Machine learning (ML) is one of the fastest growing areas in technology and a highly sought after skillset in today’s job market. Today, I am excited to announce a new education course, built in collaboration with Coursera, to help you build your ML skills: Getting started with AWS Machine Learning. You can access the course content for free now on the Coursera website.
The World Economic Forum [1] states that the growth of artificial intelligence (AI) could create 58 million net new jobs in the next few years, yet, it’s estimated that there are currently 300,000 AI engineers worldwide, but millions are needed [2]. This means that there is a unique and immediate opportunity to for you to get started learning the essential ML concepts that are used to build AI applications – no matter what your skill level. Learning the foundations of ML now will help you keep pace with this growth, expand your skills, and even help advance your career.
Based on the same ML courses used to train engineers at Amazon, this course teaches you how to get started with AWS Machine Learning. Key topics include: Machine Learning on AWS, Computer Vision on AWS, and Natural Language Processing (NLP) on AWS. Each topic consists of several modules deep-diving into a variety of ML concepts, AWS services, as well as insights from experts to put the concepts into practice. This course is a great start to build your foundational knowledge on Machine Learning before diving in deeper with the AWS Machine Learning Certification.
How it Works
You can read and view the course content for free on Coursera. If you want to access assessments, take graded assignments, and get a post course certificate, it costs $49 in the USA and $29 in Brazil, Russia, Mexico, and India. If you choose the paid route, when you complete the course, you’ll get an electronic Certificate that you can print and even add to your LinkedIn profile to showcase your new found machine learning knowledge.
Enroll now to build your skills towards becoming an ML developer!
About the Author
Tara Shankar Jana is a Senior Product Marketing Manager for AWS Machine Learning. Currently he is working on building unique and scalable educational offerings for the aspiring ML developer communities- to help them expand their skills on ML. Outside of work he loves reading books, travelling and spending time with his family.
The center of the AI ecosystem shifts to D.C. this fall, when the GPU Technology Conference arrives at the Reagan Center in Washington, from Nov. 4-6.
GTC DC will bring together some 3,000 attendees from government and industry for three days of networking and more than 100 sessions, including presentations, panel talks and workshops focused on implementing AI in government and business.
Here are five of the top reasons to attend:
Keynote
Ian Buck, vice president of accelerated computing at NVIDIA, will be giving this year’s keynote at GTC DC.
This is a rare chance to receive concrete advice on how organizations can use AI to boost competitiveness and improve services from the man who invented CUDA, the world’s leading platform for accelerated parallel computing.
Buck has devoted his career to helping many of the world’s leading organizations accelerate critical compute workloads. He’s testified before Congress on AI and advised the White House.
100+ Sessions
Leading thinkers from the White House Office of Science and Technology, National Institute of Standards and Technology, NASA Langley Research Center, the Pacific Northwest National Laboratory and more will be discussing their technology and the future of AI in a series of over 100 sessions.
With a heavy focus on autonomous machines, cybersecurity and disaster relief, there will be panels on “The National AI Strategy: What’s Happening, What to Expect and How to Engage” and “AI and Cybersecurity: Opportunities and Threats to Businesses, Government and Individuals,” among others.
A few of the confirmed speakers include:
Suzette Kent, U.S. chief information officer — U.S. Office of Management and Budget
Lynne E. Parker, assistant director for AI — White House Office of Science and Technology Policy
Gregg Cohen, CTO and staff scientist — National Institutes of Health
Elham Tabassi, chief of staff in the Information Technology Laboratory — National Institute of Standards and Technology
Kimberly Powell, vice president of healthcare — NVIDIA
Sertac Karaman, associate professor of aeronautics and astronautics — MIT
John Ferguson, CEO — Deepwave Digital
Joshua Patterson, director of AI infrastructure — NVIDIA
Moira Bergin, subcommittee director — U.S. House of Representatives Committee on Homeland Security
Exhibits
GTC DC won’t be all talk and no action, though — attendees will have access to demos of the latest innovations in AI. Over 50 companies will be exhibiting their technology in AI, robotics and high performance computing, including Booz Allen Hamilton, Lockheed Martin and Dell.
