When Topic Modeling is Part of the Text Pre-processing

How to effectively and creatively pre-process text data
A few months ago, we built a content based recommender system using a relative clean text data set. Because I collected the hotel descriptions my self, I made sure that the descriptions were useful for the goals we were going to accomplish. However, the real-world text data is never clean and there are different pre-processing ways and steps for different goals.
Topic modeling in NLP is rarely my final goal in an analysis, I use it often to either explore data or as a tool to make my final model more accurate. Let me show you what I meant.
The Data
We are still using the Seattle Hotel description data set I collected earlier, and I made it a bit more messier this time. We are going to skip all the EDA processes and I want to make recommendations as quickly as possible.
If you have read my previous post, I am sure you understand the following code script. Yes, we are looking for top 5 most similar hotels with “Hilton Garden Inn Seattle Downtown” (except itself), according to hotel description texts.
Make Recommendations
https://medium.com/media/aafe45c62a3f78bdd069868868db2b66/href

Our model returns the above 5 hotels and thinks they are top 5 most similar hotels to “Hilton Garden Inn Seattle Downtown”. I am sure you don’t agree, neither do I. Let’s say why the model thinks they are similar by looking at these descriptions.
df.loc['Hilton Garden Inn Seattle Downtown'].desc

df.loc["Mildred's Bed and Breakfast"].desc

df.loc["Seattle Airport Marriott"].desc

Found anything interesting? Yes, there are indeed somethings in common in these three hotel descriptions, they all have the same check in and check out time, and they all have the similar smoking policies. But are they important? Can we declare two hotels are similar just because they are all “non-smoking”? Of course not, these are not important characteristics and we shouldn’t measure similarity in vector space of these texts.
We need to find a way to safely remove these texts programmatically, while not removing any other useful characteristics.
Topic modeling comes to our rescue. But before that, we need to wrangle the data to make it in the right shape.
- Split each description into sentences. Hilton Garden Seattle Downtown’s entire description will be split into 7 sentences.
https://medium.com/media/57f6877b6638b27c9e142fa3a5bb7c63/href

