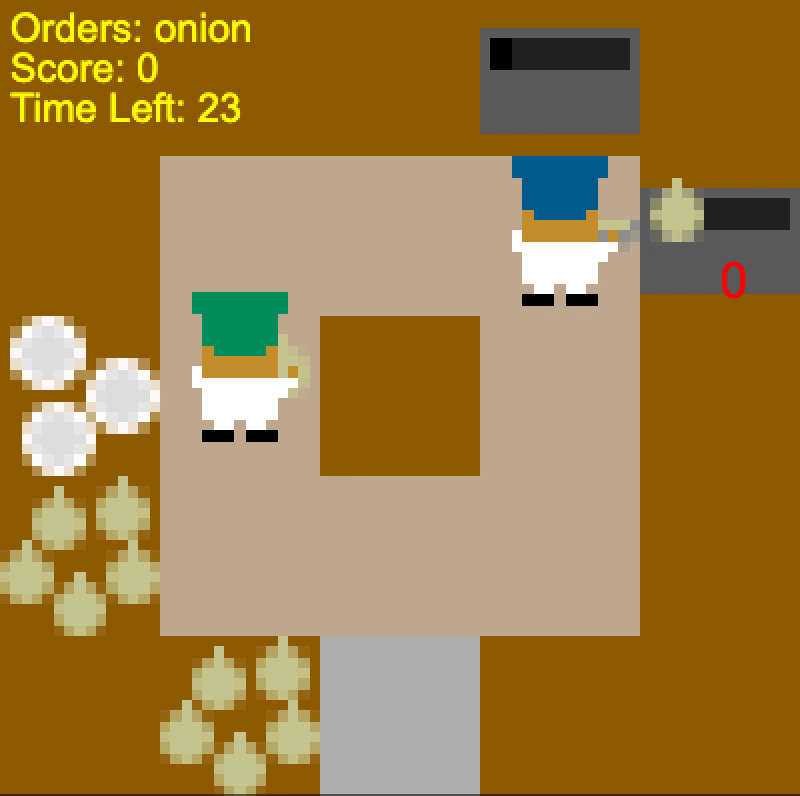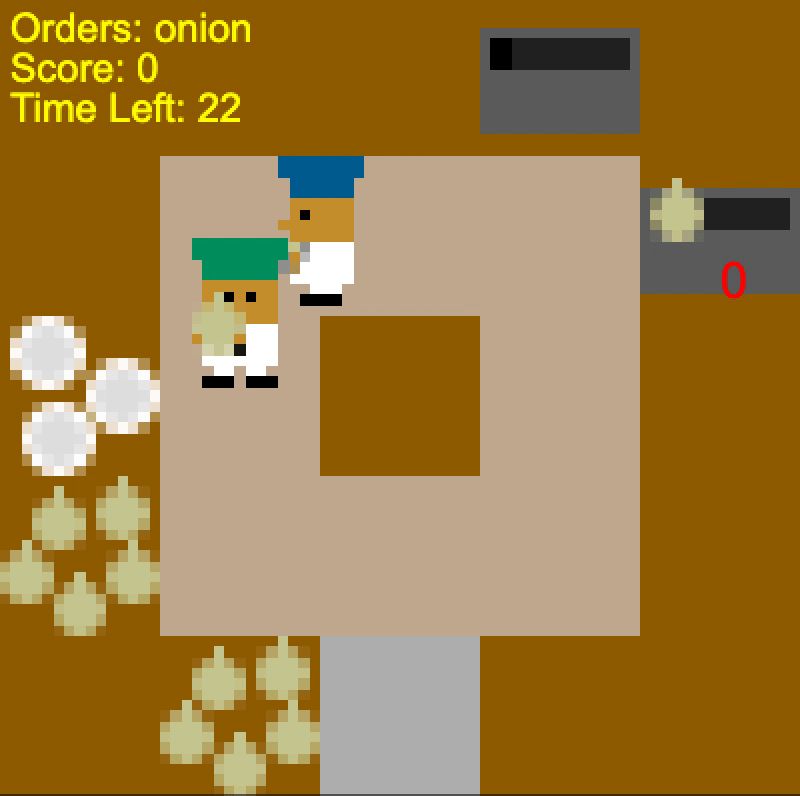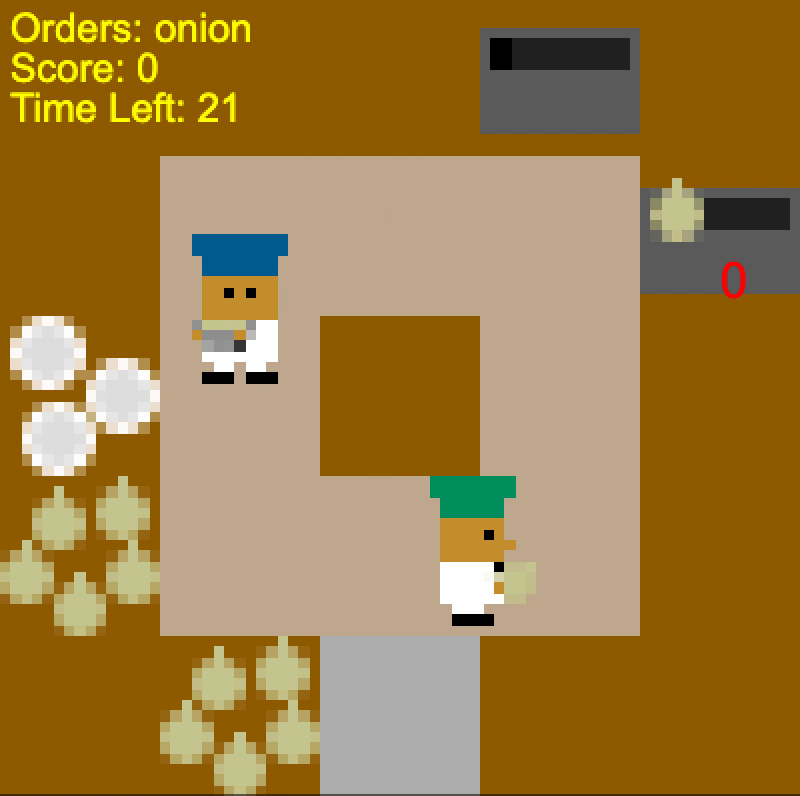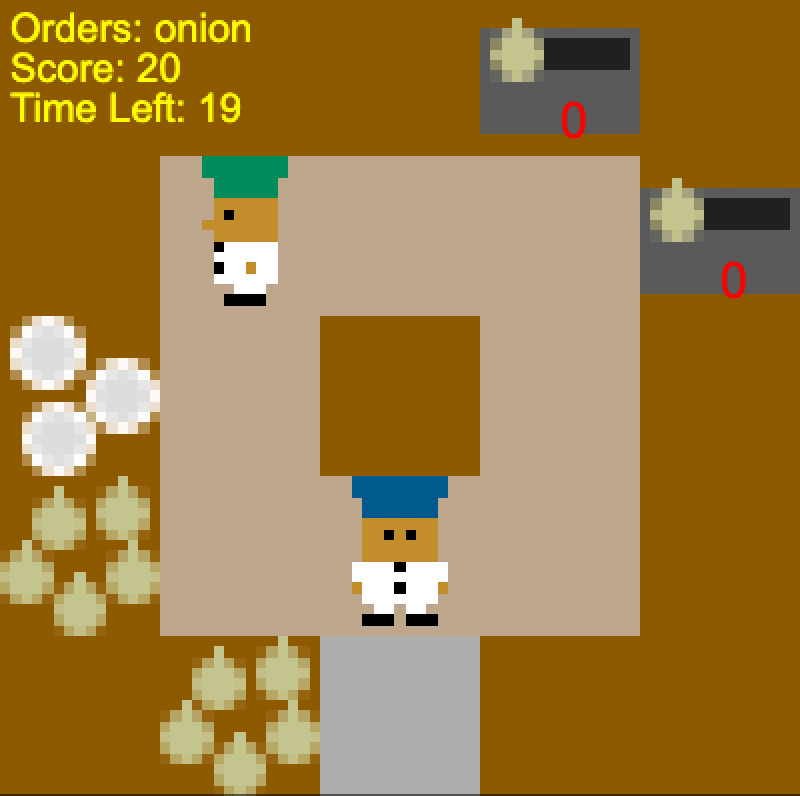
Self-play agent “stubbornly” colliding with the human (left), Human-aware agent
taking the appropriate route depending on the human’s direction (middle and
right).
