Power contextual bandits using continual learning with Amazon SageMaker RL
Amazon SageMaker is a modular, fully-managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning models at any scale. Training models is quick and easy using a set of built-in high-performance algorithms, pre-built deep learning frameworks, or using your own framework. To help select your machine learning (ML) algorithm, Amazon SageMaker comes with the most common ML algorithms that are pre-installed and performance-optimized.
In addition to building machine learning models using supervised and unsupervised learning techniques, you can also build reinforcement learning models in Amazon SageMaker using Amazon SageMaker RL. Amazon SageMaker RL includes pre-built RL libraries and algorithms that make it easy to get started with reinforcement learning. There are several examples in GitHub that show you how you can use Amazon SageMaker RL for training robots and autonomous vehicles, portfolio management, energy optimization, and automatic capacity scaling.
In this blog post, we are excited to show you how you can use Amazon SageMaker RL to implement contextual multi-armed bandits (or contextual bandits for short) to personalize content for users. The contextual bandits algorithm recommends various content options to the users (such as gamers or hiking enthusiasts) by learning from user responses to the recommendations such as clicking a recommendation or not. These algorithms require that the machine learning models be continually updated to adapt to changes in data, and we show you how to build an iterative training and deployment loop in Amazon SageMaker.
Contextual bandits
Many applications like personalized web services (content layout, ads, search, product recommendations, etc.) are continuously faced with decisions to make, often based on some contextual information. These applications need to personalize content for individuals by making use of both user and content information. For example, user information related to her being a gaming enthusiast and content information related to it being a racing game. Machine learning systems that enable these applications face two challenges. The data to learn user preferences is sparse and biased (many users have little or no history and many products have never been recommended in the past). Also, new users and content are always being added to the system. Traditional Collaborative Filtering (CF) based approaches, used for personalization, build a static recommendation model for the sparse/biased dataset and for the current set of users and content. Contextual bandits, on the other hand, collect and augment data in a strategic manner by trading off between exploiting known information (recommending games to the gaming enthusiast) and exploring recommendations (recommending hiking gear to the gaming enthusiast) which may yield higher benefits. Bandits models also use user and content features and hence they can make recommendations for new content/users based on preferences of similar content and users.
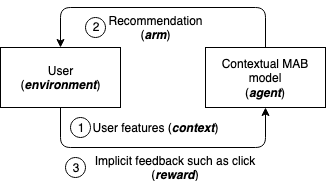
Before we go any further, let us introduce some terminology. Contextual bandits algorithm is characterized by an iterative process. There are a number of choices (known as arms or actions), from which an agent can choose, which contain stochastic rewards. At the beginning of each round, the environment generates a state of fixed dimensionality (also called context), and rewards for each action, which are related to the state. The agent chooses an arm with a certain probability for that round, and the environment reveals the reward for that arm, but not for the others. The goal of the agent is to explore and exploit actions so that it learns a good model while minimizing use of actions that yield low rewards.
Amazon SageMaker RL contextual bandits solution
To implement the explore-exploit strategy in Amazon SageMaker RL, we developed an iterative training and deployment system that: (1) Presents the recommendations from the currently hosted contextual bandit model to the user, based on her features (context), (2) Captures the implicit feedback over time, and (3) Continuously re-trains the model with incremental interaction data.
In particular, the Amazon SageMaker RL bandits solution has the following features. Accompanying this blog, we are also releasing an Amazon SageMaker example Notebook demonstrating these features.
