Save on inference costs by using Amazon SageMaker multi-model endpoints
Businesses are increasingly developing per-user machine learning (ML) models instead of cohort or segment-based models. They train anywhere from hundreds to hundreds of thousands of custom models based on individual user data. For example, a music streaming service trains custom models based on each listener’s music history to personalize music recommendations. A taxi service trains custom models based on each city’s traffic patterns to predict rider wait times.
While the benefit of building custom ML models for each use case is higher inference accuracy, the downside is that the cost of deploying models increases significantly, and it becomes difficult to manage so many models in production. These challenges become more pronounced when you don’t access all models at the same time but still need them to be available at all times. Amazon SageMaker multi-model endpoints addresses these pain points and gives businesses a scalable yet cost-effective solution to deploy multiple ML models.
Amazon SageMaker is a modular, end-to-end service that makes it easier to build, train, and deploy ML models at scale. After you train an ML model, you can deploy it on Amazon SageMaker endpoints that are fully managed and can serve inferences in real time with low latency. You can now deploy multiple models on a single endpoint and serve them using a single serving container using multi-model endpoints. This makes it easy to manage ML deployments at scale and lowers your model deployment costs through increased usage of the endpoint and its underlying compute instances.
This post introduces Amazon SageMaker multi-model endpoints and shows how to apply this new capability to predict housing prices for individual market segments using XGBoost. The post demonstrates running 10 models on a multi-model endpoint versus using 10 separate endpoints. This results in savings of $3,000 per month, as shown in the following figure:

Multi-model endpoints can easily scale to hundreds or thousands of models. The post also discusses considerations for endpoint configuration and monitoring, and highlights cost savings of over 90% for a 1,000-model example.
Overview of Amazon SageMaker multi-model endpoints
Amazon SageMaker enables you to one-click deploy your model onto autoscaling Amazon ML instances across multiple Availability Zones for high redundancy. Specify the type of instance and the maximum and minimum number desired, and Amazon SageMaker takes care of the rest. It launches the instances, deploys your model, and sets up a secure HTTPS endpoint. Your application needs to include an API call to this endpoint to achieve low latency and high throughput inference. This architecture allows you to integrate new models into your application in minutes because model changes no longer require application code changes. Amazon SageMaker is fully managed and manages your production compute infrastructure on your behalf to perform health checks, apply security patches, and conduct other routine maintenance, all with built-in Amazon CloudWatch monitoring and logging.
Amazon SageMaker multi-model endpoints enable you to deploy multiple trained models to an endpoint and serve them using a single serving container. Multi-model endpoints are fully managed and highly available to serve traffic in real time. You can easily access a specific model by specifying the target model name when you invoke the endpoint. This feature is ideal when you have a large number of similar models that you can serve through a shared serving container and don’t need to access all the models at the same time. For example, a legal application may need complete coverage of a broad set of regulatory jurisdictions, but that may include a long tail of models that are rarely used. One multi-model endpoint can serve these lightly used models to optimize cost and manage the large number of models efficiently.
To create a multi-model endpoint in Amazon SageMaker, choose the multi-model option, provide the inference serving container image path, and provide the Amazon S3 prefix in which the trained model artifacts are stored. You can define any hierarchy of your models in S3. When you invoke the multi-model endpoint, you provide the relative path of a specific model in the new TargetModel header. To add models to the multi-model endpoint, add a new trained model artifact to S3 and invoke it. To update a model already in use, add the model to S3 with a new name and begin invoking the endpoint with the new model name. To stop using a model deployed on a multi-model endpoint, stop invoking the model and delete it from S3.
Instead of downloading all the models into the container from S3 when the endpoint is created, Amazon SageMaker multi-model endpoints dynamically load models from S3 when invoked. As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. If the model is already loaded on the container and invoked, then you skip the download step and the model returns the inferences in low latency. For example, assume you have a model that is only used a few times a day. It is automatically loaded on demand, while frequently accessed models are retained in memory with the lowest latency. The following diagram shows models dynamically loaded from S3 into a multi-model endpoint.

Using Amazon SageMaker multi-model endpoints to predict housing prices
This post takes you through an example use case of multi-model endpoints, based on the domain of house pricing. For more information, see the fully working notebook on GitHub. It uses generated synthetic data to let you experiment with an arbitrary number of models. Each city has a model trained on a number of houses with randomly generated characteristics.
The walkthrough includes the following steps:
- Making your trained models available for a multi-model endpoint
- Preparing your container
- Creating and deploying a multi-model endpoint
- Invoking a multi-model endpoint
- Dynamically loading a new model
Making your trained models available for a multi-model endpoint
You can take advantage of multi-model deployment without any changes to your models or model training process and continue to produce model artifacts (for example, model.tar.gz files) that get saved in S3.
In the example notebook, a set of models is trained in parallel, and the model artifacts from each training job are copied to a specific location in S3. After training and copying a set of models, the folder has the following contents:
Each file is renamed from its original model.tar.gz name so that each model has a unique name. You refer to the target model by name when invoking a request for a prediction.
Preparing your container
To use Amazon SageMaker multi-model endpoints, you can build a docker container using the general-purpose multi-model server capability on GitHub. It is a flexible and easy-to-use framework for serving ML models with any framework. The XGBoost sample notebook demonstrates how to build a container using the open-source Amazon SageMaker XGBoost container as a base.
Creating a multi-model endpoint
The next step is to create a multi-model endpoint that knows where in S3 to find target models. This post uses boto3, the AWS SDK for Python, to create the model metadata. Instead of describing a specific model, set its mode to MultiModel and tell Amazon SageMaker the location of the S3 folder containing all the model artifacts.
Additionally, indicate the framework image that models use for inference. This post uses an XGBoost container that was built in the previous step. You can host models built with the same framework in a multi-model endpoint configured for that framework. See the following code for creating the model entity:
With the model definition in place, you need an endpoint configuration that refers back to the name of the model entity you created. See the following code:
Lastly, create the endpoint itself with the following code:
Invoking a multi-model endpoint
To invoke a multi-model endpoint, you only need to pass one new parameter, which indicates the target model to invoke. The following example code is a prediction request using boto3:
The sample notebook iterates through a set of random invocations against multiple target models hosted behind a single endpoint. This shows how the endpoint dynamically loads target models as needed. See the following output:
The time to complete the first request against a given model experiences additional latency (called a cold start) to download the model from S3 and load it into memory. Subsequent calls finish with no additional overhead because the model is already loaded.
Dynamically adding a new model to an existing endpoint
It’s easy to deploy a new model to an existing multi-model endpoint. With the endpoint already running, copy a new set of model artifacts to the same S3 location you set up earlier. Client applications are then free to request predictions from that target model, and Amazon SageMaker handles the rest. The following example code makes a new model for New York that is ready to use immediately:
With multi-model endpoints, you don’t need to bring down the endpoint when adding a new model, and you avoid the cost of a separate endpoint for this new model. An S3 copy gives you access.
Scaling multi-model endpoints for large numbers of models
The benefits of Amazon SageMaker multi-model endpoints increase based on the scale of model consolidation. You can see cost savings when hosting two models with one endpoint, and for use cases with hundreds or thousands of models, the savings are much greater.
For example, consider 1,000 small XGBoost models. Each of the models on its own could be served by an ml.c5.large endpoint (4 GiB memory), costing $0.119 per instance hour in us-east-1. To provide all one thousand models using their own endpoint would cost $171,360 per month. With an Amazon SageMaker multi-model endpoint, a single endpoint using ml.r5.2xlarge instances (64 GiB memory) can host all 1,000 models. This reduces production inference costs by 99% to only $1,017 per month. The following table summarizes the differences between single and multi-model endpoints. Note that 90th percentile latency remains at 7 milliseconds in this example.
| Single model endpoint |
Multi-model endpoint |
|
| Total endpoint price per month | $171,360 | $1,017 |
| Endpoint instance type | ml.c5.large | ml.r5.2xlarge |
| Memory capacity (GiB) | 4 | 64 |
| Endpoint price per hour | $0.119 | $0.706 |
| Number of instances per endpoint | 2 | 2 |
| Endpoints needed for 1,000 models | 1,000 | 1 |
| Endpoint p90 latency (ms) | 7 | 7 |
Monitoring multi-model endpoints using Amazon CloudWatch metrics
To make price and performance tradeoffs, you will want to test multi-model endpoints. Amazon SageMaker provides additional metrics in CloudWatch for multi-model endpoints so you can determine the endpoint usage and the cache hit rate and optimize your endpoint. The metrics are as follows:
- ModelLoadingWaitTime – The interval of time that an invocation request waits for the target model to be downloaded or loaded to perform the inference.
