Category: Global
Introducing Amazon SageMaker Operators for Kubernetes
AWS is excited to introduce Amazon SageMaker Operators for Kubernetes, a new capability that makes it easier for developers and data scientists using Kubernetes to train, tune, and deploy machine learning (ML) models in Amazon SageMaker. Customers can install these Amazon SageMaker Operators on their Kubernetes cluster to create Amazon SageMaker jobs natively using the Kubernetes API and command-line Kubernetes tools such as ‘kubectl’.
Many AWS customers use Kubernetes, an open-source general-purpose container orchestration system, to deploy and manage containerized applications, often via a managed service such as Amazon Elastic Kubernetes Service (EKS). This enables data scientists and developers, for example, to set up repeatable ML pipelines and maintain greater control over their training and inference workloads. However, to support ML workloads these customers still need to write custom code to optimize the underlying ML infrastructure, ensure high availability and reliability, provide data science productivity tools, and comply with appropriate security and regulatory requirements. For example, when Kubernetes customers use GPUs for training and inference, they often need to change how Kubernetes schedules and scales GPU workloads in order to increase utilization, throughput, and availability. Similarly, for deploying trained models to production for inference, Kubernetes customers have to spend additional time in setting up and optimizing their auto-scaling clusters across multiple Availability Zones.
Amazon SageMaker Operators for Kubernetes bridges this gap, and customers are now spared all the heavy lifting of integrating their Amazon SageMaker and Kubernetes workflows. Starting today, customers using Kubernetes can make a simple call to Amazon SageMaker, a modular and fully-managed service that makes it easier to build, train, and deploy machine learning (ML) models at scale. With workflows in Amazon SageMaker, compute resources are pre-configured and optimized, only provisioned when requested, scaled as needed, and shut down automatically when jobs complete, offering near 100% utilization. Now with Amazon SageMaker Operators for Kubernetes, customers can continue to enjoy the portability and standardization benefits of Kubernetes and EKS, along with integrating the many additional benefits that come out-of-the-box with Amazon SageMaker, no custom code required.
Amazon SageMaker and Kubernetes
Machine learning is more than just the model. The ML workflow consists of sourcing and preparing data, building machine learning models, training and evaluating these models, deploying them to production, and ongoing post-production monitoring. Amazon SageMaker is a modular and fully managed service that helps data scientists and developers more quickly accomplish the tasks to build, train, deploy, and maintain models.
But the workflows related to building a model are often one part of a bigger pipeline that spans multiple engineering teams and services that support an overarching application. Kubernetes users, including Amazon EKS customers, deploy workloads by writing configuration files, which Kubernetes matches with available compute resources in the user’s Kubernetes cluster. While Kubernetes gives customers control and portability, running ML workloads on a Kubernetes cluster brings unique challenges. For example, the underlying infrastructure requires additional management such as optimizing for utilization, cost and performance; complying with appropriate security and regulatory requirements; and ensuring high availability and reliability. All of this undifferentiated heavy lifting takes away valuable time and resources from bringing new ML applications to market. Kubernetes customers want to control orchestration and pipelines without having to manage the underlying ML infrastructure and services in their cluster.
Amazon SageMaker Operators for Kubernetes addresses this need by bringing Amazon SageMaker and Kubernetes together. From Kubernetes, data scientists and developers get to use a fully managed service that is designed and optimized specifically for ML workflows. Infrastructure and platform teams retain control and portability by orchestrating workloads in Kubernetes, without having to manage the underlying ML infrastructure and services. To add new capabilities to Kubernetes, developers can extend the Kubernetes API by creating a custom resource that contains their application-specific or domain-specific logic and components. ‘Operators’ in Kubernetes allow users to natively invoke these custom resources and automate associated workflows. By installing SageMaker Operators for Kubernetes on your Kubernetes cluster, you can now add Amazon SageMaker as a ‘custom resource’ in Kubernetes. You can then use the following Amazon SageMaker Operators:
- Train – Train ML models in Amazon SageMaker, including Managed Spot Training, to save up to 90% in training costs, and distributed training to reduce training time by scaling to multiple GPU nodes. You pay for the duration of your job, offering near 100% utilization.
- Tune – Tune model hyperparameters in Amazon SageMaker, including with Amazon EC2 Spot Instances, to save up to 90% in cost. Amazon SageMaker Automatic Model Tuning performs hyperparameter optimization to search the hyperparameter range for more accurate models, saving you days or weeks of time spent improving model accuracy.
- Inference – Deploy trained models in Amazon SageMaker to fully managed autoscaling clusters, spread across multiple Availability Zones, to deliver high performance and availability for real-time or batch prediction.
Each Amazon SageMaker Operator for Kubernetes provides you with a native Kubernetes experience for creating and interacting with your jobs, either with the Kubernetes API or with Kubernetes command-line utilities such as kubectl. Engineering teams can build automation, tooling, and custom interfaces for data scientists in Kubernetes by using these operators—all without building, maintaining, or optimizing ML infrastructure. Data scientists and developers familiar with Kubernetes can compose and interact with Amazon SageMaker training, tuning, and inference jobs natively, as you would with Kubernetes jobs executing locally. Logs from Amazon SageMaker jobs stream back to Kubernetes, allowing you to natively view logs for your model training, tuning, and prediction jobs in your command line.
Using Amazon SageMaker Operators for Kubernetes with TensorFlow
This post demonstrates training a simple convolutional neural network model on the Modified National Institute of Standards and Technology (MNIST) dataset using the Amazon SageMaker Training Operators for Kubernetes. The MNIST dataset contains images of handwritten digits from 0 to 9 and is a popular ML problem. The MNIST dataset contains 60,000 training images and 10,000 test images.
This post performs the following steps:
- Install Amazon SageMaker Operators for Kubernetes on a Kubernetes cluster
- Create a YAML config for training
- Train the model using the Amazon SageMaker Operator
Prerequisites
For this post, you need an existing Kubernetes cluster in EKS. For information about creating a new cluster in Amazon EKS, see Getting Started with Amazon EKS. You also need the following on the machine you use to control the Kubernetes cluster (for example, your laptop or an EC2 instance):
- Kubectl (Version >=1.13). Use a
kubectlversion that is within one minor version of your Kubernetes cluster’s control plane. For example, a 1.13kubectlclient works with Kubernetes 1.13 and 1.14 clusters. For more information, see Installing kubectl. - AWS CLI (Version >=1.16.232). For more information, see Installing the AWS CLI version 1.
- AWS IAM Authenticator for Kubernetes. For more information, see Installing aws-iam-authenticator.
- Either existing IAM access keys for the operator to use or IAM permissions to create users, attach policies to users, and create access keys.
Setting up IAM roles and permissions
Before you deploy the operator to your Kubernetes cluster, associate an IAM role with an OpenID Connect (OIDC) provider for authentication. See the following code:
Your output should look like the following:
Now that your Kubernetes cluster in EKS has an OIDC identity provider, you can create a role and give it permissions. Obtain the OIDC issuer URL with the following command:
This command will return a URL like the following:
Use the OIDC ID returned by the previous command to create your role. Create a new file named ‘trust.json’ with the following code block. Be sure to update the placeholders with your OIDC ID, AWS Account Number, and EKS Cluster Region.
Now create a new IAM role:
The output will return your ‘ROLE ARN’ that you pass to the operator for securely invoking Amazon SageMaker from the Kubernetes cluster.
Finally, give this new role access to Amazon SageMaker and attach the AmazonSageMakerFullAccess policy.
Setting up the operator on your Kubernetes cluster
Use the Amazon SageMaker Operators from the GitHub repo by downloading a YAML configuration file that installs the operator for you.
In the installer.yaml file, update the eks.amazonaws.com/role-arn with the ARN from your OIDC-based role from the previous step.
Now on your Kubernetes cluster, install the Amazon SageMaker CRD and set up your operators.
Verify that Amazon SageMaker Operators are available in your Kubernetes cluster. See the following code:
With these operators, all of Amazon SageMaker’s managed and secured ML infrastructure and software optimization at scale is now available as a custom resource in your Kubernetes cluster.
To view logs from Amazon SageMaker in our command line using kubetl, we will install the following client:
Preparing your training job
Before you create a YAML config for your Amazon SageMaker training job, create a container that includes your Python training code, which is available in the tensorflow_distributed_mnist GitHub repo. Use TensorFlow GPU images provided by AWS Deep Learning Containers to create your Dockerfile. See the following code:
For this post, you uploaded the MNIST training dataset to an S3 bucket. Create a train.yaml YAML configuration file to start training. Specify TrainingJob as a custom resource to train your model on Amazon SageMaker, which is now a custom resource on your Kubernetes cluster.
Training the model
You can now start your training job by entering the following:
Amazon SageMaker Operator creates a training job in Amazon SageMaker using the specifications you provided in train.yaml. You can interact with this training job as you normally would in Kubernetes. See the following code:
After your training job is complete, any compute instances that were provisioned in Amazon SageMaker for this training job are terminated.
For additional examples, see the GitHub repo.
New Amazon SageMaker capabilities are now generally available
Amazon SageMaker Operators for Kubernetes are generally available as of this writing in US East (Ohio), US East (N. Virginia), US West (Oregon), and EU (Ireland) AWS Regions. For more information and step-by-step tutorials, see our user guide.
As always, please share your experience and feedback, or submit additional example YAML specs or Operator improvements. Let us know how you’re using Amazon SageMaker Operators for Kubernetes by posting on the AWS forum for Amazon SageMaker, creating issues in the GitHub repo, or sending it through your usual AWS contacts.
About the Author
 Aditya Bindal is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to use deep learning engines. In his spare time, he enjoys playing tennis, reading historical fiction, and traveling.
Aditya Bindal is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to use deep learning engines. In his spare time, he enjoys playing tennis, reading historical fiction, and traveling.
AWS DeepRacer Evo is coming soon, enabling developers to race their object avoidance and head-to-head models in exciting new racing formats
Since the launch of AWS DeepRacer, tens of thousands of developers from around the world have been getting hands-on experience with reinforcement learning in the AWS Management Console, by building their AWS DeepRacer models and competing in the AWS DeepRacer League for a chance to be crowned the 2019 AWS DeepRacer League Champion. The League Final takes place this week at re:Invent 2019.
Introducing AWS DeepRacer Evo for head to head racing and more
 We’re excited to announce AWS DeepRacer Evo, a 1/18th scale autonomous car driven by reinforcement learning, now with LIDAR and stereo camera sensors! The new stereo camera and LIDAR (light detection and ranging) sensors enable customers to train even more advanced reinforcement learning models capable of detecting objects and avoiding other cars. Customers will now be able to build models capable of competing in new AWS DeepRacer League race types in 2020, including object avoidance and dual-car head-to-head races, both virtually and in the physical world, in addition to the 2019 time-trial race format.
We’re excited to announce AWS DeepRacer Evo, a 1/18th scale autonomous car driven by reinforcement learning, now with LIDAR and stereo camera sensors! The new stereo camera and LIDAR (light detection and ranging) sensors enable customers to train even more advanced reinforcement learning models capable of detecting objects and avoiding other cars. Customers will now be able to build models capable of competing in new AWS DeepRacer League race types in 2020, including object avoidance and dual-car head-to-head races, both virtually and in the physical world, in addition to the 2019 time-trial race format.
Developers can start building their object avoidance and head-to-head models now by adding stereo cameras and LIDAR sensors to their virtual cars in the new “My Garage” section of the AWS DeepRacer console. These sensors provide a unique perspective of the racetrack. Stereo cameras allow the car to detect the distance to an object and LIDAR helps to determine whether a car is fast approaching from behind. By combining these sensory inputs with advanced algorithms, and updated reward functions, developers can build models that not only detect obstacles (including other cars), but also decide when to overtake, to beat the other car to the finish line.