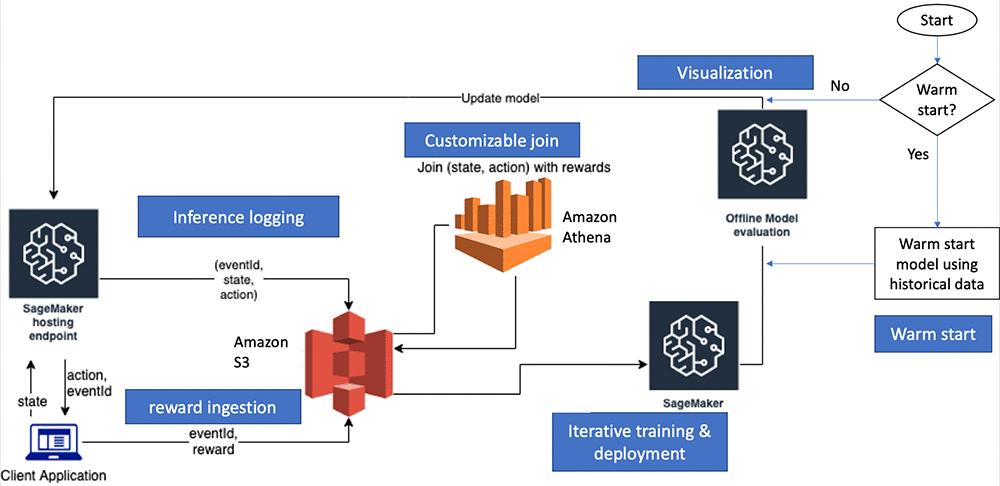
Amazon SageMaker RL Bandits Container: The Amazon SageMaker RL bandits container provides a library of contextual bandits algorithms from the Vowpal Wabbit (VW) project. In addition, it also provides support for hosting the trained bandit models for predictions.
Warm start: If there is historical data capturing user and content interactions, it can be used to create the initial model. In particular, data of the form <state, action, probability, reward> is needed. Presence of such data can help improve the model convergence times (number of training and deployment cycles). In the absence of such data, we can also initialize the model randomly. In the following code from our Amazon SageMaker example Notebook, we show how to warm start the bandits model with historical data.
(Simulated) Client Application and Reward Ingestion: Any real world application (for example, a retail website serving recommendations to users) is referred to as the Client Application in the figure above, will ping the Amazon SageMaker hosted endpoint with user features (state) and will receive recommendations (action) with an associated probability (probability) in return. In addition, the client application will also receive a system-generated event_id. Data generated as a result of user interactions with the recommendations is used in the subsequent iteration of training. In particular, the user behavior of interest (such as clicks and purchases) is captured as the feedback or reward. The feedback may not be instantaneous (purchase after a few hours of the recommendation) and the client application is expected to (1) associate the reward with the event_id and (2) upload the aggregated rewards data (<reward, event_id>) back on to S3. We include code in the example notebook to demonstrate how such a client application can be implemented. The simulated application has a predictor object that has the logic to make HTTP requests to the Amazon SageMaker endpoint. The event_id is used to join inference data (<state, action, probability, event_id>) with the rewards data (<reward, event_id>).
Inference logging: To use data generated from user interactions with the deployed contextual bandit models, we need to be able to capture data at the inference time (<state, action, probability, event_id>). Inference data logging happens automatically from the deployed Amazon SageMaker endpoint serving the bandits model. The data is captured and uploaded to an S3 bucket in the user account. Please refer to the notebook for details on the S3 locations where this data is stored.
Customizable joins: At every iteration, the training data is obtained by joining the inference data with the rewards data. By default, all of the specified rewards data and inference data are used for the join. The Amazon SageMaker RL bandits solution also lets customers specify a time window on which the inference data and rewards data can be joined (number of hours before the join).
Iterative training and deployment (Continual Learning setup): The example notebook and accompanying code help demonstrate how to use Amazon SageMaker and other AWS services to create the iterative training and deployment loop to build and train bandit models. This is demonstrated in two parts. First, the notebook demonstrates each step individually (model initialization, deploying the first model, initializing the client application, reward ingestion, model re-training and re-deployment). These individual steps help during the development phase. Subsequently, an end-to-end loop demonstrates how bandits models can be deployed post development. The ExperimentManager class can be used for all the Bandits/RL and continual learning workflows. Similar to the estimators in the Amazon SageMaker Python SDK, ExperimentManager contains methods for training, deployment, and evaluation. It keeps track of the job status and reflects current progress in the workflow. It sets up an AWS CloudFormation stack of AWS resources like Amazon DynamoDB, Amazon Kinesis Data Firehose and Amazon Athena, that are required to support the continual learning loop, in addition to Amazon SageMaker.