NVIDIA will demonstrate its RTX-powered lunar landing demo, which stole the show at SIGGRAPH earlier this year.
A celebration of the Apollo 11 moon landing, the demo uses a single camera to capture a participant’s movement and match it using AI pose estimation technology to a 3D-rendered astronaut in real time.
Also in the spotlight will be NVIDIA Clara AI, in a demo called “Enhancing Radiology with Cinematic Rendering and AI.” Clara uses NVIDIA GPUs and AI to enable views of the body that traditional medical imaging techniques cannot produce. These cinematic 3D renderings of medical images can transform the way we diagnose and recommend treatment.
Training
GTC DC is offering both AI beginners and experts the chance to work on their skills with seven day-long NVIDIA Deep Learning Institute workshops that will take place on Nov. 4. Led by certified DLI instructors, participants can earn a certificate of competency by completing the built-in assessment at the end of each session. Workshops include: “Getting Started with AI on Jetson Nano,” “Deep Learning for Intelligent Video Analytics” and “Deep Learning for Healthcare Image Analysis.”
There will also be dozens of two-hour hands-on training sessions throughout GTC DC. Instructors will train participants in the application of data science and accelerated computing to address the most difficult governmental and industrial challenges. Popular sessions available for registration are “Accelerating Data Science Workflows with RAPIDS” and “Introduction to CUDA Python with Numba.”
Networking
For many, the biggest benefit of GTC DC is being able to talk with a unique cross-section of technical experts, elected representatives, agency and department heads, staffers, corporate executives and academic leaders.
Attendees can engage with representatives from the White House, Department of Energy, Oak Ridge National Laboratory, Microsoft, Carnegie Mellon University, Amazon Web Services and many others in government, research and business.
The conference also hosts an annual Women in AI breakfast, bringing together women speakers from a variety of industries and research fields.
After hours, evening receptions offer attendees the chance to continue networking.
To see all of this and more, come join us at GTC DC from Nov. 4 to Nov. 6.
Sella Nevo, Senior Software Engineer, Google Research, Tel Aviv
Several years ago, we identified flood forecasts as a unique opportunity to improve people’s lives, and began looking into how Google’s infrastructure and machine learning expertise can help in this field. Last year, we started our flood forecasting pilot in the Patna region, and since then we have expanded our flood forecasting coverage, as part of our larger AI for Social Good efforts. In this post, we discuss some of the technology and methodology behind this effort.
The Inundation Model A critical step in developing an accurate flood forecasting system is to develop inundation models, which use either a measurement or a forecast of the water level in a river as an input, and simulate the water behavior across the floodplain.
A 3D visualization of a hydraulic model simulating various river conditions.
This allows us to translate current or future river conditions, to highly spatially accurate risk maps – which tell us what areas will be flooded and what areas will be safe. Inundation models depend on four major components, each with its own challenges and innovations:
Real-time Water Level Measurements To run these models operationally, we need to know what is happening on the ground in real-time, and thus we rely on partnerships with the relevant government agencies to receive timely and accurate information. Our first governmental partner is the Indian Central Water Commission (CWC), which measures water levels hourly in over a thousand stream gauges across all of India, aggregates this data, and produces forecasts based on upstream measurements. The CWC provides these real-time river measurements and forecasts, which are then used as inputs for our models.
CWC employees measuring water level and discharge near Lucknow, India.
Elevation Map Creation Once we know how much water is in a river, it is critical that the models have a good map of the terrain. High-resolution digital elevation models (DEMs) are incredibly useful for a wide range of applications in the earth sciences, but are still difficult to acquire in most of the world, especially for flood forecasting. This is because meter-wide features of the ground conditions can create a critical difference in the resulting flooding (embankments are one exceptionally important example), but publicly accessible global DEMs have resolutions of tens of meters. To help address this challenge, we’ve developed a novel methodology to produce high resolution DEMs based on completely standard optical imagery.
