Evaluating the Unsupervised Learning of Disentangled Representations
The ability to understand high-dimensional data, and to distill that knowledge into useful representations in an unsupervised manner, remains a key challenge in deep learning. One approach to solving these challenges is through disentangled representations, models that capture the independent features of a given scene in such a way that if one feature changes, the others remain unaffected. If done successfully, a machine learning system that is designed to navigate the real world, such as a self driving car or a robot, can disentangle the different factors and properties of objects and their surroundings, enabling the generalization of knowledge to previously unobserved situations. While, unsupervised disentanglement methods have already been used for curiosity driven exploration, abstract reasoning, visual concept learning and domain adaptation for reinforcement learning, recent progress in the field makes it difficult to know how well different approaches work and the extent of their limitations.
In “Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations” (to appear at ICML 2019), we perform a large-scale evaluation on recent unsupervised disentanglement methods, challenging some common assumptions in order to suggest several improvements to future work on disentanglement learning. This evaluation is the result of training more than 12,000 models covering most prominent methods and evaluation metrics in a reproducible large-scale experimental study on seven different data sets. Importantly, we have also released both the code used in this study as well as more than 10,000 pretrained disentanglement models. The resulting library, disentanglement_lib, allows researchers to bootstrap their own research in this field and to easily replicate and verify our empirical results.
Understanding Disentanglement
To better understand the ground-truth properties of an image that can be encoded in a disentangled representation, first consider the ground-truth factors of the data set Shapes3D. In this toy model, shown in the figure below, each panel represents one factor that could be encoded into a vector representation of the image. The model shown is defined by the shape of the object in the middle of the image, its size, the rotation of the camera and the color of the floor, the wall and the object.
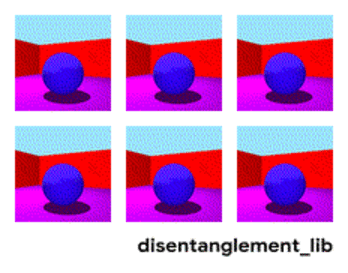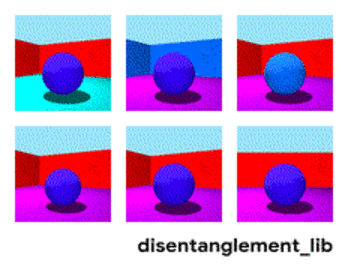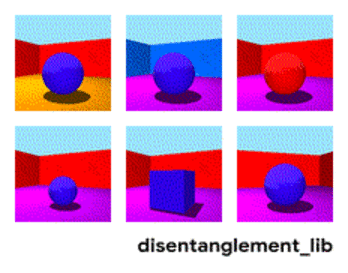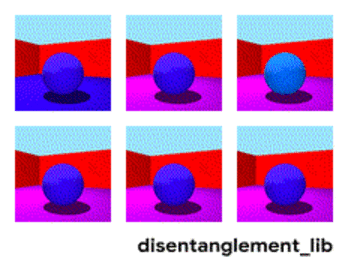 |
| Visualization of the ground-truth factors of the Shapes3D data set: Floor color (upper left), wall color (upper middle), object color (upper right), object size (bottom left), object shape (bottom middle), and camera angle (bottom right). |
The goal of disentangled representations is to build models that can capture these explanatory factors in a vector. The figure below presents a model with a 10-dimensional representation vector. Each of the 10 panels visualizes what information is captured in one of the 10 different coordinates of the representation. From the top right and the top middle panel we see that the model has successfully disentangled floor color, while the two bottom left panels indicate that object color and size are still entangled.