Offline model evaluation and visualization: At every training and deployment iteration, we demonstrate how offline model evaluation can be used to aid the decision to update the deployed model. After every training cycle, we need to evaluate if the newly trained model is better than the one currently deployed. Using an evaluation dataset, we evaluate how the new model would have done had it been deployed compared to the model that is currently deployed. Amazon SageMaker RL supports offline evaluation by performing this counterfactual analysis (CFA). By default, we apply a doubly robust (DR) estimation method [1]. These evaluation scores are also sent to Amazon CloudWatch so that for long running cycles, users can visualize the progress over time.
Amazon SageMaker example notebook
To demonstrate the bandits application, we used the Statlog(Shuttle) dataset from the UCI Machine Learning repository [2]. It contains nine integer attributes (or features) related to indicators during a space shuttle flight, and the goal is to predict one of seven states of the radiator subsystem of the shuttle. For demonstrating the bandits solution, this multi-class classification problem is converted into a bandits problem. In the classification problem, the algorithm receives features and correct label per datapoint. In the bandit problem, the algorithm picks one of the label options given the features. If this matches the class in the original data point, a reward of one is assigned. If not, a reward of zero is assigned.
We create an offline dataset to showcase the warm-start feature. For this purpose, 100 data points are randomly selected. The features are considered as the context and an action is generated for each sample by selecting one class randomly from the seven (probability=1/7). During the training and deployment loop, the hosted bandits model generates a predicted class (action) and the associated probability. Again, the reward is assigned as one if the predicted class matches the actual class. Otherwise, it is set to zero. After every 500 data points the accumulated data is used to re-train the model that is deployed based on its offline model evaluation.
Local vs Amazon SageMaker modes
The explore/exploit strategy requires iterative training and model deployment cycles. For faster experimentation/development cycles, we have used the Amazon SageMaker local mode. In this mode, the model training, data joins, and deployment are happening in the Amazon SageMaker notebook instance, which aids faster iteration. You can easily move from the local mode to training in Amazon SageMaker for production use-cases where you need to scale to a high model throughput with a single click.
Comparing different Exploration strategies
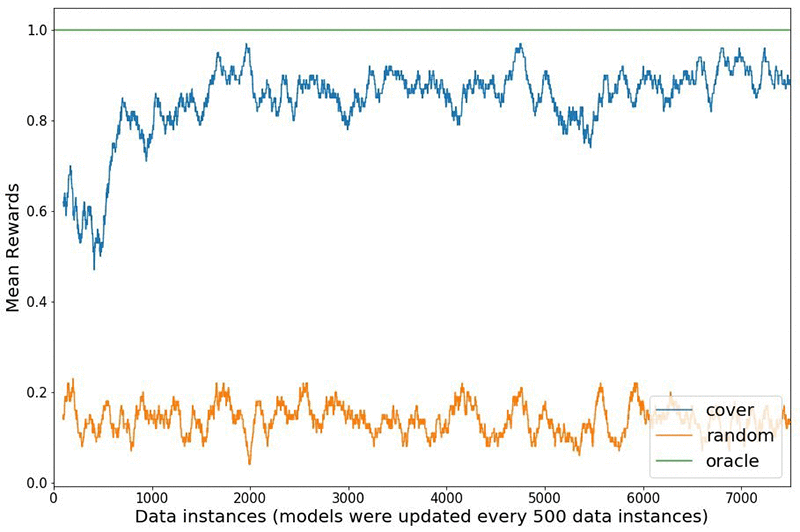
We compare the rewards received in the Statlog (Shuttle) simulated environment between using a naive random strategy to explore the environment versus a bandit algorithm called online cover [3]. The figure below shows how the bandit algorithm explores different actions initially, learns from the received rewards and shifts to exploiting as time progresses. The agent receives a reward of one if the predicted action is the correct class and zero otherwise. The oracle always knows the right action to take for each state, and gets a perfect score of one. The experiment starts with a model warm started from 100 data points and updates the model every 500 interactions for a total of 7500 interactions. The rewards shown are a rolling mean over 100 data points. The rewards plot aligns with results reported in the literature [4].
