The On-Device Machine Learning Behind Recorder
Over the past two decades, Google has made information widely accessible through search — from textual information, photos and videos, to maps and jobs. But much of the world’s information is conveyed through speech. Yet even though many people use audio recording devices to capture important information in conversations, interviews, lectures and more, it can be very difficult to later parse through hours of recordings to identify and extract information of interest. But what if there was the ability to automatically transcribe and tag long recordings in real-time, enabling you to intuitively find the relevant information you need, when you need it?
For this reason, we launched Recorder, a new kind of audio recording app for Pixel phones that leverages recent developments in on-device machine learning (ML) to transcribe conversations, to detect and identify the type of audio recorded (from broad categories like music or speech to particular sounds, such as applause, laughter and whistling), and to index recordings so users can quickly find and extract segments of interest. All of these features run entirely on-device, without the need for an internet connection.
Transcription
Recorder transcribes speech in real-time using an on-device automatic speech recognition model based on improvements announced earlier this year. Being a key component to many of Recorder’s smart features, we made sure that this model can transcribe long audio recordings (a few hours) reliably, while also indexing conversation by mapping words to timestamps as computed by the speech recognition model. This enables the user to click on a word in the transcription and initiate playback starting from that point in the recording, or to search for a word and jump to the exact point in the recording where it was being said.
