1000x Faster Data Augmentation

Effect of Population Based Augmentation applied to images, which differs at different percentages into training.
In this blog post we introduce Population Based Augmentation (PBA), an
algorithm that quickly and efficiently learns a state-of-the-art approach to
augmenting data for neural network training. PBA matches the previous best
result on CIFAR and SVHN but uses one thousand times less
compute, enabling researchers and practitioners to effectively learn
new augmentation policies using a single workstation GPU. You can use PBA
broadly to improve deep learning performance on image recognition tasks.
We discuss the PBA results from our recent paper and then show how
to easily run PBA for yourself on
a new data set in the Tune framework.
Why should you care about data augmentation?
Recent advances in deep learning models have been largely attributed to the
quantity and diversity of data gathered in recent years. Data augmentation is a
strategy that enables practitioners to significantly increase the diversity of
data available for training models, without actually collecting new data. Data
augmentation techniques such as cropping, padding, and horizontal flipping are
commonly used to train large neural networks. However, most approaches used in
training neural networks only use basic types of augmentation. While neural
network architectures have been investigated in depth, less focus has been put
into discovering strong types of data augmentation and data augmentation
policies that capture data invariances.

An image of the number “3” in original form and with basic augmentations
applied.
Recently, Google has been able to push the state-of-the-art accuracy on
datasets such as CIFAR-10 with AutoAugment, a new automated data
augmentation technique. AutoAugment has shown that prior work using just
applying a fixed set of transformations like horizontal flipping or padding and
cropping leaves potential performance on the table. AutoAugment introduces 16
geometric and color-based transformations, and formulates an augmentation
policy that selects up to two transformations at certain magnitude levels to
apply to each batch of data. These higher performing augmentation policies are
learned by training models directly on the data using reinforcement learning.
What’s the catch?
AutoAugment is a very expensive algorithm which requires training 15,000 models
to convergence to generate enough samples for a reinforcement learning based
policy. No computation is shared between samples, and it costs 15,000 NVIDIA
Tesla P100 GPU hours to learn an ImageNet augmentation policy and 5,000 GPU
hours to learn an CIFAR-10 one. For example, if using Google Cloud on-demand
P100 GPUs, it would cost about $7,500 to discover a CIFAR policy, and $37,500
to discover an ImageNet one! Therefore, a more common use case when training on
a new dataset would be to transfer a pre-existing published policy, which the
authors show works relatively well.
Population Based Augmentation
Our formulation of data augmentation policy search, Population Based
Augmentation (PBA), reaches similar levels of test accuracy on a variety of
neural network models while utilizing three orders of magnitude less compute.
We learn an augmentation policy by training several copies of a small model on
CIFAR-10 data, which takes five hours using a NVIDIA Titan XP GPU. This policy
exhibits strong performance when used for training from scratch on larger model
architectures and with CIFAR-100 data.
Relative to the several days it takes to train large CIFAR-10 networks to
convergence, the cost of running PBA beforehand is marginal and significantly
enhances results. For example, training a PyramidNet model on CIFAR-10 takes
over 7 days on a NVIDIA V100 GPU, so learning a PBA policy adds only 2%
precompute training time overhead. This overhead would be even lower, under 1%,
for SVHN.