- ModelUnloadingTime – The interval of time that it takes to unload the model through the container’s
UnloadModelAPI call. - ModelDownloadingTime – The interval of time that it takes to download the model from S3.
- ModelLoadingTime – The interval of time that it takes to load the model through the container’s
LoadModelAPI call. - ModelCacheHit – The number of
InvokeEndpointrequests sent to the endpoint where the model was already loaded. Taking the Average statistic shows the ratio of requests in which the model was already loaded. - LoadedModelCount – The number of models loaded in the containers in the endpoint. This metric is emitted per instance. The
Averagestatistic with a period of 1 minute tells you the average number of models loaded per instance, and theSumstatistic tells you the total number of models loaded across all instances in the endpoint. The models that this metric tracks are not necessarily unique because you can load a model in multiple containers in the endpoint.
You can use CloudWatch charts to help make ongoing decisions on the optimal choice of instance type, instance count, and number of models that a given endpoint should host. For example, the following chart shows the increasing number of models loaded and a corresponding increase to the cache hit rate.
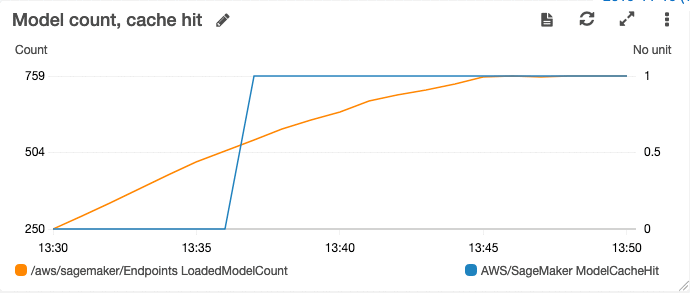
In this case, the cache hit rate started at 0 when no models had been loaded. As the number of models loaded increases, the cache hit rate eventually hits 100%.
Matching your endpoint configuration to your use case
Choosing the right endpoint configuration for an Amazon SageMaker endpoint, particularly the instance type and number of instances, depends heavily on the requirements of your specific use case. This is also true for multi-model endpoints. The number of models that you can hold in memory depends on the configuration of your endpoint (such as instance type and count), the profile of your models (such as model size and model latency), and the traffic patterns. You should configure your multi-model endpoint and right-size your instances by considering all these factors and also set up automatic scaling for your endpoint.
Amazon SageMaker multi-model endpoints fully support automatic scaling. The invocation rates used to trigger an autoscale event are based on the aggregate set of predictions across the full set of models an endpoint serves.
In some cases, you may opt to reduce costs by choosing an instance type that cannot hold all the targeted models in memory at the same time. Amazon SageMaker unloads models dynamically when it runs out of memory to make room for a newly-targeted model. For infrequently requested models, the dynamic load latency can still meet the requirements. In cases with more stringent latency needs, you may opt for larger instance types or more instances. Investing time up front to do proper performance testing and analysis pays excellent dividends in successful production deployments.
Conclusion
Amazon SageMaker multi-model endpoints help you deliver high-performance machine learning solutions at the lowest possible cost. You can significantly lower your inference costs by bundling sets of similar models behind a single endpoint that you can serve using a single shared serving container. Similarly, Amazon SageMaker gives you managed spot training to help with training costs, and integrated support for Amazon Elastic Inference for deep learning workloads. You can boost the bottom-line impact of your ML teams by adding these to the significant productivity improvements Amazon SageMaker delivers.
Give multi-model endpoints a try, and share your feedback and questions in the comments.
About the authors
 Mark Roy is a Machine Learning Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Mark loves to play, coach, and follow basketball.
Mark Roy is a Machine Learning Specialist Solution Architect, helping customers on their journey to well-architected machine learning solutions at scale. In his spare time, Mark loves to play, coach, and follow basketball.
 Urvashi Chowdhary is a Principal Product Manager for Amazon SageMaker. She is passionate about working with customers and making machine learning more accessible. In her spare time, she loves sailing, paddle boarding, and kayaking.
Urvashi Chowdhary is a Principal Product Manager for Amazon SageMaker. She is passionate about working with customers and making machine learning more accessible. In her spare time, she loves sailing, paddle boarding, and kayaking.