Add new sensors to AWS DeepRacer Evo in the new garage section of the AWS DeepRacer console.
And it doesn’t stop there. AWS DeepRacer Evo will be available on Amazon.com in 2020 and will come equipped with the same sensors (stereo camera and LIDAR) allowing developers to take the models they have trained in simulation into a real world experience. With AWS DeepRacer Evo, developers will be ready to hit the road immediately with an AWS DeepRacer car capable of mastering each race that the AWS DeepRacer League will bring in 2020. You can sign up to be notified when AWS DeepRacer Evo will be available here. Developers who already own an AWS DeepRacer car can buy an easy-to-install sensor kit from Amazon.com, also available in 2020, to give their car the same capabilities as AWS DeepRacer Evo.
Under the Hood
The new AWS DeepRacer Evo car will be configurable, so when you receive it you choose if you want to start with one camera, two cameras, and LIDAR on or off. These can be easily plugged in or removed from the car’s USB ports, with minimal effort.
The rest remains the same as AWS DeepRacer, including the use of Intel’s OpenVINO toolkit that optimizes the reinforcement learning model built in the simulator, allowing for faster decision making about the next action to take as images of the track are collected by the camera.
| CAR | 18th scale 4WD with monster truck chassis |
| CPU | Intel Atom Processor Processor |
| MEMORY | 4 GB RAM |
| STORAGE | 32 GB (expandable) |
| WI-FI | 802.11ac |
| CAMERA | 2 X 4 MP camera with MJPEG |
| LIDAR | 360 Degree 12 meters scanning radius LIDAR sensor |
| SOFTWARE | Ubuntu OS 16.04.3 LTS, Intel® OpenVINO toolkit, ROS Kinetic |
| DRIVE BATTERY | 7.4V/1100mAh lithium polymer |
| COMPUTE BATTERY | 13600 mAh USB-C PD |
| PORTS | 4x USB-A, 1x USB-C, 1x Micro-USB, 1x HDMI |
| SENSORS | Integrated accelerometer and gyroscope |

Warm up for the 2020 season of the AWS DeepRacer League
In 2020 there will be more ways to compete in the League, with object avoidance and dual-car head-to-head added as new racing formats that take advantage of AWS DeepRacer Evo’s new features. The in-person racing will expand to all of the AWS Summits next year and the Virtual Circuit will add multiple races per month where developers will be able to compete to win in time trial races or take to the tracks head to head against an AWS bot car. The 2020 season of the AWS DeepRacer League promises to add even more fun and excitement as machine learning developers from around the world start their journey and compete to become the next AWS DeepRacer League Champion!
All new features are available in the AWS DeepRacer console now. Log in to learn more and start your machine learning journey today.
About the Author
 Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.
Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.
NVIDIA Clara Federated Learning to Deliver AI to Hospitals While Protecting Patient Data
With over 100 exhibitors at the annual Radiological Society of North America conference using NVIDIA technology to bring AI to radiology, 2019 looks to be a tipping point for AI in healthcare.
Despite AI’s great potential, a key challenge remains: gaining access to the huge volumes of data required to train AI models while protecting patient privacy. Partnering with the industry, we’ve created a solution.
Today at RSNA, we’re introducing NVIDIA Clara Federated Learning, which takes advantage of a distributed, collaborative learning technique that keeps patient data where it belongs — inside the walls of a healthcare provider.
Clara Federated Learning (Clara FL) runs on our recently announced NVIDIA EGX intelligent edge computing platform.
Federated Learning — AI with Privacy
Clara FL is a reference application for distributed, collaborative AI model training that preserves patient privacy. Running on NVIDIA NGC-Ready for Edge servers from global system manufacturers, these distributed client systems can perform deep learning training locally and collaborate to train a more accurate global model.
Here’s how it works: The Clara FL application is packaged into a Helm chart to simplify deployment on Kubernetes infrastructure. The NVIDIA EGX platform securely provisions the federated server and the collaborating clients, delivering everything required to begin a federated learning project, including application containers and the initial AI model.
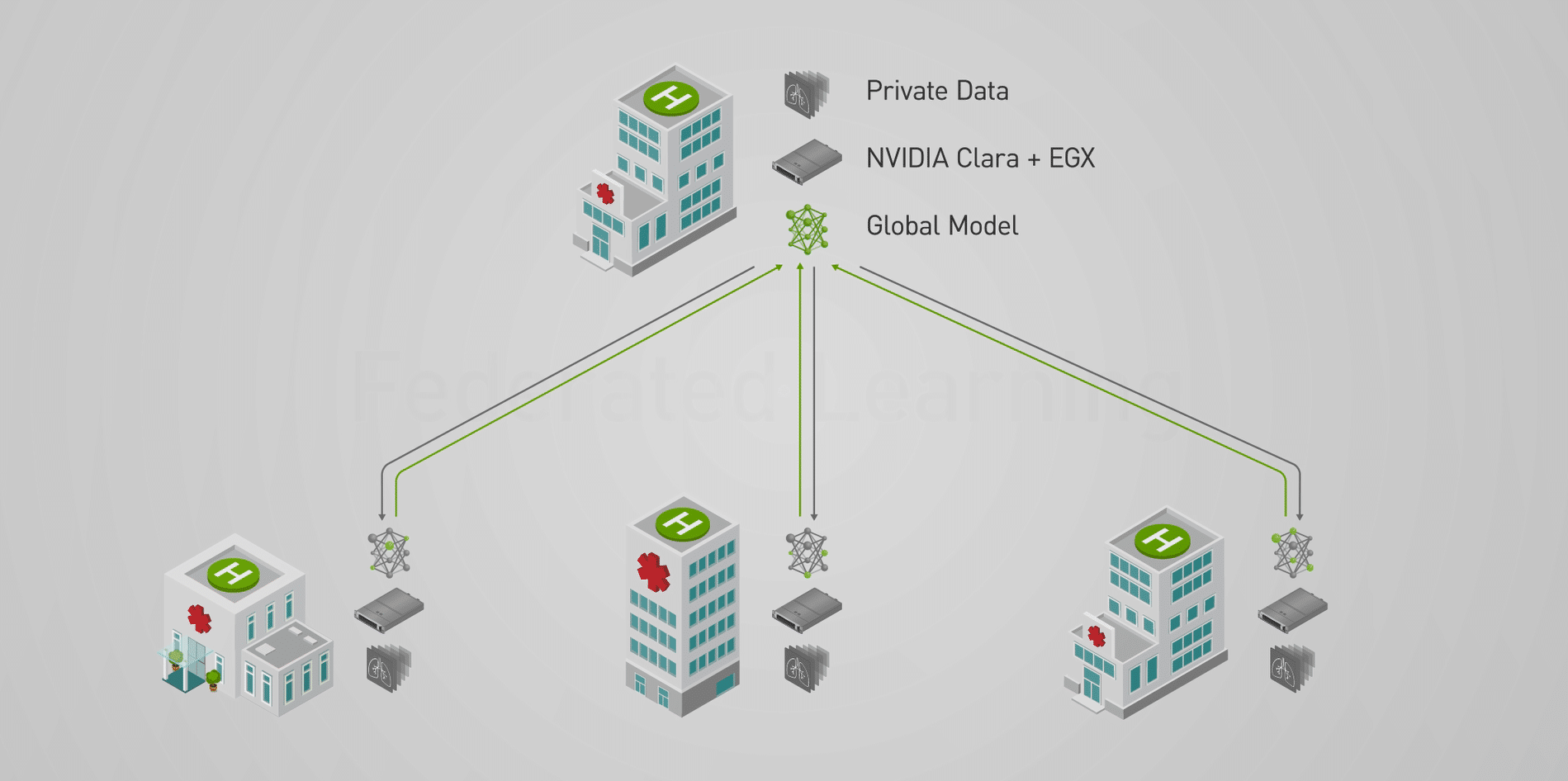
Participating hospitals label their own patient data using the NVIDIA Clara AI-Assisted Annotation SDK integrated into medical viewers like 3D slicer, MITK, Fovia and Philips Intellispace Discovery. Using pre-trained models and transfer learning techniques, NVIDIA AI assists radiologists in labeling, reducing the time for complex 3D studies from hours to minutes.
NVIDIA EGX servers at participating hospitals train the global model on their local data. The local training results are shared back to the federated learning server over a secure link. This approach preserves privacy by only sharing partial model weights and no patient records in order to build a new global model through federated averaging.
The process repeats until the AI model reaches its desired accuracy. This distributed approach delivers exceptional performance in deep learning while keeping patient data secure and private.
US and UK Lead the Way
Healthcare giants around the world — including the American College of Radiology, MGH and BWH Center for Clinical Data Science, and UCLA Health — are pioneering the technology. They aim to develop personalized AI for their doctors, patients and facilities where medical data, applications and devices are on the rise and patient privacy must be preserved.
ACR is piloting NVIDIA Clara FL in its AI-LAB, a national platform for medical imaging. The AI-LAB will allow the ACR’s 38,000 medical imaging members to securely build, share, adapt and validate AI models. Healthcare providers that want access to the AI-LAB can choose a variety of NVIDIA NGC-Ready for Edge systems, including from Dell, Hewlett Packard Enterprise, Lenovo and Supermicro.
UCLA Radiology is also using NVIDIA Clara FL to bring the power of AI to its radiology department. As a top academic medical center, UCLA can validate the effectiveness of Clara FL and extend it in the future across the broader University of California system.
Partners HealthCare in New England also announced a new initiative using NVIDIA Clara FL. Massachusetts General Hospital and Brigham and Women’s Hospital’s Center for Clinical Data Science will spearhead the work, leveraging data assets and clinical expertise of the Partners HealthCare system.
In the U.K., NVIDIA is partnering with King’s College London and Owkin to create a federated learning platform for the National Health Service. The Owkin Connect platform running on NVIDIA Clara enables algorithms to travel from one hospital to another, training on local datasets. It provides each hospital a blockchain-distributed ledger that captures and traces all data used for model training.
The project is initially connecting four of London’s premier teaching hospitals, offering AI services to accelerate work in areas such as cancer, heart failure and neurodegenerative disease, and will expand to at least 12 U.K. hospitals in 2020.
Making Everything Smart in the Hospital
With the rapid proliferation of sensors, medical centers like Stanford Hospital are working to make every system smart. To make sensors intelligent, devices need a powerful, low-power AI computer.
That’s why we’re announcing NVIDIA Clara AGX, an embedded AI developer kit that can handle image and video processing at high data rates, bringing AI inference and 3D visualization to the point of care.

Clara AGX is powered by NVIDIA Xavier SoCs, the same processors that control self-driving cars. They consume as little as 10W, making them suitable for embedding inside a medical instrument or running in a small adjacent system.
A perfect showcase of Clara AGX is Hyperfine, the world’s first portable point-of-care MRI system. The revolutionary Hyperfine system will be on display in NVIDIA’s booth at this week’s RSNA event.
Hyperfine’s system is among the first of many medical instruments, surgical suites, patient monitoring devices and smart medical cameras expected to use Clara AGX. We’re witnessing the beginning of an AI-enabled internet of medical things.