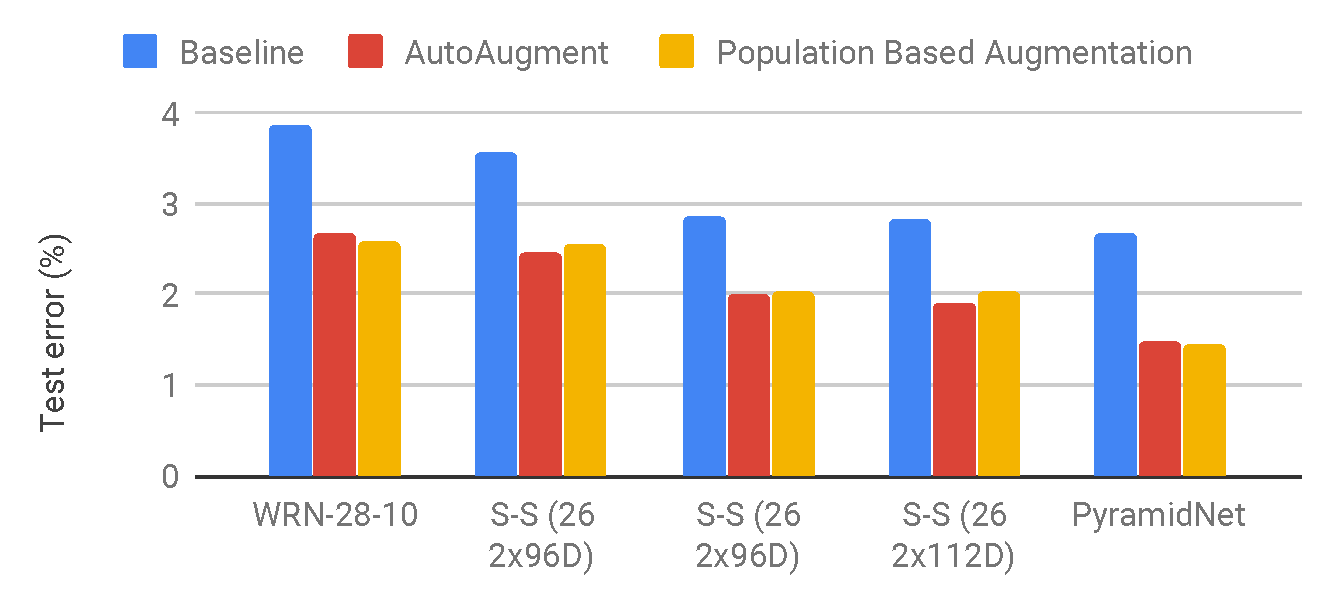
CIFAR-10 test set error between PBA, AutoAugment, and the baseline which only
uses horizontal flipping, padding, and cropping, on WideResNet, Shake-Shake, and PyramidNet+ShakeDrop models. PBA is
significantly better than the baseline and on-par with AutoAugment.
PBA leverages the Population
Based Training algorithm to generate an augmentation policy schedule which
can adapt based on the current epoch of training. This is in contrast to a
fixed augmentation policy that applies the same transformations independent of
the current epoch number.
This allows an ordinary workstation user to easily experiment with the search
algorithm and augmentation operations. One interesting use case would be to
introduce new augmentation operations, perhaps targeted towards a particular
dataset or image modality, and be able to quickly produce a tailored, high
performing augmentation schedule. Through ablation studies, we have found that
the learned hyperparameters and schedule order are important for good results.
How is the augmentation schedule learned?
We use Population Based Training with a population of 16 small WideResNet
models. Each worker in the population will learn a different candidate
hyperparameter schedule. We transfer the best performing schedule to train
larger models from scratch, from which we derive our test error metrics.
