rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch
Since the advent of deep reinforcement learning for game play in 2013, and
simulated robotic control shortly after, a multitude of new algorithms
have flourished. Most of these are model-free algorithms which can be
categorized into three families: deep Q-learning, policy gradients, and Q-value
policy gradients. Because they rely on different learning paradigms, and
because they address different (but overlapping) control problems,
distinguished by discrete versus continuous action sets, these three families
have developed along separate lines of research. Currently, very few if any
code bases incorporate all three kinds of algorithms, and many of the original
implementations remain unreleased. As a result, practitioners often must
develop from different starting points and potentially learn a new code base
for each algorithm of interest or baseline comparison. RL researchers must
invest time reimplementing algorithms–a valuable individual exercise but one
which incurs redundant effort across the community, or worse, one that presents
a barrier to entry.
Yet these algorithms share a great depth of common reinforcement learning
machinery. We are pleased to share rlpyt, which leverages this commonality
to offer all three algorithm families built on a shared, optimized
infrastructure, in one repository. Available from BAIR at
https://github.com/astooke/rlpyt, it contains modular implementations of
many common deep RL algorithms in Python using Pytorch, a leading deep learning
library. Among numerous existing implementations, rlpyt is a more
comprehensive open-source resource for researchers.
rlpyt is designed as a high-throughput code base for small- to medium-scale
research in deep RL (large-scale being DeepMind AlphaStar or OpenAI
Five, with 100’s of GPUs). This blog post briefly introduces its features
and relation to prior work. Notably, rlpyt reproduces the recent
record-setting results in the Atari domain from “Recurrent Experience Replay in
Distributed Reinforcement Learning” (R2D2)–except without requiring
distributed compute infrastructure to gather the 10’s of billions of frames of
gameplay needed. We also introduce a new data structure, called the
namedarraytuple, which is used extensively in rlpyt for handling collections
of numpy arrays. Further technical discussion, including more detailed
implementation and usage notes, are provided in a white paper posted on
arxiv.
Key features and capabilities include the following:
- Run experiments in serial mode (helpful for debugging, maybe sufficient for
experiments). - Run experiments parallelized, with options for parallel sampling and/or
multi-GPU optimization. - Sampling and optimization synchronous or asynchronous (via replay buffer).
- Use CPU or GPU for training and/or batched action selection during
environment sampling. - Full support for recurrent agents.
- Online or offline evaluation and logging of agent diagnostics during
training. - Launching utilities for stacking / queueing sets of experiments on local
computer. - Modularity for easy modification and re-use of existing components.
- Compatible with OpenAI Gym environment interface.
Algorithms implemented (check the repository for additions):
- Policy Gradient: A2C, PPO
- DQN + variants: Double, Dueling, Categorical,
Rainbow minus Noisy Nets, Recurrent (R2D2-style) (coming soon:
Implicit Quantile Networks) - Q-value Policy Gradients: DDPG, TD3, SAC (coming soon:
Distributional DDPG)
Replay buffers (supporting DQN and QPG) are included with the following
optional features: n-step returns, prioritized replay, sequence replay
(for recurrence), frame-based buffers (e.g. to store only unique Atari frames
from multi-frame observations).
Parallel Computing Infrastructure for Faster Experimentation
Sampling. The two phases of model-free RL, sampling environment
interactions and training the agent, can be parallelized differently. For
sampling, rlpyt includes three basic options: serial, parallel-CPU, and
parallel-GPU. Serial sampling is the simplest, as the entire program runs in
one Python process, and this is often useful for debugging. But environments
are typically CPU-based and single-threaded, so the parallel samplers use
worker processes to run environment instances, speeding up the overall
collection rate. CPU sampling also runs the agent’s neural network in the
workers for action selection. GPU sampling batches all environments’
observations together for action-selection in the master process, for more
efficient use of the GPU. These configurations are depicted in the Figure
[sampler]. One additional offering is alternating-GPU sampling, which uses two
groups of workers: one executes environment simulation while the other awaits
new actions. This may provide speedups when the action-selection time is
similar to but shorter than the batch environment simulation time.
