Announcing Google-Landmarks-v2: An Improved Dataset for Landmark Recognition & Retrieval
Last year we released Google-Landmarks, the largest world-wide landmark recognition dataset available at that time. In order to foster advancements in research on instance-level recognition (recognizing specific instances of objects, e.g. distinguishing Niagara Falls from just any waterfall) and image retrieval (matching a specific object in an input image to all other instances of that object in a catalog of reference images), we also hosted two Kaggle challenges, Landmark Recognition 2018 and Landmark Retrieval 2018, in which more than 500 teams of researchers and machine learning (ML) enthusiasts participated. However, both instance recognition and image retrieval methods require ever larger datasets in both the number of images and the variety of landmarks in order to train better and more robust systems.
In support of this goal, this year we are releasing Google-Landmarks-v2, a completely new, even larger landmark recognition dataset that includes over 5 million images (2x that of the first release) of more than 200 thousand different landmarks (an increase of 7x). Due to the difference in scale, this dataset is much more diverse and creates even greater challenges for state-of-the-art instance recognition approaches. Based on this new dataset, we are also announcing two new Kaggle challenges—Landmark Recognition 2019 and Landmark Retrieval 2019—and releasing the source code and model for Detect-to-Retrieve, a novel image representation suitable for retrieval of specific object instances.
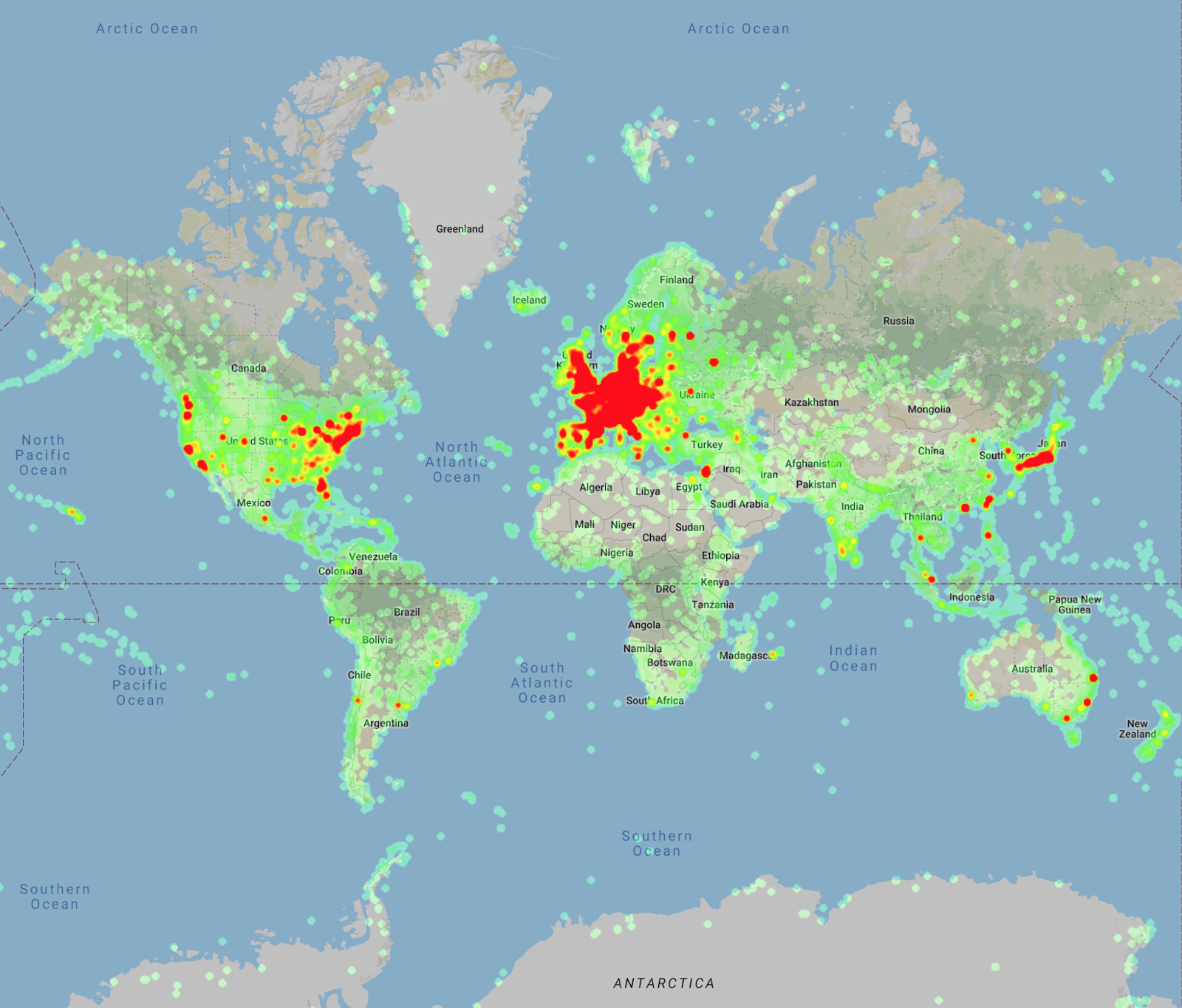 |
| Heatmap of the landmark locations in Google-Landmarks-v2, which demonstrates the increase in the scale of the dataset and the improved geographic coverage compared to last year’s dataset. |
{kind=link}
Creating the Dataset
A particular problem in preparing Google-Landmarks-v2 was the generation of instance labels for the landmarks represented, since it is virtually impossible for annotators to recognize all of the hundreds of thousands of landmarks that could potentially be present in a given photo. Our solution to this problem was to crowdsource the landmark labeling through the efforts of a world-spanning community of hobby photographers, each familiar with the landmarks in their region.
 |
| Selection of images from Google-Landmarks-v2. Landmarks include (left to right, top to bottom) Neuschwanstein Castle, Golden Gate Bridge, Kiyomizu-dera, Burj khalifa, Great Sphinx of Giza, and Machu Picchu. |