Topic Modeling
- We are going to build topic model for all the sentences together. I decided to have 40 topics after several experiments.
https://medium.com/media/0478e76d0041ce7510ce5092c27e42b9/href
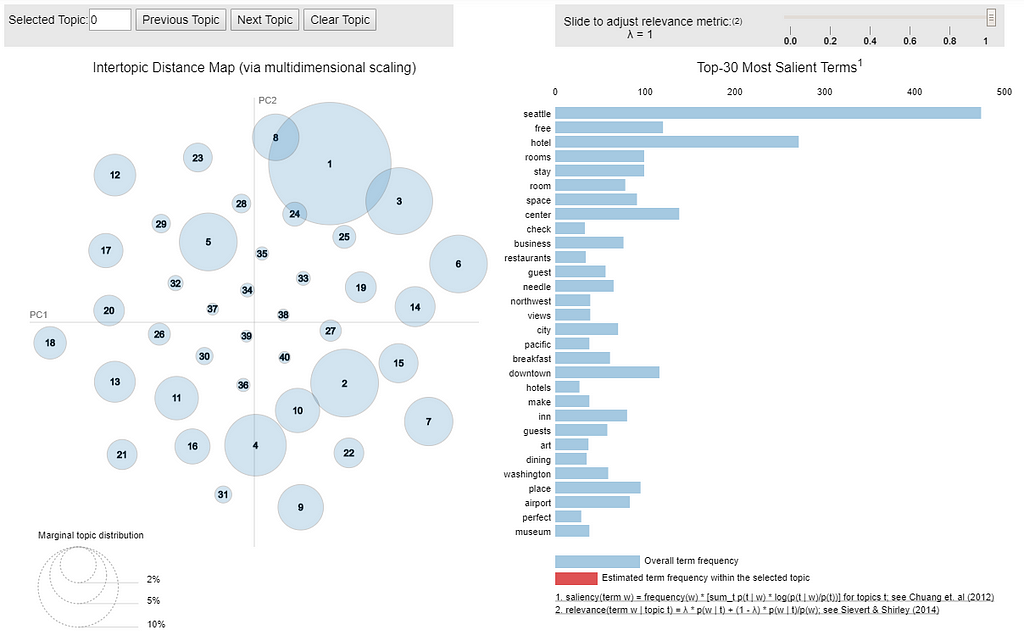
Not too bad, there were not too much overlapping.
- To understand better, you may want to investigate top 20 words in each topic.
https://medium.com/media/3667d3da9af7aee9b9e721ffd1ae853b/href
We shall have 40 topics, and each topic shows 20 keywords. Its very hard to print out the entire table, I will only show a small part of it.
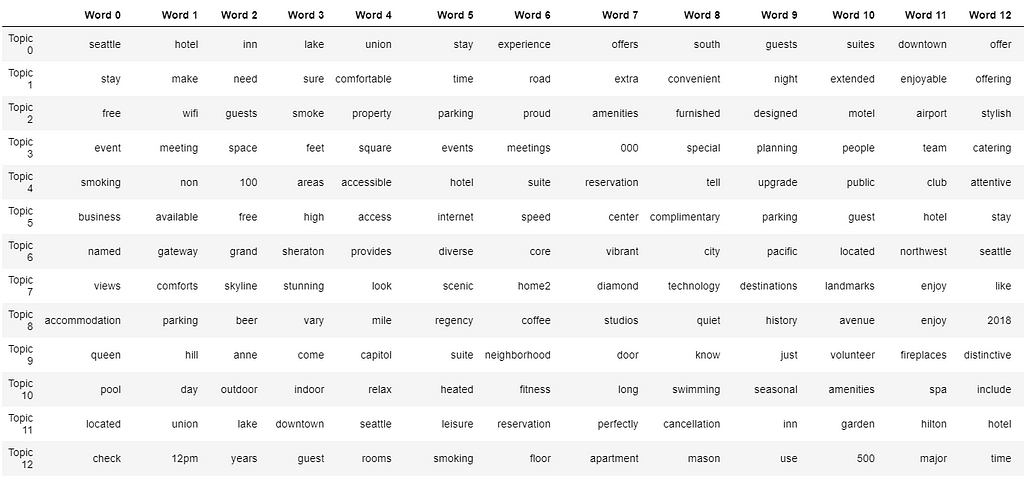
By staring at the table, we can guess that at least topic 12 should be one of the topics we would like to dismiss, because it contains several words that meaningless for our purpose.
In the following code scripts, we:
- Create document-topic matrix.
- Create a data frame where each document is a row, and each column is a topic.
- The weight of each topic is assigned to each document.
- The last column is the dominant topic for that document, in which it carries the most weight.
- When we merge this data frame to the previous sentence data frame. We are able to find the the weight of each topic in every sentence, and the dominant topic for each sentence.
https://medium.com/media/4d76caf58479fd78fe5beaae6256fabd/href
- Now we can visually examine dominant topics assignment of each sentence for “Hilton Garden Inn Seattle Downtown”.
df_sent_topic.loc[df_sent_topic['name'] == 'Hilton Garden Inn Seattle Downtown'][['sentence', 'dominant_topic']]
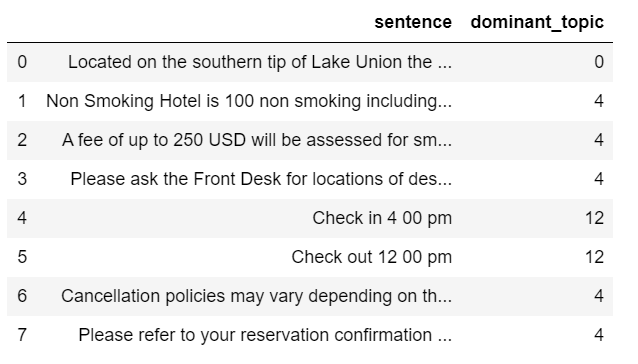
- By staring at the above table, my assumption is that if a sentence’s dominant topic is topic 4 or topic 12, that sentence is likely to be useless.
- Let’s see a few more example sentences that have topic 4 or topic 12 as their dominant topic.
df_sent_topic.loc[df_sent_topic['dominant_topic'] == 4][['sentence', 'dominant_topic']].sample(20)
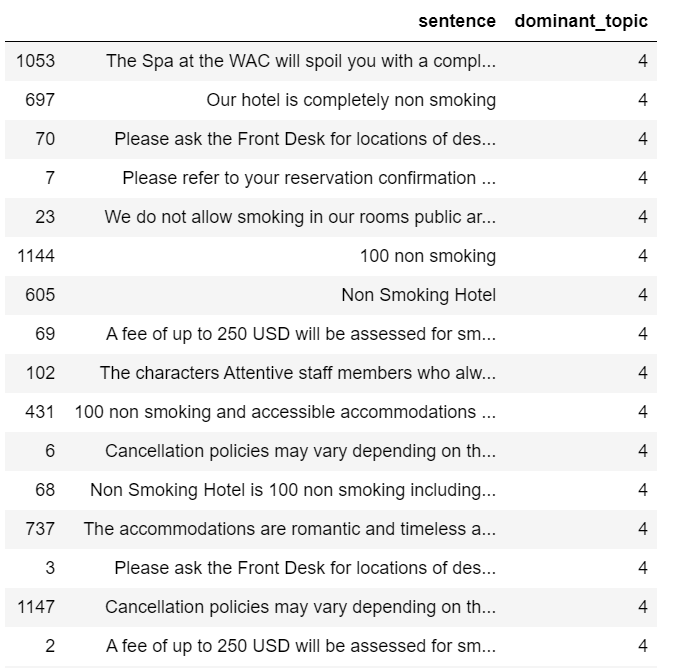
df_sent_topic.loc[df_sent_topic['dominant_topic'] == 12][['sentence', 'dominant_topic']].sample(10)
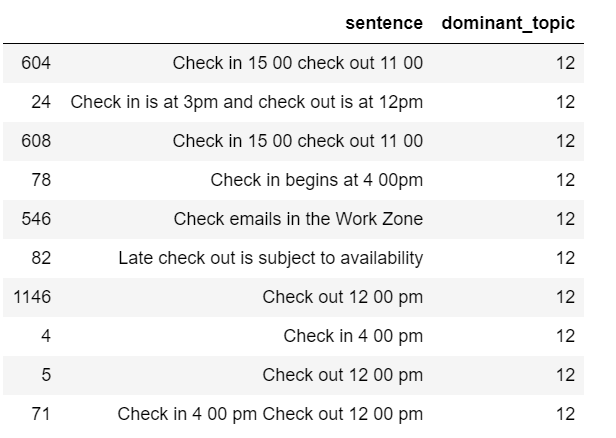
- After reviewing the above two tables, I decided to remove all the sentences that have topic 4 or topic 12 as their dominant topic.
print('There are', len(df_sent_topic.loc[df_sent_topic['dominant_topic'] == 4]), 'sentences that belong to topic 4 and we will remove')
print('There are', len(df_sent_topic.loc[df_sent_topic['dominant_topic'] == 12]), 'sentences that belong to topic 12 and we will remove')

df_sent_topic_clean = df_sent_topic.drop(df_sent_topic[(df_sent_topic.dominant_topic == 4) | (df_sent_topic.dominant_topic == 12)].index)
- Next, we will join the clean sentence together in to a descriptions. That is, making it back to one description per hotel.
df_description = df_sent_topic_clean[['sentence','name']]
df_description = df_description.groupby('name')['sentence'].agg(lambda col: ' '.join(col)).reset_index()
- Let’s see what left for our “Hilton Garden Inn Seattle Downtown”
df_description['sentence'][45]

There is only one sentence left and it is about the location of the hotel and this is what I had expected.
Make Recommendations
Using the same cosine similarity measurement, we are going to find the top 5 most similar hotels with “Hilton Garden Inn Seattle Downtown” (except itself), according to the cleaned hotel description texts.
https://medium.com/media/2338ec051f9d736f4062aa769eace360/href

Nice! Our method worked!
Jupyter notebook can be found on Github. Have a great weekend!