Sprint Data Science Interview Questions
Sprint had more than 55 million customers at the end of 2013.
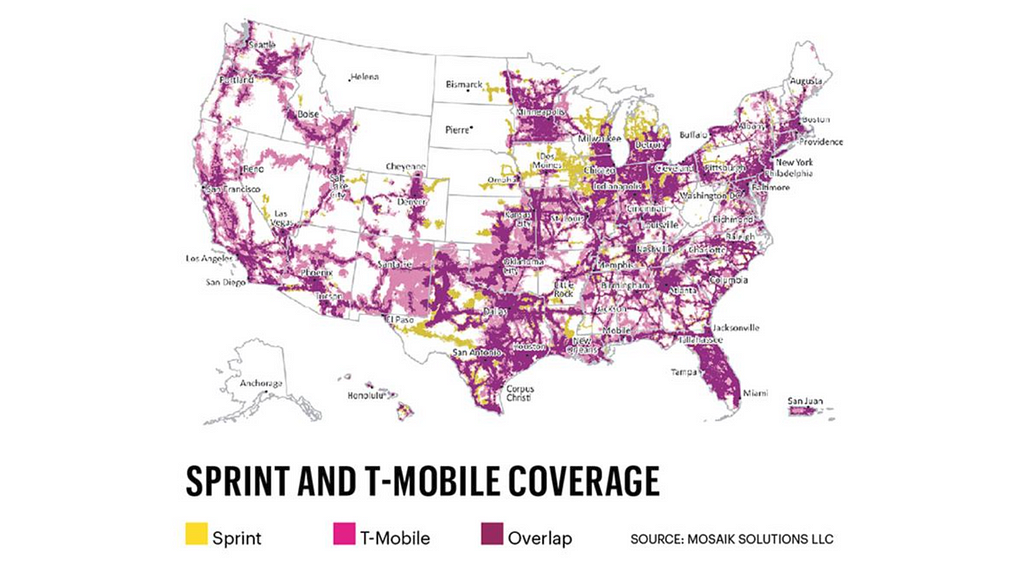
Sprint Corporation headquarters are located in Overland Park, Kansas. The company is widely recognized for developing, engineering and deploying innovative technologies, including the first wireless 4G service from a national carrier in the United States. The American Customer Satisfaction Index rated Sprint as the most improved company in customer satisfaction, across all 47 industries, during the last five years. The merger of T-Mobile and Sprint, the third- and fourth-largest carriers in the U.S happened in 2018. The combined company would have more than 126 million customers. One cannot imagine the amount of data that resides within a telecom company let alone two companies after merging. Sprint established subsidiary Pinsight Media to investigate ways of capitalizing on that data. Since then it has gone from serving zero to six billion ad impressions per month, based on “authenticated first party data” which it alone has access to. This kind of data is a huge advantage for any Data Scientist and provide a tremendous potential to grow their career.
Interview Process
The interview process with an HR interview. The next interview is a take home ML and Coding assessment. The assessment is statistics heavy and requires in depth knowledge about probability distributions and ML Algorithms. The assessment is followed a case study around predictions. The case study provides a problem statement and requires to come up with predictions based on the dataset provided in the case study. The case study is followed by the technical interview and finally a hiring manager interview. The interview process is intense consisting of five rounds but the company is well worth it.
Important Reading
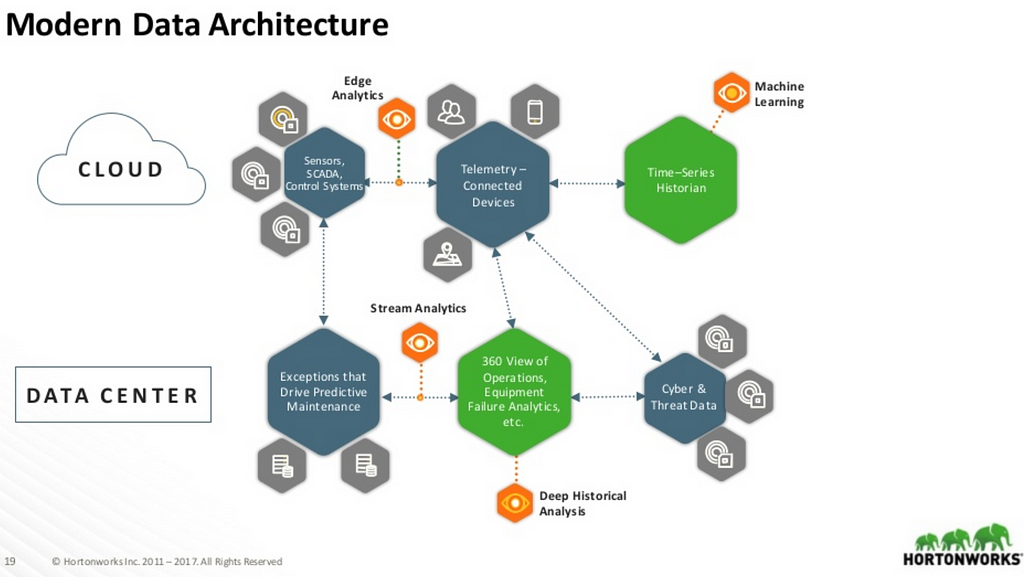
- Sprint Data Modernization Journey: Slideshare
- Sprint Big Data: Hadoop Implementation
- Pinsight Intro: Pinsight Datameer intro
Data Science Related Interview Questions
- Describe Ridge and Lasso Regression.
- Explain SVMs and how they could be used in telecom.
- What are the differences between RDBMS and NoSQL?
- What are the different Data Structures used in Spark?
- Which Data Structure is apt for Geolocation Analysis?
- What is standard deviation? Why do we need it?
- Given n samples from a uniform distribution[0,d]. How do you estimate d?
- In an A/B test, how can you check if assignment to the various buckets was truly random?
- How do you optimize model parameters during model building?
- How does regularization reduce over fitting?
Reflecting on the Questions
The data science team at Sprint which is now merged with T-Mobile has some of the best data sets in the world. Their stack is hadoop and spark based. Their questions reflect the kind of work they do where data insights could be employed for ads. A decent knowledge of how ML can be applied to Telecom can surely land you a job with one of the world’s largest Telecom giant!
Subscribe to our Acing AI newsletter, I promise not to spam and its FREE!
Thanks for reading! 😊 If you enjoyed it, test how many times can you hit 👏 in 5 seconds. It’s great cardio for your fingers AND will help other people see the story.
The sole motivation of this blog article is to learn about Sprint and its technologies helping people to get into it. All data is sourced from online public sources. I aim to make this a living document, so any updates and suggested changes can always be included. Please provide relevant feedback.
Sprint Data Science Interview Questions was originally published in Acing AI on Medium, where people are continuing the conversation by highlighting and responding to this story.