The NVIDIA Clara AGX SDK will be available soon through our early access program. It includes reference applications for two popular uses — real-time ultrasound and endoscopy edge computing.
NVIDIA at RSNA 2019
Visit NVIDIA and our many healthcare partners in booth 10939 in the RSNA AI Showcase. We’ll be showing our latest AI-driven medical imaging advancements, including keeping patient data secure with AI at the edge.
Find out from our deep learning experts how to use AI to advance your research and accelerate your clinical workflows. See the full lineup of talks and learn more on our website.
The post NVIDIA Clara Federated Learning to Deliver AI to Hospitals While Protecting Patient Data appeared first on The Official NVIDIA Blog.
Amazon Forecast now supports the generation of forecasts at a quantile of your choice
We are happy to announce that Amazon Forecast can now generate forecasts at a quantile of your choice.
Launched at re:Invent 2018, and generally available since Aug 2019, Forecast is a fully managed service that uses machine learning (ML) to generate highly accurate forecasts, without requiring any prior ML experience. Forecast is applicable in a wide variety of use cases, including estimating product demand, supply chain optimization, energy demand forecasting, financial planning, workforce planning, computing cloud infrastructure usage, and traffic demand forecasting.
Based on the same technology used at Amazon.com, Forecast is a fully managed service, so there are no servers to provision. Additionally, you only pay for what you use, and there are no minimum fees or upfront commitments. To use Forecast, you only need to provide historical data for what you want to forecast, and optionally any additional data that you believe may impact your forecasts. The latter may include both time-varying data such as price, events, and weather, and categorical data such as color, genre, or region. The service automatically trains and deploys ML models based on your data, and provides you a custom API from which to download forecasts.
Unlike most other forecasting solutions that generate point forecasts (p50), Forecast generates probabilistic forecasts at three default quantiles: 10% (p10), 50% (p50), and 90% (p90). You can choose the forecast that suits your business needs depending on the trade-off between the cost of capital (over-forecasting) or missing customer demand (under-forecasting) in your business. For the p10 forecast, the true value is expected to be lower than the predicted value 10% of the time. If the cost of invested capital is high (for example, being overstocked with product), the p10 quantile forecast is useful to order relatively fewer items. Similarly, with the p90 forecast, the true value is expected to be lower than the predicted value 90% of the time. If missing customer demand would result in either a significant amount of lost revenue or a poor customer experience, the p90 forecast is more useful. For more information, see Evaluating Predictor Accuracy.
While the three existing quantiles supported by Forecast are useful, they can also be limiting for two reasons. Firstly, the fixed quantiles may not always meet specific use case requirements. For example, if meeting customer demand is imperative at all costs, a p99 forecast may be more useful than p90.
Secondly, because Forecast always generates forecasts at three different quantiles by default, you are billed for three quantiles, even if only one quantile is relevant for your decision making processes. Forecast now allows you to override the default quantiles, and choose up to five quantiles of your choice (any quantile between 1% and 99%, including mean). You can achieve this by passing an optional parameter in the CreateForecast API or specifying the override quantiles directly in the AWS Management Console. You can continue to query your forecasts via the console or the QueryForecast API.
This post looks at how to use this new feature via the console. You can also access this feature via the CreateForecast API.
To demonstrate this functionality, we use the same example from the earlier blog post Amazon Forecast – Now Generally Available. The example uses the individual household electric power consumption dataset from the UCI Machine Learning Repository. For more information about creating a predictor in Forecast, see the preceding post.
Once the predictor is active, go to the console to generate forecasts or use the CreateForecast API. On the Create a forecast page, there is a new optional parameter called Forecast types, where you can override the default quantiles of .10, .50, and .90.
For this post, we add the custom quantiles of .10, .35, mean, .75, and .99.

Accepted values include any value between .01 to .99 (in increments of .01), including the mean. The mean forecast is different from the median (.50) when the distribution is not symmetric (for example, Beta and Negative Binomial). In this case, because you specified five quantiles, you are billed for all five. For example, if you generated forecasts for 5,000 time series, you are billed for 25,000 unique forecasts. Because the service bills in units of 1,000, this results in a total bill of 25 x $0.60 = $15. For more information on the latest pricing plan, see Amazon Forecast Pricing.
When the forecast is active, you can query and visualize the forecast using the Forecast lookup tool from the console.
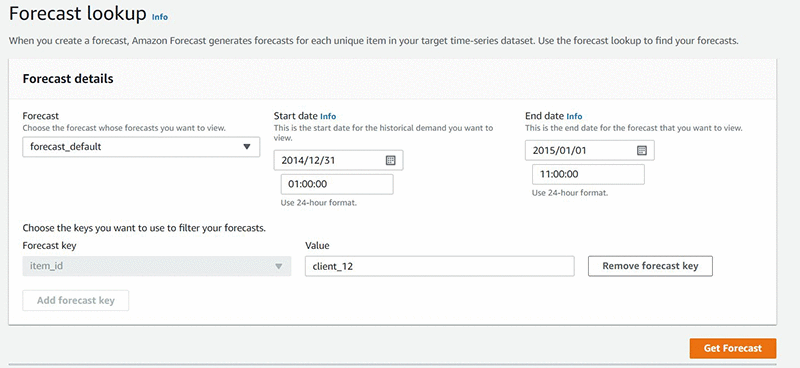
The following graph shows the historical demand and forecasts for a specific time series, in this case “client_12”. All the quantiles specified during CreateForecast (in this case, .10, .35, mean, .75, and .99) are displayed here.
In addition to querying a forecast in the console, you can also export forecasts as a .csv file in an Amazon S3 bucket of your choice. The exported .csv file contains the forecasts for all your time series and the quantiles selected. In our specific example, this is the energy demand forecasts for each client, for the five quantiles chosen. To export your forecast, you can use the CreateForecastExportJob API or via the “Create forecast export” button in the console, as displayed in the screenshot below.
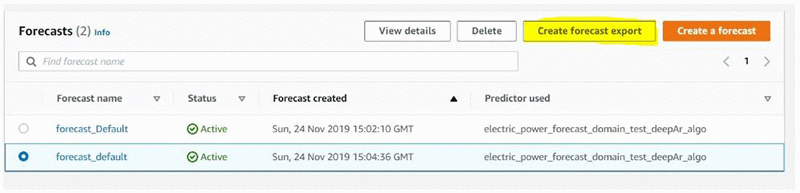
Once you click ‘Create forecast export’, you are taken to the detail page below. Here you specify the name for your export job, specify the forecast, IAM role and the S3 bucket where you want the file to be stored.

When the export job is complete, you can navigate to S3 (via the console) and verify that the file has been created in the relevant S3 bucket.
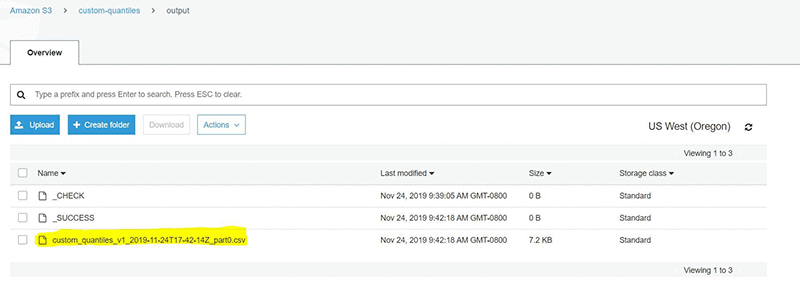
The following table shows the content of the csv, corresponding to the generated forecasts for each client for all quantiles specified over the entire forecast horizon.
|
item_id |
date | p10 | p35 | mean | p75 |
p99 |
| client_111 | 2015-01-01T01:00:00Z | 48.89389038 | 69.03968811 | 75.33065033 | 88.43639374 | 174.2510834 |
| client_111 | 2015-01-01T02:00:00Z | 49.26203156 | 67.66025543 | 72.34096527 | 85.50863647 | 148.0922241 |
| client_111 | 2015-01-01T03:00:00Z | 46.06879807 | 67.83860016 | 76.61499786 | 83.54689789 | 225.3299561 |
| client_111 | 2015-01-01T04:00:00Z | 45.66434097 | 65.45301056 | 73.38169098 | 88.51142883 | 138.77005 |
| client_111 | 2015-01-01T05:00:00Z | 43.5483017 | 66.55085754 | 70.6720047 | 88.17260742 | 144.4982605 |
| client_111 | 2015-01-01T06:00:00Z | 50.08174133 | 67.60101318 | 75.05982971 | 83.4147644 | 206.5582886 |
| client_111 | 2015-01-01T07:00:00Z | 50.79389954 | 66.47422791 | 78.7857666 | 90.23943329 | 222.6696167 |
| client_111 | 2015-01-01T08:00:00Z | 58.11802673 | 67.99427795 | 76.23995209 | 88.22603607 | 185.4029236 |
| client_111 | 2015-01-01T09:00:00Z | 42.96152878 | 74.78701019 | 80.14347839 | 96.66455841 | 142.397644 |
| client_111 | 2015-01-01T10:00:00Z | 59.34168243 | 72.34555054 | 80.24354553 | 94.45916748 | 164.3058929 |
| client_111 | 2015-01-01T11:00:00Z | 53.01160049 | 72.67097473 | 79.31721497 | 90.48171234 | 208.0553894 |
| client_111 | 2015-01-01T12:00:00Z | 47.87768173 | 69.18990326 | 77.85028076 | 89.63658905 | 143.6833801 |
| client_111 | 2015-01-01T13:00:00Z | 46.98330688 | 71.60288239 | 86.48907471 | 87.89906311 | 1185.726318 |
Summary
You can now use Forecast to generate probabilistic forecasts at any quantile of your choice. This allows you to build forecasts that are specific to your use case, and reduce your bills by choosing and paying for precisely the quantiles you need. You can start using this feature today in all Regions in which Forecast is available. Please share feedback either via the AWS forum or your regular AWS Support channels.
About the author
 Rohit Menon is a senior product manager for Amazon Forecast at AWS.
Rohit Menon is a senior product manager for Amazon Forecast at AWS.
 Ammar Chinoy is a senior software development manager for Amazon Forecast at AWS.
Ammar Chinoy is a senior software development manager for Amazon Forecast at AWS.
Save on inference costs by using Amazon SageMaker multi-model endpoints
Businesses are increasingly developing per-user machine learning (ML) models instead of cohort or segment-based models. They train anywhere from hundreds to hundreds of thousands of custom models based on individual user data. For example, a music streaming service trains custom models based on each listener’s music history to personalize music recommendations. A taxi service trains custom models based on each city’s traffic patterns to predict rider wait times.
While the benefit of building custom ML models for each use case is higher inference accuracy, the downside is that the cost of deploying models increases significantly, and it becomes difficult to manage so many models in production. These challenges become more pronounced when you don’t access all models at the same time but still need them to be available at all times. Amazon SageMaker multi-model endpoints addresses these pain points and gives businesses a scalable yet cost-effective solution to deploy multiple ML models.
Amazon SageMaker is a modular, end-to-end service that makes it easier to build, train, and deploy ML models at scale. After you train an ML model, you can deploy it on Amazon SageMaker endpoints that are fully managed and can serve inferences in real time with low latency. You can now deploy multiple models on a single endpoint and serve them using a single serving container using multi-model endpoints. This makes it easy to manage ML deployments at scale and lowers your model deployment costs through increased usage of the endpoint and its underlying compute instances.
This post introduces Amazon SageMaker multi-model endpoints and shows how to apply this new capability to predict housing prices for individual market segments using XGBoost. The post demonstrates running 10 models on a multi-model endpoint versus using 10 separate endpoints. This results in savings of $3,000 per month, as shown in the following figure:

Multi-model endpoints can easily scale to hundreds or thousands of models. The post also discusses considerations for endpoint configuration and monitoring, and highlights cost savings of over 90% for a 1,000-model example.
Overview of Amazon SageMaker multi-model endpoints
Amazon SageMaker enables you to one-click deploy your model onto autoscaling Amazon ML instances across multiple Availability Zones for high redundancy. Specify the type of instance and the maximum and minimum number desired, and Amazon SageMaker takes care of the rest. It launches the instances, deploys your model, and sets up a secure HTTPS endpoint. Your application needs to include an API call to this endpoint to achieve low latency and high throughput inference. This architecture allows you to integrate new models into your application in minutes because model changes no longer require application code changes. Amazon SageMaker is fully managed and manages your production compute infrastructure on your behalf to perform health checks, apply security patches, and conduct other routine maintenance, all with built-in Amazon CloudWatch monitoring and logging.
Amazon SageMaker multi-model endpoints enable you to deploy multiple trained models to an endpoint and serve them using a single serving container. Multi-model endpoints are fully managed and highly available to serve traffic in real time. You can easily access a specific model by specifying the target model name when you invoke the endpoint. This feature is ideal when you have a large number of similar models that you can serve through a shared serving container and don’t need to access all the models at the same time. For example, a legal application may need complete coverage of a broad set of regulatory jurisdictions, but that may include a long tail of models that are rarely used. One multi-model endpoint can serve these lightly used models to optimize cost and manage the large number of models efficiently.
To create a multi-model endpoint in Amazon SageMaker, choose the multi-model option, provide the inference serving container image path, and provide the Amazon S3 prefix in which the trained model artifacts are stored. You can define any hierarchy of your models in S3. When you invoke the multi-model endpoint, you provide the relative path of a specific model in the new TargetModel header. To add models to the multi-model endpoint, add a new trained model artifact to S3 and invoke it. To update a model already in use, add the model to S3 with a new name and begin invoking the endpoint with the new model name. To stop using a model deployed on a multi-model endpoint, stop invoking the model and delete it from S3.
Instead of downloading all the models into the container from S3 when the endpoint is created, Amazon SageMaker multi-model endpoints dynamically load models from S3 when invoked. As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. If the model is already loaded on the container and invoked, then you skip the download step and the model returns the inferences in low latency. For example, assume you have a model that is only used a few times a day. It is automatically loaded on demand, while frequently accessed models are retained in memory with the lowest latency. The following diagram shows models dynamically loaded from S3 into a multi-model endpoint.