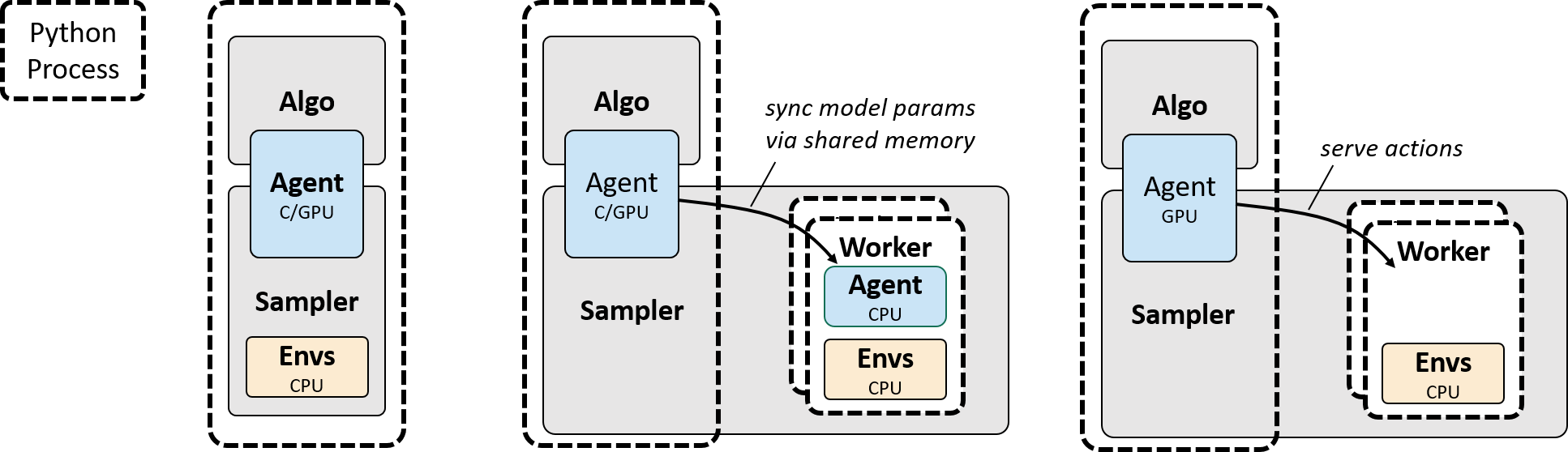
Figure [sampler]. Environment interaction sampling schemes. a) Serial: agent
and environments execute within one Python process. b) Parallel-CPU: agent and
environments execute on CPU in parallel worker processes. c) Parallel-GPU:
environments execute on CPU in parallel workers processes, agent executes in
central process, enabling batched action-selection.
Optimization. Synchronous multi-GPU optimization is included via PyTorch’s
DistributedDataParallel wrapper. The entire sampler-optimizer stack is
replicated in a separate process for each GPU, and the model implicitly
synchronizes by all-reducing the gradient during backpropagation. The
DistributedDataParallel tool automatically reduces the gradient in chunks
concurrently with backpropagation for better scaling on large networks. This
arrangement is shown in Figure [sync]. The sampler can be any serial or
parallel configuration described earlier.