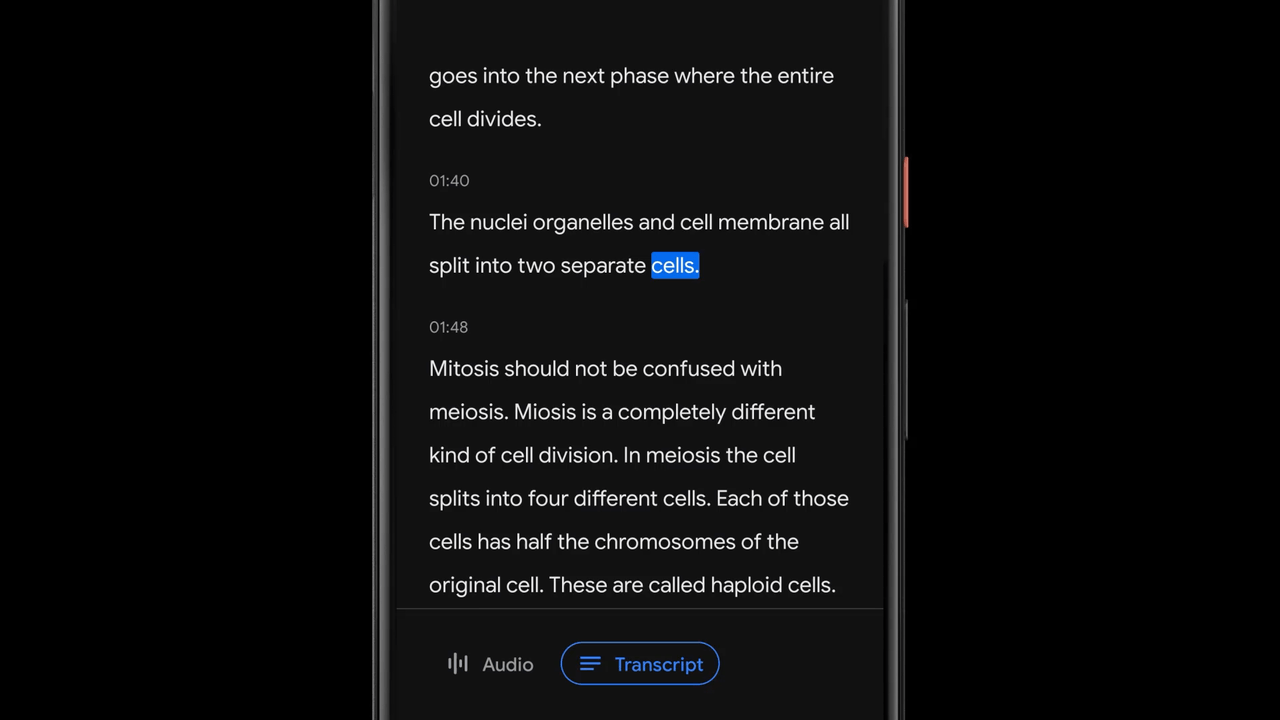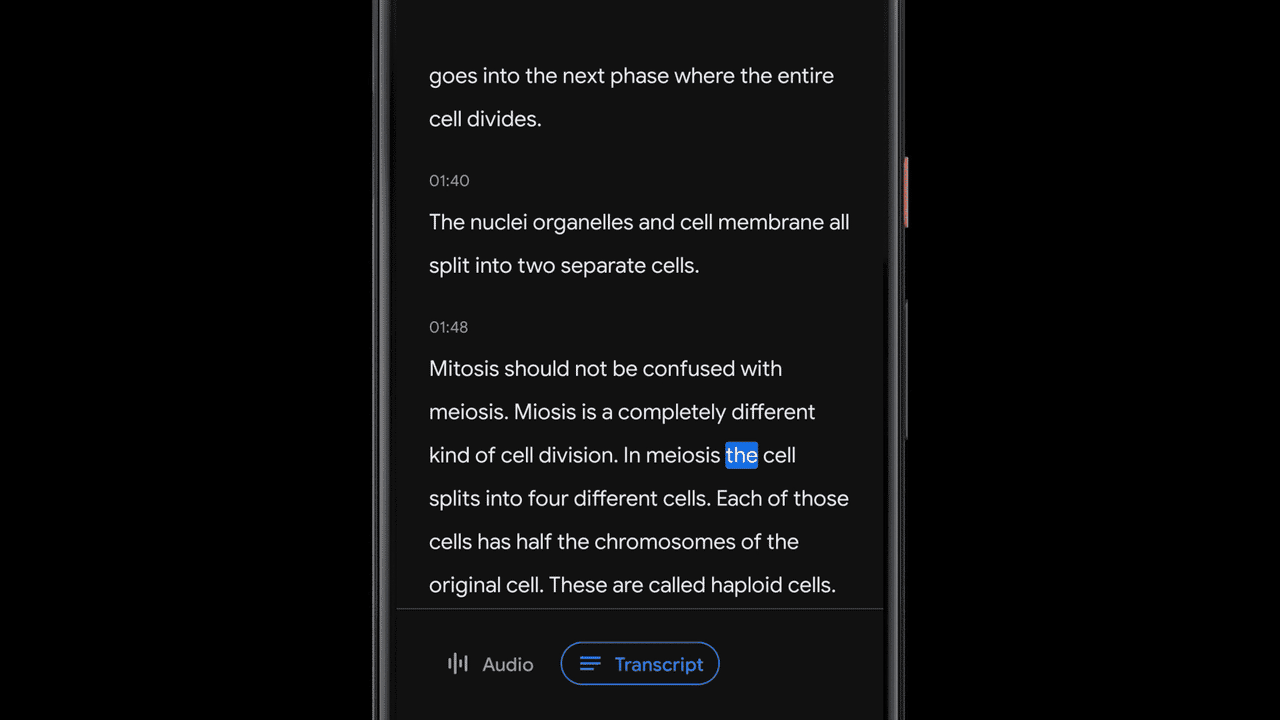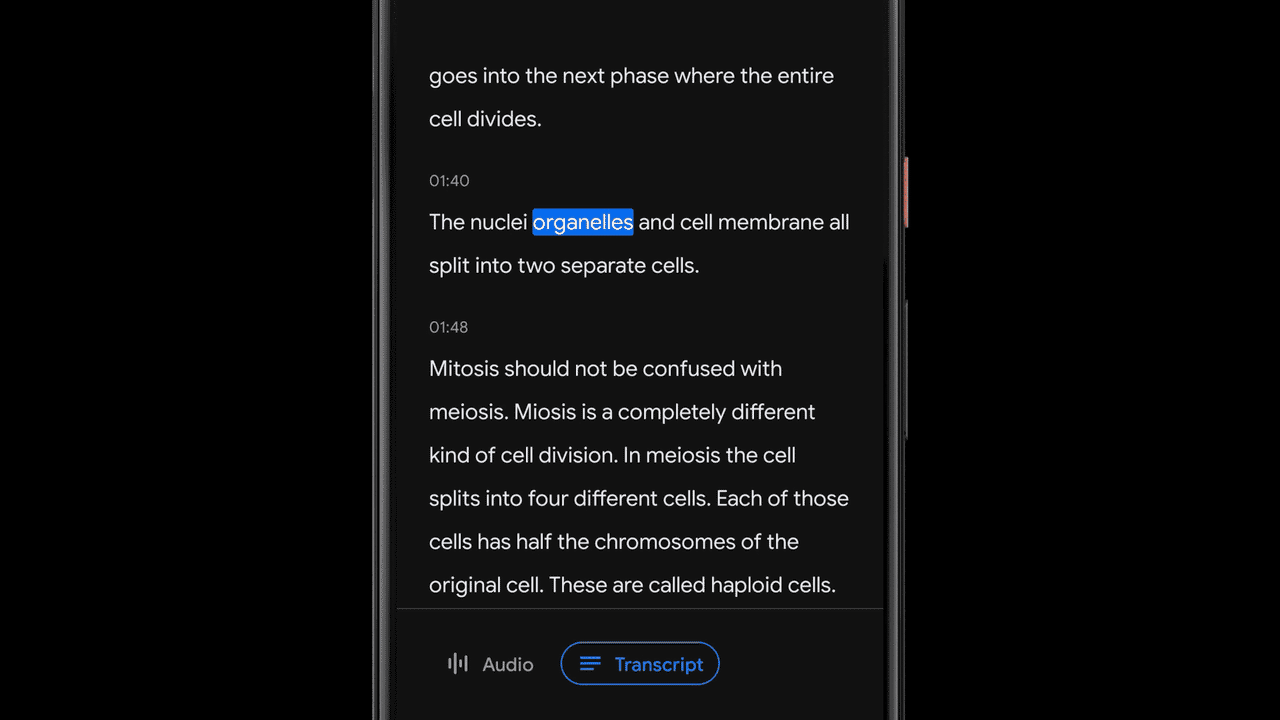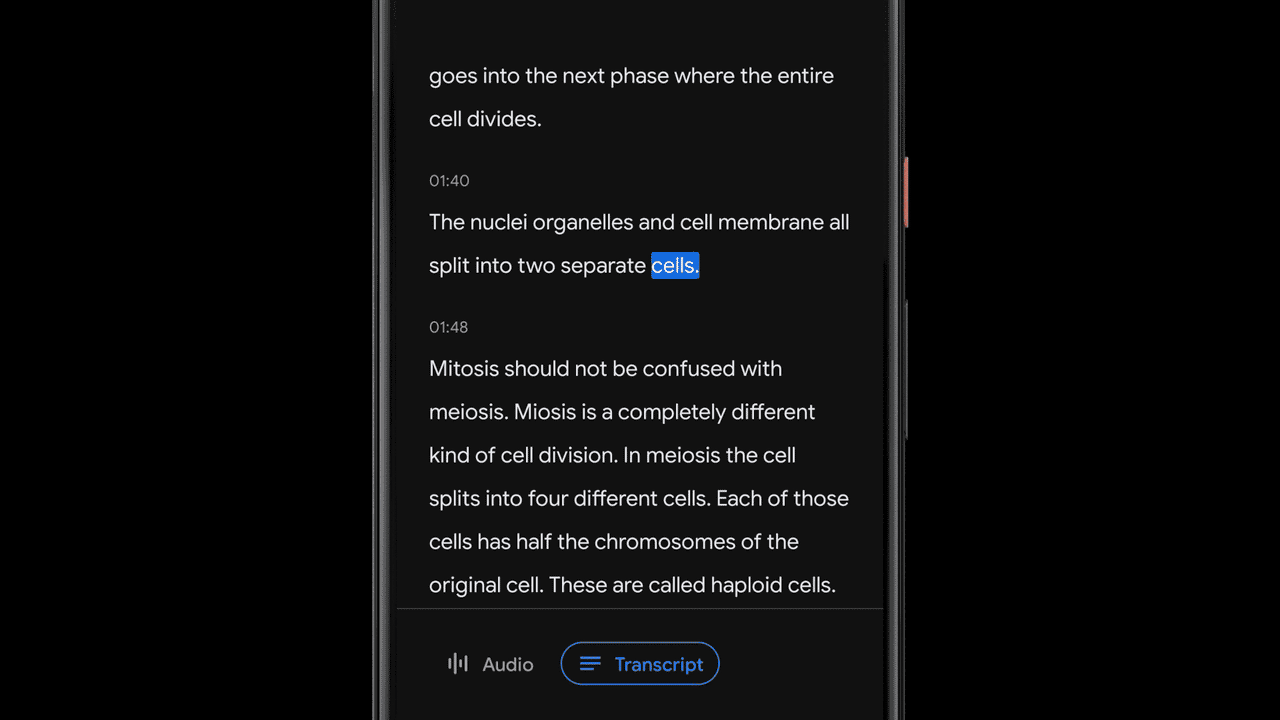
Recording Content Visualization via Sound Classification
While presenting a transcript for a recording is useful and allows one to search for specific words, sometimes (especially for very long recordings) it’s more useful to visually search for sections of a recording based on specific moments or sounds. To enable this, Recorder additionally represents audio visually as a colored waveform where each color is associated with a different sound category. This is done by combining research into using CNNs to classify audio sounds (e.g., identifying a dog barking or a musical instrument playing) with previously published datasets for audio event detection to classify apparent sound events in individual audio frames.
