Running Amazon Elastic Inference Workloads on Amazon ECS
Amazon Elastic Inference (EI) is a new service launched at re:Invent 2018. Elastic Inference reduces the cost of running deep learning inference by up to 75% compared to using standalone GPU instances. Elastic Inference lets you attach accelerators to any Amazon SageMaker or Amazon EC2 instance type and run inference on TensorFlow, Apache MXNet, and ONNX models. Amazon ECS is a highly scalable, high-performance container orchestration service that supports Docker containers and allows you to run and scale containerized applications on AWS easily.
In this post, I describe how to accelerate deep learning inference workloads in Amazon ECS by using Elastic Inference. I also demonstrate how multiple containers, running potentially different workloads on the same ECS container instance, can share a single Elastic Inference accelerator. This sharing enables higher accelerator utilization.
As of February 4, 2019, ECS supports pinning GPUs to tasks. This works well for training workloads. However, for inference workloads, using Elastic Inference from ECS is more cost effective when those GPUs are not fully used.
For example, the following diagram shows a cost efficiency comparison of a p2/p3 instance type and a c5.large instance type with each type of Elastic Inference accelerator per 100K single-threaded inference calls (normalized by minimal cost):
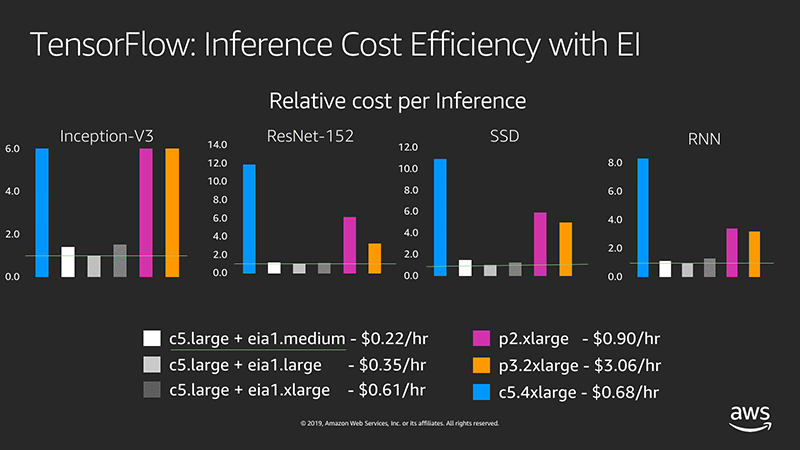
TensorFlow: Inference Cost Efficiency with EI
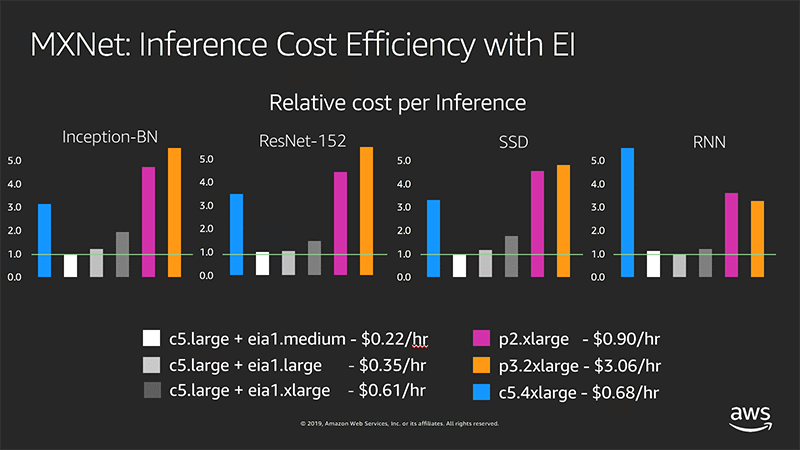
MXNet: Inference Cost Efficiency with EI
Using Elastic Inference on ECS
As an example, this post spins up TensorFlow ModelServer containers as part of an ECS task. You try to identify objects in a single image (the giraffe image that follows), using an SSD with ResNet-50 model, trained with a COCO dataset.

Next, you profile and compare the inference latencies of both a regular and an Elastic Inference–enabled TensorFlow ModelServer. Base your profiling setup on the Elastic Inference with TensorFlow Serving example. You can follow step-by-step instructions or launch an AWS CloudFormation stack with the same infrastructure as this post. Either way, you must be logged into your AWS account as an administrator. For AWS CloudFormation stack creation, choose Launch Stack and follow the instructions.
![]()
If Elastic Inference is not supported in the selected Availability Zone, delete and re-create the stack with a different zone. To launch the stack in a Region other than us-east-1, use the same template and template URL. Make sure to select the appropriate Region and Availability Zone.
After choosing Launch Stack, you can also examine the AWS CloudFormation template in detail in AWS CloudFormation Designer.
The AWS CloudFormation stack includes the following resources:
- A VPC
- A subnet
- An Internet gateway
- An Elastic Inference endpoint
- IAM roles and policies
- Security groups and rules
- Two EC2 instances
- One for running TensorFlow ModelServer containers (this instance has an Elastic Inference accelerator attached and works as an ECS container instance).
- One for running a simple client application for making inference calls against the first instance.
- An ECS task definition
After you create the AWS CloudFormation stack:
- Go directly to the Running an Elastic Inference-enabled TensorFlow ModelServer task section in this post.
- Skip Making inference calls.
- Go directly to Verifying the results.
The second instance runs an example application as part of the bootstrap script.
Make sure to delete the stack once it is no longer needed.
Create an ecsInstanceRole to be used by the ECS container instance
In this step, you create an ecsInstanceRole role to be used by the ECS container instance through an associated instance profile.
In the IAM console, check if an ecsInstanceRole role exists. If the role does not exist, create a new role with the managed policy AmazonEC2ContainerServiceforEC2Role attached and name it ecsInstanceRole. Update its trust policy with the following code:
Setting up an ECS container instance for Elastic Inference
Your goal is to launch an ECS container instance with an Elastic Inference endpoint attached and with the following additional properties:
- Region: us-east-1
- AMI ID: ami-0fac5486e4cff37f4 (latest ECS-optimized Amazon Linux 2 AMI)
- Instance type: c5.large
- IAM role:ecsInstanceRole
Launching the stack automates the setup process. To execute the steps manually, follow the instructions to set up an EC2 instance for Elastic Inference. Make the following changes to these procedures, for simplicity.
Because you plan to call Elastic Inference from ECS tasks, define a task role with relevant permissions. In the IAM console, create a new role with the following properties:
- Trusted entity type: AWS service
- Service to use this role: Elastic Container Service
- Select your use case: Elastic Container Service Task
- Name: ecs-ei-task-role
In the Attach permissions policies step, select the policy that you created in Set up an EC2 instance for Elastic Inference step. The policy’s content should look like the following example:
Only the elastic-inference:Connect permission is required. The remaining permissions provide troubleshooting assistance. You can remove them for production setup.
To validate the role’s trust relationship, on the Trust Relationships tab, choose Show policy document. The policy should look like the following:
Creating an ECS task execution IAM role
Running on an ECS container instance, the ECS agent needs permissions to make ECS API calls on behalf of the task (for example, pulling container images from ECR). As a result, you must create an IAM role that captures the exact permissions needed. If you’ve created any ECS tasks before, you probably have created this or an equivalent role. For more information, see ECS Task Execution IAM Role.
If no such role exists, in the IAM console, choose Roles and create a new role with the following properties:
- Trusted entity type: AWS service
- Service to this role: Elastic Container Service
- Select your use case: Elastic Container Service Task
- Name: ecsTaskExecutionRole
- Attached managed policy: AmazonECSTaskExecutionRolePolicy
Creating a task definition for both regular and Elastic Inference–enabled TensorFlow ModelServer containers
In this step, you create an ECS task definition comprising two containers:
- One running TensorFlow ModelServer
- One running an Elastic Inference-enabled TensorFlow ModelServer
Both containers use tensorflow-inference: 1.13-cpu-py27-ubuntu16.04 image (one of the newly released Deep Learning Containers Images). These images already have a regular TensorFlow ModelServer and all its library dependencies. Both containers retrieve and set up the relevant model.
