Amazon SageMaker now comes with new capabilities for accelerating machine learning experimentation
Data scientists and developers can now quickly and easily organize, track, and evaluate their machine learning (ML) model training experiments on Amazon SageMaker. We are introducing a new Amazon SageMaker Search capability that lets you find and evaluate the most relevant model training runs from the hundreds and thousands of your Amazon SageMaker model training jobs. This accelerates the model development and experimentation phase, improves the productivity of data scientists and developers, and reduces overall time to market of machine-learning-based solutions. The new search capability is available in beta through both the AWS Management Console and the AWS SDK APIs for Amazon SageMaker. It’s available in 13 AWS Regions where Amazon SageMaker is currently available, at no additional charge to you.
Developing a machine learning model requires continuous experimentation and observation. For example, when you try a new learning algorithm or tune the model hyperparameters, you need to observe the impact of such incremental changes on model performance and accuracy. This iterative optimization exercise often leads to data explosion, with hundreds of model training experiments and model versions. This can slow down the convergence and discovery of the “winning” model. The information explosion also makes it cumbersome to trace back the antecedents of a model version deployed in a production environment. This difficulty in tracing model lineage hinders model auditing and compliance verifications, debugging a degradation in model’s live prediction performance and setting up new model retraining experiments.
Amazon SageMaker Search lets you quickly identify the most relevant model training runs for addressing your business use case. You can search on all of the defining attributes: the learning algorithm employed, hyperparameter settings, training datasets used, even the tags you have added on the model training jobs. Searching on tags lets you quickly find the model training runs associated with a specific business project, a research lab, or a data science team. This can help you meaningfully categorize and catalog your model training runs. In addition to tracking and organizing the relevant model training runs in a centralized place, you can quickly compare and rank them based on their performance metrics such as training loss and validation accuracy, thus creating leaderboards for picking “winning” models to deploy into production environments. Finally, with Amazon SageMaker search you can quickly trace back the lineage of a model deployed in live environments right to the data set used in training or validating the model. With a single click on the AWS Management Console or through simple one-line API calls, you can now access the specific training run along with all of the ingredients that went into creating the model in first place.
Now let’s dive into a step-by-step experience that shows you how you can efficiently manage your model training experiments using Amazon SageMaker Search. This new feature is available in beta, so use it with caution in production.
Organize, track, and evaluate model training experiments using Amazon SageMaker Search
In this example we’ll train a simple binary classification model on the MNIST data set using the Amazon SageMaker Linear Learner algorithm. The model will predict whether a given image is of the digit 0 or otherwise. We’ll experiment with tuning the hyperparameters of the Linear Learner algorithm, such as mini_batch_size, while optimizing for the binary_classification_accuracy metric that measures the accuracy of predictions made by the model. You can find the sample notebook for this example here.
Step 1: Set up the experiment tracking by choosing a unique label for tagging all of the model training runs
You can add the tag while creating a model training job. Open the AWS Management Console and navigate to the Amazon SageMaker console.
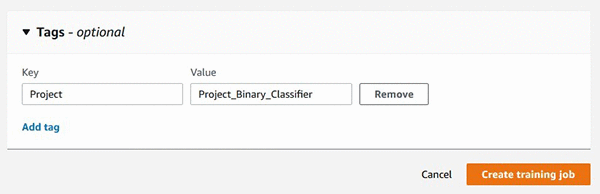
You can also add the tag using the Amazon SageMaker Python SDK API while you are creating a training job using SageMaker estimator.
Step 2: Perform multiple model training runs trying new hyperparameter settings each time
For demonstration purposes, we’ll try three different batch_sizes of 100, 200, and 300. Here is some sample code:
We are consistently tagging all three model training runs with the same unique label so we can group them together under the same project. In the next step we’ll show you how you can use Amazon SageMaker Search to query and organize all of the model training runs labelled with our “Project” tag.
Step 3: Search and organize the relevant experiments at a centralized place for further evaluation
Search is available in beta on the Amazon SageMaker console.
You can search all three model training runs that we performed in Step 2, by searching for the tag.

This lists all of the labelled training runs in a table.
