Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Google’s mission is not just to organize the world’s information but to make it universally accessible, which means ensuring that our products work in as many of the world’s languages as possible. When it comes to understanding human speech, which is a core capability of the Google Assistant, extending to more languages poses a challenge: high-quality automatic speech recognition (ASR) systems require large amounts of audio and text data — even more so as data-hungry neural models continue to revolutionize the field. Yet many languages have little data available.
We wondered how we could keep the quality of speech recognition high for speakers of data-scarce languages. A key insight from the research community was that much of the “knowledge” a neural network learns from audio data of a data-rich language is re-usable by data-scarce languages; we don’t need to learn everything from scratch. This led us to study multilingual speech recognition, in which a single model learns to transcribe multiple languages.
In “Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model”, published at Interspeech 2019, we present an end-to-end (E2E) system trained as a single model, which allows for real-time multilingual speech recognition. Using nine Indian languages, we demonstrated a dramatic improvement in the ASR quality on several data-scarce languages, while still improving performance for the data-rich languages.
India: A Land of Languages
For this study, we focused on India, an inherently multilingual society where there are more than thirty languages with at least a million native speakers. Many of these languages overlap in acoustic and lexical content due to the geographic proximity of the native speakers and shared cultural history. Additionally, many Indians are bilingual or trilingual, making the use of multiple languages within a conversation a common phenomenon, and a natural case for training a single multilingual model. In this work, we combined nine primary Indian languages, namely Hindi, Marathi, Urdu, Bengali, Tamil, Telugu, Kannada, Malayalam and Gujarati.
A Low-latency All-neural Multilingual Model
Traditional ASR systems contain separate components for acoustic, pronunciation, and language models. While there have been attempts to make some or all of the traditional ASR components multilingual [1,2,3,4], this approach can be complex and difficult to scale. E2E ASR models combine all three components into a single neural network and promise scalability and ease of parameter sharing. Recent works have extended E2E models to be multilingual [1,2], but they did not address the