Using Amazon SageMaker multi-model endpoints to predict housing prices
This post takes you through an example use case of multi-model endpoints, based on the domain of house pricing. For more information, see the fully working notebook on GitHub. It uses generated synthetic data to let you experiment with an arbitrary number of models. Each city has a model trained on a number of houses with randomly generated characteristics.
The walkthrough includes the following steps:
- Making your trained models available for a multi-model endpoint
- Preparing your container
- Creating and deploying a multi-model endpoint
- Invoking a multi-model endpoint
- Dynamically loading a new model
Making your trained models available for a multi-model endpoint
You can take advantage of multi-model deployment without any changes to your models or model training process and continue to produce model artifacts (for example, model.tar.gz files) that get saved in S3.
In the example notebook, a set of models is trained in parallel, and the model artifacts from each training job are copied to a specific location in S3. After training and copying a set of models, the folder has the following contents:
Each file is renamed from its original model.tar.gz name so that each model has a unique name. You refer to the target model by name when invoking a request for a prediction.
Preparing your container
To use Amazon SageMaker multi-model endpoints, you can build a docker container using the general-purpose multi-model server capability on GitHub. It is a flexible and easy-to-use framework for serving ML models with any framework. The XGBoost sample notebook demonstrates how to build a container using the open-source Amazon SageMaker XGBoost container as a base.
Creating a multi-model endpoint
The next step is to create a multi-model endpoint that knows where in S3 to find target models. This post uses boto3, the AWS SDK for Python, to create the model metadata. Instead of describing a specific model, set its mode to MultiModel and tell Amazon SageMaker the location of the S3 folder containing all the model artifacts.
Additionally, indicate the framework image that models use for inference. This post uses an XGBoost container that was built in the previous step. You can host models built with the same framework in a multi-model endpoint configured for that framework. See the following code for creating the model entity:
With the model definition in place, you need an endpoint configuration that refers back to the name of the model entity you created. See the following code:
Lastly, create the endpoint itself with the following code:
Invoking a multi-model endpoint
To invoke a multi-model endpoint, you only need to pass one new parameter, which indicates the target model to invoke. The following example code is a prediction request using boto3:
The sample notebook iterates through a set of random invocations against multiple target models hosted behind a single endpoint. This shows how the endpoint dynamically loads target models as needed. See the following output:
The time to complete the first request against a given model experiences additional latency (called a cold start) to download the model from S3 and load it into memory. Subsequent calls finish with no additional overhead because the model is already loaded.
Dynamically adding a new model to an existing endpoint
It’s easy to deploy a new model to an existing multi-model endpoint. With the endpoint already running, copy a new set of model artifacts to the same S3 location you set up earlier. Client applications are then free to request predictions from that target model, and Amazon SageMaker handles the rest. The following example code makes a new model for New York that is ready to use immediately:
With multi-model endpoints, you don’t need to bring down the endpoint when adding a new model, and you avoid the cost of a separate endpoint for this new model. An S3 copy gives you access.
Scaling multi-model endpoints for large numbers of models
The benefits of Amazon SageMaker multi-model endpoints increase based on the scale of model consolidation. You can see cost savings when hosting two models with one endpoint, and for use cases with hundreds or thousands of models, the savings are much greater.
For example, consider 1,000 small XGBoost models. Each of the models on its own could be served by an ml.c5.large endpoint (4 GiB memory), costing $0.119 per instance hour in us-east-1. To provide all one thousand models using their own endpoint would cost $171,360 per month. With an Amazon SageMaker multi-model endpoint, a single endpoint using ml.r5.2xlarge instances (64 GiB memory) can host all 1,000 models. This reduces production inference costs by 99% to only $1,017 per month. The following table summarizes the differences between single and multi-model endpoints. Note that 90th percentile latency remains at 7 milliseconds in this example.
| Single model endpoint |
Multi-model endpoint |
|
| Total endpoint price per month | $171,360 | $1,017 |
| Endpoint instance type | ml.c5.large | ml.r5.2xlarge |
| Memory capacity (GiB) | 4 | 64 |
| Endpoint price per hour | $0.119 | $0.706 |
| Number of instances per endpoint | 2 | 2 |
| Endpoints needed for 1,000 models | 1,000 | 1 |
| Endpoint p90 latency (ms) | 7 | 7 |
Monitoring multi-model endpoints using Amazon CloudWatch metrics
To make price and performance tradeoffs, you will want to test multi-model endpoints. Amazon SageMaker provides additional metrics in CloudWatch for multi-model endpoints so you can determine the endpoint usage and the cache hit rate and optimize your endpoint. The metrics are as follows:
- ModelLoadingWaitTime – The interval of time that an invocation request waits for the target model to be downloaded or loaded to perform the inference.
- ModelUnloadingTime – The interval of time that it takes to unload the model through the container’s
UnloadModelAPI call. - ModelDownloadingTime – The interval of time that it takes to download the model from S3.
- ModelLoadingTime – The interval of time that it takes to load the model through the container’s
LoadModelAPI call. - ModelCacheHit – The number of
InvokeEndpointrequests sent to the endpoint where the model was already loaded. Taking the Average statistic shows the ratio of requests in which the model was already loaded. - LoadedModelCount – The number of models loaded in the containers in the endpoint. This metric is emitted per instance. The
Averagestatistic with a period of 1 minute tells you the average number of models loaded per instance, and theSumstatistic tells you the total number of models loaded across all instances in the endpoint. The models that this metric tracks are not necessarily unique because you can load a model in multiple containers in the endpoint.
You can use CloudWatch charts to help make ongoing decisions on the optimal choice of instance type, instance count, and number of models that a given endpoint should host. For example, the following chart shows the increasing number of models loaded and a corresponding increase to the cache hit rate.
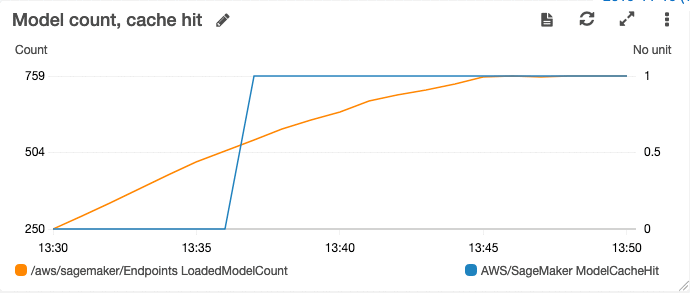
In this case, the cache hit rate started at 0 when no models had been loaded. As the number of models loaded increases, the cache hit rate eventually hits 100%.
Matching your endpoint configuration to your use case
Choosing the right endpoint configuration for an Amazon SageMaker endpoint, particularly the instance type and number of instances, depends heavily on the requirements of your specific use case. This is also true for multi-model endpoints. The number of models that you can hold in memory depends on the configuration of your endpoint (such as instance type and count), the profile of your models (such as model size and model latency), and the traffic patterns. You should configure your multi-model endpoint and right-size your instances by considering all these factors and also set up automatic scaling for your endpoint.
Amazon SageMaker multi-model endpoints fully support automatic scaling. The invocation rates used to trigger an autoscale event are based on the aggregate set of predictions across the full set of models an endpoint serves.
In some cases, you may opt to reduce costs by choosing an instance type that cannot hold all the targeted models in memory at the same time. Amazon SageMaker unloads models dynamically when it runs out of memory to make room for a newly-targeted model. For infrequently requested models, the dynamic load latency can still meet the requirements. In cases with more stringent latency needs, you may opt for larger instance types or more instances. Investing time up front to do proper performance testing and analysis pays excellent dividends in successful production deployments.
Conclusion
Amazon SageMaker multi-model endpoints help you deliver high-performance machine learning solutions at the lowest possible cost. You can significantly lower your inference costs by bundling sets of similar models behind a single endpoint that you can serve using a single shared serving container. Similarly, Amazon SageMaker gives you managed spot training to help with training costs, and integrated support for Amazon Elastic Inference for deep learning workloads. You can boost the bottom-line impact of your ML teams by adding these to the significant productivity improvements Amazon SageMaker delivers.
Give multi-model endpoints a try, and share your feedback and questions in the comments.
About the authors
 Mark Roy is a Machine Learning Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Mark loves to play, coach, and follow basketball.
Mark Roy is a Machine Learning Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Mark loves to play, coach, and follow basketball.
 Urvashi Chowdhary is a Principal Product Manager for Amazon SageMaker. She is passionate about working with customers and making machine learning more accessible. In her spare time, she loves sailing, paddle boarding, and kayaking.
Urvashi Chowdhary is a Principal Product Manager for Amazon SageMaker. She is passionate about working with customers and making machine learning more accessible. In her spare time, she loves sailing, paddle boarding, and kayaking.
Automating financial decision making with deep reinforcement learning
Machine learning (ML) is routinely used in every sector to make predictions. But beyond simple predictions, making decisions is more complicated because non-optimal short-term decisions are sometimes preferred or even necessary to enable long-term, strategic goals. Optimizing policies to make sequential decisions toward a long-term objective can be learned using a family of ML models called Reinforcement Learning (RL).
Amazon SageMaker is a modular, fully managed service with which developers and data scientists can build, train, and deploy ML models at any scale. In addition to building supervised and unsupervised ML models, you can also build RL models in Amazon SageMaker. Amazon SageMaker RL builds on top of Amazon SageMaker, adding pre-packaged RL toolkits and making it easy to integrate custom simulation environments. Training and prediction infrastructure is fully managed so you can focus on your RL problem and not on managing servers.
In this post I will show you how to train an agent with RL that can make smart decisions at each time step in a simple bidding environment. The RL agent will choose whether to buy or sell an asset at a given price to achieve maximum long-term profit. I will first introduce the mathematical concepts behind deep reinforcement learning and describe a simple custom implementation of a trading agent in Amazon SageMaker RL. I will also present some benchmark results between two different types of implementation. The first, most straightforward approach consists of an agent looking back at a 10-day window to predict the best decision to make between buying, selling, or doing nothing. In the second approach, I design a time series forecasting deep learning recurrent neural network (RNN) and the agent acts based on forecasts produced by the RNN. The RNN encoder plays the role of an advisor as the agent makes decisions and learns optimal policies to maximize long-term profit.