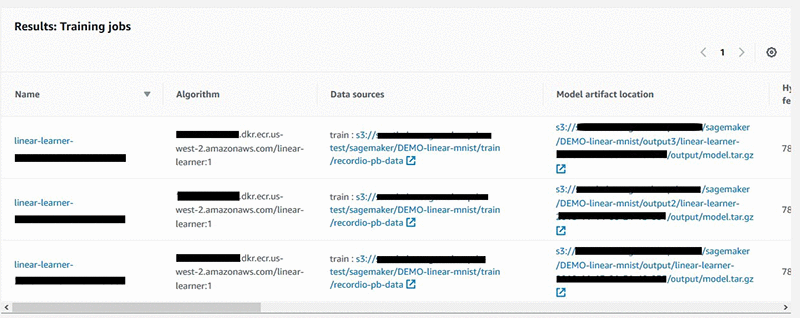
You can also search using the AWS SDK API for Amazon SageMaker Search.
While we have demonstrated searching by tags, the new Amazon SageMaker Search supports searching on any metadata for model training runs, such as the learning algorithm used, training dataset URIs, and ranges of numerical values for hyperparameters and model training metrics.
Step 4: Sort on the objective performance metric of your choice to find the winning model
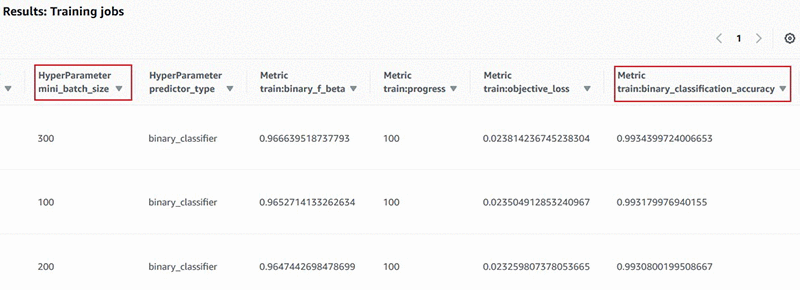
The model training jobs returned by Amazon SageMaker Search in Step 3 are presented to you in a table—like a leaderboard—with all of the hyperparameters and model training metrics presented in sortable columns. Choose the column header to rank the leaderboard for the objective performance metric of your choice, in this case, binary_classification_accuracy.
You can also print the leaderboard inline in your Amazon SageMaker Jupyter notebooks. Here is some sample code:
As you can see in Step 3, we had already given the sort criteria in the search() API call as “SortBy“: “Metrics.train:binary_classification_accuracy” and “SortOrder“: “Descending” for returning the results sorted on metric of our interest. The previous sample code parses the JSON response and presents the results in a leaderboard format, that looks like the following:

Now that you have identified the winning model—with batch_size = 300, and the highest classification accuracy of 0.99344—you can now deploy this model to a live endpoint. The sample notebook has step-by-step instructions for deploying an Amazon SageMaker endpoint.
Tracing a model’s lineage on Amazon SageMaker
Now we’ll show you an example of picking a prediction endpoint and quickly tracing back to the model training run used in creating the model deployed at the endpoint.
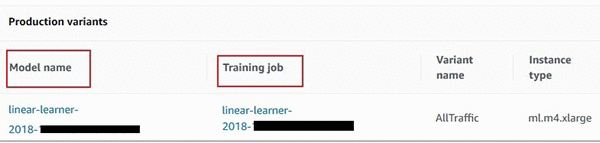
Using single-click on the Amazon SageMaker console
In the left navigation pane of the Amazon SageMaker, choose Endpoints, and select the relevant endpoint from the list of all your deployed endpoints. Scroll to Endpoint Configuration Settings, which lists all the model versions deployed at the endpoint. You will see an additional hyperlink to the Model Training Job that created that model in the first place.
Using the AWS SDK for Amazon SageMaker Search
You can also use few simple one-line API calls to quickly trace the lineage of a model.
Get started with more examples and developer support
Now that you have seen examples of how to efficiently manage the machine learning experimentation process and trace a model’s lineage using the new Amazon SageMaker Search, you can try out our sample notebook. You can also refer to our developer guide for more examples or post your questions on our developer forum. Happy experimenting!
About the Author
 Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.
Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.