Moving Camera, Moving People: A Deep Learning Approach to Depth Prediction
The human visual system has a remarkable ability to make sense of our 3D world from its 2D projection. Even in complex environments with multiple moving objects, people are able to maintain a feasible interpretation of the objects’ geometry and depth ordering. The field of computer vision has long studied how to achieve similar capabilities by computationally reconstructing a scene’s geometry from 2D image data, but robust reconstruction remains difficult in many cases.
A particularly challenging case occurs when both the camera and the objects in the scene are freely moving. This confuses traditional 3D reconstruction algorithms that are based on triangulation, which assumes that the same object can be observed from at least two different viewpoints, at the same time. Satisfying this assumption requires either a multi-camera array (like Google’s Jump), or a scene that remains stationary as the single camera moves through it. As a result, most existing methods either filter out moving objects (assigning them “zero” depth values), or ignore them (resulting in incorrect depth values).
 |
| Left: The traditional stereo setup assumes that at least two viewpoints capture the scene at the same time. Right: We consider the setup where both camera and subject are moving. |
In “Learning the Depths of Moving People by Watching Frozen People”, we tackle this fundamental challenge by applying a deep learning-based approach that can generate depth maps from an ordinary video, where both the camera and subjects are freely moving. The model avoids direct 3D triangulation by learning priors on human pose and shape from data. While there is a recent surge in using machine learning for depth prediction, this work is the first to tailor a learning-based approach to the case of simultaneous camera and human motion. In this work, we focus specifically on humans because they are an interesting target for augmented reality and 3D video effects.
 |
| Our model predicts the depth map (right; brighter=closer to the camera) from a regular video (left), where both the people in the scene and the camera are freely moving. |
Sourcing the Training Data
We train our depth-prediction model in a supervised manner, which requires videos of natural scenes, captured by moving cameras, along with accurate depth maps. The key question is where to get such data. Generating data synthetically requires realistic modeling and rendering of a wide range of scenes and natural human actions, which is challenging. Further, a model trained on such data may have difficulty generalizing to real scenes. Another approach might be to record real scenes with an RGBD sensor (e.g., Microsoft’s Kinect), but depth sensors are typically limited to indoor environments and have their own set of 3D reconstruction issues.
Instead, we make use of an existing source of data for supervision: YouTube videos in which people imitate mannequins by freezing in a wide variety of natural poses, while a hand-held camera tours the scene. Because the entire scene is stationary (only the camera is moving), triangulation-based methods–like multi-view-stereo (MVS)–work, and we can get accurate depth maps for the entire scene including the people in it. We gathered approximately 2000 such videos, spanning a wide range of realistic scenes with people naturally posing in different group configurations.
 |
| Videos of people imitating mannequins while a camera tours the scene, which we used for training. We use traditional MVS algorithms to estimate depth, which serves as supervision during training of our depth-prediction model. |
Inferring the Depth of Moving People
The Mannequin Challenge videos provide depth supervision for moving camera and “frozen” people, but our goal is to handle videos with a moving camera and moving people. We need to structure the input to the network in order to bridge that gap.
A possible approach is to infer depth separately for each frame of the video (i.e., the input to the model is just a single frame). While such a model already improves over state-of-the-art single image methods for depth prediction, we can improve the results further by considering information from multiple frames. For example, motion parallax, i.e., the relative apparent motion of static objects between two different viewpoints, provides strong depth cues. To benefit from such information, we compute the 2D optical flow between each input frame and another frame in the video, which represents the pixel displacement between the two frames. This flow field depends on both the scene’s depth and the relative position of the camera. However, because the camera positions are known, we can remove their dependency from the flow field, which results in an initial depth map. This initial depth is valid only for static scene regions. To handle moving people at test time, we apply a human-segmentation network to mask out human regions in the initial depth map. The full input to our network then includes: the RGB image, the human mask, and the masked depth map from parallax.
