Robust Neural Machine Translation
In recent years, neural machine translation (NMT) using Transformer models has experienced tremendous success. Based on deep neural networks, NMT models are usually trained end-to-end on very large parallel corpora (input/output text pairs) in an entirely data-driven fashion and without the need to impose explicit rules of language.
Despite this huge success, NMT models can be sensitive to minor perturbations of the input, which can manifest as a variety of different errors, such as under-translation, over-translation or mistranslation. For example, given a German sentence, the state-of-the-art NMT model, Transformer, will yield a correct translation.
(Machine translation to English: “The spokesman of the Committee of Inquiry has announced that if the witnesses summoned continue to refuse to testify, he will be brought to court.”),
But, when we apply a subtle change to the input sentence, say from geladenen to the synonym vorgeladenen, the translation becomes very different (and in this case, incorrect):
(Machine translation to English: “The investigative committee has announced that he will be brought to justice if the witnesses who have been invited continue to refuse to testify.”).
This lack of robustness in NMT models prevents many commercial systems from being applicable to tasks that cannot tolerate this level of instability. Therefore, learning robust translation models is not just desirable, but is often required in many scenarios. Yet, while the robustness of neural networks has been extensively studied in the computer vision community, only a few prior studies on learning robust NMT models can be found in literature.
In “Robust Neural Machine Translation with Doubly Adversarial Inputs” (to appear at ACL 2019), we propose an approach that uses generated adversarial examples to improve the stability of machine translation models against small perturbations in the input. We learn a robust NMT model to directly overcome adversarial examples generated with knowledge of the model and with the intent of distorting the model predictions. We show that this approach improves the performance of the NMT model on standard benchmarks.
Training a Model with AdvGen
An ideal NMT model would generate similar translations for separate inputs that exhibit small differences. The idea behind our approach is to perturb a translation model with adversarial inputs in the hope of improving the model’s robustness. It does this using an algorithm called Adversarial Generation (AdvGen), which generates plausible adversarial examples for perturbing the model and then feeds them back into the model for defensive training. While this method is inspired by the idea of generative adversarial networks (GANs), it does not rely on a discriminator network, but simply applies the adversarial example in training, effectively diversifying and extending the training set.
The first step is to perturb the model using AdvGen. We start by using Transformer to calculate the translation loss based on a source input sentence, a target input sentence and a target output sentence. Then AdvGen randomly selects some words in the source sentence, assuming a uniform distribution. Each word has an associated list of similar words, i.e., candidates that can be used for substitution, from which AdvGen selects the word that is most likely to introduce errors in Transformer output. Then, this generated adversarial sentence is fed back into Transformer, initiating the defense stage.
 |
| First, the Transformer model is applied to an input sentence (lower left) and, in conjunction with the target output sentence (above right) and target input sentence (middle right; beginning with the placeholder “<sos>”), the translation loss is calculated. The AdvGen function then takes the source sentence, word selection distribution, word candidates, and the translation loss as inputs to construct an adversarial source example. |
During the defend stage, the adversarial sentence is fed back into the Transformer model. Again the translation loss is calculated, but this time using the adversarial source input. Using the same method as above, AdvGen uses the target input sentence, word replacement candidates, the word selection distribution calculated by the attention matrix, and the translation loss to construct an adversarial target example.
 |
| In the defense stage, the adversarial source example serves as input to the Transformer model, and the translation loss is calculated. AdvGen then uses the same method as above to generate an adversarial target example from the target input. |
Finally, the adversarial sentence is fed back into Transformer and the robustness loss using the adversarial source example, the adversarial target input example and the target sentence is calculated. If the perturbation led to a significant loss, the loss is minimized so that when the model is confronted with similar perturbations, it will not repeat the same mistake. On the other hand, if the perturbation leads to a low loss, nothing happens, indicating that the model can already handle this perturbation.
Model Performance
We demonstrate the effectiveness of our approach by applying it to the standard Chinese-English and English-German translation benchmarks. We observed a notable improvement of 2.8 and 1.6 BLEU points, respectively, compared to the competitive Transformer model, achieving a new state-of-the-art performance.
