Introducing Google Research Football: A Novel Reinforcement Learning Environment

The goal of reinforcement learning (RL) is to train smart agents that can interact with their environment and solve complex tasks, with real-world applications towards robotics, self-driving cars, and more. The rapid progress in this field has been fueled by making agents play games such as the iconic Atari console games, the ancient game of Go, or professionally played video games like Dota 2 or Starcraft 2, all of which provide challenging environments where new algorithms and ideas can be quickly tested in a safe and reproducible manner. The game of football is particularly challenging for RL, as it requires a natural balance between short-term control, learned concepts, such as passing, and high level strategy.
Today we are happy to announce the release of the Google Research Football Environment, a novel RL environment where agents aim to master the world’s most popular sport—football. Modeled after popular football video games, the Football Environment provides a physics based 3D football simulation where agents control either one or all football players on their team, learn how to pass between them, and manage to overcome their opponent’s defense in order to score goals. The Football Environment provides several crucial components: a highly-optimized game engine, a demanding set of research problems called Football Benchmarks, as well as the Football Academy, a set of progressively harder RL scenarios. In order to facilitate research, we have released a beta version of the underlying open-source code on Github.
Football Engine
The core of the Football Environment is an advanced football simulation, called Football Engine, which is based on a heavily modified version of Gameplay Football. Based on input actions for the two opposing teams, it simulates a match of football including goals, fouls, corner and penalty kicks, and offsides. The Football Engine is written in highly optimized C++ code, allowing it to be run on off-the-shelf machines, both with GPU and without GPU-based rendering enabled. This allows it to reach a performance of approximately 25 million steps per day on a single hexa-core machine.
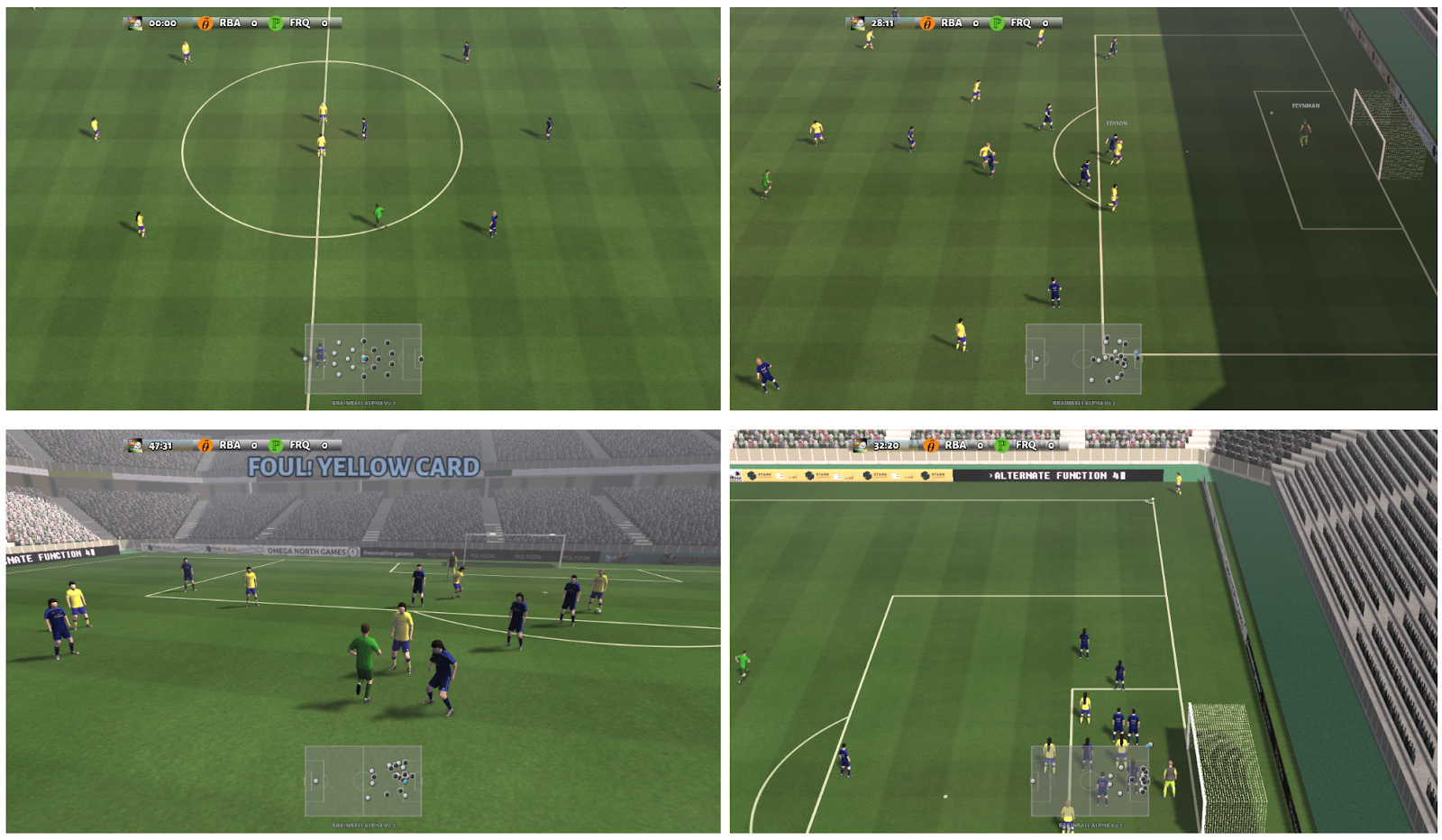 |
| The Football Engine is an advanced football simulation that supports all the major football rules such as kickoffs (top left), goals (top right), fouls, cards (bottom left), corner and penalty kicks (bottom right), and offside. |
The Football Engine has additional features geared specifically towards RL. First, it allows learning from both different state representations, which contain semantic information such as the player’s locations, as well as learning from raw pixels. Second, to investigate the impact of randomness, it can be run in both a stochastic mode (enabled by default), in which there is randomness in both the environment and opponent AI actions, and in a deterministic mode, where there is no randomness. Third, the Football Engine is out of the box compatible with the widely used OpenAI Gym API. Finally, researchers can get a feeling for the game by playing against each other or their agents, using either keyboards or gamepads.
