Improvements to Portrait Mode on the Google Pixel 4 and Pixel 4 XL
Portrait Mode on Pixel phones is a camera feature that allows anyone to take professional-looking shallow depth of field images. Launched on the Pixel 2 and then improved on the Pixel 3 by using machine learning to estimate depth from the camera’s dual-pixel auto-focus system, Portrait Mode draws the viewer’s attention to the subject by blurring out the background. A critical component of this process is knowing how far objects are from the camera, i.e., the depth, so that we know what to keep sharp and what to blur.
With the Pixel 4, we have made two more big improvements to this feature, leveraging both the Pixel 4’s dual cameras and dual-pixel auto-focus system to improve depth estimation, allowing users to take great-looking Portrait Mode shots at near and far distances. We have also improved our bokeh, making it more closely match that of a professional SLR camera.
 |
| Pixel 4’s Portrait Mode allows for Portrait Shots at both near and far distances and has SLR-like background blur. (Photos Credit: Alain Saal-Dalma and Mike Milne) |
A Short Recap
The Pixel 2 and 3 used the camera’s dual-pixel auto-focus system to estimate depth. Dual-pixels work by splitting every pixel in half, such that each half pixel sees a different half of the main lens’ aperture. By reading out each of these half-pixel images separately, you get two slightly different views of the scene. While these views come from a single camera with one lens, it is as if they originate from a virtual pair of cameras placed on either side of the main lens’ aperture. Alternating between these views, the subject stays in the same place while the background appears to move vertically.
 |
| The dual-pixel views of the bulb have much more parallax than the views of the man because the bulb is much closer to the camera. |
This motion is called parallax and its magnitude depends on depth. One can estimate parallax and thus depth by finding corresponding pixels between the views. Because parallax decreases with object distance, it is easier to estimate depth for near objects like the bulb. Parallax also depends on the length of the stereo baseline, that is the distance between the cameras (or the virtual cameras in the case of dual-pixels). The dual-pixels’ viewpoints have a baseline of less than 1mm, because they are contained inside a single camera’s lens, which is why it’s hard to estimate the depth of far scenes with them and why the two views of the man look almost identical.
Dual Cameras are Complementary to Dual-Pixels
The Pixel 4’s wide and telephoto cameras are 13 mm apart, much greater than the dual-pixel baseline, and so the larger parallax makes it easier to estimate the depth of far objects. In the images below, the parallax between the dual-pixel views is barely visible, while it is obvious between the dual-camera views.
 |
| Left: Dual-pixel views. Right: Dual-camera views. The dual-pixel views have only a subtle vertical parallax in the background, while the dual-camera views have much greater horizontal parallax. While this makes it easier to estimate depth in the background, some pixels to the man’s right are visible in only the primary camera’s view making it difficult to estimate depth there. |
Even with dual cameras, information gathered by the dual pixels is still useful. The larger the baseline, the more pixels that are visible in one view without a corresponding pixel in the other. For example, the background pixels immediately to the man’s right in the primary camera’s image have no corresponding pixel in the secondary camera’s image. Thus, it is not possible to measure the parallax to estimate the depth for these pixels when using only dual cameras. However, these pixels can still be seen by the dual pixel views, enabling a better estimate of depth in these regions.
Another reason to use both inputs is the aperture problem, described in our previous blog post, which makes it hard to estimate the depth of vertical lines when the stereo baseline is also vertical (or when both are horizontal). On the Pixel 4, the dual-pixel and dual-camera baselines are perpendicular, allowing us to estimate depth for lines of any orientation.
Having this complementary information allows us to estimate the depth of far objects and reduce depth errors for all scenes.
Depth from Dual Cameras and Dual-Pixels
We showed last year how machine learning can be used to estimate depth from dual-pixels. With Portrait Mode on the Pixel 4, we extended this approach to estimate depth from both dual-pixels and dual cameras, using Tensorflow to train a convolutional neural network. The network first separately processes the dual-pixel and dual-camera inputs using two different encoders, a type of neural network that encodes the input into an intermediate representation. Then, a single decoder uses both intermediate representations to compute depth.