Conclusion
In this blog post, we showcased how to you can use Amazon SageMaker RL and the Amazon SageMaker built-in bandits container to systematically train and deploy contextual bandit models. We explained how you can get started with training multi-armed contextual bandit models interacting with a live environment and updating the model along with efficient exploration. The accompanying Amazon SageMaker example notebook demonstrates how you can manage your own bandits workflow on top of all the benefits offered by the Amazon SageMaker managed service. To learn more about Amazon SageMaker RL, please visit the developer documentation here.
References
- Dudik, M., Langford, J. and Li, L. (2011). Doubly Robust Policy Evaluation and Learning. In Proceedings of the 28thInternational Conferenceon Machine Learning (ICML 2011).
- Dua, D. and Graff, C. (2019). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science.
- Agarwal, A., Hsu, D., Kale, S., Langford, J., Li, L. and Schapire, R.E. (2014). Taming the monster: A fast and simple algorithm for contextual bandits. In Proceedings of the 31st International Conference on Machine Learning (ICML-14).
- Bietti, A., Agarwal, A. and Langford, J. (2018). A Contextual Bandit Bake-off.
About the Authors
 Saurabh Gupta is an Applied Scientist with AWS Deep Learning. He did his MS in AI and Machine Learning from UC San Diego. His interests lie in Natural Language Processing and Reinforcement Learning algorithms, and in providing high performance practical implementations of the former, that are deployable in the real world.
Saurabh Gupta is an Applied Scientist with AWS Deep Learning. He did his MS in AI and Machine Learning from UC San Diego. His interests lie in Natural Language Processing and Reinforcement Learning algorithms, and in providing high performance practical implementations of the former, that are deployable in the real world.
 Bharathan Balaji is a Research Scientist in AWS and his research interests lie in reinforcement learning systems and applications. He contributed to the launch of Amazon SageMaker RL and AWS DeepRacer. He received his Ph.D. in Computer Science and Engineering from University of California, San Diego.
Bharathan Balaji is a Research Scientist in AWS and his research interests lie in reinforcement learning systems and applications. He contributed to the launch of Amazon SageMaker RL and AWS DeepRacer. He received his Ph.D. in Computer Science and Engineering from University of California, San Diego.
 Anna Luo is an Applied Scientist in the AWS. She works on utilizing RL techniques for different domains including supply chain and recommender system. She received her Ph.D. in Statistics from University of California, Santa Barbara.
Anna Luo is an Applied Scientist in the AWS. She works on utilizing RL techniques for different domains including supply chain and recommender system. She received her Ph.D. in Statistics from University of California, Santa Barbara.
 Yijie Zhuang is a Software Engineer with AWS SageMaker. He did his MS in Computer Engineering from Duke. His interests lie in building scalable algorithms and reinforcement learning systems. He contributed to Amazon SageMaker Built-in Algorithms and Amazon SageMaker RL.
Yijie Zhuang is a Software Engineer with AWS SageMaker. He did his MS in Computer Engineering from Duke. His interests lie in building scalable algorithms and reinforcement learning systems. He contributed to Amazon SageMaker Built-in Algorithms and Amazon SageMaker RL.
 Siddhartha Agarwal is a Software Developer with AWS Deep Learning team. He did his Masters in Computer Science from UC San Diego, and currently focuses on bulding Reinforcement Learning solutions on SageMaker. Prior to SageMaker, he worked on Amazon Comprehend, a natural language processing service on AWS. In his leisure time, he loves to cook and explore new places.
Siddhartha Agarwal is a Software Developer with AWS Deep Learning team. He did his Masters in Computer Science from UC San Diego, and currently focuses on bulding Reinforcement Learning solutions on SageMaker. Prior to SageMaker, he worked on Amazon Comprehend, a natural language processing service on AWS. In his leisure time, he loves to cook and explore new places.
 Vineet Khare is a Sciences Manager for AWS Deep Learning. He focuses on building Artificial Intelligence and Machine Learning applications for AWS customers using techniques that are at the forefront of research. In his spare time, he enjoys reading, hiking and spending time with his family.
Vineet Khare is a Sciences Manager for AWS Deep Learning. He focuses on building Artificial Intelligence and Machine Learning applications for AWS customers using techniques that are at the forefront of research. In his spare time, he enjoys reading, hiking and spending time with his family.