Of course, in most situations many sounds can appear at the same time. In order to visualize the audio in a very clear way, we decided to color each waveform bar in a single color that represents the most dominant sound in a given time frame (in our case, 50ms bars). The colorized waveform lets users understand what type of content was captured in a specific recording and navigate along an ever-growing audio library more easily. This brings a visual representation of the audio recordings to the users, and also enables them to search over audio events in their recordings.
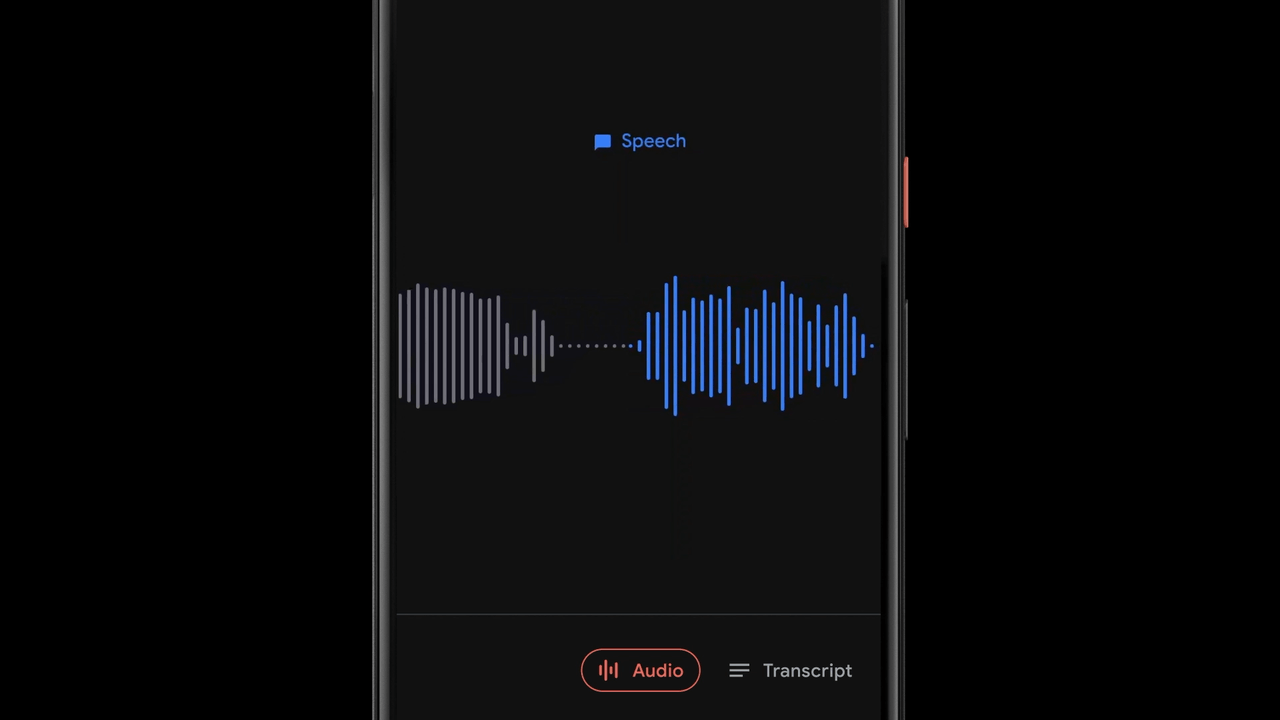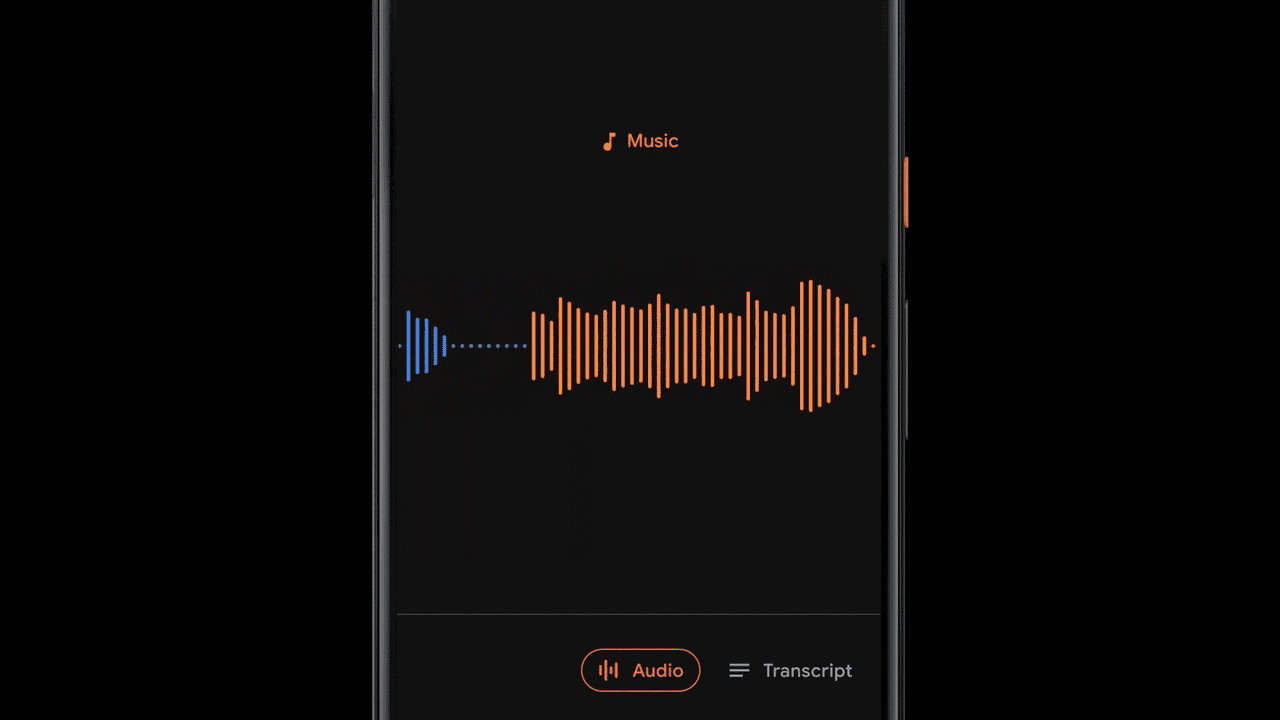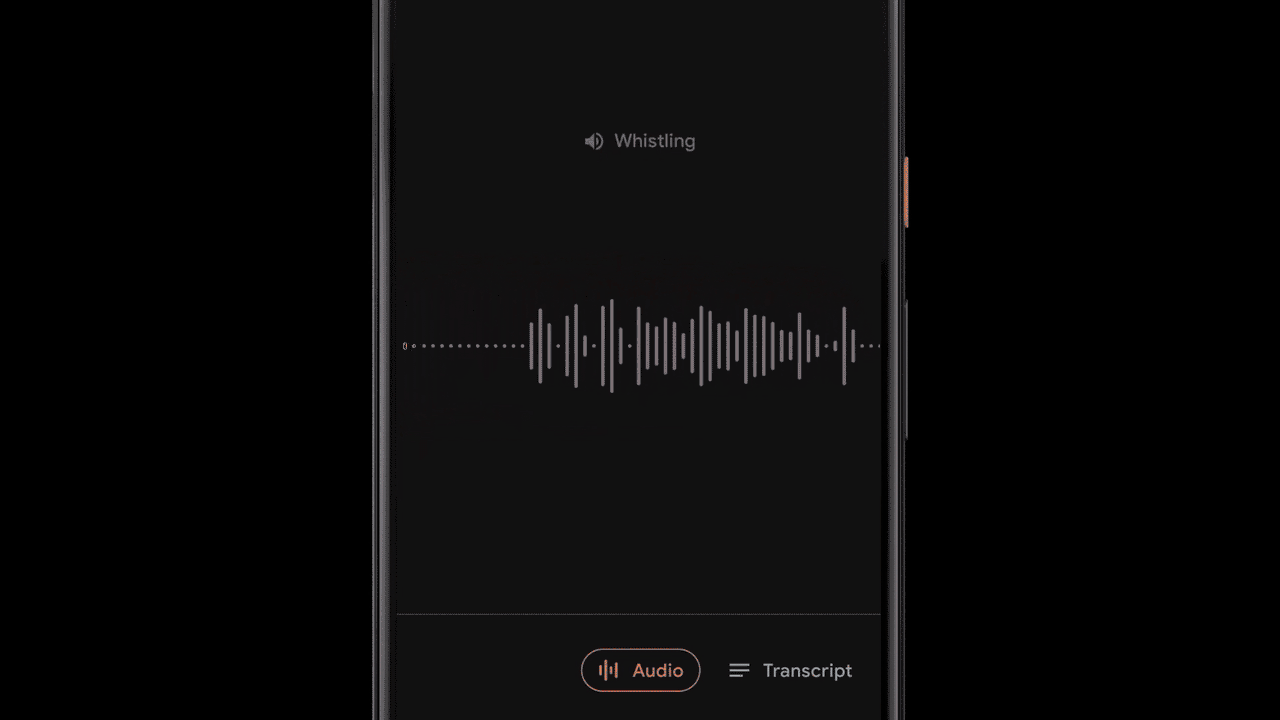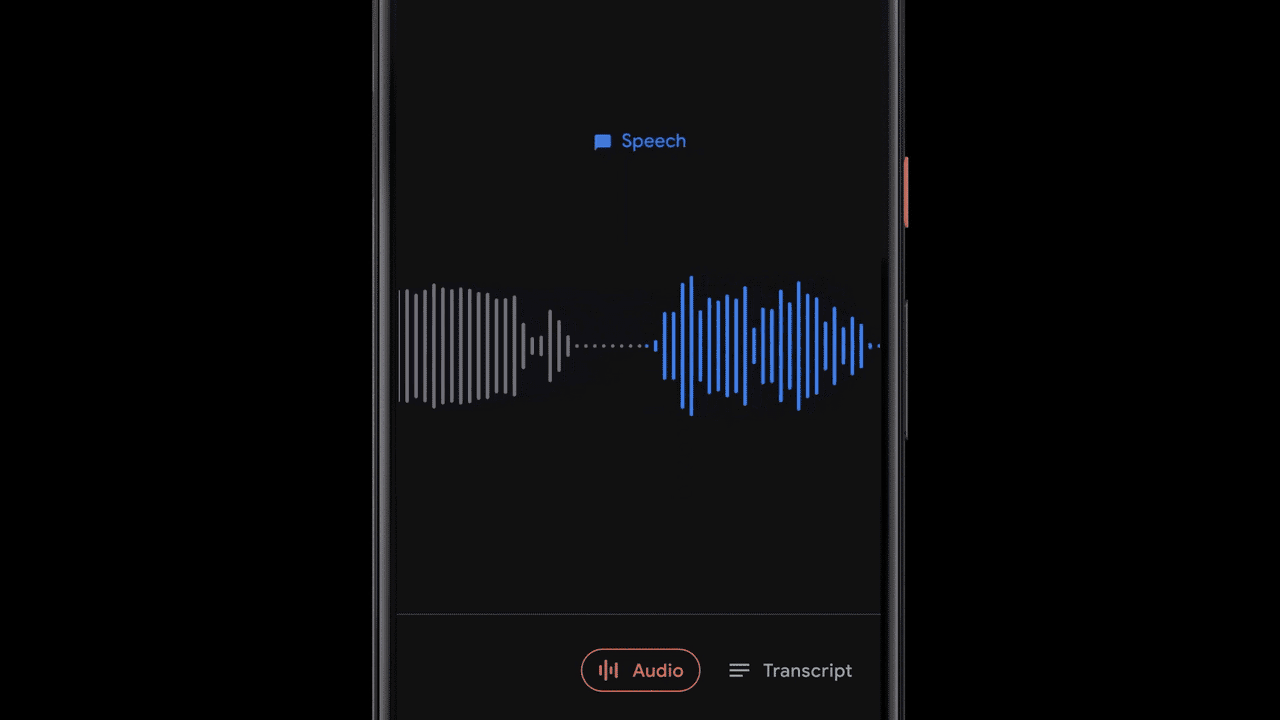
Recorder implements a sliding window capability that processes partially overlapping 960ms audio frames at 50ms intervals and outputs a sigmoid scores vector, representing the probability for each supported audio class within the frame. We apply a linearization process on the sigmoid scores in combination with a thresholding mechanism, in order to maximize the system precision and report the correct sound classification. This process of analyzing the content of the 960ms window with small 50ms offsets makes it possible to pinpoint exact start and end times in a manner that is less prone to mistakes than analyzing consecutive large 960ms window slices on their own.

Since the model analyzes each audio frame independently, it can be prone to quick jittering between audio classes. This is solved with an adaptive-size median filtering technique applied to the most recent model audio class outputs, thus providing a smoothed consecutive output. The process runs continuously in real-time, requiring it to meet very strict power consumption limitations.
Suggesting Tags for Titles
Once a recording is done, Recorder suggests three tags that the app deems to represent the most memorable content, enabling the user to quickly compose a meaningful title.
