EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML
For several decades, computer processors have doubled their performance every couple of years by reducing the size of the transistors inside each chip, as described by Moore’s Law. As reducing transistor size becomes more and more difficult, there is a renewed focus in the industry on developing domain-specific architectures — such as hardware accelerators — to continue advancing computational power. This is especially true for machine learning, where efforts are aimed at building specialized architectures for neural network (NN) acceleration. Ironically, while there has been a steady proliferation of these architectures in data centers and on edge computing platforms, the NNs that run on them are rarely customized to take advantage of the underlying hardware.
Today, we are happy to announce the release of EfficientNet-EdgeTPU, a family of image classification models derived from EfficientNets, but customized to run optimally on Google’s Edge TPU, a power-efficient hardware accelerator available to developers through the Coral Dev Board and a USB Accelerator. Through such model customizations, the Edge TPU is able to provide real-time image classification performance while simultaneously achieving accuracies typically seen only when running much larger, compute-heavy models in data centers.
Using AutoML to customize EfficientNets for Edge TPU
EfficientNets have been shown to achieve state-of-the-art accuracy in image classification tasks while significantly reducing the model size and computational complexity. To build EfficientNets designed to leverage the Edge TPU’s accelerator architecture, we invoked the AutoML MNAS framework and augmented the original EfficientNet’s neural network architecture search space with building blocks that execute efficiently on the Edge TPU (discussed below). We also built and integrated a “latency predictor” module that provides an estimate of the model latency when executing on the Edge TPU, by running the models on a cycle-accurate architectural simulator. The AutoML MNAS controller implements a reinforcement learning algorithm to search this space while attempting to maximize the reward, which is a joint function of the predicted latency and model accuracy. From past experience, we know that Edge TPU’s power efficiency and performance tend to be maximized when the model fits within its on-chip memory. Hence we also modified the reward function to generate a higher reward for models that satisfy this constraint.
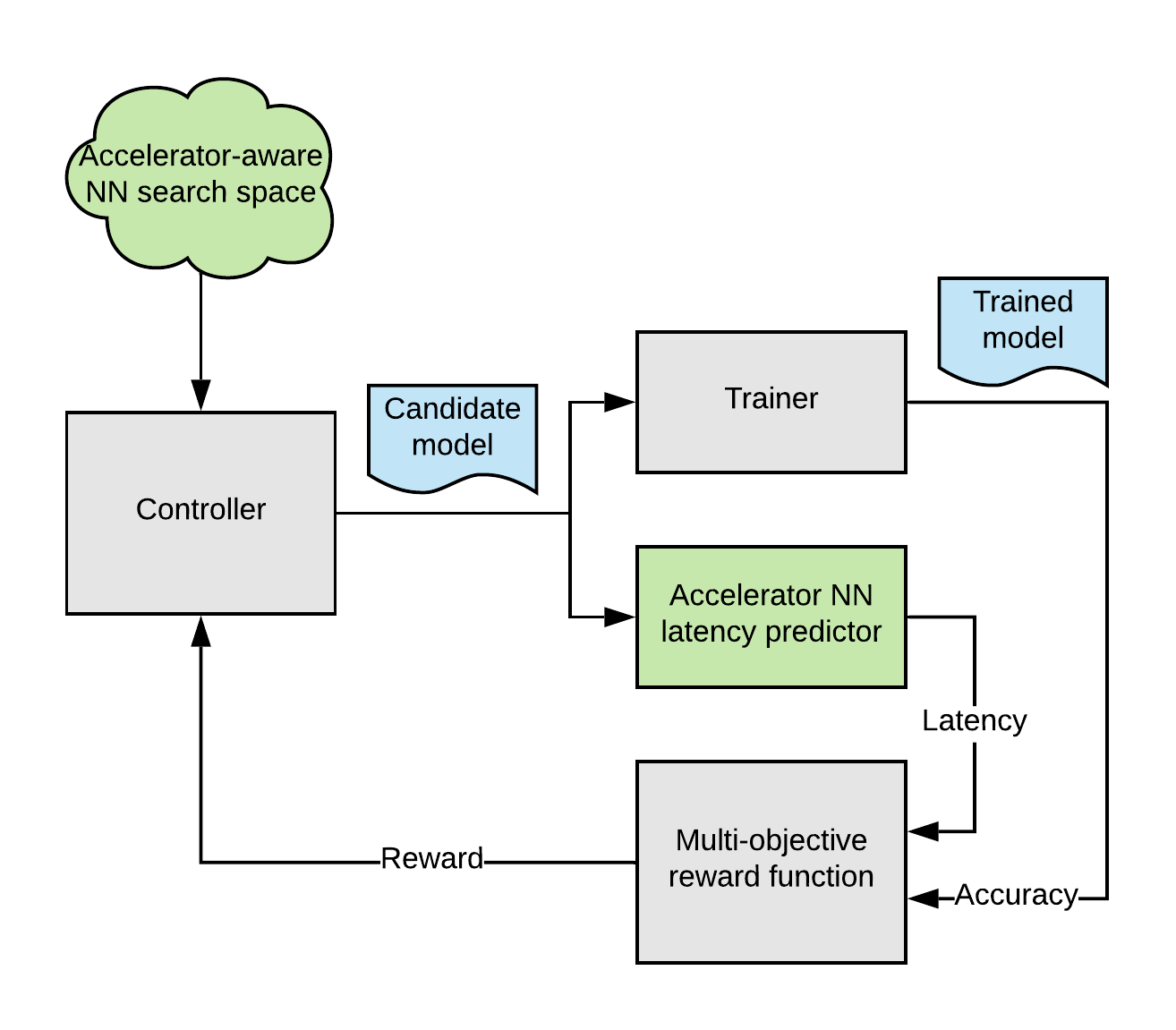 |
| Overall AutoML flow for designing customized EfficientNet-EdgeTPU models. |
Search Space Design
When performing the architecture search described above, one must consider that EfficientNets rely primarily on depthwise-separable convolutions, a type of neural network block that factorizes a regular convolution to reduce the number of parameters as well as the amount of computations. However, for certain configurations, a regular convolution utilizes the Edge TPU architecture more efficiently and executes faster, despite the much larger amount of compute. While it is possible, albeit tedious, to manually craft a network that uses an optimal combination of the different building blocks, augmenting the AutoML search space with these accelerator-optimal blocks is a more scalable approach.
 |
| A regular 3×3 convolution (right) has more compute (multiply-and-accumulate (mac) operations) than an depthwise-separable convolution (left), but for certain input/output shapes, executes faster on Edge TPU due to ~3x more effective hardware utilization. |