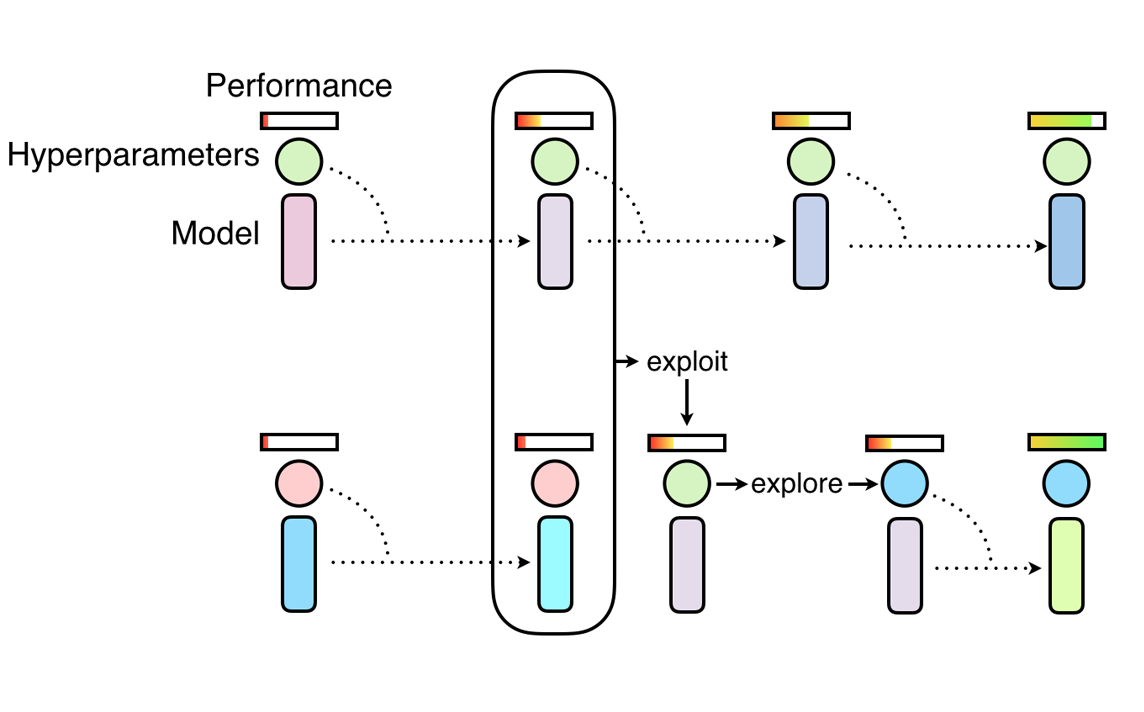
Overview of Population Based Training, which discovers hyperparameter schedules
by training a population of neural networks. It combines random search
(explore) with the copying of model weights from high performing workers
(exploit). Source
The population models are trained on the target dataset of interest starting
with all augmentation hyperparameters set to 0 (no augmentations applied). At
frequent intervals, an “exploit-and-explore” process “exploits” high performing
workers by copying their model weights to low performing workers, and then
“explores” by perturbing the hyperparameters of the worker. Through this
process, we are able to share compute heavily between the workers and target
different augmentation hyperparameters at different regions of training. Thus,
PBA is able to avoid the cost of training thousands of models to convergence in
order to reach high performance.
Example and Code
We leverage Tune’s built-in implementation of PBT to make it straightforward to
use PBA.
import ray
def explore(config):
"""Custom PBA function to perturb augmentation hyperparameters."""
...
ray.init()
pbt = ray.tune.schedulers.PopulationBasedTraining(
time_attr="training_iteration",
reward_attr="val_acc",
perturbation_interval=3,
custom_explore_fn=explore)
train_spec = {...} # Things like file paths, model func, compute.
ray.tune.run_experiments({"PBA": train_spec}, scheduler=pbt)
We call Tune’s implementation of PBT with our custom exploration function. This
will create 16 copies of our WideResNet model and train them time-multiplexed.
The policy schedule used by each copy is saved to disk and can be retrieved
after termination to use for training new models.
You can run PBA by following the README at: https://github.com/arcelien/pba. On
a Titan XP, it only requires one hour to learn a high performing augmentation
policy schedule on the SVHN dataset. It is also easy to use PBA on a custom
dataset as well: simply define a new dataloader and everything else falls into
place.
Big thanks to Daniel Rothchild, Ashwinee Panda, Aniruddha Nrusimha, Daniel
Seita, Joseph Gonzalez, and Ion Stoica for helpful feedback while writing this
post. Feel free to get in touch with us on Github!
This post is based on the following paper to appear in ICML 2019 as an oral
presentation: