Robots that Learn to Use Improvised Tools
In many animals, tool-use skills emerge from a combination of observational
learning and experimentation. For example, by watching one another, chimpanzees
can learn how to use twigs to “fish” for insects. Similarly, capuchin
monkeys demonstrate the ability to wield sticks as sweeping tools to pull
food closer to themselves. While one might wonder whether these are just
illustrations of “monkey see, monkey do,” we believe these tool-use abilities
indicate a greater level of intelligence.


Left: A chimpanzee fishing for termites. Right: A gorilla using a stick to
gather herbs. (source)
The question our new work explores is: can we enable robots to use tools in the
same way — through observation and experimentation?
A requisite for performing complex multi-object manipulation tasks, such as
those involved in tool use, is an understanding of physical cause-and-effect
relationships. Therefore, the ability to predict how one object might
interact with another is crucial. Our prior work has investigated how
visual predictive models of cause-and-effect can be learned from unsupervised
robot interaction with the world. After learning such a model, the robot can
plan to accomplish a diverse set of simple tasks, including cloth folding and
object arrangement. However, if we consider the more complex interactions that
occur in tool-use tasks, such as how a broom can sweep dirt into a dustpan,
undirected experimentation isn’t enough.
Hence, taking inspiration from how animals learn, we designed an algorithm that
allows robots to learn tool-use skills through a similar paradigm of imitation
and interaction. In particular, we show that, with a mix of demonstration data
and unsupervised experience, a robot can use novel objects as tools and even
improvise tools in the absence of traditional ones. Further, depending on the
demands of the task, our method demonstrates the ability to decide whether to
use the provided tools. In this post, we will describe how this works.






Our approach enables the robot to figure out how to use diverse objects as
tools to achieve user-specified goals (marked by the yellow arrows). The robot
wasn’t told to use the provided tools but determined that it should from the
task.
Guided Visual Foresight
Learning from Demonstrations
First, we will use a dataset of demonstrations that illustrates how various
tools can be used. Because we ultimately hope to learn a model that is useful
for a diverse range of tool-use skills, we collect demonstrations for a variety
of tasks with a variety of tools. For each demonstration, we record the
sequence of images from the robot’s camera, gripper positions, and commanded
actions.




Examples of kinesthetic demonstrations.
With this data, we can fit a model that proposes sequences of actions that
enable the robot to use objects in the current scene as tools. And, to capture
the range of behaviors in the demonstrations, the action proposal model outputs
a distribution over action sequences.
Unsupervised Data Collection for a Visual Predictive Model
Since we want the robot to go beyond the behaviors in the demonstrations, and
to generalize to new objects and new situations, we need a lot of diverse data.
That is, data that can be collected in a scalable way by the robot itself. For
example, we want the robot to understand how small mistakes, such as slightly
imperfect grasping, might affect the future. So, we allow the robot to expand
upon its experiences by collecting data on its own.
In particular, the robot autonomously collects data in two different ways: by
taking random sequences of actions and by sampling from the action proposal
model introduced in the previous section. The latter allows the robot to grasp
at tools and move them randomly. This experience is crucial to learn about
multi-object interactions.








Unsupervised interactions with household objects and tools.
Our final dataset is composed of the expert demonstrations, the robot’s
unsupervised experiences with various tools, and data from the BAIR Robot
Interaction Dataset. We use this dataset to train a dynamics model. Implemented
as a recurrent convolutional neural network, the model takes as input the
previous image and an action at each timestep and generates the next image.
Demonstration-Guided Planning
At test time, the robot can now use the model trained with imitation to guide
the planning process and the predictive model to determine which actions will
allow it to perform the task at hand.
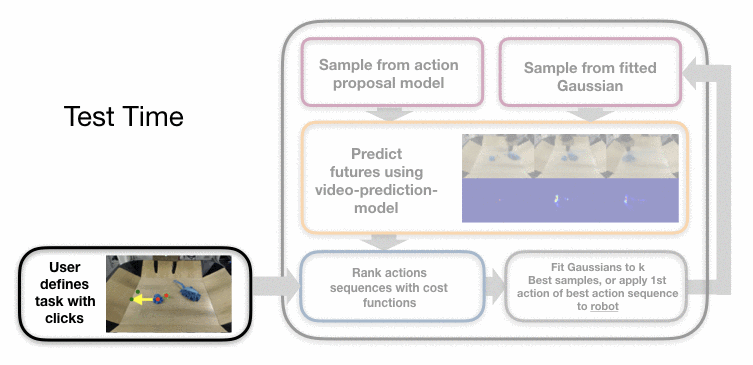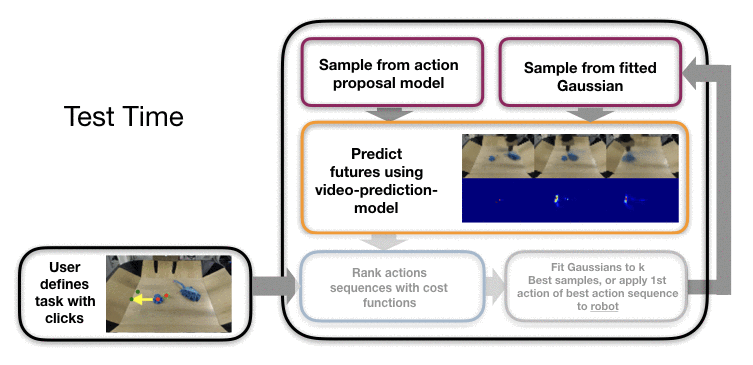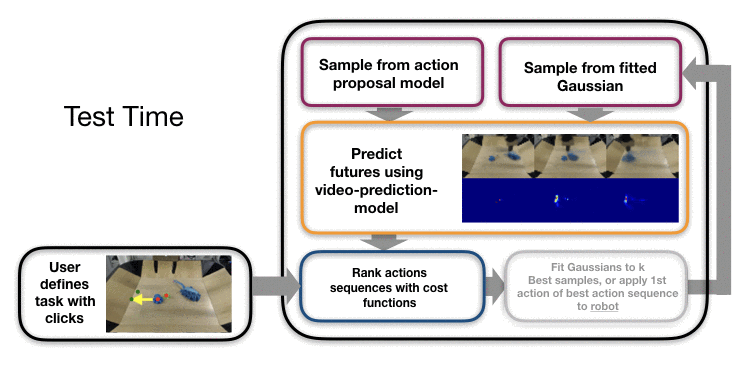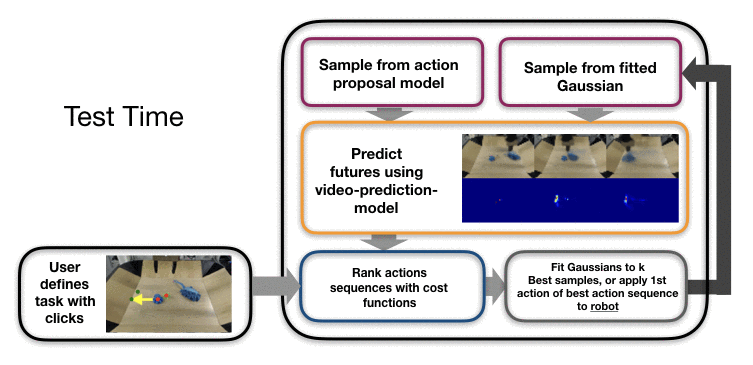
New tasks are specified through user-provided key clicks. For example, we can
ask the robot to move the pile of trash onto the dustpan by selecting the
center points of the rubbish and the desired final positions (see below).
Specifying the task in this way does not tell the robot how to use the tool or
even which tool to use in scenarios with multiple candidates, and the robot has
to figure this out during the planning process.

We use a sampling-based planning procedure that leverages the action proposal
and video prediction models and allows the robot to accomplish a variety of
tasks with a number of different tools and objects. In particular, action
sequences are initially sampled at random and from the action proposal model.
Then, using the video prediction model, we predict the outcome of each plan.









Video predictions corresponding to different action sequences for the same
initial scene.
By taking the top plans and fitting a distribution to them, we can repeatedly
sample and improve upon the best one, which is then executed on the robot.
Experiments
We experiment with this approach to enable robots to use new tools and achieve
user-specified goals.



Left: Initial scene with arrows indicating specified task. Middle: Video
prediction corresponding to the best plan. Right: Execution of the plan on the
robot.
In the task shown earlier, the robot uses the nearby sweeper to perform the
task more efficiently:

Even though the robot has never seen a sponge before, it can figure out how to
use it to clean debris off a plate:
In the following example, the robot is only allowed to move within the shaded
green region and tasked with moving the blue cylinder towards itself.
Critically, the robot figures out how to use the L-shaped hook to accomplish
the task:


And, even when presented with an ordinary object such as a bottle, the robot
can infer how to use it as a tool for the task:


Finally, in situations where it’s better to not use a tool, the robot chooses
to complete the task with its own gripper:


Scenario 1: The robot uses the tool to more efficiently move the two objects.


Scenario 2: The robot ignores the hook and moves the single object with its own
gripper.
Beyond these examples, our quantitative results in the paper suggest that our
approach is more general than learning from demonstrations and more capable
than learning from experience alone.
Related Work on Robotic Tool-Use
Prior works have studied tool manipulation with logic programming and
known models under the task and motion planning framework. However, logic-based
and analytic model-based systems are susceptible to modelling errors, which can
accumulate during test-time execution.
Other works have decomposed tool use into task–oriented grasping
of the tool and using the tool with planning or policy learning.
These methods constrain the scope of motions to those that involve the tool,
while our approach is capable of finding plans with or without the tool based
on the situation.
Some approaches have also proposed learning dynamics models for
tool use. However, in contrast to these methods, which either use
hand-designed perception pipelines or forgo perception entirely, our approach
learns about object interactions directly from raw image pixels.
Conclusion
Performing tasks that are both diverse and complex involving
previously-unseen objects is a challenging undertaking in robotics. To study
this problem, we focused on a variety of tasks that require manipulation of
objects as tools. We demonstrated how our approach, which combines imitation
and self-supervised interaction, can enable robots to accomplish complex
multi-object tasks with a multitude of objects, and even use improvised tools
under new scenarios. We hope that this work represents a step towards making
robots simultaneously more general and more capable, so that they one day
can perform useful tasks in everyday environments.
This post is based on the following paper:
- Improvisation through Physical Understanding: Using Novel Objects as Tools with Visual Foresight
Annie Xie, Frederik Ebert, Sergey Levine, Chelsea Finn
I would like to thank Chelsea Finn and Sergey Levine for their valuable feedback when preparing this blog post.