need for real-time speech recognition, a key requirement for applications such as the Assistant, Voice Search and GBoard dictation. For this, we turned to recent research at Google that used a Recurrent Neural Network Transducer (RNN-T) model to achieve streaming E2E ASR. The RNN-T system outputs words one character at a time, just as if someone was typing in real time, however this was not multilingual. We built upon this architecture to develop a low-latency model for multilingual speech recognition.
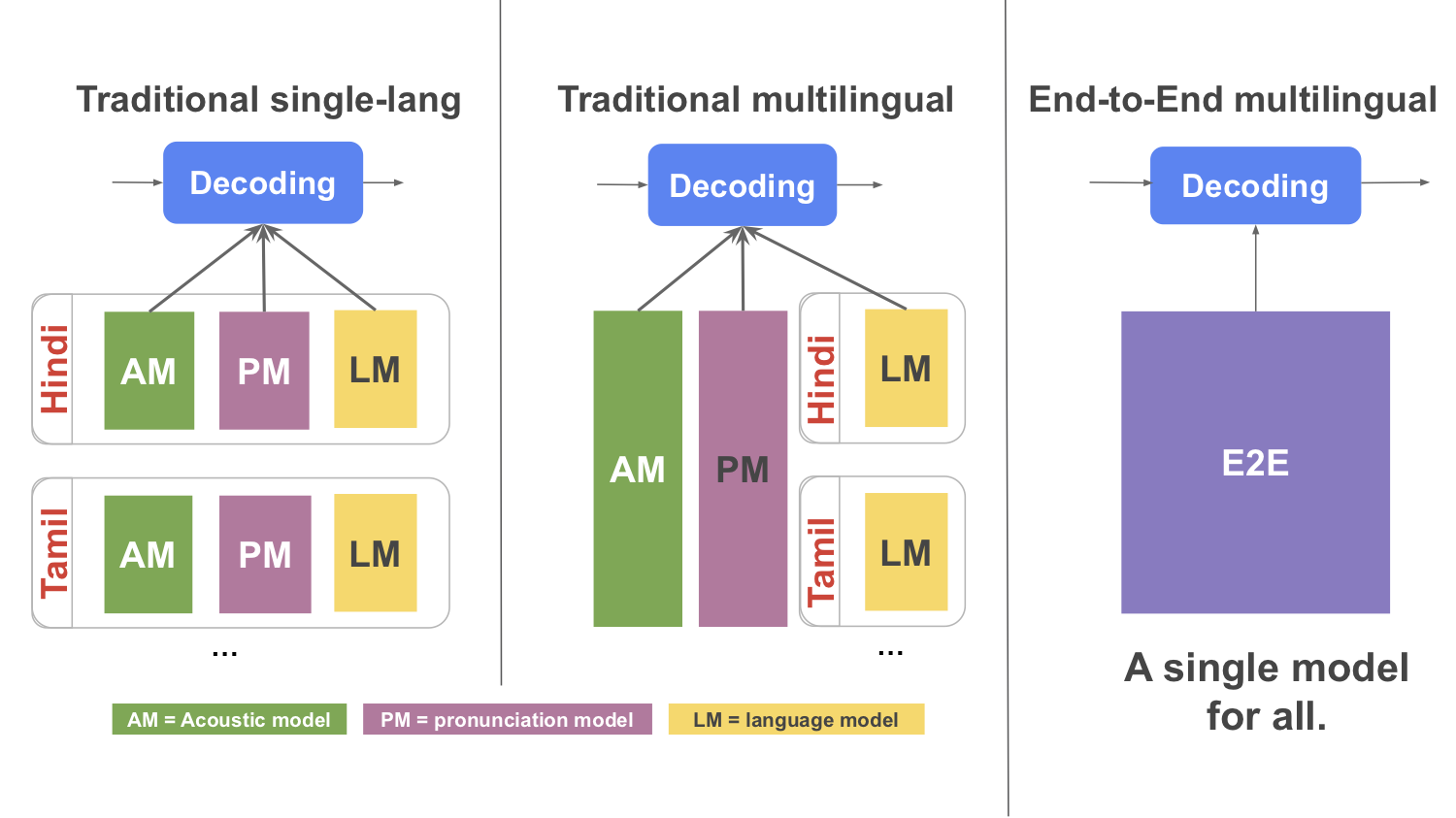 |
| [Left] A traditional monolingual speech recognizer comprising of Acoustic, Pronunciation and Language Models for each language. [Middle] A traditional multilingual speech recognizer where the Acoustic and Pronunciation model is multilingual, while the Language model is language-specific. [Right] An E2E multilingual speech recognizer where the Acoustic, Pronunciation and Language Model is combined into a single multilingual model. |
Large-Scale Data Challenges
Using large-scale, real-world data for training a multilingual model is complicated by data imbalance. Given the steep skew in the distribution of speakers across the languages and speech product maturity, it is not surprising to have varying amounts of transcribed data available per language. As a result, a multilingual model can tend to be more influenced by languages that are over-represented in the training set. This bias is more prominent in an E2E model, which unlike a traditional ASR system, does not have access to additional in-language text data and learns lexical characteristics of the languages solely from the audio training data.
 |
| Histogram of training data for the nine languages showing the steep skew in the data available. |
We addressed this issue with a few architectural modifications. First, we provided an extra language identifier input, which is an external signal derived from the language locale of the training data; i.e. the language preference set in an individual’s phone. This signal is combined with the audio input as a one-hot feature vector. We hypothesize that the model is able to use the language vector not only to disambiguate the language but also to learn separate features for separate languages, as needed, which helped with data imbalance.
Building on the idea of language-specific representations within the global model, we further augmented the network architecture by allocating extra parameters per language in the form of residual adapter modules. Adapters helped fine-tune a global model on each language while maintaining parameter efficiency of a single global model, and in turn, improved performance.