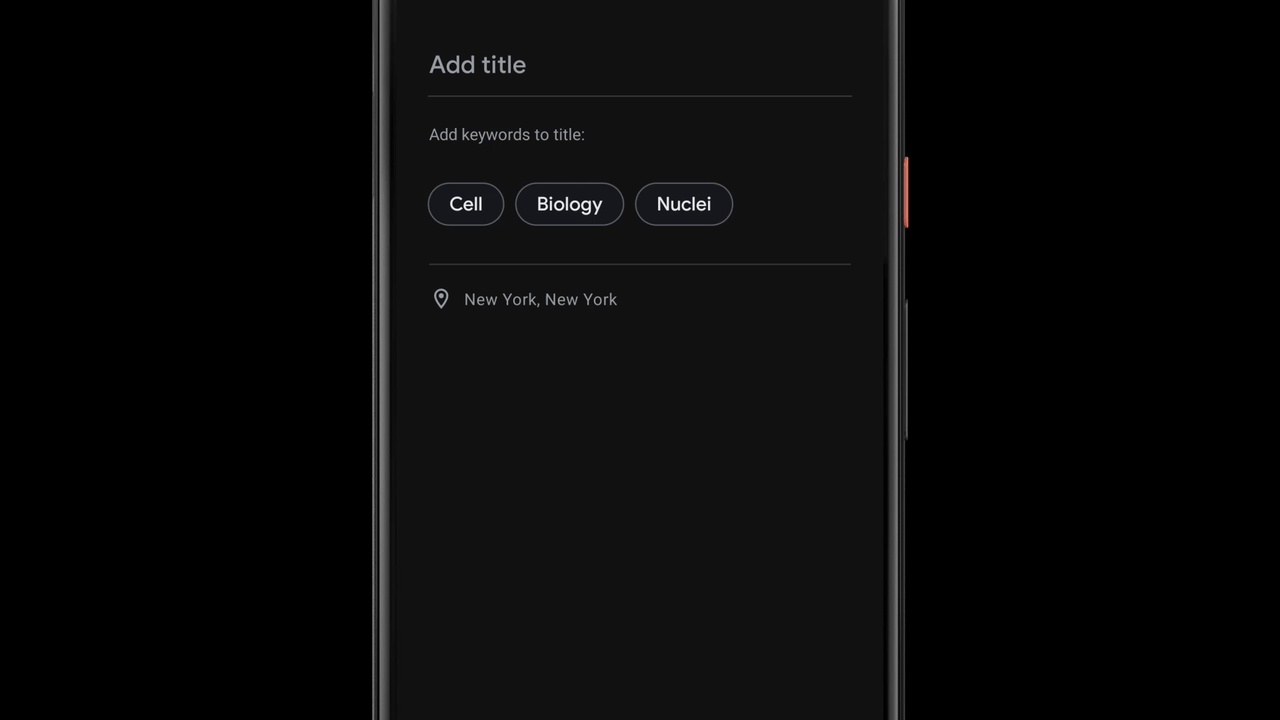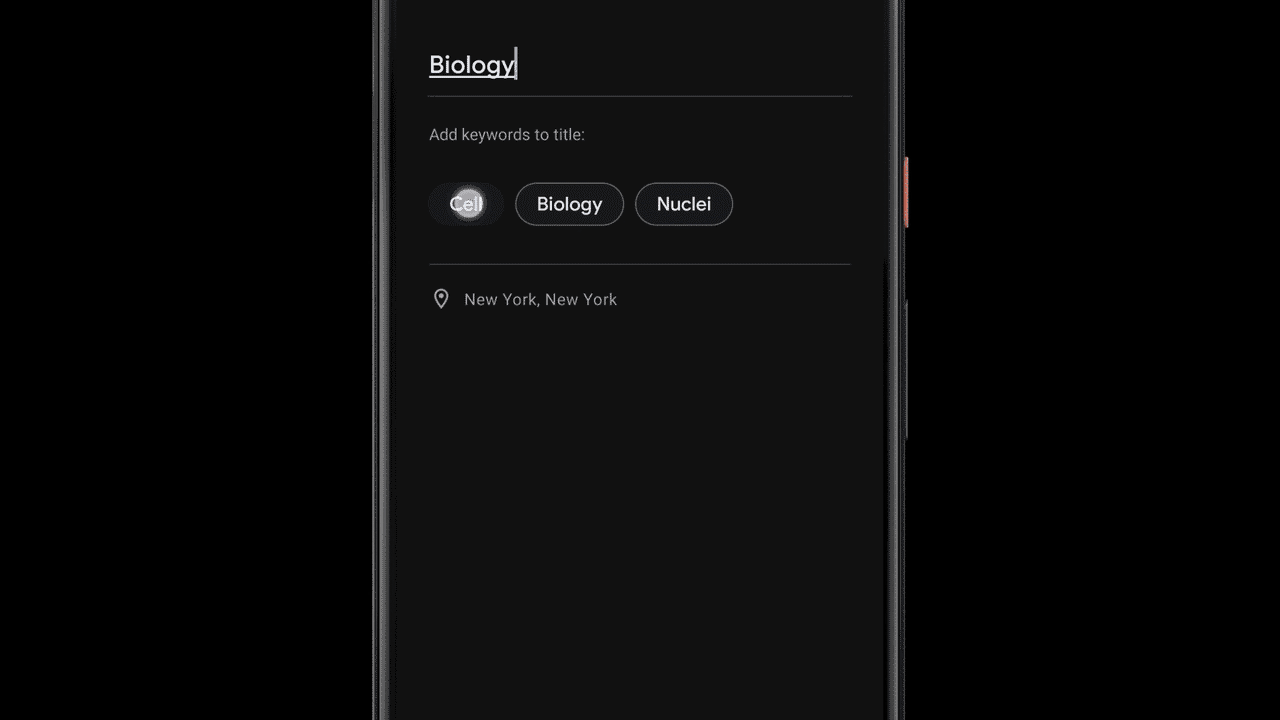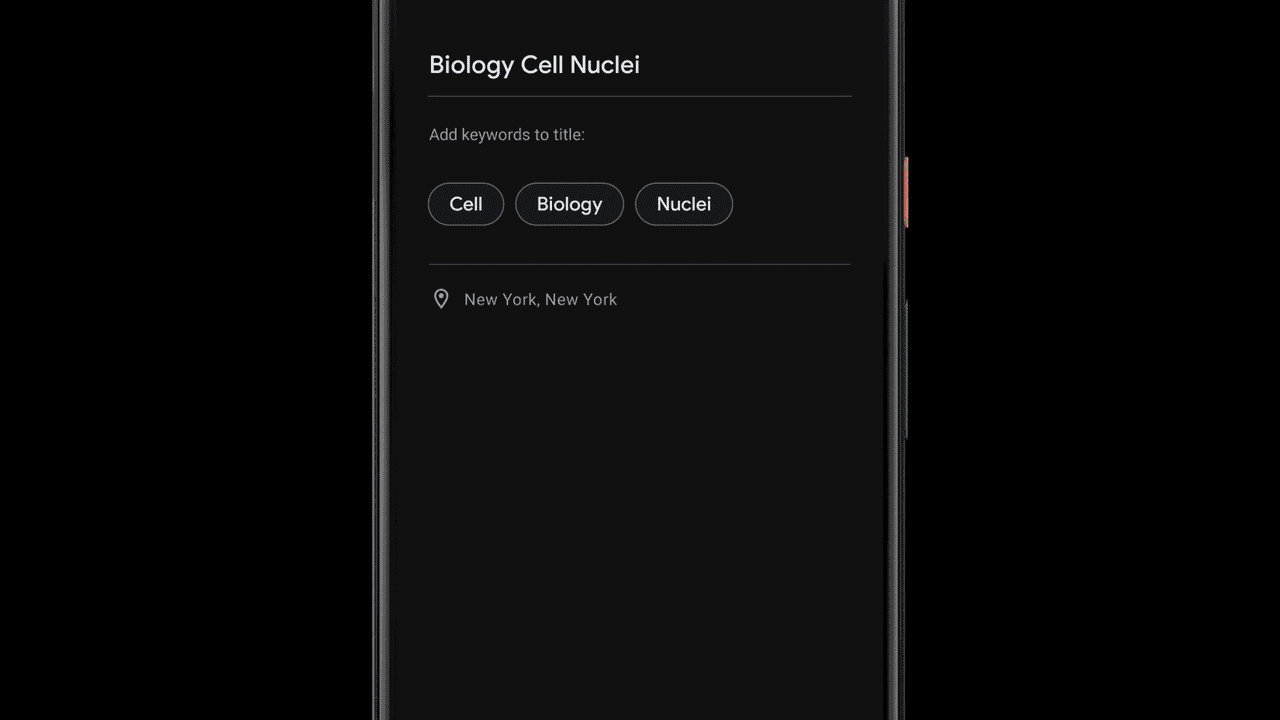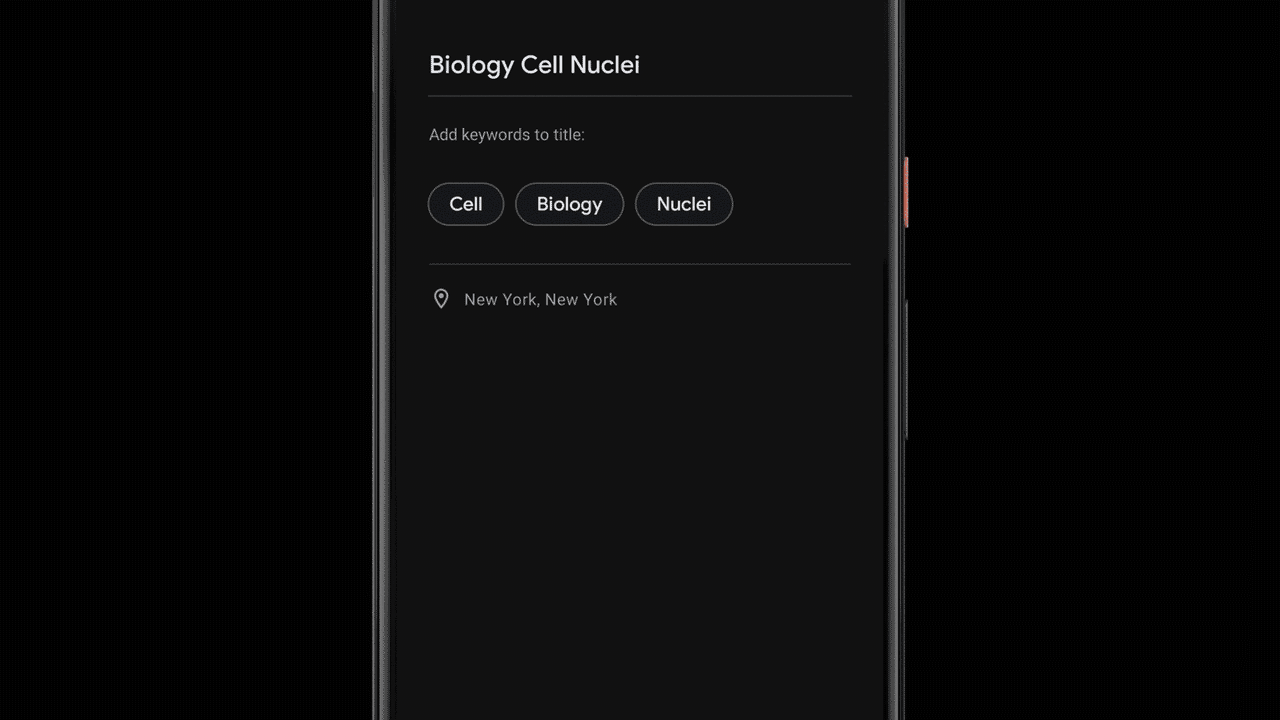
To be able to suggest these tags immediately when the recording ends, Recorder analyzes the content of the recording as it is being transcribed. First, Recorder counts term occurrences as well as their grammatical role in the sentence. The terms identified as entities are capitalized. Then, we utilize an on-device part-of-speech-tagger — a model that labels each word in the sentence according to its grammatical role — to detect common nouns and proper nouns, which appear to be more memorable by users. Recorder utilizes a prior scores table supporting both unigram and bigram terms extraction. To generate the scores, we trained a boosted decision tree with conversational data and utilized textual features like document words frequency and specificity. Last, filtering of stop words and swear words is applied and the top tags are outputted.
