Learning to Generalize from Sparse and Underspecified Rewards
Reinforcement learning (RL) presents a unified and flexible framework for optimizing goal-oriented behavior, and has enabled remarkable success in addressing challenging tasks such as playing video games, continuous control, and robotic learning. The success of RL algorithms in these application domains often hinges on the availability of high-quality and dense reward feedback. However, broadening the applicability of RL algorithms to environments with sparse and underspecified rewards is an ongoing challenge, requiring a learning agent to generalize (i.e., learn the right behavior) from limited feedback. A natural way to investigate the performance of RL algorithms in such problem settings is via language understanding tasks, where an agent is provided with a natural language input and needs to generate a complex response to achieve a goal specified in the input, while only receiving binary success-failure feedback.
For instance, consider a “blind” agent tasked with reaching a goal position in a maze by following a sequence of natural language commands (e.g., “Right, Up, Up, Right”). Given the input text, the agent (green circle) needs to interpret the commands and take actions based on such interpretation to generate an action sequence (a). The agent receives a reward of 1 if it reaches the goal (red star) and 0 otherwise. Because the agent doesn’t have access to any visual information, the only way for the agent to solve this task and generalize to novel instructions is by correctly interpreting the instructions.
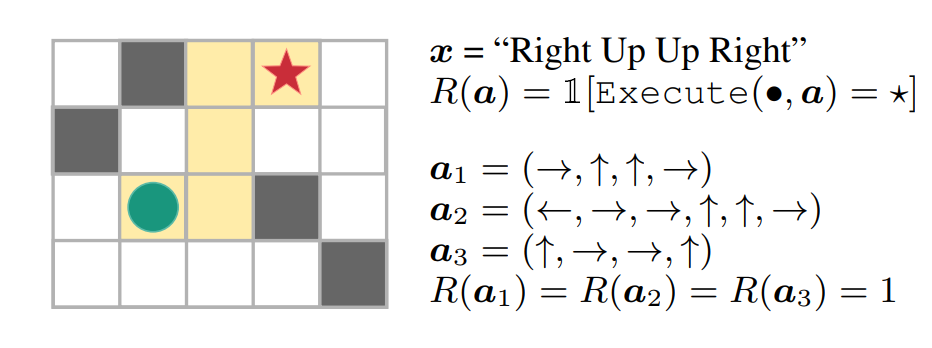 |
| In this instruction-following task, the action trajectories a1, a2 and a3 reach the goal, but the sequences a2 and a3 do not follow the instructions. This illustrates the issue of underspecified rewards. |
In these tasks, the RL agent needs to learn to generalize from sparse (only a few trajectories lead to a non-zero reward) and underspecified (no distinction between purposeful and accidental success) rewards. Importantly, because of underspecified rewards, the agent may receive positive feedback for exploiting spurious patterns in the environment. This can lead to reward hacking, causing unintended and harmful behavior when deployed in real-world systems.
In “Learning to Generalize from Sparse and Underspecified Rewards“, we address the issue of underspecified rewards by developing Meta Reward Learning (MeRL), which provides more refined feedback to the agent by optimizing an auxiliary reward function. MeRL is combined with a memory buffer of successful trajectories collected using a novel exploration strategy to learn from sparse rewards. The effectiveness of our approach is demonstrated on semantic parsing, where the goal is to learn a mapping from natural language to logical forms (e.g., mapping questions to SQL programs). In the paper, we investigate the weakly-supervised problem setting, where the goal is to automatically discover logical programs from question-answer pairs, without any form of program supervision. For instance, given the question “Which nation won the most silver medals?” and a relevant Wikipedia table, an agent needs to generate an SQL-like program that results in the correct answer (i.e., “Nigeria”).

The proposed approach achieves state-of-the-art results on the WikiTableQuestions and WikiSQL benchmarks, improving upon prior work by 1.2% and 2.4% respectively. MeRL automatically learns the auxiliary reward function without using any expert demonstrations, (e.g., ground-truth programs) making it more widely applicable and distinct from previous reward learning approaches. The diagram below depicts a high level overview of our approach:
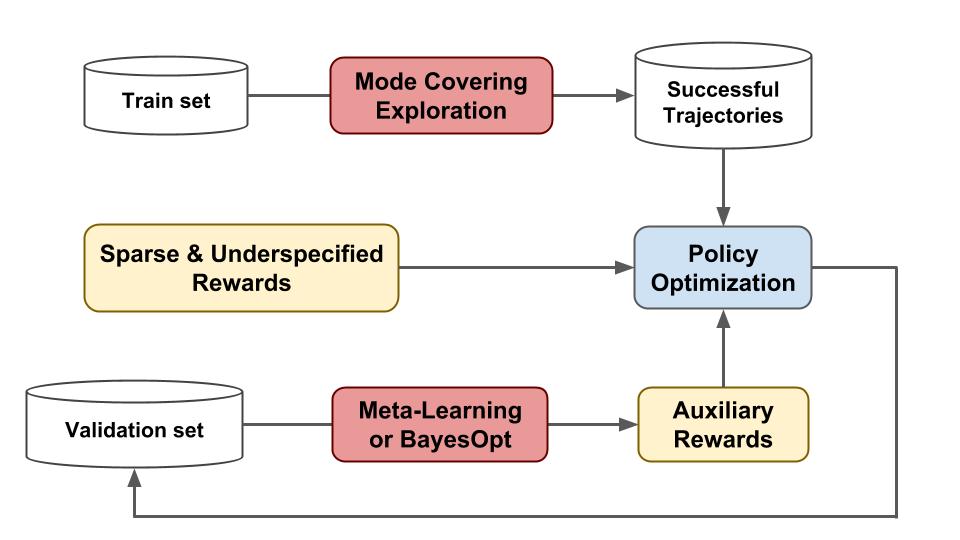 |
| Overview of the proposed approach. We employ (1) mode covering exploration to collect a diverse set of successful trajectories in a memory buffer; (2) Meta-learning or Bayesian optimization to learn an auxiliary reward that provides more refined feedback for policy optimization. |
Meta Reward Learning (MeRL)
The key insight of MeRL in dealing with underspecified rewards is that spurious trajectories and programs that achieve accidental success are detrimental to the agent’s generalization performance. For example, an agent might be able to solve a specific instance of the maze problem above. However, if it learns to perform spurious actions during training, it is likely to fail when provided with unseen instructions. To mitigate this issue, MeRL optimizes a more refined auxiliary reward function, which can differentiate between accidental and purposeful success based on features of action trajectories. The auxiliary reward is optimized by maximizing the trained agent’s performance on a hold-out validation set via meta learning.
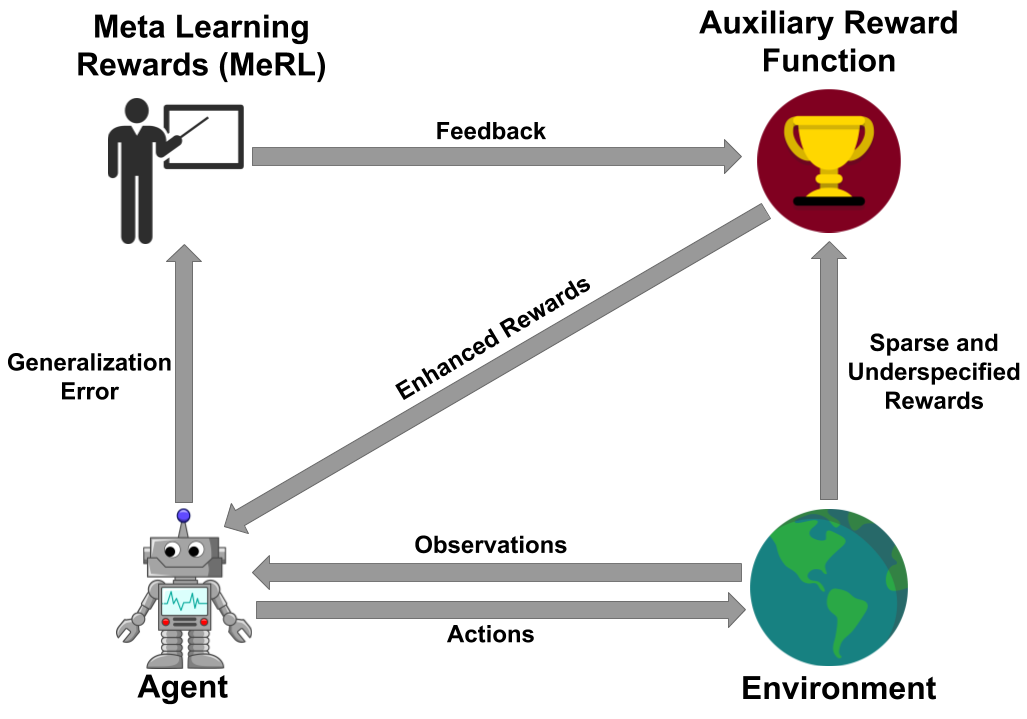 |
| Schematic illustration of MeRL: The RL agent is trained via the reward signal obtained from the auxiliary reward model while the auxiliary rewards are trained using the generalization error of the agent. |
Learning from Sparse Rewards
To learn from sparse rewards, effective exploration is critical to find a set of successful trajectories. Our paper addresses this challenge by utilizing the two directions of Kullback–Leibler (KL) divergence, a measure on how different two probability distributions are. In the example below, we use KL divergence to minimize the difference between a fixed bimodal (shaded purple) and a learned gaussian (shaded green) distribution, which can represent the distribution of the agent’s optimal policy and our learned policy respectively. One direction of the KL objective learns a distribution which tries to cover both the modes while the distribution learned by other objective seeks a particular mode (i.e. it prefers one mode over another). Our method exploits the mode covering KL’s tendency to focus on multiple peaks to collect a diverse set of successful trajectories and mode seeking KL’s implicit preference between trajectories to learn a robust policy.
 |
| Left: Optimizing mode covering KL. Right: Optimizing mode seeking KL |
Conclusion
Designing reward functions that distinguish between optimal and suboptimal behavior is critical for applying RL to real-world applications. This research takes a small step in the direction of modelling reward functions without any human supervision. In future work, we’d like to tackle the credit-assignment problem in RL from the perspective of automatically learning a dense reward function.
Acknowledgements
This research was done in collaboration with Chen Liang and Dale Schuurmans. We thank Chelsea Finn and Kelvin Guu for their review of the paper.