In addition, removing certain operations from the search space that require modifications to the Edge TPU compiler to fully support, such swish non-linearity and squeeze-and-excitation block, naturally leads to models that are readily ported to the Edge TPU hardware. These operations tend to improve model quality slightly, so by eliminating them from the search space, we have effectively instructed AutoML to discover alternate network architectures that may compensate for any potential loss in quality.
Model Performance
The neural architecture search (NAS) described above produced a baseline model, EfficientNet-EdgeTPU-S, which is subsequently scaled up using EfficientNet’s compound scaling method to produce the -M and -L models. The compound scaling approach selects an optimal combination of input image resolution scaling, network width, and depth scaling to construct larger, more accurate models. The -M, and -L models achieve higher accuracy at the cost of increased latency as shown in the figure below.
 |
| EfficientNet-EdgeTPU-S/M/L models achieve better latency and accuracy than existing EfficientNets (B1), ResNet, and Inception by specializing the network architecture for Edge TPU hardware. In particular, our EfficientNet-EdgeTPU-S achieves higher accuracy, yet runs 10x faster than ResNet-50. |
Interestingly, the NAS-generated model employs the regular convolution quite extensively in the initial part of the network where the depthwise-separable convolution tends to be less effective than the regular convolution when executed on the accelerator. This clearly highlights the fact that trade-offs usually made while optimizing models for general purpose CPUs (reducing the total number of operations, for example) are not necessarily optimal for hardware accelerators. Also, these models achieve high accuracy even without the use of esoteric operations. Comparing with the other image classification models such as Inception-resnet-v2 and Resnet50, EfficientNet-EdgeTPU models are not only more accurate, but also run faster on Edge TPUs.
This work represents a first experiment in building accelerator-optimized models using AutoML. The AutoML-based model customization can be extended to not only a wide range of hardware accelerators, but also to several different applications that rely on neural networks.
From Cloud TPU training to Edge TPU deployment
We have released the training code and pretrained models for EfficientNet-EdgeTPU on our github repository. We employ tensorflow’s post-training quantization tool to convert a floating-point trained model to an Edge TPU-compatible integer-quantized model. For these models, the post-training quantization works remarkably well and produces only a very slight loss in accuracy (~0.5%). The script for exporting the quantized model from a training checkpoint can be found here. For an update on the Coral platform, see this post on the Google Developer’s Blog, and for full reference materials and detailed instructions, please refer to the Coral website.
Acknowledgements
Special thanks to Quoc Le, Hongkun Yu, Yunlu Li, Ruoming Pang, and Vijay Vasudevan from the Google Brain team; Bo Wu, Vikram Tank, and Ajay Nair from the Google Coral team; Han Vanholder, Ravi Narayanaswami, John Joseph, Dong Hyuk Woo, Raksit Ashok, Jason Jong Kyu Park, Jack Liu, Mohammadali Ghodrat, Cao Gao, Berkin Akin, Liang-Yun Wang, Chirag Gandhi, and Dongdong Li from the Google Edge TPU team.