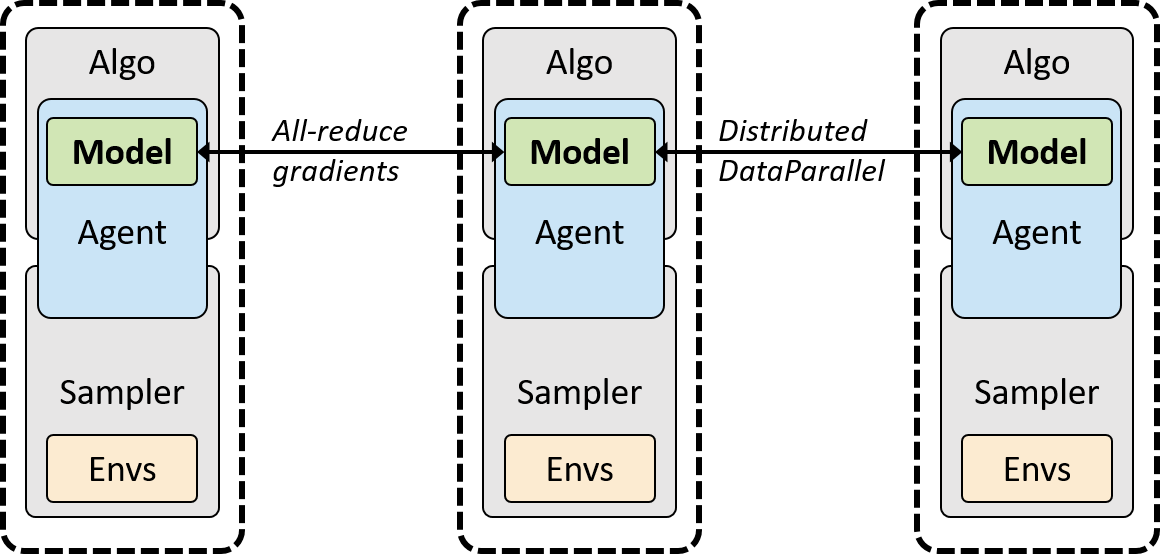
Figure [sync]. Synchronous multi-process reinforcement learning. Each python
process runs a copy of the fully sample-algorithm stack, with synchronization
enforced implicitly during backpropagation in PyTorch’s
`DistribuedDataParallel` class. Both GPU (NCCL backend) and CPU (gloo backend)
modes are supported.
Asynchronous Sampling-Optimization. In the configurations depicted so far,
the sampler and optimizer operate sequentially in the same Python process. In
some cases, however, running optimization and sampling asynchronously achieves
better hardware utilization, by allowing both to run continuously. This was
the case in our R2D2 reproduction and could also be true for learning on real
robots. In asynchronous mode, separate Python processes run the training and
sampling, tied together by a replay buffer built on shared memory. Sampling
runs uninterrupted by the use of a double buffer for data batches, which yet
another Python process copies into the main buffer, under write lock. See
Figure [async]. The optimizer and sampler may be parallelized independently,
perhaps each using a different number of GPUs, to achieve best overall
utilization and speed.
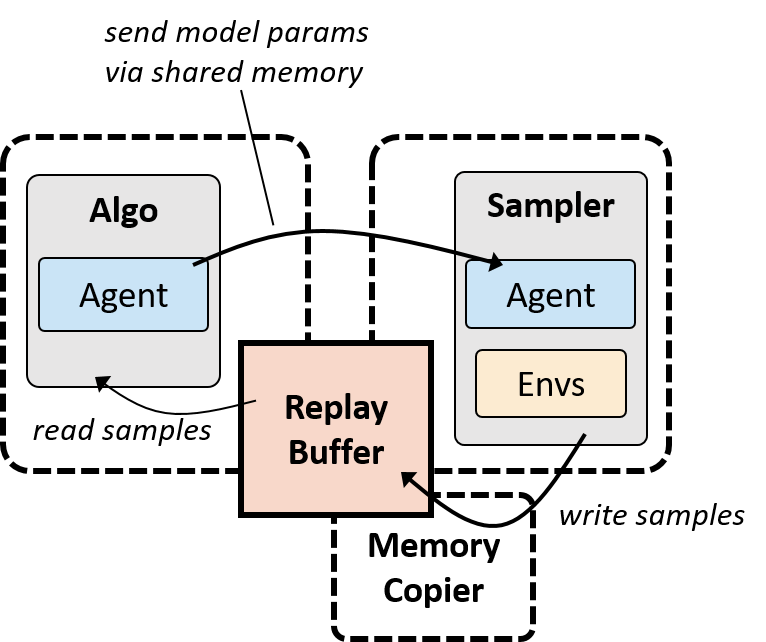
Figure [async]. Asynchronous sampling/optimization mode. Separate python
processes run optimization and sampling via a shared-memory replay buffer under
read-write lock. Memory copier processes write to the replay buffer, freeing
the sampler to proceed immediately from batch to batch of collection.
Which configuration is best? For creating or modifying agents, models,
algorithms, and environments, serial mode will be the easiest for debugging.
