Building A Collaborative Filtering Recommender System with TensorFlow

Collaborative Filtering is a technique widely used by recommender systems when you have a decent size of user — item data. It makes recommendations based on the content preferences of similar users.
Therefore, collaborative filtering is not a suitable model to deal with cold start problem, in which it cannot draw any inference for users or items about which it has not yet gathered sufficient information.
But once you have relative large user — item interaction data, then collaborative filtering is the most widely used recommendation approach. And we are going to learn how to build a collaborative filtering recommender system using TensorFlow.
The Data
We are again using booking crossing dataset that can be found here. The data pre-processing steps does the following:
- Merge user, rating and book data.
- Remove unused columns.
- Filtering books that have had at least 25 ratings.
- Filtering users that have given at least 20 ratings. Remember, collaborative filtering algorithms often require users’ active participation.
https://medium.com/media/defd12f7c924869652fef81d9795e6c6/href

So, our final dataset contains 3,192 users for 5,850 books. And each user has given at least 20 ratings and each book has received at least 25 ratings. If you do not have a GPU, this would be a good size.
The collaborative filtering approach focuses on finding users who have given similar ratings to the same books, thus creating a link between users, to whom will be suggested books that were reviewed in a positive way. In this way, we look for associations between users, not between books. Therefore, collaborative filtering relies only on observed user behavior to make recommendations — no profile data or content data is necessary.
Our technique will be based on the following observations:
- Users who rate books in a similar manner share one or more hidden preferences.
- Users with shared preferences are likely to give ratings in the same way to the same books.
The Process in TensorFlow
First, we will normalize the rating feature.
scaler = MinMaxScaler()
combined['Book-Rating'] = combined['Book-Rating'].values.astype(float)
rating_scaled = pd.DataFrame(scaler.fit_transform(combined['Book-Rating'].values.reshape(-1,1)))
combined['Book-Rating'] = rating_scaled
Then, build user, book matrix with three features:
combined = combined.drop_duplicates(['User-ID', 'Book-Title'])
user_book_matrix = combined.pivot(index='User-ID', columns='Book-Title', values='Book-Rating')
user_book_matrix.fillna(0, inplace=True)
users = user_book_matrix.index.tolist()
books = user_book_matrix.columns.tolist()
user_book_matrix = user_book_matrix.as_matrix()
tf.placeholder only available in v1, so I have to work around like so:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
In the following code scrips
- We set up some network parameters, such as the dimension of each hidden layer.
- We will initialize the TensorFlow placeholder.
- Weights and biases are randomly initialized.
- The following code are taken from the book: Python Machine Learning Cook Book — Second Edition
https://medium.com/media/b9d3ea77cc85bc45921c16d0d53e2ffb/href
Now, we can build the encoder and decoder model.
https://medium.com/media/7eefae55b835e0f730c1a2f1dd21c16d/href
Now, we construct the model and the predictions
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
y_pred = decoder_op
y_true = X
In the following code, we define loss function and optimizer, and minimize the squared error, and define the evaluation metrics.
loss = tf.losses.mean_squared_error(y_true, y_pred)
optimizer = tf.train.RMSPropOptimizer(0.03).minimize(loss)
eval_x = tf.placeholder(tf.int32, )
eval_y = tf.placeholder(tf.int32, )
pre, pre_op = tf.metrics.precision(labels=eval_x, predictions=eval_y)
Because TensorFlow uses computational graphs for its operations, placeholders and variables must be initialized before they have values. So in the following code, we initialize the variables, then create an empty data frame to store the result table, which will be top 10 recommendations for every user.
init = tf.global_variables_initializer()
local_init = tf.local_variables_initializer()
pred_data = pd.DataFrame()
We can finally start training our model.
- We split training data into batches, and we feed the network with them.
- We train our model with vectors of user ratings, each vector represents a user and each column a book, and entries are ratings that the user gave to books.
- After a few trials, I discovered that training model for 100 epochs with a batch size of 35 would be consuming enough memories. This means that the entire training set will feed our neural network 100 times, every time using 35 users.
