Build a serverless Twitter reader using AWS Fargate
In a previous post, Ben Snively and Viral Desai showed us how to build a social media dashboard using serverless technology. The social media dashboard reads tweets with the #AWS hashtag, uses machine learning based services to do translation, and natural language processing (NLP) to determine topics, entities, and sentiment analysis. Finally, it aggregates this information using Amazon Athena and builds dashboards to visualize the information captured from the tweets. In this architecture, the only server to manage is running the application that reads the Twitter feed. In this blog post we’ll walk you through the steps to move this application to a Docker container and execute it in Amazon ECS with AWS Fargate. This removes the need to manage any Amazon EC2 instances in the architecture.
AWS Fargate is a technology for Amazon Elastic Container Service (ECS) that allows you to run containers without having to manage servers or clusters. With AWS Fargate, you no longer have to provision, configure, and scale clusters of virtual machines to run containers. This removes the need to choose server types, decide when to scale your clusters, or optimize cluster packing. AWS Fargate removes the need for you to interact with or think about servers or clusters. Using AWS Fargate you can focus on designing and building your container applications, instead of managing the infrastructure that runs them.
AWS Fargate is a great approach if you want to eliminate operational responsibilities with Amazon EC2. AWS Fargate is fully integrated with the AWS Code services such as AWS CodeStar, AWS CodeBuild, AWS CodeDeploy, and AWS CodePipeline, making it very simple to configure an end-to-end continuous delivery pipeline to automate deployments to ECS.
Run tweet-reading app on Fargate
As you follow this blog post, you’ll set up an architecture that looks like this:
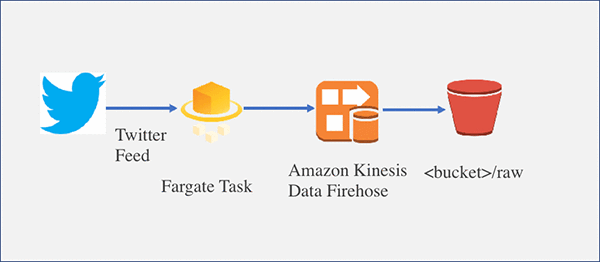
Our focus for this blog post is to move the Twitter stream producer app from running in an EC2 instance to running in containers managed by Fargate.
We’ll start by creating a Docker image that has our code for the Twitter feed reader application, plus all of its dependencies. After we have the Docker image, we’ll upload and register this image to ECR, which serves as a repository for Docker images. With the image registered in ECR, we are going to create a task definition, which describes the configuration we want to set for running our Docker container in the Fargate service. Finally, we are going to run the task and test our app.
Prerequisites
- Go to the previous blog post and follow the instructions found there. The high level steps are:
- Launching the AWS CloudFormation template. When you launch the template you need to provide the Twitter API configuration parameters.
- After the CloudFormation stack is created go to the AWS Management Console, search for the stack and choose the Resources Take note of the Physical ID of the IngestionFirehoseStream resource. It will be something like: SocialMediaAnalyticsBlogPo-IngestionFirehoseStream-<ID>

- Setting up S3 Notification – Call Amazon Translate/Comprehend from new Tweets.
- Start the Twitter stream producer. This is the application that is running in an EC2 instance.
- Create the Athena tables. This is done by running four different SQL statements.
- (optional – recommended) Building Amazon QuickSight dashboards.
After you complete all the steps you should have following architecture deployed on your environment: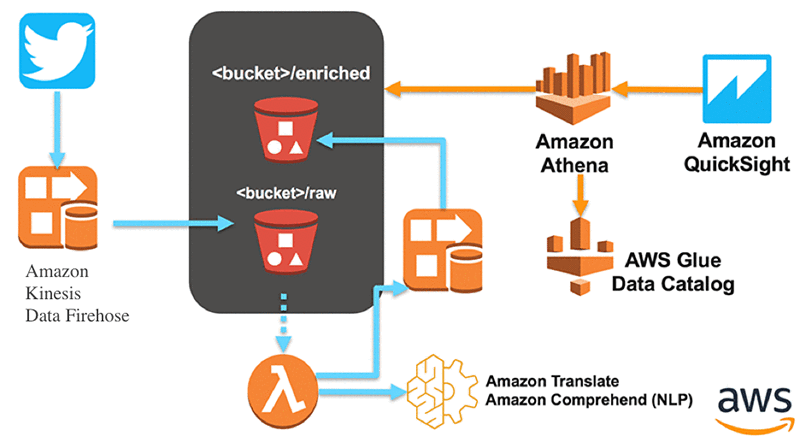
- Configure an environment where you can run AWS CLI and Docker commands. You can launch an EC2 instance and install Docker or you can use AWS Cloud9, which comes with Docker. We used an EC2 instance and installed Docker in it. If you decide to go with the EC2 option, you’ll need to create an IAM role and attach it to the instance.
We are going to refer this environment as the “Dev Environment” in the following steps. We will use the Dev Environment to create our Docker image and register the image with the ECR service. This environment will need permission to use Amazon Kinesis Data Firehose, ECR, and IAM APIs.
Note: You need to install the AWS CLI on the Docker environment. For AWS CLI installation, refer this page.
Step 1: Create the Docker image
To create the Docker image, first we need to create a Dockerfile. A Dockerfile is a manifest that describes the base image to use for your Docker image and what you want installed and running on it. For more information about Dockerfiles, go to the Dockerfile Reference. In our case, we want to create a Docker image that we use to instantiate containers that run Node applications. In particular, we want to run our Twitter stream producer node app.
- Choose a directory in the Docker environment and perform the following steps in that directory. I used /home/ec2-user directory to perform the following steps.
- Download the application code to our Dev Environment. When you executed the instructions in the prerequisites section 1.a, a CloudFormation template was used to create a stack called SocialMediaAnalyticsBlogPost. This stack configures the EC2 instance with the Twitter stream producer app. If you open the CloudFormation file and go to the EC2 configuration section (line 229 in the template), you will find that the application code was copied from an Amazon S3 bucket to the EC2 instance. We want to copy the same code to our Dev Environment. Use the following command:
- Now we are going to do a small refactor on the SocialAnalyticsReader app. The Node application is currently designed to read the Twitter API credentials from a configuration file. We want to avoid this approach after the application runs on a container. A better way is to store the configuration settings on a service like AWS Systems Manager Parameter Store. Extracting the configuration settings increases the flexibility and reusability of our container image. For example, it allows us to change the configuration values for the application without the need of rebuilding the Docker image.Replace the contents of the following files:twitter_stream_producer_app.js
twitter_stream_producer.js
If you compare the new files with the original version, you will notice that only a few lines of code were changed. In summary, our application will now use the AWS Node SDK to retrieve configuration settings from AWS Systems Manager Parameter store instead of retrieving them from a config file. For additional information on recommended approaches for handling configuration and secrets on containers, we recommend this blog post.
- Navigate back to /home/ec2-user directory and create a file called Dockerfile (case sensitive) with the following content:
- After completing these steps, your directory structure will look like this:

Step 2: Build the Docker image
Build the Docker image by running this command from the directory where you created the Dockerfile in the Docker environment in the previous step (I ran it from /home/ec2-user directory):
Output: It installs various packages and sets environment variables as part of building the image from the Dockerfile. The steps 5 to 10 from the Dockerfile should produce an output similar to the following:
Step 3: Push the Docker image to Amazon Elastic Container Registry (ECR)
Now we are going to upload the Docker image we just built to Amazon Elastic Container Registry (ECR), a fully-managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images. Amazon ECR is integrated with Amazon Elastic Container Service (ECS), simplifying your development to production workflow.
Perform the following steps in the Dev Environment.
- Run the following aws configure command and set the default Region to be us-east-1.
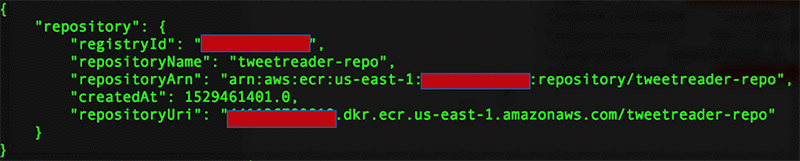
- Create an Amazon ECR repository using this command (note the repositoryUri in the output):
Output:
- Tag the tweetreader image with the repositoryUri value from the previous step using this command:
- Get the Docker login credentials using the following command:
- Run the Docker login command returned from the previous step. If the command is successful, you will get a message “Login Succeeded.”
- Push the Docker image to Amazon ECR with the repositoryUri from step 1 using this command:
Step 4: Store configuration information in AWS Systems Manager Parameter Store
Now we are going to store application configuration information in AWS Systems Manager Parameter Store, which provides hierarchical storage for configuration data management and secrets management. You can store data such as passwords, database strings, and license codes as parameter values. By storing our configuration parameters outside the container we improve the security posture by separating this data from the code and enabling us to control and audit access at granular levels.
- Go to the AWS Management Console and navigate to the AWS Systems Manager console.
- In the navigation pane at the left, scroll to the bottom and choose Parameter Store and then choose create parameter at the top right.
For name use : /twitter-reader/aws-configFor type: select StringFor Value:- Update the placeholders VAL1 through VAL4 with the values corresponding to your Twitter API credentials.
- Update the placeholder VAL5 with the value captured in the Prerequisites section step b IngestionFirehoseStream physical ID.
- The value will be something like
SocialMediaAnalyticsBlogPo-IngestionFirehoseStream-<value> - Choose Create Parameter.