Another issue for research datasets is the requirement that images be shared freely and stored indefinitely, so that the dataset can be used to track the progress of research over a long period of time. As such, we sourced the Google-Landmarks-v2 images through Wikimedia Commons, capturing both world-famous and lesser-known, local landmarks while ensuring broad geographic coverage (thanks in part to Wiki Loves Monuments) and photos sourced from public institutions, including historical photographs that are valuable to test instance recognition over time.
The Kaggle Challenges
The goal of the Landmark Recognition 2019 challenge is to recognize a landmark presented in a query image, while the goal of Landmark Retrieval 2019 is to find all images showing that landmark. The challenges include cash prizes totaling $50,000 and the winning teams will be invited to present their methods at the Second Landmark Recognition Workshop at CVPR 2019.
Open Sourcing our Model
To foster research reproducibility and help push the field of instance recognition forward, we are also releasing open-source code for our new technique, called Detect-to-Retrieve (which will be presented as a paper in CVPR 2019). This new method leverages bounding boxes from an object detection model to give extra weight to image regions containing the class of interest, which significantly improves accuracy. The model we are releasing is trained on a subset of 86k images from the original Google-Landmarks dataset that were annotated with landmark bounding boxes. We are making these annotations available along with the original dataset here.
We invite researchers and ML enthusiasts to participate in the Landmark Recognition 2019 and Landmark Retrieval 2019 Kaggle challenges and to join the Second Landmark Recognition Workshop at CVPR 2019. We hope that this dataset will help advance the state-of-the-art in instance recognition and image retrieval. The data is being made available via the Common Visual Data Foundation.
Acknowledgments
The core contributors to this project are Andre Araujo, Bingyi Cao, Jack Sim and Tobias Weyand. We would like to thank our team members Daniel Kim, Emily Manoogian, Nicole Maffeo, and Hartwig Adam for their kind help. Thanks also to Marvin Teichmann and Menglong Zhu for their contribution to collecting the landmark bounding boxes and developing the Detect-to-Retrieve technique. We would like to thank Will Cukierski and Maggie Demkin for their help organizing the Kaggle challenge, Elan Hourticolon-Retzler, Yuan Gao, Qin Guo, Gang Huang, Yan Wang, Zhicheng Zheng for their help with data collection, Tsung-Yi Lin for his support with CVDF hosting, as well as our CVPR workshop co-organizers Bohyung Han, Shih-Fu Chang, Ondrej Chum, Torsten Sattler, Giorgos Tolias, and Xu Zhang. We have great appreciation for the Wikimedia Commons Community and their volunteer contributions to an invaluable photographic archive of the world’s cultural heritage. And finally, we’d like to thank the Common Visual Data Foundation for hosting the dataset.