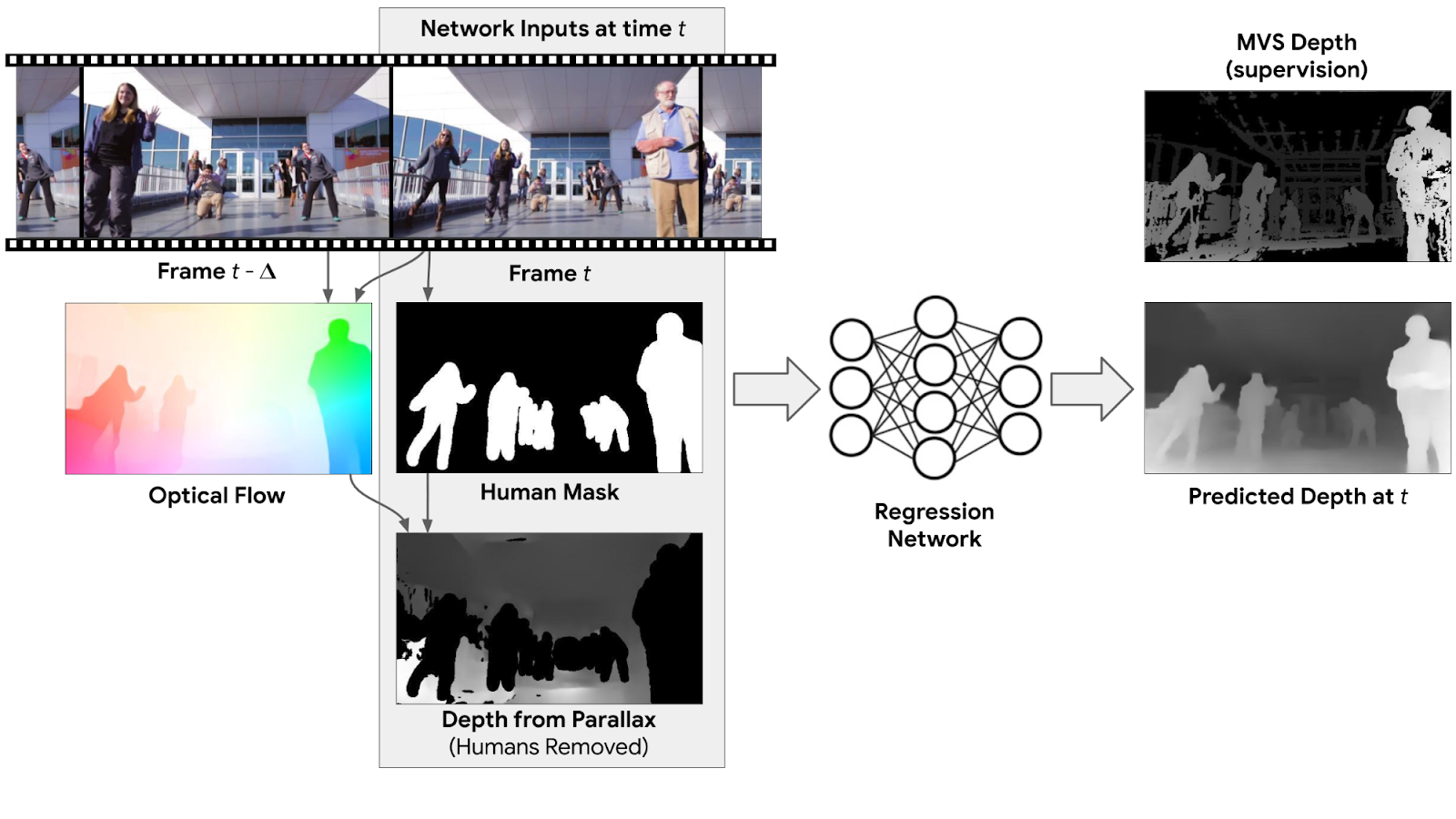 |
| Depth prediction network: The input to the model includes an RGB image (Frame t), a mask of the human region, and an initial depth for the non-human regions, computed from motion parallax (optical flow) between the input frame and another frame in the video. The model outputs a full depth map for Frame t. Supervision for training is provided by the depth map, computed by MVS. |
The network’s job is to “inpaint” the depth values for the regions with people, and refine the depth elsewhere. Intuitively, because humans have consistent shape and physical dimensions, the network can internally learn such priors by observing many training examples. Once trained, our model can handle natural videos with arbitrary camera and human motion.
Below are some examples of our depth-prediction model results based on videos, with comparison to recent state-of-the-art learning based methods.
 |
| Comparison of depth prediction models to a video clip with moving cameras and people. Top: Learning based monocular depth prediction methods (DORN; Chen et al.). Bottom: Learning based stereo method (DeMoN), and our result. |
3D Video Effects Using Our Depth Maps
Our predicted depth maps can be used to produce a range of 3D-aware video effects. One such effect is synthetic defocus. Below is an example, produced from an ordinary video using our depth map.
 |
| Bokeh video effect produced using our estimated depth maps. Video courtesy of Wind Walk Travel Videos. |
Other possible applications for our depth maps include generating a stereo video from a monocular one, and inserting synthetic CG objects into the scene. Depth maps also provide the ability to fill in holes and disoccluded regions with the content exposed in other frames of the video. In the following example, we have synthetically wiggled the camera at several frames and filled in the regions behind the actor with pixels from other frames of the video.

Acknowledgements
The research described in this post was done by Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noah Snavely, Ce Liu and Bill Freeman. We would like to thank Miki Rubinstein for his valuable feedback.