Football Benchmarks
With the Football Benchmarks, we propose a set of benchmark problems for RL research based on the Football Engine. The goal in these benchmarks is to play a “standard” game of football against a fixed rule-based opponent that was hand-engineered for this purpose. We provide three versions: the Football Easy Benchmark, the Football Medium Benchmark, and the Football Hard Benchmark, which only differ in the strength of the opponent.
As a reference, we provide benchmark results for two state-of-the-art reinforcement learning algorithms: DQN and IMPALA, which both can be run in multiple processes on a single machine or concurrently on many machines. We investigate both the setting where the only rewards provided to the algorithm are the goals scored and the setting where we provide additional rewards for moving the ball closer to the goal.
Our results indicate that the Football Benchmarks are interesting research problems of varying difficulties. In particular, the Football Easy Benchmark appears to be suitable for research on single-machine algorithms while the Football Hard Benchmark proves to be challenging even for massively distributed RL algorithms. Based on the nature of the environment and the difficulty of the benchmarks, we expect them to be useful for investigating current scientific challenges such as sample-efficient RL, sparse rewards, or model based RL.
 |
| The average goal difference of agent versus opponent at different difficulty levels for different baselines. The Easy opponent can be beaten by a DQN agent trained for 20 million steps, while the Medium and Hard opponents require a distributed algorithm such as IMPALA that is trained for 200 million steps. |
Football Academy & Future Directions
As training agents for the full Football Benchmarks can be challenging, we also provide Football Academy, a diverse set of scenarios of varying difficulty. This allows researchers to get the ball rolling on new research ideas, allows testing of high-level concepts (such as passing), and provides a foundation to investigate curriculum learning research ideas, where agents learn from progressively harder scenarios. Examples of the Football Academy scenarios include settings where agents have to learn how to score against the empty goal, where they have to learn how to quickly pass between players, and where they have to learn how to execute a counter-attack. Using a simple API, researchers can further define their own scenarios and train agents to solve them.
 |
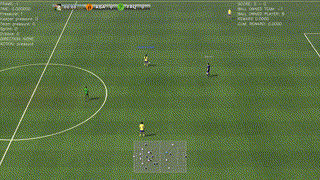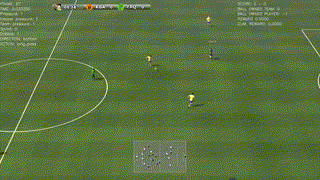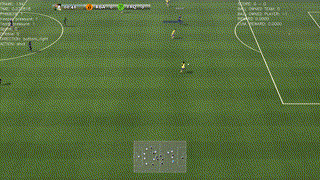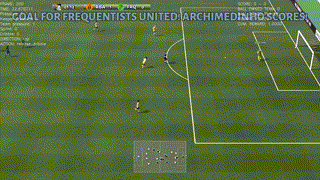 |
 |
 |
| Top: A successful policy that runs towards the goal (as required, since a number of opponents chase our player) and scores against the goal-keeper. Second: A beautiful way to drive and finish a counter-attack. Third: A simple way to solve a 2-vs-1 play. Bottom: The agent scores after a corner kick. |
The Football Benchmarks and the Football Academy consider the standard RL setup, in which agents compete against a fixed opponent, i.e., where the opponent can be considered a part of the environment. Yet, in reality, football is a two-player game where two different teams compete and where one has to adapt to the actions and strategy of the opposing team. The Football Engine provides a unique opportunity for research into this setting and, once we complete our on-going effort to implement self-play, even more interesting research settings can be investigated.
Acknowledgments
This project was undertaken together with Anton Raichuk, Piotr Stańczyk, Michał Zając, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet and Sylvain Gelly at Google Research, Zürich. We also wish to thank Lucas Beyer, Nal Kalchbrenner, Tim Salimans and the rest of the Google Brain team for helpful discussions, comments, technical help and code contributions. Finally, we would like to thank Bastiaan Konings Schuiling, who authored and open-sourced the original version of this game.