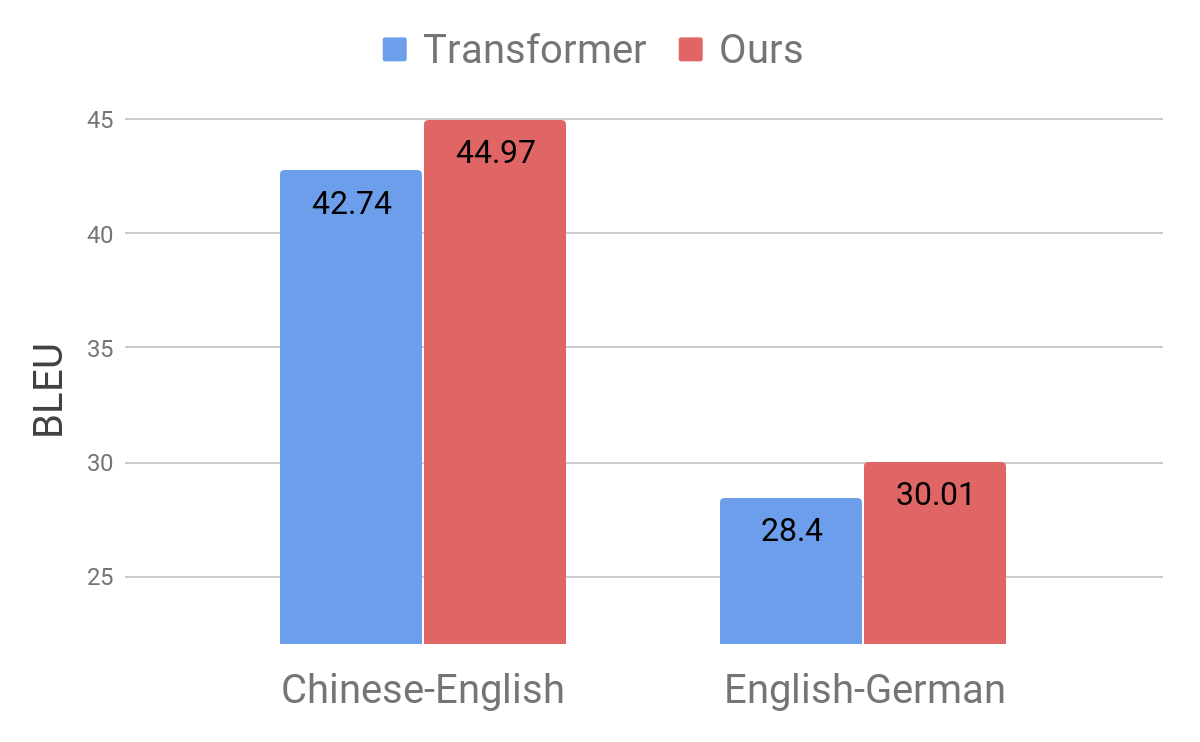 |
| Comparison of Transformer model (Vaswani et al., 2017) on standard benchmarks. |
We then evaluate our model on a noisy dataset, generated using a procedure similar to that described for AdvGen. We take an input clean dataset, such as that used on standard translation benchmarks, and randomly select words for similar word substitution. We find that our model exhibits improved robustness compared to other recent models.
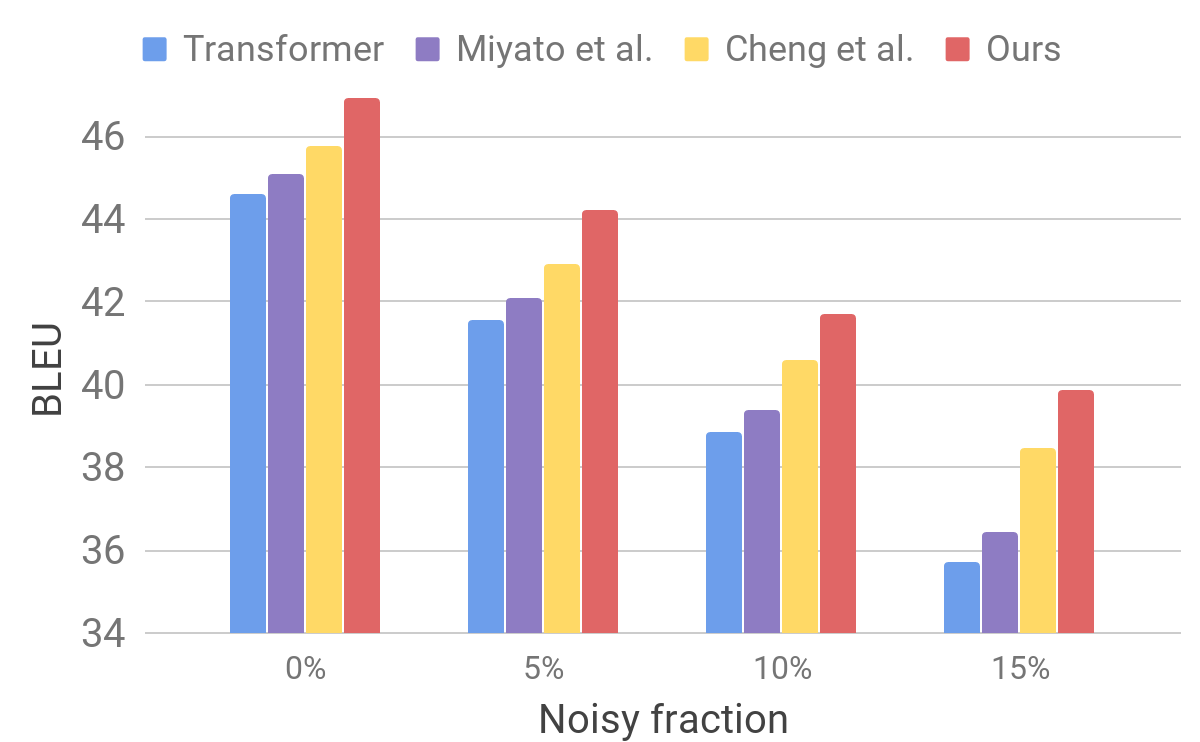 |
| Comparison of Transformer, Miyao et al. and Cheng et al. on artificial noisy inputs. |
These results show that our method is able to overcome small perturbations in the input sentence and improve the generalization performance. It outperforms competitive translation models and achieves state-of-the-art translation performance on standard benchmarks. We hope our translation model will serve as a robust building block for improving many downstream tasks, especially when those are sensitive or intolerant to imperfect translation input.
Acknowledgements
This research was conducted by Yong Cheng, Lu Jiang and Wolfgang Macherey. Additional thanks go to our leadership Andrew Moore and Julia (Wenli) Zhu.
