Run ONNX models with Amazon Elastic Inference
At re:Invent 2018, AWS announced Amazon Elastic Inference (EI), a new service that lets you attach just the right amount of GPU-powered inference acceleration to any Amazon EC2 instance. This is also available for Amazon SageMaker notebook instances and endpoints, bringing acceleration to built-in algorithms and to deep learning environments.
In this blog post, I show how to use the models in the ONNX Model Zoo on GitHub to perform inference by using MXNet with Elastic Inference Accelerator (EIA) as a backend.
The benefits of Amazon Elastic Inference
Amazon Elastic Inference allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Amazon SageMaker instances to reduce the cost of running deep learning inference by up to 75 percent.
Amazon Elastic Inference provides support for Apache MXNet, TensorFlow, and ONNX models. ONNX is an open standard format for deep learning models that enables interoperability between deep learning frameworks such as Apache MXNet, Caffe2, Microsoft Cognitive Toolkit (CNTK), PyTorch, and more. This means that you can use any of these frameworks to train a model, export the model in ONNX format, and then import them into Apache MXNet for inference.
You can see the collection of pre-trained, state-of-the-art models in ONNX format at the ONNX Model Zoo on GitHub.
Getting started with inference by using Resnet 152v1 model
To start with the tutorial, I use an AWS Deep Learning AMI (DLAMI), which already provides support for Apache MXNet, EIA, ONNX and other required libraries. You can review Elastic Inference Prerequisites for the instructions related to Elastic Inference. For detailed instructions on how to launch a DLAMI with an Elastic Inference Accelerator, see the Elastic Inference documentation. I use the standard ResNet-152v1 ONNX model from model zoo for inference in MXNet.
Step 1: Activate the MXNet EI environment
To begin the tutorial, log in to your Deep Learning AMI with Conda console. Activate the Python 3 MXNet EI environment.
Step 2: Import dependencies and download
From the ONNX model zoo, download both the Resnet-152v1 model and synset.txt file, which contains class labels.
Step 3: Import ONNX model in MXNet and perform inference
Import ONNX model in MXNet with the help of ONNX-MXNet API.
Load the resnet152v1 network for inference using CPU context.
Define a predict function, which takes the path of the input image and prints the top five predictions.
Plot the input image for inference.

Step 4: Generate prediction on input image
The top five classes, in order, along with the probabilities generated for the image displayed are as below.
Evaluate your output and improve performance
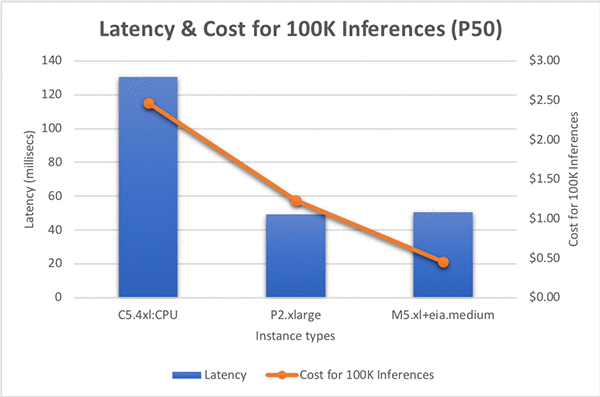
Inference on this model takes approximately 131 milliseconds on C5.4xlarge. So, for 100,000 inference requests, this would cost $2.46 USD. This can be expensive for production use cases. So, let’s look at how Amazon Elastic Inference can help.
Amazon Elastic Inference is available in the following three sizes, making it efficient for a wide range of inference models including computer vision, natural language processing, and speech recognition.
- eia1.medium: 8 teraflops of mixed-precision performance
- eia1.large: 16 teraflops of mixed-precision performance
- eia1.xlarge: 32 teraflops of mixed-precision performance
This lets you select the best price-to-performance ratio for your application. I ran the inference on the same model using GPU and EIA contexts to see the difference in the cost and performance.
To run the model with mx.eia() context, you just need to do minor changes in the code.
- With EIA context, when you use either the Symbol API or the Module API, make sure you set
for_training=False. - Set the context to bind your model as
ctx=mx.eia().
EI typically aims to minimize the host instance CPU memory requirements by offloading to the EI accelerator, but some pre and post-processing must still be done on the host. Depending on the application’s compute and memory requirements, you can select the instance types that are most appropriate.
I evaluated performance of this model with C5 and M5 instances but found that this model required more CPU memory. The M5 instances with more RAM were the most cost effective solution. I ran tests with a few different sized M5 instances with an EIA1.Medium accelerator and observed that instance sizes larger than the M5.xlarge didn’t materially improve latency performance. Next, I tested the M5.xlarge with different EI accelerator sizes. Inference calls with an EIA1.large accelerator were significantly faster than an EIA1.Medium, but my EIA1.Medium at 50ms for an inference request met my requirements, so I didn’t need more horsepower.
Based on my requirements, I decided on an M5.xlarge with an EIA1.Medium as the right infrastructure combination for my workload. Comparing the hourly costs for the instances in our comparison: a P2.xlarge cost $0.90 per hour, whereas the M5.xlarge + EIA1.Medium costs $0.32 per hour, and lastly the C5.4xlarge is $0.68 per hour. But let’s also compare the cost to perform 100,000 inferences, this will incorporate hourly cost and performance to give us a meaningful comparison. The P2.xlarge costs $1.23 to execute 100,000 inferences, whereas this new EI based combination costs $0.45, a whopping 74% reduction in cost, sacrificing just 2% speed. If you use C5.4xlarge, it costs $2.47 and is 2.5x slower than M5.xlarge with EIA1.Medium! See the graph below for more information:
Conclusion
As you can see from the tutorial here, Amazon Elastic Inference gives you the opportunity to select the best price-to-performance ratio suitable for your application. For ONNX ResNet152 model inference, EIA1.medium is 2.5x faster and 81% cheaper than C5.4xlarge! Also with ONNX support, you can export models trained in different deep learning frameworks to run inference with EIA using Apache MXNet as a backend.
For general information about how to use EI, see Working with Amazon EI in the EC2 user guide. You can also find more information about ONNX support in MXNet, in the ONNX API documentation on the MXNet website.
About the Authors

Roshani Nagmote is a Software Developer for AWS Deep Learning. She focusses on building distributed Deep Learning systems and innovative tools to make Deep Learning accessible for all. In her spare time, she enjoys hiking, exploring new places and is a huge dog lover.
 Vandana Kannan is a Software Developer for AWS Deep Learning focusing on building scalable deep learning systems. In her spare time, she enjoys painting, learning Indian classical dance, and spending time with family and friends.
Vandana Kannan is a Software Developer for AWS Deep Learning focusing on building scalable deep learning systems. In her spare time, she enjoys painting, learning Indian classical dance, and spending time with family and friends.
 Hagay Lupesko is an Engineering Manager for AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys reading, hiking and spending time with his family.
Hagay Lupesko is an Engineering Manager for AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys reading, hiking and spending time with his family.