The data for this post is an arbitrary bidding system made of financial time series in dollars that represent the prices of an arbitrary asset. You can think of this data as the price of an EC2 Spot Instance or the market value of a publicly traded stock.
Introduction to deep reinforcement learning
Predicting events is straightforward, but making decisions is more complicated. The framework of reinforcement learning defines a system that learns to act and make decisions to reach a specified long-term objective. This section describes the key motivations, concepts, and equations behind deep reinforcement learning. If you are familiar with RL concepts, you can skip this section.
Notations and terminology
Supervised learning relies on labels of target outcomes for training models to predict these outcomes on unseen data. Unsupervised learning does not need labels; it learns inherent patterns on training data to group unseen data according to these learned patterns. But there are cases in which labeled data is only partially available, cases in which you can only characterize final targeted outcomes and you’d like to learn how to reach these outcomes, or even cases in which tradeoffs and compromises need be learned given an overall objective (for example, how to balance work and personal life every day to remain happy in the long term). Those are cases where RL can help. Motivations behind RL are indeed cases in which you cannot define a complete supervision and can only define feedback signals based on actions taken, and cases in which you’d like to learn the optimal decisions to make as time progresses.
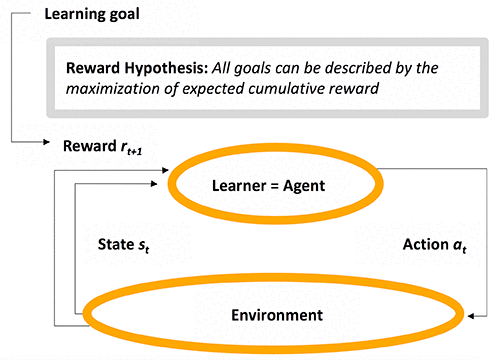
To define an RL framework, you need to define a goal for a learning system (the agent) that makes decisions in an environment. Then you need to translate this goal into a mathematical formula called a reward function, aimed at rewarding or penalizing the agent when it takes an action and acting as a feedback loop to help the agent reach the predefined goal. There are three key RL components: state, action, and reward; at each time step, the agent receives a representation of the environment’s state st, takes an action at based on st, and receives a numerical reward rt+1based on st+1 = (st, at).
The following diagram presents key components of Reinforcement Learning.
Defining a reward function can be easy or, in contrast, highly empirical. For example, in the AWS DeepRacer League, participants are asked to invent their own RL reward function to compete in virtual and in-person races worldwide, because as of this writing, no one knows how to define the best policy for a car to win a race. In contrast, for a trading agent, the reward function can be simply defined as the overall profit accumulated, because this is always a key performance that traders are driving toward.
In most cases, situations in which an agent is confronted may change over time depending on which actions it takes, and thus the RL problem requires to map situations to actions that are best in these particular situations. The general RL problem consists of learning entire sequences of actions, called policies, and noted 𝜋(a|s), to maximize reward.
Before looking at methods to find optimal policies, you can formalize the objective of learning when the goal is to maximize the cumulative reward after a time step t by defining the concept of cumulative return Gt:
![]()
When there is a notion of a final step, each subsequence of actions is called an episode, and the MDP is said to have a finite horizon. If the agent-environment interaction goes on forever, the MDP is said to have an infinite horizon; in which case you can introduce a concept of discounting to define a mathematically unified notation for cumulative return:
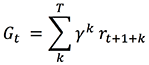
If γ = 1 and T is finite, this notation is the finite horizon formula for Gt, while if γ < 1, episodes naturally emerge even if T is infinite because terms with a large value of k become exponentially insignificant compared to terms with a smaller value of k. Thus the sum converges for infinite horizon MDP, and this notation applies for both finite and infinite horizon MDP.
Optimizing sequential decision-making with RL
There exists a large number of optimization methods that have been developed to solve the general RL problem. They are generally grouped into either policy-based methods or value-based methods, or combination thereof. We’ll focus mostly on the value-based methods as explained below.
Policy-based RL
In a policy-based RL, the policy is defined as a parametric function of some parameters θ: 𝜋θ = 𝜋(a|s,θ) and estimated directly by standard gradient methods. This is done by defining a performance measure, typically the expected value of Gt for a given policy, and applying gradient ascent to find θ that maximizes this performance measure. 𝜋θ can be any parameterized functional form of 𝜋 as long as 𝜋 is differentiable with respect to θ; thus a neural network can be used to estimate it, in which case the parameters θ are the weights of the neural network and the neural network predicts entire policies based on input states.
Direct policy search is relatively simple and also very limited because it attempts to estimate an entire policy directly from a set of previously experienced policies. Combining policy-based RL with value-based RL to refine the estimate of Gt almost always improves accuracy and convergence of RL, so this post focuses exclusively on value-based RL.
Value-based RL
An RL process is a Markov Decision Process (MDP), which is a mathematical formalization of sequential decision-making for which you can make precise statements. An MDP consists in a sequence (s0, a0, r1, s1, a1, r2, …, sn), or more generally (st, at, rt+1, st+1)n, and the dynamics of an MDP as illustrated in the previous diagram is fully characterized by a transition probability T(s,a,s’) = p(s’|s,a) that defines the probability for any state s to going to any other state s’, and a reward function r(s,a) = 𝔼(r|s,a) that defines the expected reward for any given state s.
Given the goal of RL is to learn the best policies to maximize Gt, this post first describes how to evaluate a policy in an MDP, and then how to go about finding an optimal policy.
To evaluate a policy, define a measure for any state s called a state value function V(s) that estimates how good it is to be in s for a particular way of acting, that is, for a particular policy 𝜋:
![]()
Recall from previous section that Gt is defined by the cumulative sum of rewards starting from current time step t up to final time step T. Replacing Gt by the right side of the equation defined in the previous section and moving rt+1 out of the summation, you get:
![]()
Replacing the expectation formula by a sum over all probabilities yields:
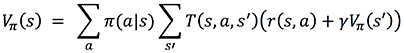
The latter is called the Bellman equation; it enables you to compute V𝜋(s) for an arbitrary 𝜋 based on T and r, computing the new value of V at time step t based on the previous value of V at time step t+1, recursively. You can estimate T and r by counting all the occurrences of observed transitions and rewards in a set of observed interactions between the agent and the environment. T and r define the model of the MDP.
Now you know how to evaluate a policy, you can extend the notion of state value function to the notion of state-action value function Q(s,a) to define an optimal policy:
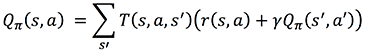
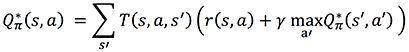
The latter is called the Bellman Optimality equation; it estimates the value of taking a particular action a in a particular state s assuming you’ll take the best actions thereafter. If you transform the Bellman Optimality equation into an assignment function you get an iterative algorithm that, assuming you know T and r, is guaranteed to converge to the optimal policy with random sampling of all possible actions in all states. Because you can apply this equation to states in any order, this iterative algorithm is referred to as asynchronous dynamic programming.
For systems in which you can easily compute or sample T and r, this approach is sufficient and is referred to as model-based RL because you know (previously computed) the transition dynamics (as characterized by T and r). But for most real-case problems, it is more convenient to produce stochastic estimates of the Q-values based on experience accumulated so far, so the RL agent learns in real time at every step and ultimately converges toward true estimates of the Q-values. To this end, combine asynchronous dynamic programming with the concept of moving average:
![]()
and replace Gt(s) by a sampled value as defined in the Bellman Optimality equation:
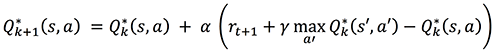
The latter is called temporal difference learning; it enables you to update the moving average Q*k+1(s,a) based on the difference between Q*k(s,a) and Q*k(s’,a’). This post shows a one-step temporal difference, as used in the most straightforward version of the Q-learning algorithm, but you could extend this equation to include more than one step (n-step temporal difference). Again, some theorems exist that prove Q-learning converges to the optimal policy 𝜋* assuming infinite random action selection.
RL action-selection strategy
You can alleviate the infinite random action selection condition by using a more efficient random action selection strategy such as ε-Greedy to increase sampling of states frequently encountered in good policies and decrease sampling of less valuable states. In ε-Greedy, the agent selects a random action with probability ε, and the rest of the time (that is, with probability 1 – ε), the agent selects the best action according to the latest Q-values, which is defined as ![]() .
.
This strategy enables you to balance exploiting the latest Q-values with exploring new states and actions. Generally, ε is chosen to be large at the beginning to favor exploration of state-action space, and progressively reduced to a smaller value. For example, ε = 1% to exploit Q-values most of the time yet keep exploring and potentially discovering better policies.
Combining deep learning and reinforcement learning
In many cases, for example when playing chess or Go, the number of states, actions, and combinations thereof is so large that the memory and time needed to store the array of Q-values is enormous. There are more combinations of states and actions in the game Go than known stars in the universe. Instead of storing Q-values for all states and actions in an array which is impossible for Go and many other cases, deep RL attempts to generalize experience from a subset of states and actions to new states and actions. The following diagram is a comparison of Q-learning with look-up tables vs. function approximation.
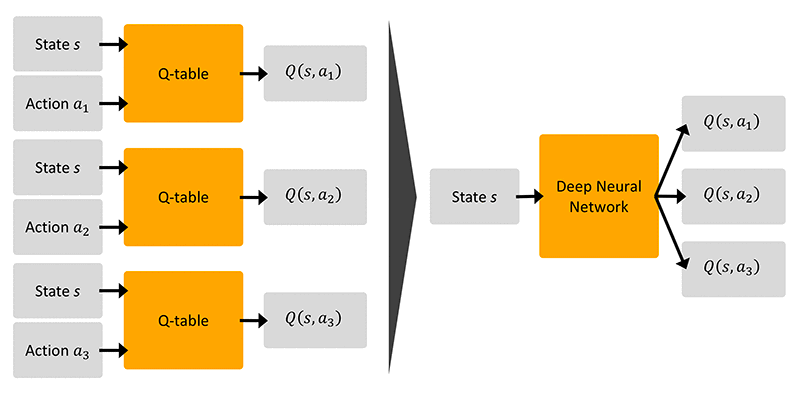
Deep Q-learning uses a supervised learning approximation to Q(s,a) by using ![]() as the label, because the Q-learning assignment function is equivalent to a gradient update of the general form x = x – ∝∇J (for any arbitrary x) where:
as the label, because the Q-learning assignment function is equivalent to a gradient update of the general form x = x – ∝∇J (for any arbitrary x) where:
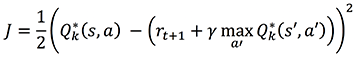
The latter is called the Square Bellman Loss; it allows you to estimate Q-values based on generalization from mapping states and actions to Q-values using a deep learning network, hence the name deep Q-learning.
Deep Q-learning is not guaranteed to converge anymore because the label used for supervised learning depends on current values of the network weights, which are themselves updated based on learning from the labels, hence a problem of broken ergodicity. But this approach is often good enough in practice and can generalize to the most complex RL problems (such as autonomous driving, robotics, or playing Go).
In deep RL, the training set changes at every step, so you need to define a buffer to enable batch training, and schedule regular refreshes as experience accumulates for the agent to learn in real time. This is called experience replay and can be compared to the process of learning while dreaming in biological systems: experience replay allows you to keep optimizing policies over a subset of experiences (st, at, rt+1, st+1)n kept in memory.
This closes our theoretical journey on reinforcement learning and in particular the popular Deep Q-learning method, which implied several flavors of statistical learning, namely asynchronous dynamic programming, moving average, ε-Greedy and deep learning. Several RL variants exist in addition to the standard Deep Q-learning method, and Amazon SageMaker RL provides most of them out of the box, so after understanding one you will be able to test most of them using Amazon SageMaker RL.
Implementing a custom RL model in Amazon SageMaker
Application of reinforcement learning in financial services has received attention because better financial decisions can lead to high dollar return. In this post I implement a financial trading bot to demonstrate how to develop an agent that looks at the price of an asset over the past few days and decide whether to buy, sell, or do nothing, given the goal to maximize long-term profit.
I will benchmark this approach with another approach in which I combine reinforcement learning with recurrent deep neural networks for time series forecasting. In this second approach, the agent uses insights from multi-step horizon forecasts to make trading decisions and learn policies based on forecasted sequences of events rather than past sequences of events.
The data is a randomized version of a publicly available dataset on Yahoo Finance and represents price series for an arbitrary asset. For example, you can think of this data as the price of an EC2 Spot Instance or the market value of a publicly traded stock.
Setting up a built-in preset for deep Q-learning