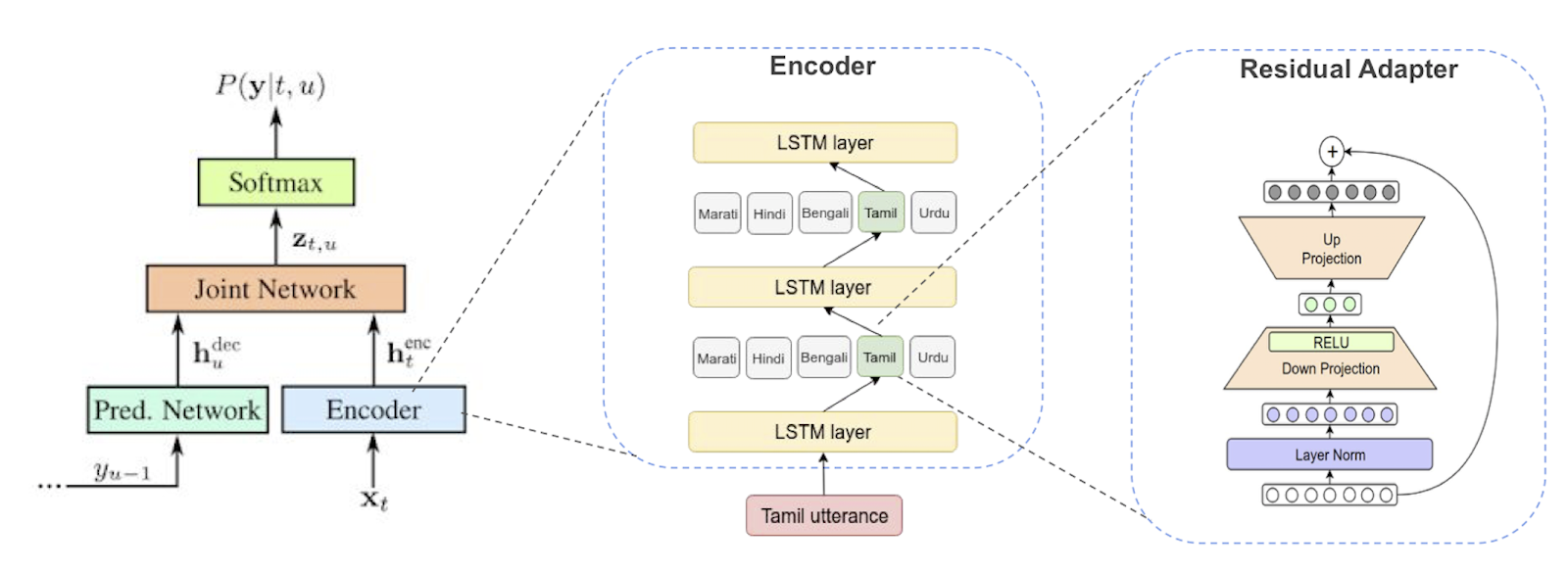 |
| [Left] Multilingual RNN-T architecture with a language identifier. [Middle] Residual adapters inside the encoder. For a Tamil utterance, only the Tamil adapters are applied to each activation. [Right] Architecture details of the Residual Adapter modules. For more details please see our paper. |
Putting all of these elements together, our multilingual model outperforms all the single-language recognizers, with especially large improvements in data-scarce languages like Kannada and Urdu. Moreover, since it is a streaming E2E model, it simplifies training and serving, and is also usable in low-latency applications like the Assistant. Building on this result, we hope to continue our research on multilingual ASRs for other language groups, to better assist our growing body of diverse users.
Acknowledgements
We would like to thank the following for their contribution to this research: Tara N. Sainath, Eugene Weinstein, Bo Li, Shubham Toshniwal, Ron Weiss, Bhuvana Ramabhadran, Yonghui Wu, Ankur Bapna, Zhifeng Chen, Seungji Lee, Meysam Bastani, Mikaela Grace, Pedro Moreno, Yanzhang (Ryan) He, Khe Chai Sim.
