Join our meetup, learn, connect, share, and get to know your Toronto AI community.
Browse through the latest deep learning, ai, machine learning postings from Indeed for the GTA.
Are you looking to sponsor space, be a speaker, or volunteer, feel free to give us a shout.
Hello r/MachineLearning,
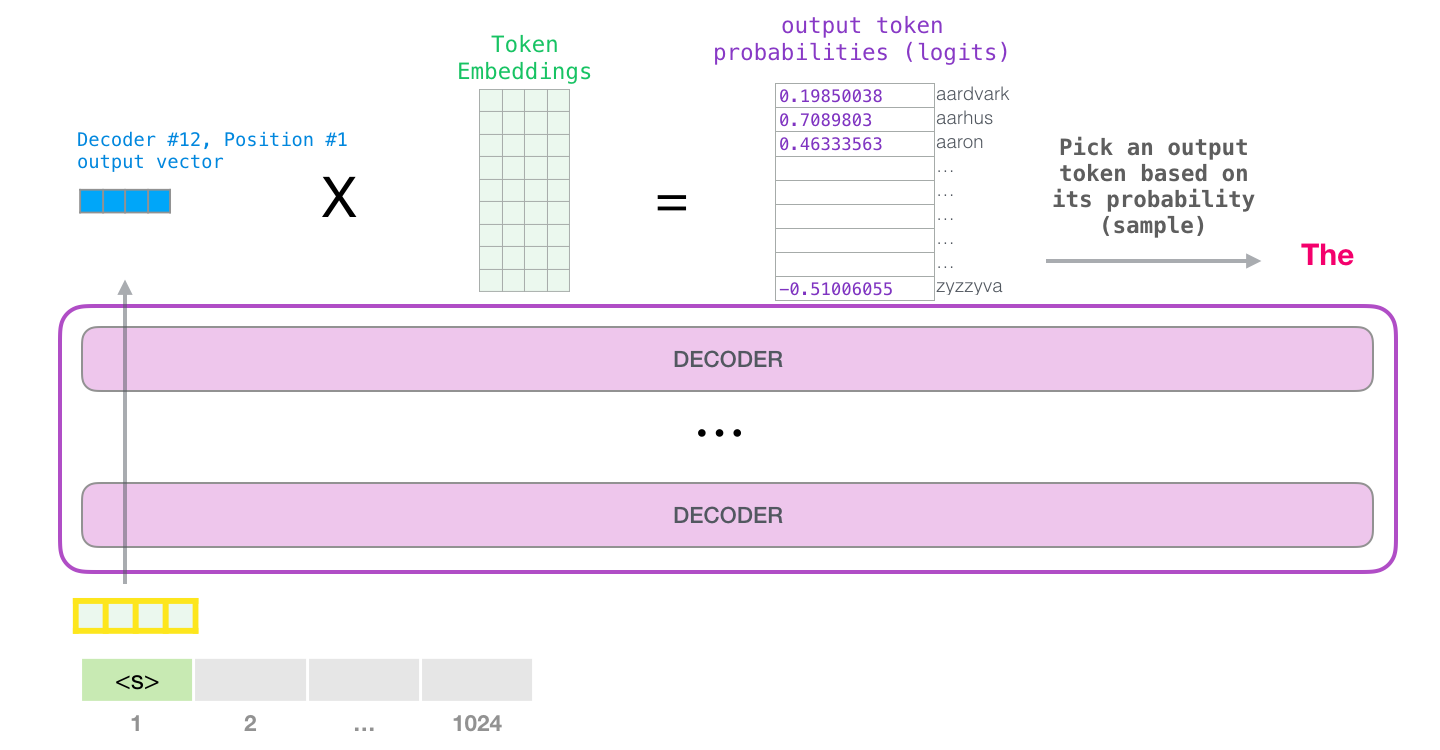
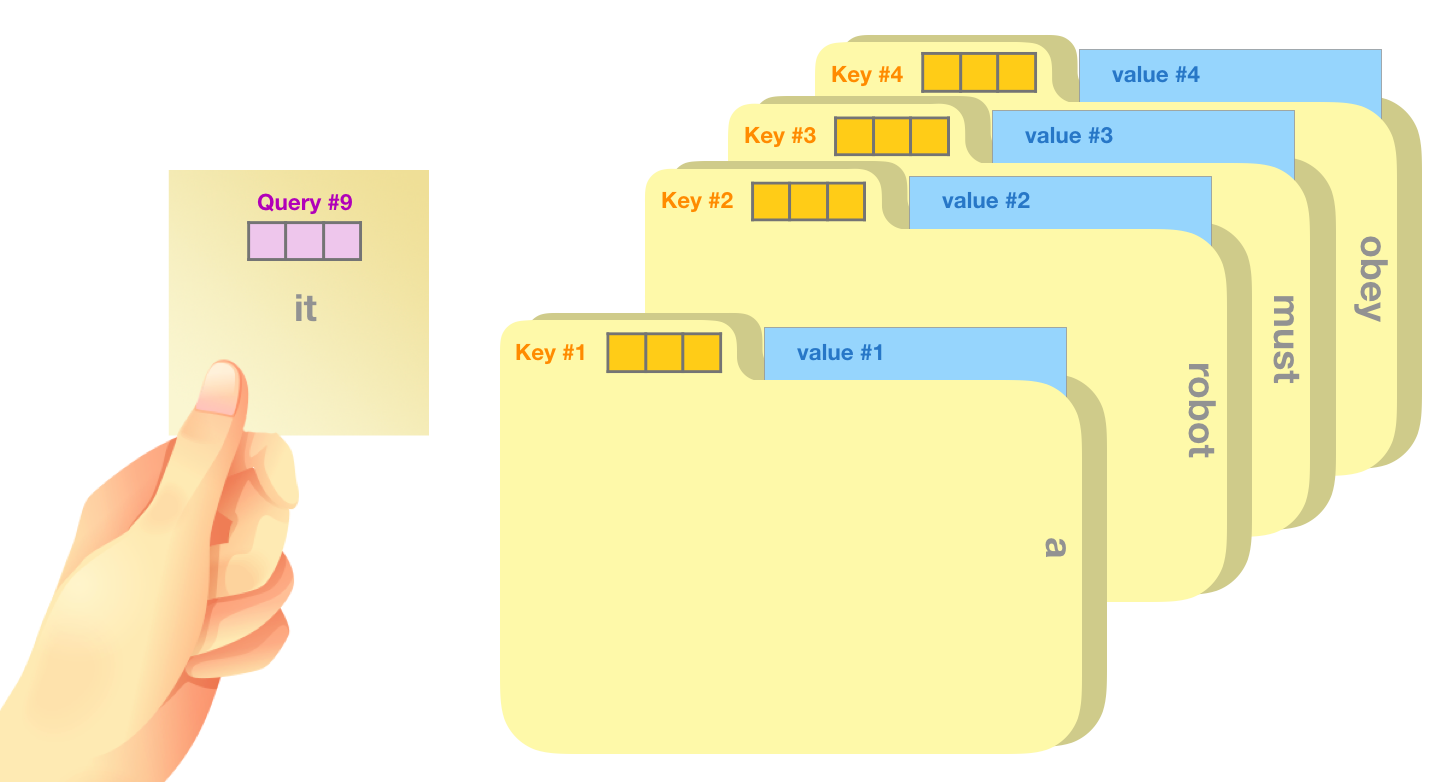
