Now use Pipe mode with CSV datasets for faster training on Amazon SageMaker built-in algorithms
Amazon SageMaker built-in algorithms now support Pipe mode for fetching datasets in CSV format from Amazon Simple Storage Service (S3) into Amazon SageMaker while training machine learning (ML) models.
With Pipe input mode, the data is streamed directly to the algorithm container while model training is in progress. This is unlike File mode, which downloads data to the local Amazon Elastic Block Store (EBS) volume prior to starting the training. Using Pipe mode your training jobs start faster, use significantly less disk space and finish sooner. This reduces your overall cost to train machine learning models. In some of our internal benchmarks that trained a regression model with the Amazon SageMaker Linear Learner algorithm on a 3.9 GB CSV dataset, the overall time to train the model was reduced by up to 40 percent by using Pipe mode instead of File mode. You can read more about Pipe mode and its benefits in this blog post.
Using Pipe mode with Amazon SageMaker Built-in Algorithms
Earlier this year when we first released the Pipe input mode for the built-in Amazon SageMaker algorithms, it supported data only in protobuf recordIO format. This is a special format designed specifically for high-throughput training jobs. With today’s release we are extending the performance benefits of the Pipe input mode to your training datasets in CSV format as well. The following Amazon SageMaker built-in algorithms now have full support for training with datasets in CSV format using Pipe input mode:
- Principal Component Analysis (PCA)
- K-Means Clustering
- K-Nearest Neighbors
- Linear Learner (Classification and Regression)
- Neural Topic Modelling
- Random Cut Forest
To start benefiting from this new feature in your training jobs just specify the Amazon S3 location of your CSV dataset as usual and pick “Pipe” instead of “File” as your input mode. Your CSV datasets will be streamed seamlessly with no data formatting or code changes required at your end.
Faster Training using CSV optimized Pipe Mode
The new Pipe mode implementation for datasets in CSV format is a highly optimized, high throughput process. To demonstrate performance gains from using Pipe input mode, we trained the Amazon SageMaker Linear Learner algorithms over two synthetic CSV datasets.
The first dataset – a 3.9 GB CSV file– contained 2 million records, each record having 100 comma-separated, single-precision floating-point values. The following is a comparison of the overall training job execution time and model training times between Pipe mode and File mode while training the Amazon SageMaker Linear Learner algorithm with a batch size of 1000.
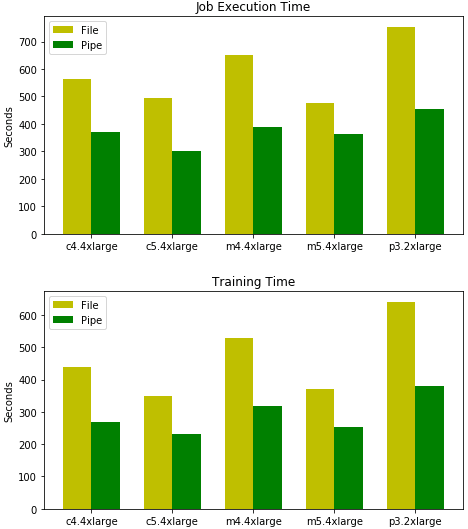
As you can see, using Pipe input mode with CSV datasets reduces the total time-to-train the model by up to 40 percent across few of the instance types supported by Amazon SageMaker.
Our second dataset – a 1 GB CSV file–had only 400 records, however each record had 100,000 comma-separated single-precision floating-point values. We repeated the earlier training benchmarks with a batch size of 10.
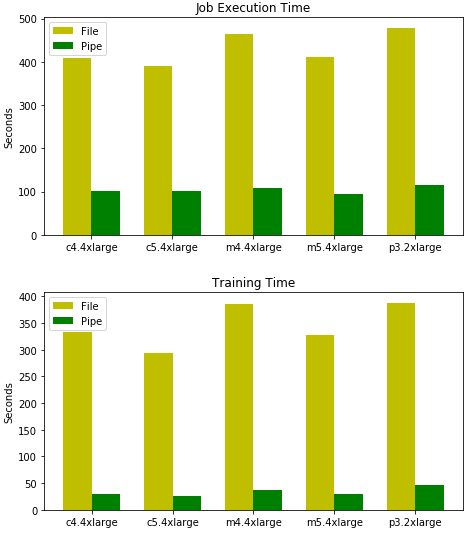
This time the performance gain from using Pipe mode is even more significant, to an order of 75 percent reduction in total-time-to-train the model.
Both experiments clearly show that using Pipe input mode brings a dramatic performance improvement. Your training jobs can avoid any startup delays caused by downloading datasets to the training instances, and they can have a much higher data read throughput.
Get started with Amazon SageMaker
You can easily get started with Amazon SageMaker using our sample notebooks. You can also look at our developer guide for more resources and subscribe to our discussion forum for new launch announcements.
About the Authors
 Can Balioglu is a Software Development Engineer on the AWS AI Algorithms team where he is specialized in high-performance computing. In his spare time he loves to play with his homemade GPU cluster.
Can Balioglu is a Software Development Engineer on the AWS AI Algorithms team where he is specialized in high-performance computing. In his spare time he loves to play with his homemade GPU cluster.
 Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.
Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.