Accelerate model training using faster Pipe mode on Amazon SageMaker
Amazon SageMaker now comes with a faster Pipe mode implementation, significantly accelerating the speeds at which data can be streamed from Amazon Simple Storage Service (S3) into Amazon SageMaker while training machine learning models.
Pipe mode offers significantly better read throughput than the File mode that downloads data to the local Amazon Elastic Block Store (EBS) volume prior to starting the model training. This means your training jobs start sooner, finish quicker, and need less disk space, reducing your overall cost to train machine learning models on Amazon SageMaker. For example, we conducted internal benchmarks earlier this year when we launched Pipe Input Mode for Amazon SageMaker built-in algorithms. We learned that start times were reduced by up to 87 percent on a 78 GB training dataset. In addition, we saw that throughput was twice as fast in some benchmarks, resulting in up to 35 percent reduction in total training time.
Overview
Amazon SageMaker supports two mechanisms for transferring training data: File mode and Pipe mode. In File mode, the training data is downloaded first to an encrypted EBS volume attached to the training instance prior to commencing the training. However, in Pipe mode the input data is streamed directly to the training algorithm while it is running. This continuous streaming of data enables a few significant advantages. First, the startup time of a training job becomes independent of the size of the input data, resulting in much quicker startup, especially while training on gigabyte- and petabyte-scale datasets. Furthermore, you don’t have to pay for a large disk volume to download large datasets. Finally, if your training algorithm is I/O-bound, the highly concurrent, high-throughput reading mechanism employed by Pipe mode can significantly speed up your model training.
Higher I/O throughput with faster Pipe mode
The latest implementation of Pipe mode provides higher data streaming throughputs than before. The following chart demonstrates the throughput improvements in Pipe mode compared to when we launched Pipe mode support earlier this year. For apples to apples comparison, the streaming throughput numbers are baselined against that of File mode as measured across instance types supported by Amazon SageMaker training.
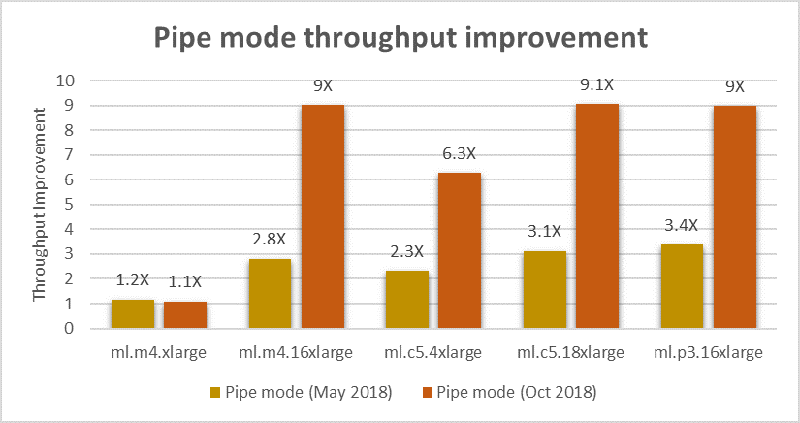
As you can see, streaming training data using Pipe mode is now up to three times faster than before in some cases. Pipe mode support is available out of the box for Amazon SageMaker built-in algorithms. Now we will present an example of how you can take advantage of the Pipe mode if you are bringing your own custom training algorithms to Amazon SageMaker.
Writing Pipe mode training code
In Pipe mode, data is pre-fetched from Amazon S3 at high-concurrency and throughput and streamed into Unix Named Pipes (aka FIFOs). There is one FIFO per channel per epoch. The algorithm must open the FIFO for reading and read through to <EOF> (or optionally abort mid-stream). It must close its end-of-the-file descriptor when done. It can then optionally wait for the next epoch’s FIFO to get created and then it can commence reading. The algorithm iterates through epochs until achieves its completion criteria.
This notebook example has an extremely simple Pipe mode “training” algorithm implementation in Python. It conforms to the specifications required by Amazon SageMaker training It reads data in Pipe mode but does nothing with the data. It simply reads it and throws it away. The example is written this way to illustrate exactly what’s needed to support Pipe mode without complicating the code with a real training algorithm.
The train.py Python program contains the code. The following code snippet iterates through reading each epoch’s data through its corresponding FIFO:
Using Pipe mode versus File mode
There are a few situations where Pipe mode may not be the optimum choice for training. In that case you should stick to using File mode:
- If your algorithm needs to backtrack or skip ahead within an epoch. This isn’t possible in Pipe mode because the underlying FIFO cannot support lseek() operations.
- If your training dataset is small enough to fit in memory and you need to run multiple epochs. In this case it might be quicker and easier just to load it all into memory and iterate.
- If it is not easy to parse your training dataset from a streaming source.
In all other scenarios, if you have an I/O-bound training algorithm, switching to Pipe mode should give you a significant throughput-boost as well as reduce the size of the disk volume required. This should result in both saving you time and reducing training costs.
About the authors
 Ishaaq Chandy is a Senior Engineer in Amazon AI where he loves his work in building an innovative and massively scalable training platform for Amazon Sagemaker. Prior to this he was working on AWS ELB where he was part of the launch teams for both ALB as well as NLB.
Ishaaq Chandy is a Senior Engineer in Amazon AI where he loves his work in building an innovative and massively scalable training platform for Amazon Sagemaker. Prior to this he was working on AWS ELB where he was part of the launch teams for both ALB as well as NLB.
 Sumit Thakur works on products that make it quick and easy for customers to get started with deep learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.
Sumit Thakur works on products that make it quick and easy for customers to get started with deep learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.