In Amazon SageMaker RL, a preset file configures the RL training jobs and defines the hyperparameters for the RL algorithms. The following preset, for example, implements and parameterizes a deep Q-learning agent, as described in the previous section. It sets the number of steps to 2M. For more information about Amazon SageMaker RL hyperparameters and training jobs configuration, see Reinforcement Learning with Amazon SageMaker RL.
Setting up a custom OpenAI Gym RL environment
In Amazon SageMaker RL, most of the components of an RL Markov Decision Process as described in the previous section are defined in an environment file. You can connect open-source and custom environments developed using OpenAI Gym, which is a popular set of interfaces to help define RL environments and is fully integrated into Amazon SageMaker. The RL environment can be the real world in which the RL agent interacts or a simulation of the real world. You can simulate the real world by a daily series of past prices. To formulate the bidding problem into an RL problem, you need to define each of the following components of the MDP:
- Environment – Custom environment that generates a simulated price with daily and weekly variations and occasional spikes
- State – Daily price of the asset over the past 10 days
- Action – Sell or buy the asset, or do nothing, on a daily basis
- Goal – Maximize accumulated profit
- Reward – Positive reward equivalent to daily profit, if any, and a penalty equivalent to the price paid for any asset purchased
A custom file called TradingEnv.py specifies all these components. It is located in the src/ folder and called by the preset file defined earlier. In particular, the size of the state space (n = 10 days) and the action space (m = 3) are defined using OpenAI Gym through the following lines of code:
The goal is translated into a quantitative reward function, as explained in the previous section, and this reward function is also formulated in the environment file. See the following code:
Launching an Amazon SageMaker RL estimator
After defining a preset and RL environment in Amazon SageMaker RL, you can train the agent by creating an estimator following a similar approach to when using any other ML estimators in Amazon SageMaker. The following code shows how to define an estimator that calls the preset (which itself calls the custom environment):
You would generally use a config.py file in Amazon SageMaker RL to define global variables, such as the location of a custom data file in the Amazon SageMaker container. See the following code:
Training and evaluating the RL agent’s performance
This section demonstrates how to train the RL bidding agent in a simulation environment constructed using seven years of daily historical transactions. You can evaluate learning during the training phase and evaluate the performance of the trained RL agent at generalizing on a test simulation, here constructed using three additional years of daily transactions. You can assess the agent’s ability to learn and generalize by visualizing the accumulated reward and accumulated profit per episode during the training and test phases.
Evaluating learning during training of the RL agent
In reinforcement learning, you can train an agent by simulating interactions (st, at, rt+1, st+1) with the environment and computing the cumulative return Gt, as described previously. After an initial exploration phase, as the value of ε in ε-Greedy progressively decreases to favor exploitation of learned policies, the total accumulated reward in a given episode accounts for how good the policy followed was. Thus, the total accumulated reward compared between episodes enables you to evaluate the relative quality of the policies learned. The following graphs show the reward and profit accumulated by the RL agent during training simulations. The x-axis is the episode index and the y-axis is the reward or profit accumulated per episode by the RL agent.
The graph on accumulated reward shows a trend with essentially three phases: relatively large fluctuations during the first 300 episodes (exploration phase), steady growth between 300 and 500 episodes, and a plateau (500–800 episodes) in which the total accumulated reward has reached convergence and revolves around a relatively stable value of $1,800.
Consistently, the accumulated profit is approximately zero during the first 300 episodes and revolves around a relatively stable value of $800 after episode 500.
Together, these results indicate that the RL agent has learned to trade the asset profitably, and has converged toward a stable behavior with reproducible policies to generate profit over the training dataset.
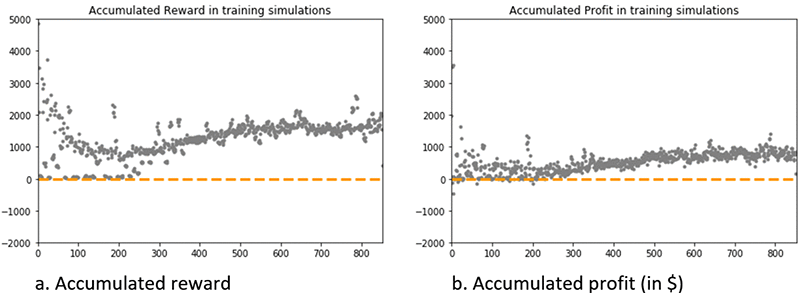
Evaluating generalization on a test set of the RL agent
To evaluate the agent’s ability to generalize to new interactions with the environment, you can constrain the agent to exploit the learned policies by setting the value of ε to zero and simulate new interactions (st, at, rt+1, st+1) with the environment.
The following graph shows the profit generated by the RL agent during test simulations. The x-axis is the episode index and the y-axis is profit accumulated per episode by the RL agent.
The graph shows that after three years of new daily prices for the same asset, the trained agent tends to generate profits with a mean of $2,200 and standard deviation of $600 across 65 test episodes. In contrast to the training simulations, you can observe a steady mean across all 65 test episodes simulated, indicating a strong convergence of the policies learned.
The graph confirms that the RL agent has converged and learned reproducible policies to trade the asset profitably and can generalize to new prices and trends.
Benchmarking a deep recurrent RL agent
Finally, I benchmarked the results from the previous deep RL approach with a deep recurrent RL approach. Instead of defining a state as a window of the past 10 days, an RNN for time series forecasting encodes the state as a 10-day horizon forecast, so the agent benefits from an advisor on future expected prices when learning optimal trading policies for maximizing long-term return.
Implementing a forecast-based RL state space
The following code implements a simple RNN for time series forecasting, following the post Forecasting financial time series with dynamic deep learning on AWS:
And the following function redirects the agent to an observation based on lag or forecasted horizon (the two types of RL approaches discussed in this post), depending on the value of a custom global variable called mode:
Evaluating learning during training of the RNN-based RL agent
As in the previous section for the RL agent in which a state is defined as the lag of the past 10 observations (referred to as lag-based RL), you can evaluate the relative quality of the policies learned by the RNN-based agent by comparing the total accumulated reward between episodes.
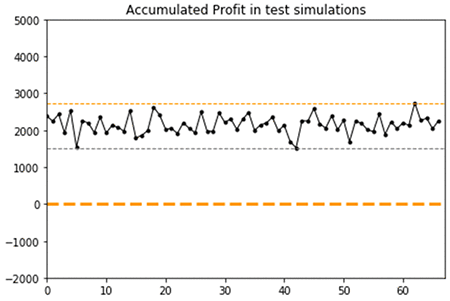
The following graphs show the reward and profit accumulated by the RNN-based RL agent during training simulations. The x-axis is the episode index and the y-axis is the reward or profit accumulated per episode by the RL agent.
The graph on accumulated reward shows a steady growth after episode 300, and most episodes after episode 500 result in an accumulated reward of approximately $1,000. But several episodes result in a much higher reward of up to $8,000.
The accumulated dollar profit is approximately zero during the first 300 episodes, revolves around a positive value after episode 500, with again several episodes where the generated profit reaches up to $7,500.
Together, these results indicate that the RL agent has learned to trade the asset profitably, and has converged toward a behavior with policies that generate profit either around $500–800, or some much higher values up to $7,500, over the training dataset.
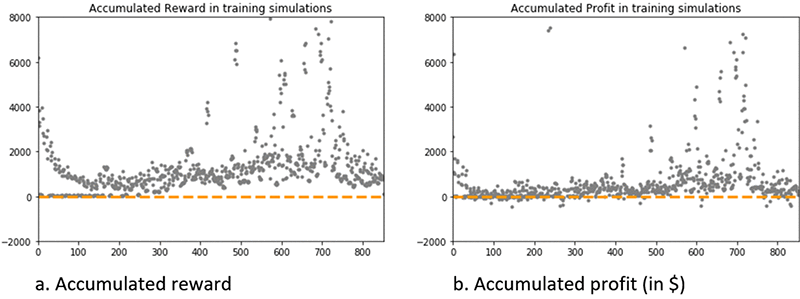
Evaluating generalization on a test set of the RNN-based RL agent
The following graph shows the profit in dollars generated by the RNN-based RL agent during test simulations. The x-axis is the episode index and the y-axis is the profit accumulated per episode by the RL agent.
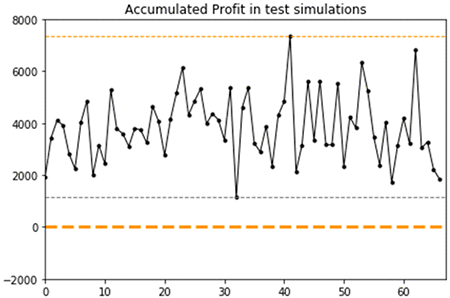
The graph shows that the RNN-based RL agent can generalize to new prices and trends. Consistent with the observations made during training, it shows that after three years of new daily prices for the same asset, the trained agent tends to generate profits around $2,000, or some much higher profit up to $7,500. This dual behavior is characterized by an overall mean of $4,900 and standard deviation of $3,000 across the 65 test episodes.
The minimum profit across all 65 test episodes simulated is $1,300, while it was $1,500 for the lag-based RL approach. The maximum profit is $7,500, with frequent accumulated profit over $5,000, while it was only $2,800 for the lag-based RL approach. Thus, the RNN-based RL approach results in higher volatility compared to the lag-based RL approach, but exclusively toward higher profits which is a better outcome given the goal of the RL problem is to generate profit.
The results between the lag-based RL agent and the RNN-based RL agent confirm that the RNN-based RL agent is more beneficial. It has learned reproducible policies to trade the asset that are either similar to, or significantly outperform, the policies learned by the lag-based agent for generating profit.
Conclusion
In this post, I introduced the motivations and underlying theoretical concepts behind deep reinforcement learning, an ML solution framework that enables you to learn and apply optimal policies given a long-term objective. You have seen how to use Amazon SageMaker RL to develop and train a custom deep RL agent to make smart decisions in real time in an arbitrary bidding environment.
You have also seen how to evaluate the performance of the deep RL agent during training and test simulations, and how to benchmark its performance against a more advanced, deep recurrent RL based on RNN for time series forecasting.
This post is for educational purposes only. Past trading performance does not guarantee future performance. The loss in trading can be substantial; investors should use all trading strategies at their own risk.
For more information about popular RL algorithms, sample codes, and documentation, you can visit Reinforcement Learning with Amazon SageMaker RL.
About the Author
 Jeremy David Curuksu is a data scientist at AWS and the global lead for financial services at Amazon Machine Learning Solutions Lab. He holds a MSc and a PhD in applied mathematics, and was a research scientist at EPFL (Switzerland) and MIT (US). He is the author of multiple scientific peer-reviewed articles and the book Data Driven, which introduces management consulting in the new age of data science.
Jeremy David Curuksu is a data scientist at AWS and the global lead for financial services at Amazon Machine Learning Solutions Lab. He holds a MSc and a PhD in applied mathematics, and was a research scientist at EPFL (Switzerland) and MIT (US). He is the author of multiple scientific peer-reviewed articles and the book Data Driven, which introduces management consulting in the new age of data science.
Building an NLP-powered search index with Amazon Textract and Amazon Comprehend
Organizations in all industries have a large number of physical documents. It can be difficult to extract text from a scanned document when it contains formats such as tables, forms, paragraphs, and check boxes. Organizations have been addressing these problems with Optical Character Recognition (OCR) technology, but it requires templates for form extraction and custom workflows.
Extracting and analyzing text from images or PDFs is a classic machine learning (ML) and natural language processing (NLP) problem. When extracting the content from a document, you want to maintain the overall context and store the information in a readable and searchable format. Creating a sophisticated algorithm requires a large amount of training data and compute resources. Building and training a perfect machine learning model could be expensive and time-consuming.
This blog post walks you through creating an NLP-powered search index with Amazon Textract and Amazon Comprehend as an automated content-processing pipeline for storing and analyzing scanned image documents. For pdf document processing, please refer AWS Sample github repository to use Textractor.
This solution uses serverless technologies and managed services to be scalable and cost-effective. The services used in this solution include:
- Amazon Textract – Extracts text and data from scanned documents automatically.
- Amazon Comprehend – Uses ML to find insights and relationships in text.
- Amazon ES with Kibana – Searches and visualizes the information.
- Amazon Cognito – Integrates with Amazon ES and authenticates user access to Kibana. For more information, see Get started with Amazon Elasticsearch Service: Use Amazon Cognito for Kibana access control.
- Amazon S3 – Stores your documents and allows for central management with fine-tuned access controls.
- AWS Lambda – Executes code in response to triggers such as changes in data, shifts in system state, or user actions. Because S3 can directly trigger a Lambda function, you can build a variety of real-time serverless data-processing systems.
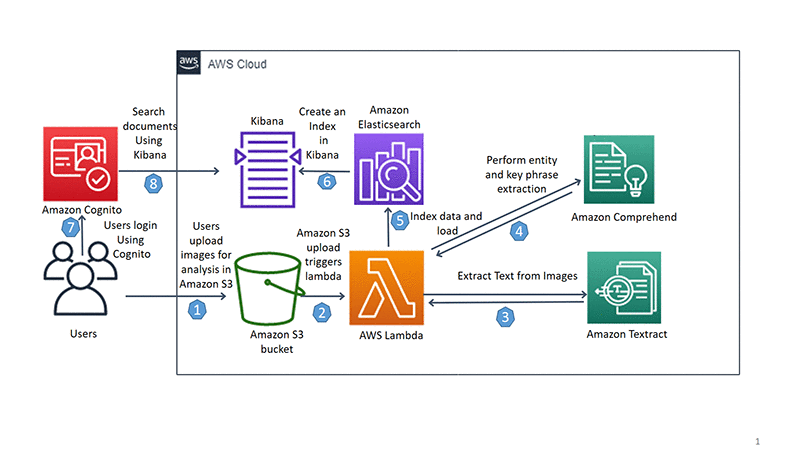
Architecture
- Users upload OCR image for analysis to Amazon S3.
- Amazon S3 upload triggers AWS Lambda.
- AWS Lambda invokes Amazon Textract to extract text from image.
- AWS Lambda sends the extracted text from image to Amazon Comprehend for entity and key phrase extraction.
- This data is indexed and loaded into Amazon Elasticsearch.
- Kibana gets indexed data.
- Users log into Amazon Cognito.
- Amazon Cognito authenticates to Kibana to search documents.
Deploying the architecture with AWS CloudFormation
The first step is to use an AWS CloudFormation template to provision the necessary IAM role and AWS Lambda function to interact with the Amazon S3, AWS Lambda, Amazon Textract, and Amazon Comprehend APIs.
- Launch the AWS CloudFormation template in the US-East-1 (Northern Virginia) Region:

- You will see the below information on the Create stack screen:
Stack name: document-search
CognitoAdminEmail: abc@amazon.com
DOMAINNAME: documentsearchapp.Edit the CognitoAdminEmail with your email address. You will receive your temporary Kibana credentials in an email.
- Scroll down to Capabilities and check both the boxes to provide acknowledgement that AWS CloudFormation will create IAM resources. For more information, see AWS IAM resources.

- Scroll down to Transforms and choose Create Change Set.
 The AWS CloudFormation template uses AWS SAM, which simplifies how to define functions and APIs for serverless applications, as well as features for these services like environment variables. When deploying AWS SAM templates in an AWS CloudFormation template, you need to perform a transform step to convert the AWS SAM template.
The AWS CloudFormation template uses AWS SAM, which simplifies how to define functions and APIs for serverless applications, as well as features for these services like environment variables. When deploying AWS SAM templates in an AWS CloudFormation template, you need to perform a transform step to convert the AWS SAM template. - Wait a few seconds for the change set to finish computing changes. Your screen should look as follows with Action, Logical Id, Physical Id, Resource Type, and Replacement. Finally, click on the Execute button, which will let AWS CloudFormation launch resources in the background.

- The following screenshot of the Stack Detail page shows the Status of the CloudFormation stack as
CREATE_IN_PROGRESS. Wait up to 20 minutes for the Status to change toCREATE_COMPLETE. In Outputs, copy the value of S3KeyPhraseBucket and KibanaLoginURL.
Uploading documents to the S3 bucket
To upload your documents to your newly created S3 bucket in the above step, complete the following:
- Click on the Amazon S3 Bucket URL you copied from the CloudFormation Output.
- Download the example dataset
demo-data.zipfrom the GitHub repo. This dataset contains a variety of images that include forms, a scanned page with paragraphs, and a two-column document. - Unzip the data.
- Upload the files in the demo-data folder to the Amazon S3 bucket starting with
document-search-blog-s3-<Random string>.
For more information, see How Do I Upload Files and Folders to an S3 Bucket?
After the upload completes, you can see four image files: Employment_application.JPG, expense.png, simple-document-image.jpg, and two-column-image.jpg in the S3 bucket.
Uploading the data to S3 triggers a Lambda S3 event notification to invoke a Lambda function. You can find event triggers configured in your Amazon S3 bucket properties under Advanced settings-> Events. You will see a Lambda function starting with document-search-blog-ComprehendKeyPhraseAnalysis-<Random string>. This Lambda function performs the following:
- Extracts text from images using Amazon Textract.
- Performs key phrase extraction using Amazon Comprehend.
- Searches text using Amazon ES.
The following code example extracts text from images using Amazon Textract:
The following code example extracts key phrases using Amazon Comprehend:
You can index the response received from Amazon Textract and Amazon Comprehend and load it into Amazon ES to create an NLP-powered search index. Refer to the below code:
For more information, see the GitHub repo.
Visualizing and searching documents with Kibana
To visualize and search documents using Kibana, perform the following steps.
- Find the email in your inbox with the subject line “Your temporary password.” Check your junk folder if you don’t see an email in your inbox.

- Go to the Kibana login URL copied from the AWS CloudFormation output.
- Login using your email address as the Username and the temporary password from the confirmation email as the Password. Click on Sign In.

Note: If you didn’t receive the email or missed it while deploying AWS CloudFormation, choose Sign up. - On the next page, enter a new password.
- On the Kibana landing page, from the menu, choose Discover.
- On the Management/Kibana page, you will see Step 1 of 2: Define index pattern, for Index pattern, enter
document*. The message “Success! Your index pattern matches 1 index.” appears. Choose Next step. Click Create Index Pattern. After a few seconds, you can see the document index page.
After a few seconds, you can see the document index page. - Choose Discover from the menu again. In the below screenshot you can see the document attributes.