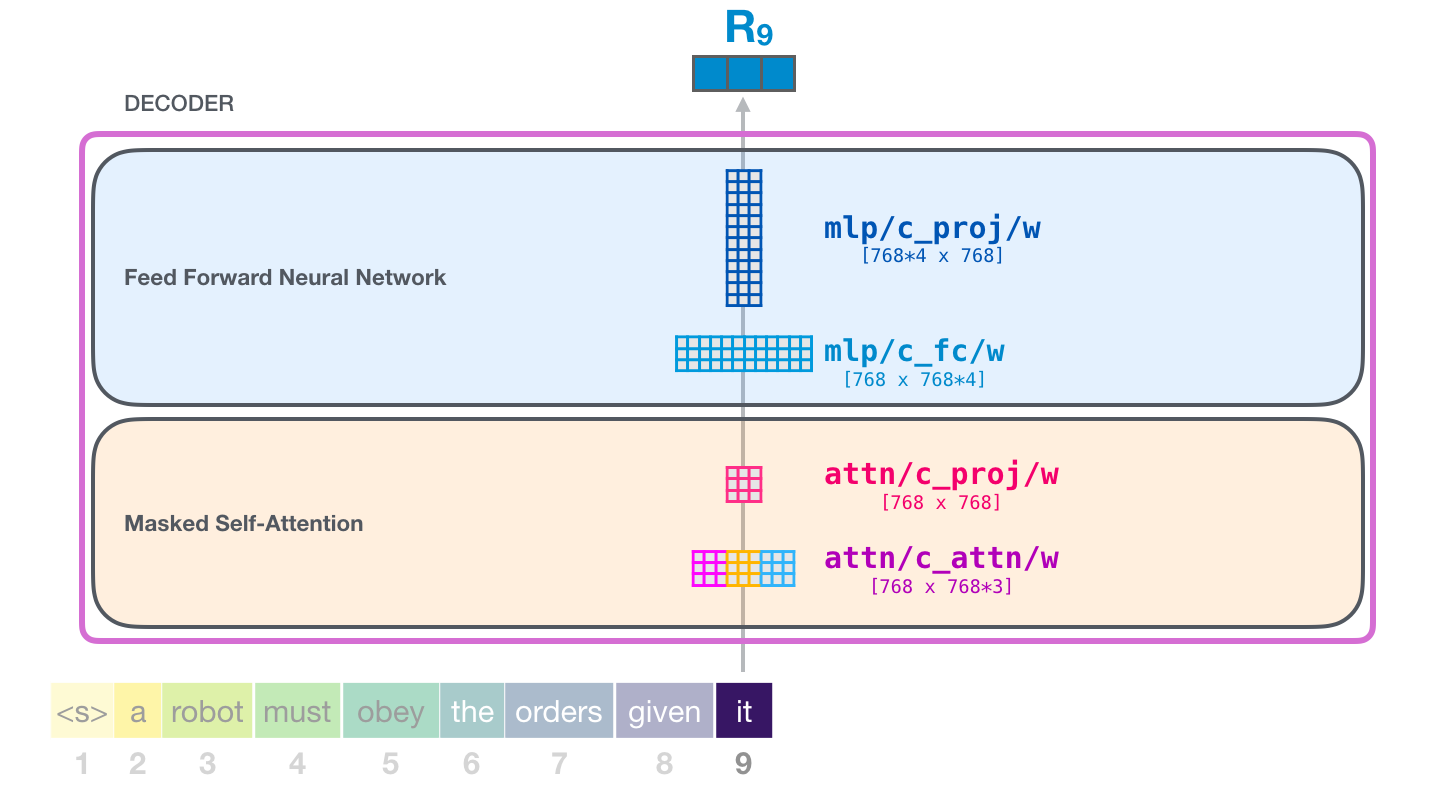
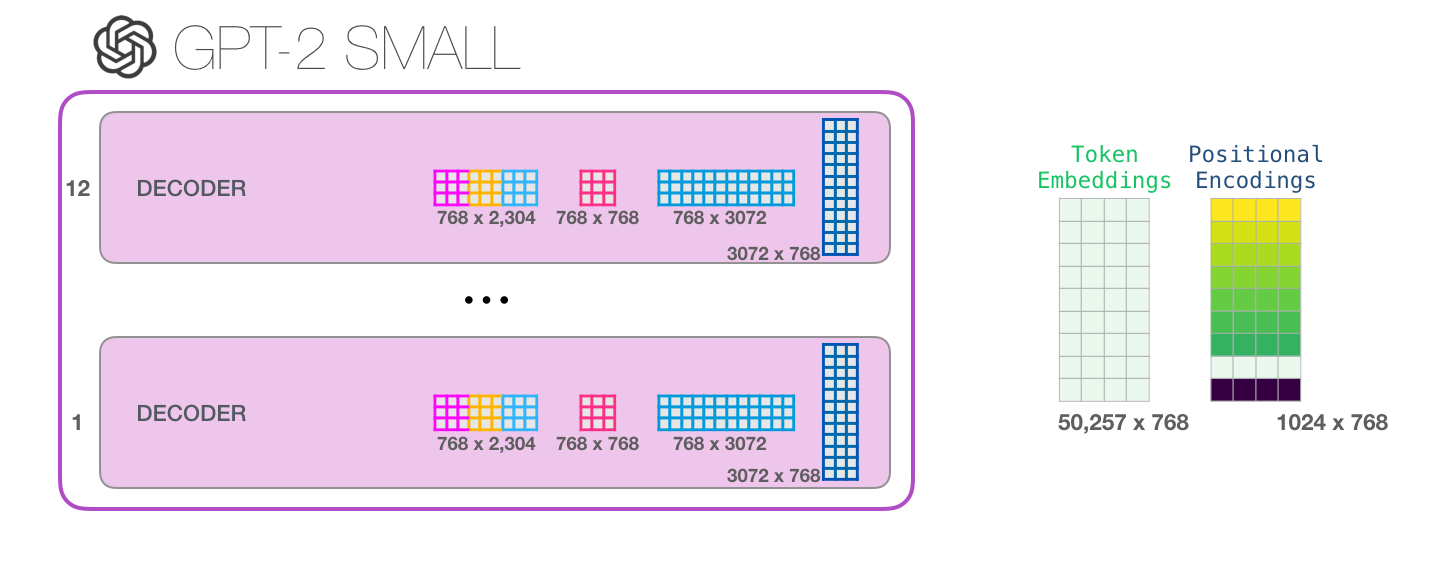
This is a new post in which I try to visualize the majority of what happens inside a trained GPT-2. We follow the journey of an input word from embedding, all the way up to the output of the model. I’ve also included a crude analogy for the query/key/value vectors of self-attention that I hope makes it easier for people starting out with transformer architectures. By the end of the post, we’d have looked at the major weight matrices of a single block, as well as the major weight matrices of the entire model. All feedback and corrections are welcomed!
submitted by /u/nortab
[link] [comments]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}