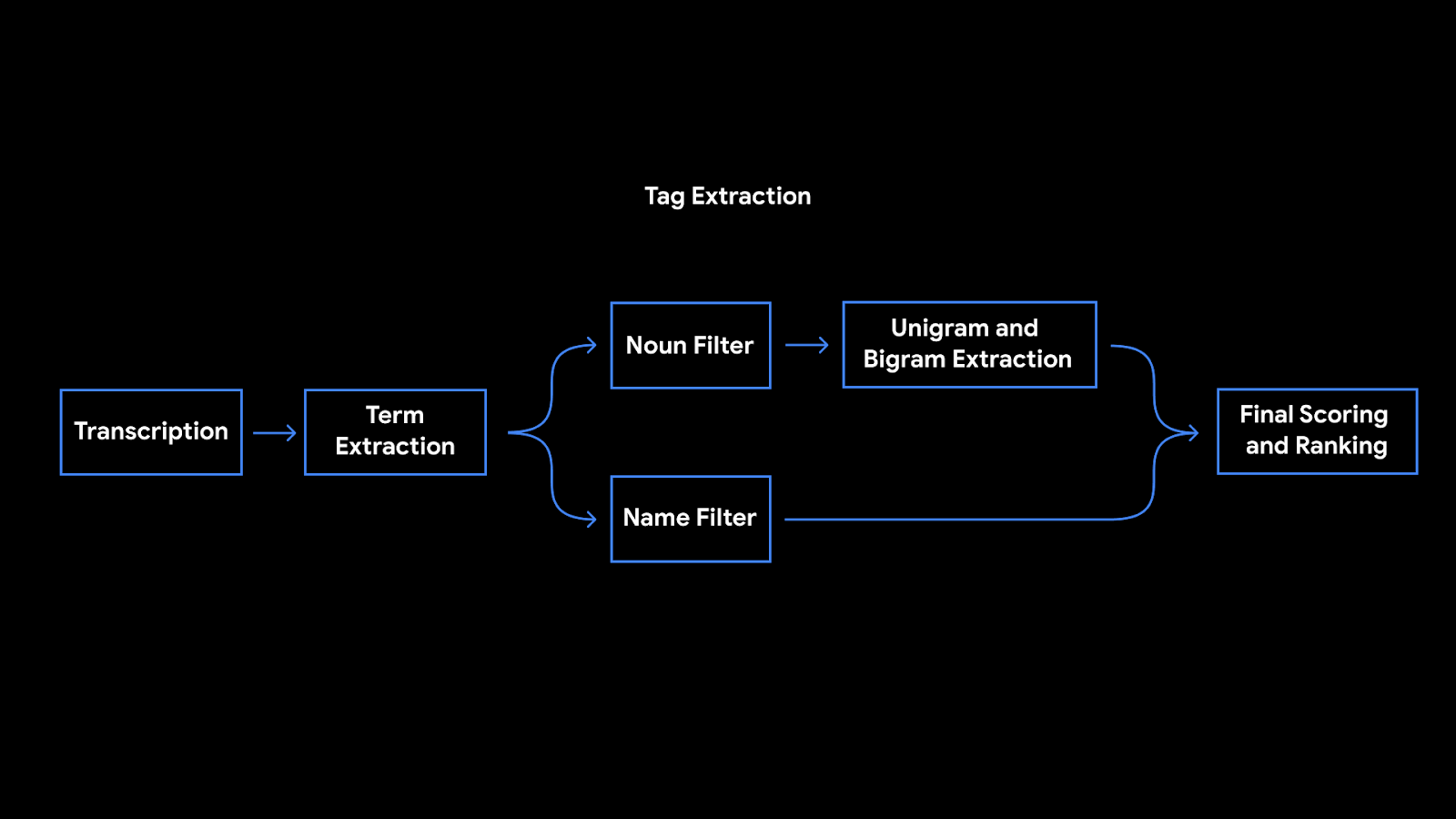 |
| Tags extraction pipeline architecture |
Conclusion
Recorder galvanized some of our most recent on-device ML research efforts into helpful features, running models on-device to ensure user privacy. The positive feedback loop between machine learning investigations and user needs revealed exciting opportunities to make our software even more useful. We’re excited for future research that will make everyone’s ideas and conversations even more easily accessible and searchable.
Acknowledgments
Special thanks to Dror Ayalon who played a key role in developing and forming the above features and without whom this blog post wouldn’t have been possible. We would also want to thank all our team members and collaborators who worked on this project with us: Amit Pitaru, Kelsie Van Deman, Isaac Blankensmith, Teo Soares, John Watkinson, Matt Hall, Josh Deitel, Benny Schlesinger, Yoni Tsafir, Michelle Tadmor Ramanovich, Danielle Cohen, Sushant Prakash, Renat Aksitov, Ed West, Max Gubin, Tiantian Zhang, Aaron Cohen, Yunhsuan Sung, Chung-Ching Chang, Nathan Dass, Amin Ahmad, Tiago Camolesi, Guilherme Santos, Julio da Silva, Dan Ellis, Qiao Liang, Arun Narayanan, Rohit Prabhavalkar, Benyah Shaparenko, Alex Salcianu, Mike Tsao, Shenaz Zak, Sherry Lin, James Lemieux, Jason Cho, Thomas Hall, Brian Chen, Allen Su, Vincent Peng, Richard Chou, Henry Liu, Edward Chen, Yitong Lin, Tracy Wu, Yvonne Yang.