Second container, downloads the Elastic Inference-enabled TensorFlow ModelServer binary. It also removes the ECS_CONTAINER_METADATA_URI environment variable setting to enable Elastic Inference endpoint metadata lookup from the ECS container instance’s metadata:
For a regular production setup, I recommend creating a new image from the deep learning container image by turning relevant steps into Dockerfile RUN commands. For this post, you can skip that for simplicity’s sake.
First container downloads model and then, runs the unchanged /usr/bin/tf_serving_entrypoint.sh:
In the ECS console, under Task Definitions, choose Create New Task Definitions.
In the Select launch type compatibility dialog box, choose EC2.
In the Create new revision of Task Definition dialog box, scroll to the bottom of the page and choose Configure via JSON.
Paste the following definition into the space provided. Before saving, make sure to replace the two occurrences of <replace-with-your-account-id> with your AWS account ID.
You could create an ECS service out of this task definition, but for the sake of this post, you need only run the task.
Running an Elastic Inference–enabled TensorFlow ModelServer task
Make sure to run the task defined in the previous section on the previously created ECS container instance. Register this instance to your default cluster.
In the ECS console, choose Clusters.
Confirm that your EC2 container instance appears in the ECS Instances tab.
Choose Tasks, Run new task.
For Launch type, select EC2, then pick previously created task (task created by CloudFormation template is named ei-ecs-blog-ubuntu-tfs-bridge) and choose Run Task.
Making inference calls
In this step, you create and run a simple client application to make multiple inference calls using the previously built infrastructure. You also launch an EC2 instance with Deep Learning AMI (DLAMI) on which to run the client application. The TensorFlow library that you use in this example requires the AVX2 instructions set.
Pick the c5.large instance type. Any of the latest generation x86-based EC2 instance types with sufficient memory are fine. The DLAMI provides preinstalled libraries on which TensorFlow relies. Also, because DLAMI is an HVM virtualization type AMI, you can take advantage of the AVX2 instruction set provided by c5.large.
Download labels and an example image to do the inference on:
Create a local file named ssd_resnet_client.py, with the following content:
Make sure to edit the ECS container instance’s security group to permit TCP traffic over ports 8500–8501 and 9000–9001 from the client instance IP address.
From the client instance, check connectivity and the status of the model:
Wait until you get two responses like the following:
Then, proceed to run the client application:
Verifying the results
The output should be similar to the following:
If you launched the AWS CloudFormation stack, connect to the client instance with SSH and check the last several lines of this output in /var/log/cloud-init-output.log.
You see a 78% reduction in latency when using an Elastic Inference accelerator with this model and input.
You can launch more than one task and more than one container on the same ECS container instance. You can use the awsvpc network mode if tasks expose the same port numbers. For bridge mode, tasks should expose unique ports.
In multi-task/container scenarios, keep in mind that all clients share accelerator memory. AWS publishes accelerator memory utilization metrics to Amazon CloudWatch as AcceleratorMemoryUsage under the AWS/ElasticInference namespace.
Also, Elastic Inference–enabled containers using the same accelerator must all use either TensorFlow or the MXNet framework. To switch between frameworks, stop and start the ECS container instance.
Conclusion
The described setup shows how multiple deep learning inference workloads running in ECS can be efficiently accelerated by use of Elastic Inference. If inference workload tasks don’t use the entire GPU instance, then using Elastic Inference accelerators may offer an attractive alternative, at a fraction of the cost of dedicated GPU instances. A single accelerator’s capacity can be shared across multiple containers running on the same EC2 container instance, allowing for even greater use of the attached accelerator.
About the Author
 Vladimir Mitrovic is a Software Engineer with AWS AI Deep Learning. He is passionate about building fault-tolerant, distributed deep-learning systems. In his spare time, he enjoys solving Project Euler problems.
Vladimir Mitrovic is a Software Engineer with AWS AI Deep Learning. He is passionate about building fault-tolerant, distributed deep-learning systems. In his spare time, he enjoys solving Project Euler problems.