- At the end, we must make sure to remove user’s ratings in the training set. That is, we must not recommend books to a user in which he (or she) has already rated.
https://medium.com/media/fcd7f1ee4eb1aa50cc9c45ecd402244c/href
Finally, let’s see how our model works. I randomly selected a user, to see what books we should recommended to him (or her).
top_ten_ranked.loc[top_ten_ranked['User-ID'] == 278582]
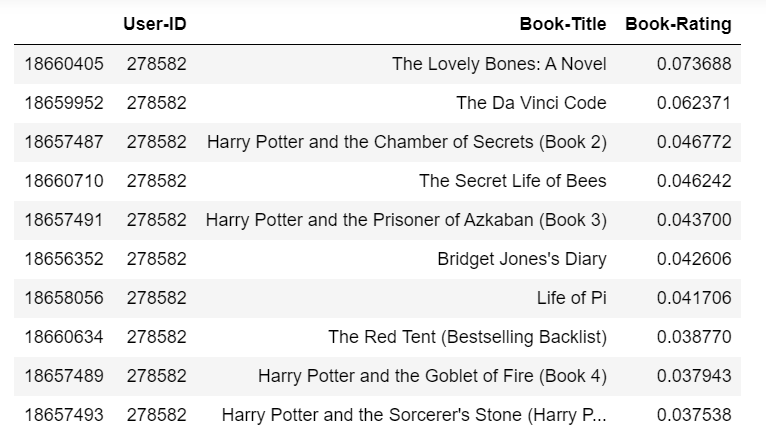
The above are the top 10 results for this user, sorted by the normalized predicted ratings.
Let’s see what books he (or she) has rated, sorted by ratings.
book_rating.loc[book_rating['User-ID'] == 278582].sort_values(by=['Book-Rating'], ascending=False)
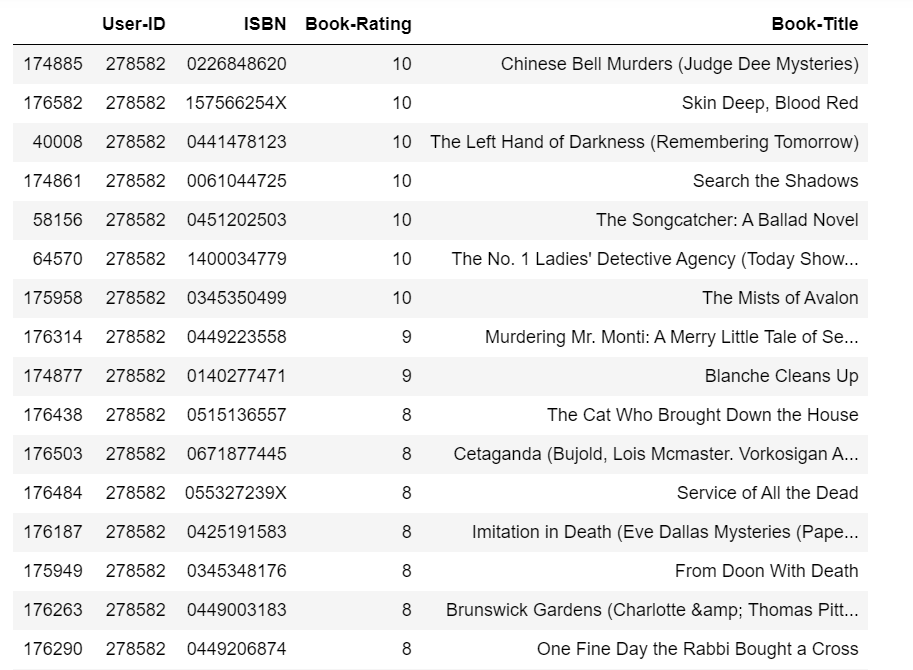
The types of the books this user liked are: historical mystery novel, thriller and suspense novel, science and fiction novel, fantasy novel and so on.
The top 10 results for this user are: murder fantasy novel, mystery thriller novel and so on.
The results were not disappointing.
The Jupyter notebook can be found on Github. Happy Friday!
References:
Python Machine Learning Cook Book — Second Edition
https://cloud.google.com/solutions/machine-learning/recommendation-system-tensorflow-overview
Building A Collaborative Filtering Recommender System with TensorFlow was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.