Once the serial program runs smoothly, one can easily explore the more
sophisticated infrastructures, such as parallel sampling, multi-GPU
optimization, and asynchronous sampling, since they are built on largely the
same interfaces. The optimal configuration may depend on the learning problem,
available computer hardware, and number of experiments to run. Parallelism
included in rlpyt is limited to the single-node case, although its components
could serve as building blocks for a distributed framework.
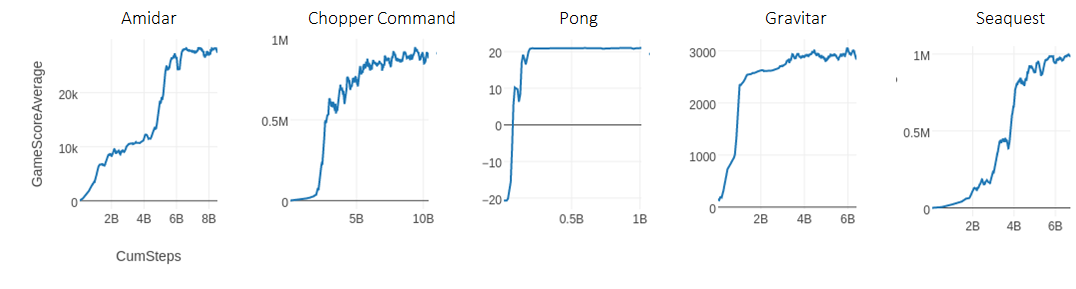
Performance Case Study: R2D2
We highlight learning curves reproducing the R2D2 result in Atari, which was
previously only feasible using distributed computing. This benchmark includes
a recurrent agent trained from a replay buffer for on the order of 10 billion
samples (40 billion frames). R2D1 (non-distributed R2D2) exercises several of
rlpyt’s more advanced infrastructure components to achieve this, namely
multi-GPU asynchronous sampling mode with the alternating-GPU sampler. In
Figure [R2D1], we reproduce several learning curves which surpass any previous
algorithm. We do note that results did not reproduce perfectly on all
games–for example in Gravitar the score plateaued at a low level. The white
paper contains more discussion on this point, as well as further verifications
for the other algorithms and environments.
<!–
–>
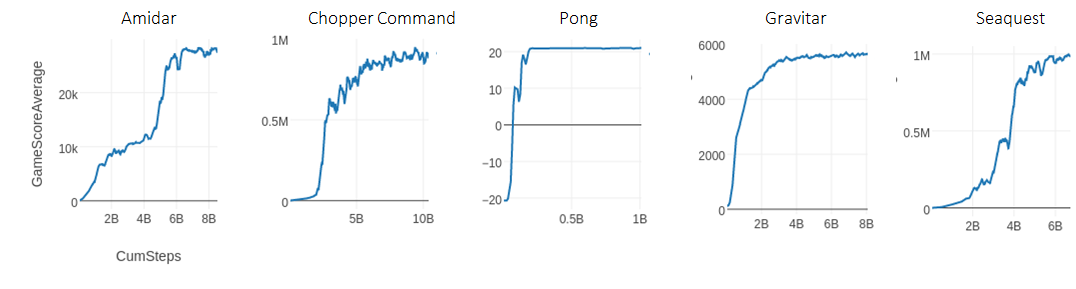
Figure [R2D1 curves]. Reproduction of R2D2 learning curves in rlpyt, using a
single computer.
The original, distributed implementation of R2D2 quoted about 66,000 steps per
second (SPS) using 256 CPUs for sampling and 1 GPU for training. rlpyt
achieves over 16,000 SPS when using only 24 CPUs (2x Intel Xeon Gold 6126,
circa 2017) and 3 Titan-Xp GPUs in a single workstation (one GPU for training,
two for action-serving in the alternating sampler). This may be enough to
enable experimentation without access to distributed infrastructure. One
possibility for future research is to increase the replay ratio (here set to 1)
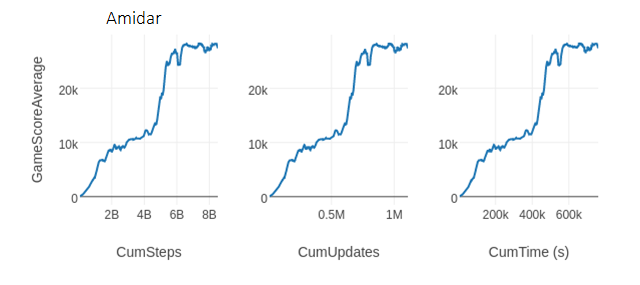
for faster learning using multi-GPU optimization. Figure [Amidar] shows the
same learning curve over three different measures: environment steps (i.e. 1
step = 4 frames), model updates, and time. This run reached 8 billion steps
and 1 million updates in less than 138 hours.