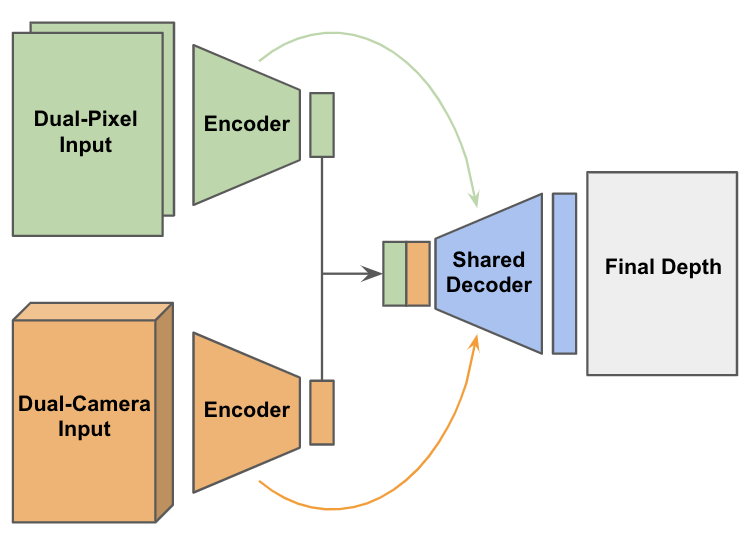 |
| Our network to predict depth from dual-pixels and dual-cameras. The network uses two encoders, one for each input and a shared decoder with skip connections and residual blocks. |
To force the model to use both inputs, we applied a drop-out technique, where one input is randomly set to zero during training. This teaches the model to work well if one input is unavailable, which could happen if, for example, the subject is too close for the secondary telephoto camera to focus on.
 |
| Depth maps from our network where either only one input is provided or both are provided. Top: The two inputs provide depth information for lines in different directions. Bottom: Dual-pixels provide better depth in the regions visible in only one camera, emphasized in the insets. Dual-cameras provide better depth in the background and ground. (Photo Credit: Mike Milne) |
The lantern image above shows how having both signals solves the aperture problem. Having one input only allows us to predict depth accurately for lines in one direction (horizontal for dual-pixels and vertical for dual-cameras). With both signals, we can recover the depth on lines in all directions.
With the image of the person, dual-pixels provide better depth information in the occluded regions between the arm and torso, while the large baseline dual cameras provide better depth information in the background and on the ground. This is most noticeable in the upper-left and lower-right corner of depth from dual-pixels. You can find more examples here.
SLR-Like Bokeh
Photographers obsess over the look of the blurred background or bokeh of shallow depth of field images. One of the most noticeable things about high-quality SLR bokeh is that small background highlights turn into bright disks when defocused. Defocusing spreads the light from these highlights into a disk. However, the original highlight is so bright that even when its light is spread into a disk, the disk remains at the bright end of the SLR’s tonal range.
 |
| Left: SLRs produce high contrast bokeh disks. Middle: It is hard to make out the disks in our old background blur. Right: Our new bokeh is closer to that of an SLR. |
To reproduce this bokeh effect, we replaced each pixel in the original image with a translucent disk whose size is based on depth. In the past, this blurring process was performed after tone mapping, the process by which raw sensor data is converted to an image viewable on a phone screen. Tone mapping compresses the dynamic range of the data, making shadows brighter relative to highlights. Unfortunately, this also results in a loss of information about how bright objects actually were in the scene, making it difficult to produce nice high-contrast bokeh disks. Instead, the bokeh blends in with the background, and does not appear as natural as that from an SLR.
The solution to this problem is to blur the merged raw image produced by HDR+ and then apply tone mapping. In addition to the brighter and more obvious bokeh disks, the background is saturated in the same way as the foreground. Here’s an album showcasing the better blur, which is available on the Pixel 4 and the rear camera of the Pixel 3 and 3a (assuming you have upgraded to version 7.2 of the Google Camera app).
 |
| Blurring before tone mapping improves the look of the backgrounds by making it more saturated and by making disks higher contrast. |
Try it Yourself
We have made Portrait Mode on the Pixel 4 better by improving depth quality, resulting in fewer errors in the final image and by improving the look of the blurred background. Depth from dual-cameras and dual-pixels only kicks in when the camera is at least 20 cm from the subject, i.e. the minimum focus distance of the secondary telephoto camera. So consider keeping your phone at least that far from the subject to get better quality portrait shots.
Acknowledgments
This work wouldn’t have been possible without Rahul Garg, Sergio Orts Escolano, Sean Fanello, Christian Haene, Shahram Izadi, David Jacobs, Alexander Schiffhauer, Yael Pritch Knaan and Marc Levoy. We would also like to thank the Google Camera team for helping to integrate these algorithms into the Pixel 4. Special thanks to our photographers Mike Milne, Andy Radin, Alain Saal-Dalma, and Alvin Li who took numerous test photographs for us.
