Amazon SageMaker Object2Vec adds new features that support automatic negative sampling and speed up training
Today, we introduce four new features of Amazon SageMaker Object2Vec: negative sampling, sparse gradient update, weight-sharing, and comparator operator customization. Amazon SageMaker Object2Vec is a general-purpose neural embedding algorithm. If you’re unfamiliar with Object2Vec, see the blog post Introduction to Amazon SageMaker Object2Vec, which provides a high-level overview of the algorithm with links to four notebook examples, one of which was added as part of this feature launch (Use Object2Vec to learn document embeddings). It also provides a link to the documentation page Object2Vec Algorithm, which provides further technical details. You can access these new features as the algorithm’s hyperparameters from the Amazon SageMaker console and using the high-level Amazon SageMaker Python API.
In this blog post we’ll discuss each of the following new features and show how it targets a customer pain point:
- Negative sampling: Previously, for use cases where only positively-labeled data are available (for example, the document embedding use case explained later in this post), customers need to implement negative sampling manually as part of data preprocessing. With the new negative sampling feature, Object2Vec automatically samples data that are unlikely observed and labels this data negative during training.
- Sparse gradient update: Previously, the algorithm’s training speed couldn’t scale to multiple GPUs and slowed down as the input vocabulary size became This is because by default, the MXNet optimizer calculates the full gradient even if most rows of the gradient are zero-valued, which not only causes unnecessary computation but also increases communication cost in a multi-GPU setup. Object2Vec with sparse gradient update speeds up single-GPU training without performance loss. In addition, the training speed can be further increased with multiple GPUs and is now independent of the vocabulary size.
- Weight sharing: Object2Vec has two encoders, each with its own token embedding layer, to encode data from two input For use cases where both sources are built on top of the same token-level units, it is common practice to jointly train the token embedding layers (known as weight-sharing in the deep learning community). The new weight sharing feature provides you with this option.
- Comparator operator customization: The comparator operator in the Object2Vec network architecture assembles the encoding vectors produced by the two encoders into Previously, this operator had been fixed, which may degrade the performance of the algorithm in some use cases (as we observed for document embedding; see Table 1). The new comparator_list parameter provides users with the flexibility to customize the comparator operator to their specific use case.
Accompanying this blog post is a new notebook example (Use Object2Vec to learn document embeddings) that demonstrates how to take advantage of all of the new features in a Document Embedding use-case. In this use case, a customer has a large collection of documents. Instead of storing these documents in their raw format or as sparse bag-of-words vectors, the customer wants to embed all documents in a common low-dimensional space, so that the semantic distances between these documents are preserved. Embedding documents this way has several useful applications, such as efficient nearest neighbor search, and as features in downstream tasks such as topical classification.
Negative sampling feature
Similar to the widely used Word2Vec algorithm for word embedding, a natural approach to document embedding is to preprocess documents as (sentence, context) pairs, where the sentence and its context come from the same document, such that the context is the entire document with the given sentence removed. The idea is to train encoders to embed both sentences and their contexts into a low dimensional space such that their mutual similarity is maximized, since they belong to the same document and therefore should be semantically related. The learned encoder for the context can then be used to encode new documents into the same embedding space. To train the encoders for sentences and documents, we also need negative (sentence, context) pairs so that the model can learn to discriminate between semantically similar and dissimilar pairs. It it’s easy to generate such negatives by pairing sentences with documents that they do not belong to. Since there are many more negative pairs than positives in naturally occurring data, we typically resort to random sampling techniques to achieve a balance between positive and negative pairs in the training data. The following figure shows how the positive pairs and negative pairs are generated from unlabeled data for the purpose of learning embeddings for documents (and sentences).
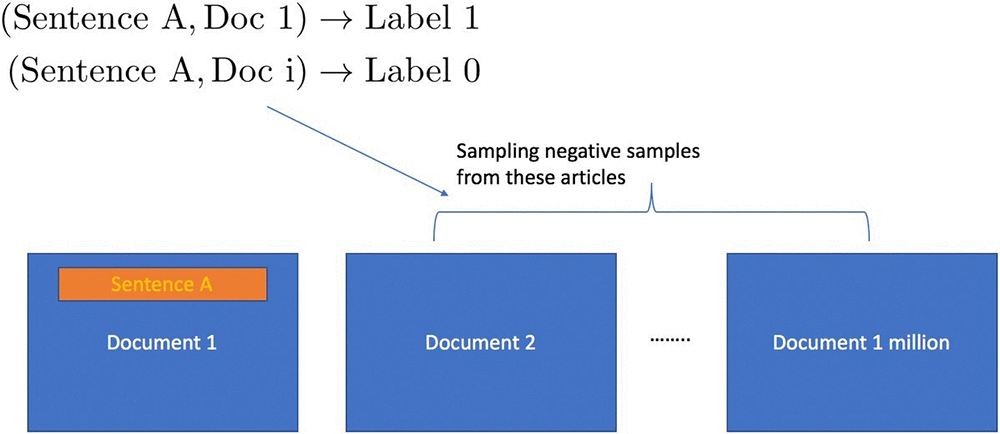
Typically, a user might be required to do the negative pair creation and sampling as a preprocessing step before training the algorithm. With the new negative_sampling_rate hyperparameter in Object2Vec, users only need to provide positively labeled data pairs, and the algorithm automatically generates and samples negative data internally during training. The value of the negative sampling rate represents the ratio of negative examples to positive examples desired by the user.