<!–
–>
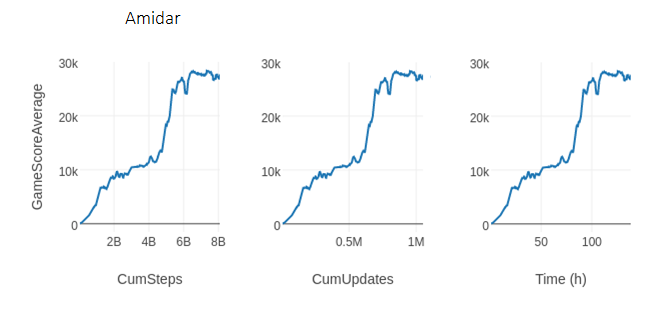
Figure [Amidar]. The same learning curve over three horizontal axes:
environment steps, model updates, and wall-clock time for rlpyt’s R2D1
implementation run in asynchronous sampling mode using 24 CPU cores and 3 GPUs.
New Data Structure: namedarraytuple
rlpyt introduces new object classes, called namedarraytuples, for easier
organization of collections of numpy arrays or torch tensors. A
namedarraytuple is essentially a namedtuple which exposes indexed or sliced
read/writes into the structure. Consider writing into a (possibly nested)
dictionary of arrays which share some common dimensions for addressing:
for k, v in src.items():
if isinstance(dest[k], dict):
..recurse..
dest[k][slice_or_indexes] = v
This code is replaced by the following:
dest[slice_or_indexes] = src
Importantly, the syntax is the same whether dest and src are individual
numpy arrays or arbitrarily-structured collections of arrays (the structures of
dest and src must match, or src can be a single value to apply to all
fields). rlpyt uses this data structure extensively–different elements of
training data are organized with the same leading dimensions, making it easy to
interact with desired time- or batch-dimensions. Namedarraytuples also
naturally support environments with multi-modal actions or observations (e.g.
vision and joint angles). This is useful when different modes interface with
the neural network at different layers, as it allows the intermediate
infrastructure code to remain unchanged regardless of this structure. For more
details, see the code and documentation for namedarraytuples in
rlpyt/utils/collections.py.
Related Work
For newcomers to deep RL, other resources may be better for familiarization
with algorithms, such as OpenAI Spinning Up (code / docs). rlpyt
is a revision of accel_rl, which explored scaling RL in the Atari domain
using Theano, see the paper for results. For a further study of
batch-size scaling in deep learning and RL, see this OpenAI report.
rlpyt and accel_rl were originally inspired by rllab (for example the
logger remains nearly a direct copy).
Other published research code bases include OpenAI Baselines and
Dopamine, both of which are implemented in Tensorflow, and neither of
which are optimized to the extent of rlpyt nor contain all three algorithm
families. Rllib, built on top of Ray, takes a different approach
focused on distributed computing, possibly complicating small experiments.
Facebook Horizon offers a subset of algorithms and focuses on
applications toward production at scale. In sum, rlpyt provides modular
implementations of more algorithms and modular infrastructure for parallelism,
making it a distinct toolset supporting a wide range of research uses.
Conclusion
We hope that rlpyt can facilitate easier use of existing deep RL techniques and
serve as a launching point for research into new ones. For example, the more
advanced topics of meta-learning, model-based, and multi-agent RL are not
explicitly addressed in rlpyt, but applicable code components may still be
helpful in accelerating their development. We expect the offerings of
algorithms to grow over time. Let us know in the comments below if you have
any questions or suggestions, check out the code with examples at
https://github.com/astooke/rlpyt, and read the white paper on arxiv
for more implementation and usage details. Happy reinforcement learning!