Step 5: Create Fargate task definition and cluster
Now we are going to configure a task for Amazon ECS using AWS Fargate as the launch type. The Fargate launch type allows you to run your containerized applications without the need to provision and manage the backend infrastructure.
- Create a text file called trustpolicyforecs.json with the following content in the DevEnvironment:
- Create a role called AccessRoleForTweetReaderfromFG using the following command in the DevEnvironment:
- Attach Kinesis Data Firehose and Systems Manager IAM policies to the role created in step 2 using the following commands in the DockerEnvironment:
AccessRoleForTweetReaderfromFG is the IAM role that will be assumed by the task running on ECS. Our task is running the Node application and only needs IAM policies to write records to Kinesis Data Firehose and read configuration information from AWS Systems Manager Parameter Store.
- In the Amazon ECS console, choose Repositories and select the tweetreader-repo repository that was created in the previous step. Copy the Repository URI.

- Choose Task Definitions and then choose Create New Task Definition.
- Select launch type compatibility as FARGATE and click Next Step.
- In the create task definition screen, do the following:
- In Task Definition Name, type tweetreader-task
- In Task Role, choose AccessRoleForTweetReaderfromFG
- In Task Memory, choose 2GB
- In Task CPU, choose 1 vCPU

- Choose Add Container under Container Definitions. On the Add Container page, do the following:
- Enter Container name as tweetreader-cont
- Enter Image URL copied from step 1
- Enter Memory Limits as 128 and choose Add.
Note: Select TaskExecutionRole as “ecsTaskExecutionRole” if it already exists. If not, select Create new role and it will create “ecsTaskExecutionRole” for you.
- Choose the Create button on the task definition screen to create the task. It will successfully create the task, execution role and Amazon CloudWatch Logs groups.
- In the Amazon ECS console, choose Clusters and create cluster. Select template as “Networking only, Powered by AWS Fargate” and chooose the next step.
- Enter cluster name as tweetreader-cluster and choose Create.

Step 6: Start the Fargate task and verify the application
- In the Amazon ECS console, go to Task Definitions, select the tweetreader-task, choose Actions, and then choose Run Task.
- On the Run Task page, for Launch Type select Fargate, for Cluster select tweetreader-cluster, select Cluster VPC and Subnets values, and then choose Run Task.
- To test the application, choose the running task in the Fargate console. Go to the logs tab and verify there is nothing there. This means the node application is running and no errors occurred. After you have verified that the Fargate task does not have any error logs, navigate to the Amazon S3 console and go to the bucket that was created as part of the CloudFormation template in the original blog post. You will see a folder called raw. Check the contents of this folder. It should have the data sent from our Twitter feed reader app to serverless processing flow (Amazon Kinesis Data Firehose, Amazon Lex, Amazon Translate, Amazon Athena )
Conclusion
Congratulations! You have successfully ‘containerized’ an application that was previously running on an EC2 instance. Furthermore, you are running the container with Amazon ECS and AWS Fargate so you don’t need to provision or manage any EC2 instances. You can also tweak the task definition configuration in AWS Fargate by tuning the amount of memory, CPU, and concurrent executions your task might need.
For more information about working with ECS and Fargate, see the AWS Fargate documentation.
About the Authors
 Raja Mani is a Solution Architect supporting AWS partners. He is interested in Serverless development, DevOps, Containers, Big Data and Machine Learning. He is helping AWS partners to architect the enterprise-grade Amazon Web Services Solutions for their customers.
Raja Mani is a Solution Architect supporting AWS partners. He is interested in Serverless development, DevOps, Containers, Big Data and Machine Learning. He is helping AWS partners to architect the enterprise-grade Amazon Web Services Solutions for their customers.
 Luis Pineda is a Partner Solutions Architect at Amazon Web Services based in Chicago. He works with our partners and customers to solve business problems using AWS. Outside of work, Luis enjoys being outdoors, running, cycling and soccer.
Luis Pineda is a Partner Solutions Architect at Amazon Web Services based in Chicago. He works with our partners and customers to solve business problems using AWS. Outside of work, Luis enjoys being outdoors, running, cycling and soccer.