In the notebook, we set the negative_sampling_rate hyperparameter to be 3.
Running the notebook, the user can check from the training console output that the negative sampling is enabled and that the sampling rate is indeed 3.
![]()
In general, to determine the best negative_sampling_rate, users should try different values and choose the one that emits the best metric (e.g., cross-entropy for classification) on validation set.
Sparse gradient update
The new sparse gradient support takes advantage of the sparse input format of Object2Vec and speeds up the mini- batch gradient descent training by 2-20 times. Even larger speedup is observed with larger vocab_size.
In the notebook example, we turned on sparse gradient update by setting token_embedding_storage_type
The user can check that sparse gradient is indeed turned on by looking at the parameter summarization table in the training console output.
![]()
The following table shows the training speeds up with sparse gradient update feature switched on, as a function of number of GPUs, on Amazon EC2 P2 instances (see here for more information about p2 instances). Another benefit of using sparse gradient update is that, in contrast to full gradient updates, increasing the vocabulary size does not affect the training speed.
Speed gain with sparse gradient update
| num_gpus | Throughput (samples/sec) with dense embedding | Throughput with sparse embedding | max_seq_len (in0/in1) | Speedup X- times | |
| 1 | 1 | 5k | 14k | 50 | 2.8 |
| 2 | 2 | 2.7k | 23k | 50 | 8.5 |
| 3 | 3 | 2k | 24k | 50 | 10 |
| 4 | 4 | 2k | 23k | 50 | 10 |
| 5 | 8 | 1.1k | 19k | 50 | 20 |
| 6 | |||||
| 7 | 1 | 1.1k | 2k | 500 | 2 |
| 8 | 2 | 1.5k | 3.6k | 500 | 2.4 |
| 9 | 4 | 1.6k | 6k | 500 | 3.75 |
| 10 | 6 | 1.3k | 6.7k | 500 | 5.15 |
| 11 | 8 | 1.1k | 5.6k | 500 | 5 |
Weight-sharing of embedding layer
Object2Vec has two encoders. During training, the algorithm previously learned the input embeddings separately for each encoder. The new tied_token_embedding_weight hyperparameter gives the user the flexibility to share the token embedding layer for both encoders. In the document embedding use case, we have found better performance in the document embedding use case with weight-sharing.
In the notebook, we set the tied_token_embedding_weight hyperparameter to True:
The user can check that weight-sharing feature is on by looking at the training console output:
![]()
Customization of comparator operator
The comparator operator in Object2Vec architecture aggregates the outputs from two encoders. Previously, the comparator operator was fixed. The new comparator_list hyperparameter gives users the flexibility to customize their own comparator operator so that they can tune the algorithm towards optimal performance for their applications. The available binary operators are “hadamard” (element-wise product), “concat” (concatenation), and “abs_diff” (absolute difference). Users can mix and match any combination of the three or simply use one of them.
In the notebook, we customize comparator operator to use element-wise product only:
The user can check the comparator operator configuration by looking at the training console output:
![]()
The default comparator operator concatenates the result of all three operators. If users want to combine hadamard and abs_diff operators, then they simply need to write:
For different problems, we recommend that the user either use the default or find out the best combination using the validation set (or use cross-validation).
Experiment on document embedding and the retrieval downstream task
In the document embedding notebook, we train the Object2Vec model using simple pooled embedding based encoders for both sentences and documents on the training data created from unlabeled Wikipedia articles as described earlier. Since we have binary labeled data, we use the standard cross-entropy function as our training loss. We can evaluate the performance of the model using the same loss function or using accuracy on a binary labeled test data. The following table shows the effect of these features on these two metrics evaluated on a test set obtained from the same data creation process.
We see that when negative sampling and weight-sharing of embedding layer is switched on, and when we use a customized comparator operator (hadamard product), the model has improved test accuracy. When all of these features are combined together (last row of the table), the algorithm has the best performance as measured by accuracy and cross-entropy.