- To view specific fields for each entry, hover over the field in the left sidebar and click Add.
This moves the fields to the Selected Fields menu. Your Kibana dashboard formulates data in an easy-to-read format. The following screenshot shows the view after adding Entity.DATE, Entity.Location, Entity.PERSON, S3link and text in the Selected Fields menu:
To look at your original document, choose s3link.
Note: You can also add forms and table to view and search tables and forms.
Conclusion
This post demonstrated how to extract and process data from an image document and visualize it to create actionable insights.
Processing scanned image documents helps you uncover large amounts of data, which can provide new business prospects. With managed ML services like Amazon Textract and Amazon Comprehend, you can gain insights into your previously undiscovered data. For example, you could build a custom application to get a text from a scanned legal document, purchase receipts, and purchase orders.
Data at scale is relevant in every industry. Whether you process data from images or PDFs, AWS can simplify your data ingestion and analysis while keeping your overall IT costs manageable.
If this blog post helps you or inspires you to solve a problem, we would love to hear about it! The code for this solution is available on the GitHub repo for you to use and extend. Contributions are always welcome!
About the authors
 Saurabh Shrivastava is a partner solutions architect and big data specialist working with global systems integrators. He works with AWS partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family, outdoor activity, and traveling to new destinations to discover new cultures.
Saurabh Shrivastava is a partner solutions architect and big data specialist working with global systems integrators. He works with AWS partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family, outdoor activity, and traveling to new destinations to discover new cultures.
 Mona is an AI/ML specialist solutions architect working with the AWS Public Sector Team. She works with AWS customers to help them with the adoption of Machine Learning on a large scale. She enjoys painting and cooking in her free time.
Mona is an AI/ML specialist solutions architect working with the AWS Public Sector Team. She works with AWS customers to help them with the adoption of Machine Learning on a large scale. She enjoys painting and cooking in her free time.
How AWS is putting machine learning in the hands of every developer and BI analyst
Today AWS announced new ways for you to easily add machine learning (ML) predictions to applications and business intelligence (BI) dashboards using relational data in your Amazon Aurora database and unstructured data in Amazon S3, by simply adding a few statements to your SQL (structured query language) queries and making a few clicks in Amazon QuickSight. Aurora, Amazon Athena, and Amazon QuickSight make direct calls to AWS ML services like Amazon SageMaker and Amazon Comprehend so you don’t need to call them from your application. This makes it more straightforward to add ML predictions to your applications without the need to build custom integrations, move data around, learn separate tools, write complex lines of code, or even have ML experience.
These new changes help make ML more usable and accessible to database developers and business analysts by making sophisticated ML predictions more readily available through SQL queries and dashboards. Formerly, you could spend days writing custom application-level code that must scale and be managed and supported in production. Now anyone who can write SQL can make and use predictions in their applications without any custom “glue code.”
Making sense of a world awash in data
AWS firmly believes that in the not-too-distant future, virtually every application will be infused with ML and artificial intelligence (AI). Tens of thousands of customers benefit from ML through Amazon SageMaker, a fully managed service that allows data scientists and developers the ability to quickly and easily build, train, and deploy ML models at scale.
While there are a variety of ways to build models, and add intelligence to applications through easy-to-use APIs like Amazon Comprehend for example, it can still be challenging to incorporate these models into your databases, analytics, and business intelligence reports. Consider a relatively simple customer service example. Amazon Comprehend can quickly evaluate the sentiment of a piece of text (is it positive or negative?). Suppose that I leave feedback on a store’s customer service page: “Your product stinks and I’ll never buy from you again!” It would be trivial for the store to run sentiment analysis on user feedback and contact me immediately to make things right. The data is available in their database and ML services are widely available.
The problem, however, lies in the difficulty of building prediction pipelines to move data between models and applications.
Developers have historically had to perform a large amount of complicated manual work to take these predictions and make them part of a broader application, process, or analytics dashboard. This can include undifferentiated, tedious application-level code development to copy data between different data stores and locations and transform data between formats, before submitting data to the ML models and transforming the results to use inside your application. Such work tends to be cumbersome and a poor way to use the valuable time of your developers. Moreover, moving data in and out of data stores complicates security and governance.
Putting machine learning in the hands of every developer
At AWS, our mission is clear: we aim to put machine learning in the hands of every developer. We do this by making it easier for you to become productive with sophisticated ML services. Customers of all sizes, including NFL, Intuit, AstraZeneca, and Celgene, rely on AWS ML services such as Amazon SageMaker and Amazon Comprehend. Celgene, for example, uses AWS ML services for toxicology prediction to virtually analyze the biological impacts of potential drugs without putting patients at risk. A model that previously took two months to train can now be trained in four hours.
While AWS offers the broadest and deepest set of AI and ML services, and though we introduced more than 200 machine learning features and capabilities in 2018 alone, we’ve felt that more is needed. Among these other innovations, one of the best things we can do is to enable your existing talent to become productive with ML.
And, specifically, developer talent and business analyst talent.
Though we offer services that improve the productivity of data scientists, we want to give the much broader population of application developers access to fully cloud-native, sophisticated ML services. Tens of thousands of customers use Aurora and are adept at programming with SQL. We believe it is crucial to enable you to run ML learning predictions on this data so you can access innovative data science without slowing down transaction processing. As before, you can train ML models against your business data using Amazon SageMaker, with the added ability to run predictions against those same models with one line of SQL using Aurora or Athena. This makes the results of ML models more accessible for a broad population of application developers.
Lead scoring is a good example of how this works. For example, if you build a CRM system on top of Aurora, you’ll store all of your customer relationship data, marketing outreach, leads, etc. in the database. As leads come from the website they’re moved to Aurora, and your sales team follows up on the leads convert them to customers.
But what if you wanted to help make that process more effective for your sales team? Lead scoring is a predictive model which helps qualify and rank incoming leads so that the sales team can prioritize which leads are most likely to convert to a customer sale, making them more productive. You can take a lead scoring model built by your data science team, or one that you have purchased on the AWS ML Marketplace, deploy it to Amazon SageMaker, and then order all your sales queues by priority based on the prediction from the model. Unlike in the past, you needn’t write any glue code.
Or you might want to use these services together to deliver on a next best offer use case. For example, your customer might phone into your call center complaining about an issue. The customer service representative successfully addresses the issue and proceeds to offer new products or services. How? Well, the representative can pull up a product recommendation on the Amazon QuickSight dashboard that shows multiple views and suggestions.
The first view shows product recommendations based on an Aurora query. The query pulls the customer profile, shopping history, and product catalog, and calls a model in Amazon SageMaker to make product recommendations. The second view is an Athena query that pulls customer browsing history or clickstream data from an S3 data lake, and calls an Amazon SageMaker model to make product recommendations. The third view is an Amazon QuickSight query that takes results from first and second view, calls an ensemble model in Amazon SageMaker, and makes the recommendations. You now have several offers to make based on different views of the customer, and all within one dashboard.
On the BI analyst side, we regularly hear from customers that it’s frustrating to have to build and manage prediction pipelines before getting predictions from a model. Developers currently spend days writing application-level code to move data back and forth between models and applications. You may now choose to deprecate your prediction pipelines and instead use Amazon QuickSight to visualize and report on all your ML predictions.
For application developers and business analysts, these changes make it more straightforward to add ML predictions to your applications without the need to build custom integrations, move data around, learn separate tools, write complex lines of code, or even have ML experience. Instead of days of developer labor, you can now add a few statements to your SQL queries and make a few clicks in Amazon QuickSight.
In these ways, we’re enabling a broader population of developers and data analysts to tap into the power of ML, with no Ph.D. required.
About the Author
 Matt Asay (pronounced “Ay-see”) is a principal at AWS, and has spent nearly two decades working for a variety of open source and big data companies. You can follow him on Twitter (@mjasay).
Matt Asay (pronounced “Ay-see”) is a principal at AWS, and has spent nearly two decades working for a variety of open source and big data companies. You can follow him on Twitter (@mjasay).
Astrophotography with Night Sight on Pixel Phones
Taking pictures of outdoor scenes at night has so far been the domain of large cameras, such as DSLRs, which are able to achieve excellent image quality, provided photographers are willing to put up with bulky equipment and sometimes tricky postprocessing. A few years ago experiments with phone camera nighttime photography produced pleasing results, but the methods employed were impractical for all but the most dedicated users.
Night Sight, introduced last year as part of the Google Camera App for the Pixel 3, allows phone photographers to take good-looking handheld shots in environments so dark that the normal camera mode would produce grainy, severely underexposed images. In a previous blog post our team described how Night Sight is able to do this, with a technical discussion presented at SIGGRAPH Asia 2019.
This year’s version of Night Sight pushes the boundaries of low-light photography with phone cameras. By allowing exposures up to 4 minutes on Pixel 4, and 1 minute on Pixel 3 and 3a, the latest version makes it possible to take sharp and clear pictures of the stars in the night sky or of nighttime landscapes without any artificial light.
 |
| The Milky Way as seen from the summit of Haleakala volcano on a cloudless and moonless September night, captured using the Google Camera App running on a Pixel 4 XL phone. The image has not been retouched or post-processed in any way. It shows significantly more detail than a person can see with the unaided eye on a night this dark. The dust clouds along the Milky Way are clearly visible, the sky is covered with thousands of stars, and unlike human night vision, the picture is colorful. |
A Brief Overview of Night Sight
The amount of light detected by the camera’s image sensor inherently has some uncertainty, called “shot noise,” which causes images to look grainy. The visibility of shot noise decreases as the amount of light increases; therefore, it is best for the camera to gather as much light as possible to produce a high-quality image.
How much light reaches the image sensor in a given amount of time is limited by the aperture of the camera lens. Extending the exposure time for a photo increases the total amount of light captured, but if the exposure is long, motion in the scene being photographed and unsteadiness of the handheld camera can cause blur. To overcome this, Night Sight splits the exposure into a sequence of multiple frames with shorter exposure times and correspondingly less motion blur. The frames are first aligned, compensating for both camera shake and in-scene motion, and then averaged, with careful treatment of cases where perfect alignment is not possible. While individual frames may be fairly grainy, the combined, averaged image looks much cleaner.
Experimenting with Exposure Time
Soon after the original Night Sight was released, we started to investigate taking photos in very dark outdoor environments with the goal of capturing the stars. We realized that, just as with our previous experiments, high quality pictures would require exposure times of several minutes. Clearly, this cannot work with a handheld camera; the phone would have to be placed on a tripod, a rock, or whatever else might be available to hold the camera steady.
Just as with handheld Night Sight photos, nighttime landscape shots must take motion in the scene into account — trees sway in the wind, clouds drift across the sky, and the moon and the stars rise in the east and set in the west. Viewers will tolerate motion-blurred clouds and tree branches in a photo that is otherwise sharp, but motion-blurred stars that look like short line segments look wrong. To mitigate this, we split the exposure into frames with exposure times short enough to make the stars look like points of light. Taking pictures of real night skies we found that the per-frame exposure time should not exceed 16 seconds.
 |
| Motion-blurred stars in a single-frame two-minute exposure. |
While the number of frames we can capture for a single photo, and therefore the total exposure time, is limited by technical considerations, we found that it is more tightly constrained by the photographer’s patience. Few are willing to wait more than four minutes for a picture, so we limited a single Night Sight image to at most 15 frames with up to 16 seconds per frame.
Sixteen-second exposures allow us to capture enough light to produce recognizable images but a useable camera app capable of taking pictures that look great must deal with additional issues that are unique to low-light photography.
Dark Current and Hot Pixels
Dark current causes CMOS image sensors to record a spurious signal, as if the pixels were exposed to a small amount of light, even when no actual light is present. The effect is negligible when exposure times are short, but it becomes significant with multi-second captures. Due to unavoidable imperfections in the sensor’s silicon substrate, some pixels exhibit higher dark current than their neighbors. In a recorded frame these “warm pixels,” as well as defective “hot pixels,” are visible as tiny bright dots.
Warm and hot pixels can be identified by comparing the values of neighboring pixels within the same frame and across the sequence of frames recorded for a photo, and looking for outliers. Once an outlier has been detected, it is concealed by replacing its value with the average of its neighbors. Since the original pixel value is discarded, there is a loss of image information, but in practice this does not noticeably affect image quality.
 |
| Left: A small region of a long-exposure image with hot pixels, and warm pixels caused by dark current nonuniformity. Right: The same image after outliers have been removed. Fine details in the landscape, including small points of light, are preserved. |
Scene Composition
Mobile phones use their screens as electronic viewfinders — the camera captures a continuous stream of frames that is displayed as a live video in order to aid with shot composition. The frames are simultaneously used by the camera’s autofocus, auto exposure, and auto white balance systems.
To feel responsive to the photographer, the viewfinder is updated at least 15 times per second, which limits the viewfinder frame exposure time to 66 milliseconds. This makes it challenging to display a detailed image in low-light environments. At light levels below the rough equivalent of a full moon or so, the viewfinder becomes mostly gray — maybe showing a few bright stars, but none of the landscape — and composing a shot becomes difficult.
To assist in framing the scene in extremely low light, Night Sight displays a “post-shutter viewfinder”. After the shutter button has been pressed, each long-exposure frame is displayed on the screen as soon as it has been captured. With exposure times up to 16 seconds, these frames have collected almost 250 times more light than the regular viewfinder frames, allowing the photographer to easily see image details as soon as the first frame has been captured. The composition can then be adjusted by moving the phone while the exposure continues. Once the composition is correct, the initial shot can be stopped, and a second shot can be captured where all frames have the desired composition.
 |
| Left: The live Night Sight viewfinder in a very dark outdoor environment. Except for a few points of light from distant buildings, the landscape and the sky are largely invisible. Right: The post-shutter viewfinder during a long exposure shot. The image is much clearer; it updates after every long-exposure frame. |
Autofocus
Autofocus ensures that the image captured by the camera is sharp. In normal operation, the incoming viewfinder frames are analyzed to determine how far the lens must be from the sensor to produce an in-focus image, but in very low light the viewfinder frames can be so dark and grainy that autofocus fails due to lack of detectable image detail. When this happens, Night Sight on Pixel 4 switches to “post-shutter autofocus.” After the user presses the shutter button, the camera captures two autofocus frames with exposure times up to one second, long enough to detect image details even in low light. These frames are used only to focus the lens and do not contribute directly to the final image.
Even though using long-exposure frames for autofocus leads to consistently sharp images at light levels low enough that the human visual system cannot clearly distinguish objects, sometimes it gets too dark even for post-shutter autofocus. In this case the camera instead focuses at infinity. In addition, Night Sight includes manual focus buttons, allowing the user to focus on nearby objects in very dark conditions.
Sky Processing
When images of very dark environments are viewed on a screen, they are displayed much brighter than the original scenes. This can change the viewer’s perception of the time of day when the photos were captured. At night we expect the sky to be dark. If a picture taken at night shows a bright sky, then we see it as a daytime scene, perhaps with slightly unusual lighting.
This effect is countered in Night Sight by selectively darkening the sky in photos of low-light scenes. To do this, we use machine learning to detect which regions of an image represent sky. An on-device convolutional neural network, trained on over 100,000 images that were manually labeled by tracing the outlines of sky regions, identifies each pixel in a photograph as “sky” or “not sky.”
 |
| A landscape picture taken on a bright full-moon night, without sky processing (left half), and with sky darkening (right half). Note that the landscape is not darkened. |
Sky detection also makes it possible to perform sky-specific noise reduction, and to selectively increase contrast to make features like clouds, color gradients, or the Milky Way more prominent.
Results
With the phone on a tripod, Night Sight produces sharp pictures of star-filled skies, and as long as there is at least a small amount of moonlight, landscapes will be clear and colorful.
Of course, the phone’s capabilities are not limitless, and there is always room for improvement. Although nighttime scenes are dark overall, they often contain bright light sources such as the moon, distant street lamps, or prominent stars. While we can capture a moonlit landscape, or details on the surface of the moon, the extremely large brightness range, which can exceed 500,000:1, so far prevents us from capturing both in the same image. Also, when the stars are the only source of illumination, we can take clear pictures of the sky, but the landscape is only visible as a silhouette.
For Pixel 4 we have been using the brightest part of the Milky Way, near the constellation Sagittarius, as a benchmark for the quality of images of a moonless sky. By that standard Night Sight is doing very well. Although Milky Way photos exhibit some residual noise, they are pleasing to look at, showing more stars and more detail than a person can see looking at the real night sky.
 |
| Examples of photos taken with the Google Camera App on Pixel 4. An album with more pictures can be found here. |
Tips and Tricks
In the course of developing and testing Night Sight astrophotography we gained some experience taking outdoor nighttime pictures with Pixel phones, and we’d like to share a list of tips and tricks that have worked for us. You can find it here.
Acknowledgements
Night Sight is an ongoing collaboration between several teams at Google. Key contributors to the project include from the Gcam team, Orly Liba, Nikhil Karnad, Charles He, Manfred Ernst, Michael Milne, Andrew Radin, Navin Sarma, Jon Barron, Yun-Ta Tsai, Tianfan Xue, Jiawen Chen, Dillon Sharlet, Ryan Geiss, Sam Hasinoff, Alex Schiffhauer, Yael Pritch Knaan and Marc Levoy; from the Super Res Zoom team, Bart Wronski, Peyman Milanfar, and Ignacio Garcia Dorado; from the Google camera app team, Emily To, Gabriel Nava, Sushil Nath, Isaac Reynolds, and Michelle Chen; from the Android platform team, Ryan Chan, Ying Chen Lou, and Bob Hung; from the Mobile Vision team, Longqi (Rocky) Cai, Huizhong Chen, Emily Manoogian, Nicole Maffeo, and Tomer Meron; from Machine Perception, Elad Eban and Yair Movshovitz-Attias.