 |
| Visualization of the latent dimensions learned by a FactorVAE model (see below). The ground-truth factors wall and floor color as well as rotation of the camera are disentangled (see top right, top center and bottom center panels), while the ground-truth factors object shape, size and color are entangled (see top left and the two bottom left images). |
Key Results of this Reproducible Large-scale Study
While the research community has proposed a variety of unsupervised approaches to learn disentangled representations based on variational autoencoders and has devised different metrics to quantify their level of disentanglement, to our knowledge no large-scale empirical study has evaluated these approaches in a unified manner. We propose a fair, reproducible experimental protocol to benchmark the state of unsupervised disentanglement learning by implementing six different state-of-the-art models (BetaVAE, AnnealedVAE, FactorVAE, DIP-VAE I/II and Beta-TCVAE) and six disentanglement metrics (BetaVAE score, FactorVAE score, MIG, SAP, Modularity and DCI Disentanglement). In total, we train and evaluate 12,800 such models on seven data sets. Key findings of our study include:
- We do not find any empirical evidence that the considered models can be used to reliably learn disentangled representations in an unsupervised way, since random seeds and hyperparameters seem to matter more than the model choice. In other words, even if one trains a large number of models and some of them are disentangled, these disentangled representations seemingly cannot be identified without access to ground-truth labels. Furthermore, good hyperparameter values do not appear to consistently transfer across the data sets in our study. These results are consistent with the theorem we present in the paper, which states that the unsupervised learning of disentangled representations is impossible without inductive biases on both the data set and the models (i.e., one has to make assumptions about the data set and incorporate those assumptions into the model).
- For the considered models and data sets, we cannot validate the assumption that disentanglement is useful for downstream tasks, e.g., that with disentangled representations it is possible to learn with fewer labeled observations.
The figure below demonstrates some of these findings. The choice of random seed across different runs has a larger impact on disentanglement scores than the model choice and the strength of regularization (while naively one might expect that more regularization should always lead to more disentanglement). A good run with a bad hyperparameter can easily beat a bad run with a good hyperparameter.
 |
| The violin plots show the distribution of FactorVAE scores attained by different models on the Cars3D data set. The left plot shows how the distribution changes as different disentanglement models are considered while the right plot displays the different distributions as the regularization strength in a FactorVAE model is varied. The key observation is that the violin plots substantially overlap which indicates that all methods strongly depend on the random seed. |
Based on these results, we make four observations relevant to future research:
- Given the theoretical result that the unsupervised learning of disentangled representations without inductive biases is impossible, future work should clearly describe the imposed inductive biases and the role of both implicit and explicit supervision.
- Finding good inductive biases for unsupervised model selection that work across multiple data sets persists as a key open problem.
- The concrete practical benefits of enforcing a specific notion of disentanglement of the learned representations should be demonstrated. Promising directions include robotics, abstract reasoning and fairness.
- Experiments should be conducted in a reproducible experimental setup on a diverse selection of data sets.
Open Sourcing disentanglement_lib
In order for others to verify our results, we have released disentanglement_lib, the library we used to create the experimental study. It contains open-source implementations of the considered disentanglement methods and metrics, a standardized training and evaluation protocol, as well as visualization tools to better understand trained models.
The advantages of this library are three-fold. First, with less than four shell commands disentanglement_lib can be used to reproduce any of the models in our study. Second, researchers may easily modify our study to test additional hypotheses. Third, disentanglement_lib is easily extendible and can be used to bootstrap research into the learning of disentangled representations—it is easy to implement new models and compare them to our reference implementation using a fair, reproducible experimental setup.
Reproducing all the models in our study requires a computational effort of approximately 2.5 GPU years, which can be prohibitive. So, we have also released >10,000 pretrained disentanglement_lib models from our study that can be used together with disentanglement_lib.
We hope that this will accelerate research in this field by allowing other researchers to benchmark their new models against our pretrained models and to test new disentanglement metrics and visualization approaches on a diverse set of models.
Acknowledgments
This research was done in collaboration with Francesco Locatello, Mario Lucic, Stefan Bauer, Gunnar Rätsch, Sylvain Gelly and Bernhard Schöpf at Google AI Zürich, ETH Zürich and the Max-Planck Institute for Intelligent Systems. We also wish to thank Josip Djolonga, Ilya Tolstikhin, Michael Tschannen, Sjoerd van Steenkiste, Joan Puigcerver, Marcin Michalski, Marvin Ritter, Irina Higgins and the rest of the Google Brain team for helpful discussions, comments, technical help and code contributions.