Consider the gif with the self-play agent above. In the initial state, the
human is holding an onion and is facing up. What does the SP agent think the
human will do? Well, the SP agent “expects” the human to be like itself, and it
would have a 0-30% chance of up and 57-99.9% chance of down. (The ranges are
reporting the minimum and maximum across 5 seeds.) Thus, expecting the human to
move out of the way, SP decides to take the counterclockwise route – leading SP
to crash into the human.
Meanwhile, if we exclude the noop action, the BC model we used in training
assigns 99.8% chance of up and <0.01% chance of down, since the human is facing
up. Since the human is moving clockwise, it too moves clockwise to avoid
colliding with the human. Conversely, when the human is oriented in the
counterclockwise direction, the human-aware agent goes counterclockwise to
deliver the soup (even though that route is longer). It adaptively chooses the
route depending on the position and direction of the human.
Could the agent just be fragile?
There is one other salient explanation for our quantitative and qualitative
results: perhaps the self-play agent is being forced off-distribution when it
plays with H_{proxy}, and the problem is not just that it doesn’t know
about its partner: it just doesn’t know how to play at all (even with itself)
in these new states it hasn’t encountered before. Meanwhile, playing with BC
causes the human-aware agent to be trained on such states. This is at least
part of the explanation for our results.
This fragility to distributional shift argument would suggest that
population-based training (PBT) would perform much better, since it involves a
population of agents and so the winning agent needs to be robust to the entire
population, rather than just itself. However, when repeating the experiment
with agents trained via PBT, we see broadly similar results.
Another way to test this is to implement an agent that does not suffer from
distributional shift, but still suffers from incorrect expectations about its
partner. We do this by implementing a planning agent, that uses a
hierarchical A* search to select the best plan for the team to take, and then
executes its part of the best plan’s first joint action. For the human-aware
version, we perform a hierarchical A* search, where the partner is assumed to
always take the action predicted as most likely by BC. We again see broadly
similar results, though only the version that gets access to the test-time
human does well.
User study
Of course, the true test is whether these results will hold with actual humans.
By and large, they do, but not as clearly or strongly. H1 is clearly supported:
self-play agents perform worse with humans than with themselves. H2 is also
supported: PPO_{BC} is statistically significantly better than SP or PBT,
though the effect is much less pronounced than before. Since our method only
beats teams of humans in 5/10 configurations, the data is inconclusive about
H3.
We speculate that there are two main reasons why the results are different with
real humans:
-
The difference between real humans and BC is much larger than the
difference between H_{proxy} and BC (both of which are trained on
human-human gameplay). As a result, PPO_{BC} doesn’t generalize to real
humans as well as it generalizes to H_{proxy}. This is particularly true on
the fourth and fifth layouts, where the BC-trained human model is quite bad. -
Humans are able to figure out the coordination mechanisms that SP and PBT
use, and adapt to use those mechanisms themselves. In contrast, the BC model is
not able to adapt in this way. This significantly increases the performance of
SP and PBT.
You can see these effects for yourself, by playing the demo!
Discussion
So far we’ve seen that self play algorithms form an incorrect “expectation”
about their partner, and incorporating even the naive human model produced by
behavior cloning beats self play when playing with humans. It even beats
human-human teams sometimes!
You might hope that rather than understanding humans, which requires expensive
human data, we could instead simply train our agents to be robust to a wide
variety of agents, which would automatically make them robust to humans.
However, this is exactly what PBT is supposed to do, and we found that PBT
ended up having the same kinds of problems as SP. Nonetheless, it could be that
with a larger population or other tweaks to the algorithm, PBT could be
improved.