Test performance of combining new features on Wikipedia250k data
|
negative_sampling_rate |
Weight sharing |
Comparator operator | Test accuracy (higher is better) | Test cross entropy (lower is better) | |
|
1 |
Off |
Off |
Default (hadamard, concat, abs_diff) |
0.167 |
23 |
| 2 | 3 | Off | Default | 0.92 | 0.21 |
| 3 | 5 | Off | Default | 0.92 | 0.19 |
| 4 | Off | On | Default | 0.167 | 23 |
| 5 | 3 | On | Default | 0.93 | 0.18 |
| 6 | 5 | On | Default | 0.936 | 0.17 |
| 7 | Off | On | Customized (hadamard) | 0.17 | 23 |
| 8 | 3 | On | Customized | 0.93 | 0.18 |
| 9 | 5 | On | Customized | 0.94 | 0.17 |
After training the model, we can use the encoders in Object2Vec to map new articles and sentences into a shared embedding space. Then we evaluate the quality of these embeddings with a downstream document retrieval task.
In the retrieval task, given a sentence query, the trained algorithm needs to find its best matching document (the ground-truth document is the one that contains it) from a pool of documents, where the pool contains 10,000 other non-ground-truth documents. We use two metrics hits@k and mean rank to evaluate the retrieval performance. Note that the ground-truth documents in the pool have the query sentence removed from them, otherwise the task would have been trivial.
- hits@k: It calculates the fraction of queries where its best-matching (ground-truth) document is contained in top k retrieved documents by the algorithm
- mean rank: It is the average rank of the best-matching documents, as determined by the algorithm, over all queries
We compare the performance of Object2Vec with the StarSpace algorithm on the document retrieval evaluation task, using a set of 250,000 Wikipedia documents. The experimental results displayed in the following table, show that Object2Vec significantly outperforms StarSpace on all metrics although both models use the same kind of encoders for sentences and documents.
Document retrieval evaluation
| Algorithm | hits@1 | hits@10 | hits@20 | Mean rank (smaller the better) | |
| 1 | StarSpace | 21.98% | 42.77% | 50.55% | 303.34 |
| 2 | Object2Vec | 26.40% | 47.42% | 53.83% | 248.67 |
About the Authors
 Cheng Tang is an Applied Scientist in the Verticals and Applications Group at AWS AI. Broadly interested in machine learning research and its applications to the natural language processing domain, Cheng finds great inspiration to be part of both research and industrialization of machine learning/deep learning algorithms, and she is thrilled to see them delivered to the customers.
Cheng Tang is an Applied Scientist in the Verticals and Applications Group at AWS AI. Broadly interested in machine learning research and its applications to the natural language processing domain, Cheng finds great inspiration to be part of both research and industrialization of machine learning/deep learning algorithms, and she is thrilled to see them delivered to the customers.
 Patrick Ng is a Software Development Engineer in the Verticals and Applications Group at AWS AI. He works on building scalable distributed machine learning algorithms, with focus in the area of deep neural networks and natural language processing. Before Amazon, he obtained his PhD in Computer Science from the Cornell University and worked at startup companies building machine learning systems.
Patrick Ng is a Software Development Engineer in the Verticals and Applications Group at AWS AI. He works on building scalable distributed machine learning algorithms, with focus in the area of deep neural networks and natural language processing. Before Amazon, he obtained his PhD in Computer Science from the Cornell University and worked at startup companies building machine learning systems.
 Ramesh Nallapati is a Principal Applied Scientist in the Verticals and Applications Group at AWS AI. He works on building novel deep neural networks at scale primarily in the natural language processing domain. He is very passionate about deep learning, and enjoys learning about latest developments in AI and is excited about contributing to this field to the best of his abilities.
Ramesh Nallapati is a Principal Applied Scientist in the Verticals and Applications Group at AWS AI. He works on building novel deep neural networks at scale primarily in the natural language processing domain. He is very passionate about deep learning, and enjoys learning about latest developments in AI and is excited about contributing to this field to the best of his abilities.
 Bing Xiang is a Principal Scientist and Head of Verticals and Applications Group at AWS AI. He leads a team of scientists and engineers working on deep learning, machine learning, and natural language processing for multiple AWS services.
Bing Xiang is a Principal Scientist and Head of Verticals and Applications Group at AWS AI. He leads a team of scientists and engineers working on deep learning, machine learning, and natural language processing for multiple AWS services.
ACKNOWLEDGEMENT
We would like to thank Sr. Principal Engineer Leo Dirac for his kind help and useful discussion.