You might also think that our results are primarily explained by analyzing how
many states an algorithm has been trained on: SP and PBT fall into
near-deterministic patterns, while PPO_{BC} must cope with the
stochasticity of BC, and so it is trained on a wider variety of states, which
makes it work better with humans. However, we saw approximately the same
pattern with the planning agent, which is robust on all states. In addition,
the entropy bonus in PPO keeps SP and PBT at least somewhat stochastic.
One way to view the problem we have outlined is that AI systems trained via
self-play end up using coordination protocols that humans do not use. However,
it is possible that this only happens because we are running the algorithms on
a single layout at the time, and so they learn a protocol that is specialized
to that layout. In contrast, human coordination protocols are likely much more
general. This suggests that we could make AI protocols similar to human ones by
forcing the AI protocols to be more general. In particular, if we train AI
systems via self-play to play on arbitrary maps, they will have to learn more
general coordination protocols, that may work well with human protocols. We
would like to investigate this possibility in the future.
Future Work
To demonstrate how important it is to model humans, we used the most naive
human model we could and showed that even that leads to significant
improvements over self-play. Of course, for best performance, we’d like to use
better human models. There are several areas for improvement:
-
We could use more data to make the model more accurate, or use more
sophisticated methods than behavior cloning to learn the human model -
While the human model is trained on human-human gameplay, it is used in the
context of human-AI gameplay, which may be very different and cause the BC
model to suffer from distributional shift. We could alternate between training
PPO_{BC} and collecting new human-AI gameplay to improve the BC model. -
Alternatively, we could try to use models that are more robust to
distributional shift, such as models based on Theory of Mind, where the human
is modeled as approximately optimizing some reward function. -
So far, we have made the obviously false assumption that all humans play
exactly the same. Instead, we could learn a space of strategies that humans
tend to use, and try to identify the test human’s strategy and adapt to it on
the fly. -
Another obviously false assumption we make is that the human is
stationary, that is, the human’s policy doesn’t change over time. But of
course, humans learn and adapt to their partners (and we see strong
observational evidence of this in the user study, where humans learn the
protocols that SP and PBT use). If we are able to model this learning, we
could build agents that actively teach humans better coordination protocols
that achieve higher reward.
Alternatively, rather than attempting to completely fix the model’s
expectations about its partner, we could train it to be robust to a wide
variety of partners. This will limit the peak performance, since the agent
cannot specialize to humans in particular, but it could still give a suitably
good result, and in particular it should beat imitation learning. We showed
that vanilla PBT was insufficient for this task, but we find it plausible that
variants of PBT could work.
Another aspect to investigate further is the extent to which these problems are
caused by a lack of robustness to states as opposed to partners. Currently,
when a self-play agent is forced off distribution, it behaves in a clearly
suboptimal way (such that the agent wouldn’t coordinate well even with itself).
If we had agents that at least played coherently with respect to some partner
on all states, that could potentially fix most of the problem. (However, our
planning experiments show that some problems will remain.) With deep RL,
perhaps this could be done by incentivizing exploration via intrinsic
motivation, or by generating a random initial state instead of a fixed one
during each episode.
We’re excited by the potential of Overcooked as a benchmark for human-AI
collaboration, and we hope to see more research that paves the way to AI
systems that are increasingly beneficial for humans.
This post is based on the paper “On the Utility of Learning about Humans for
Human-AI Coordination”, to be presented at NeurIPS 2019. You can play with
our trained agents or watch them play each other here. We’ve taken
particular care to separately publish our environment code, DRL code,
visualization code, and user study code, so that each can be reused
and modified. We would particularly welcome pull requests to add more
functionality to the environment.
-
Quotes have been edited for clarity. ↩
-
Although this point also applies to the competitive setting, the
problems it causes are not as significant, as we will see later in the
post. ↩ -
Other general-sum games typically have both competitive and
collaborative aspects. While we don’t study them in this work, our results
suggest that the more collaborative the game is, the worse self-play will
perform. ↩ -
That said, the agent might have been able to do better if it knew how
the human would behave. Suppose it knew that if it went left, the human
would then have gone right. Then by going left, the agent would get 8
reward; better than the 7 reward it ended up getting by going right. ↩