We start with the large and varied collection of satellite images used in Google Maps. Correlating and aligning the images in large batches, we simultaneously optimize for satellite camera model corrections (for orientation errors, etc.) and for coarse terrain elevation. We then use the corrected camera models to create a depth map for each image. To make the elevation map, we optimally fuse the depth maps together at each location. Finally, we remove objects such as trees and bridges so that they don’t block water flow in our simulations. This can be done manually or by training convolutional neural networks that can identify where the terrain elevations need to be interpolated. The result is a roughly 1 meter DEM, which can be used to run hydraulic models.
Hydraulic Modeling Once we have both these inputs – the riverine measurements and forecasts, and the elevation map – we can begin the modeling itself, which can be divided into two main components. The first and most substantial component is the physics-based hydraulic model, which updates the location and velocity of the water through time based on (an approximated) computation of the laws of physics. Specifically, we’ve implemented a solver for the 2D form of the shallow-water Saint-Venant equations. These models are suitably accurate when given accurate inputs and run at high resolutions, but their computational complexity creates challenges – it is proportional to the cube of the resolution desired. That is, if you double the resolution, you’ll need roughly 8 times as much processing time. Since we’re committed to the high-resolution required for highly accurate forecasts, this can lead to unscalable computational costs, even for Google!
To help address this problem, we’ve created a unique implementation of our hydraulic model, optimized for Tensor Processing Units (TPUs). While TPUs were optimized for neural networks (rather than differential equation solvers like our hydraulic model), their highly parallelized nature leads to the performance per TPU core being 85x times faster than the performance per CPU core. For additional efficiency improvements, we’re also looking at using machine learning to replace some of the physics-based algorithmics, extending data-driven discretization to two-dimensional hydraulic models, so we can support even larger grids and cover even more people.
A snapshot of a TPU-based simulation of flooding in Goalpara, mid-event.
As mentioned earlier, the hydraulic model is only one component of our inundation forecasts. We’ve repeatedly found locations where our hydraulic models are not sufficiently accurate – whether that’s due to inaccuracies in the DEM, breaches in embankments, or unexpected water sources. Our goal is to find effective ways to reduce these errors. For this purpose, we added a predictive inundation model, based on historical measurements. Since 2014, the European Space Agency has been operating a satellite constellation named Sentinel-1 with C-band Synthetic-Aperture Radar (SAR) instruments. SAR imagery is great at identifying inundation, and can do so regardless of weather conditions and clouds. Based on this valuable data set, we correlate historical water level measurements with historical inundations, allowing us to identify consistent corrections to our hydraulic model. Based on the outputs of both components, we can estimate which disagreements are due to genuine ground condition changes, and which are due to modeling inaccuracies.
Flood warnings across Google’s interfaces.
Looking Forward We still have a lot to do to fully realize the benefits of our inundation models. First and foremost, we’re working hard to expand the coverage of our operational systems, both within India and to new countries. There’s also a lot more information we want to be able to provide in real time, including forecasted flood depth, temporal information and more. Additionally, we’re researching how to best convey this information to individuals to maximize clarity and encourage them to take the necessary protective actions.
Computationally, while the inundation model is a good tool for improving the spatial resolution (and therefore the accuracy and reliability) of existing flood forecasts, multiple governmental agencies and international organizations we’ve spoken to are concerned about areas that do not have access to effective flood forecasts at all, or whose forecasts don’t provide enough lead time for effective response. In parallel to our work on the inundation model, we’re working on some basic research into improved hydrologic models, which we hope will allow governments not only to produce more spatially accurate forecasts, but also achieve longer preparation time.
Hydrologic models accept as inputs things like precipitation, solar radiation, soil moisture and the like, and produce a forecast for the river discharge (among other things), days into the future. These models are traditionally implemented using a combination of conceptual models approximating different core processes such as snowmelt, surface runoff, evapotranspiration and more.
The core processes of a hydrologic model. Designed by Daniel Klotz, JKU Institute for Machine Learning.
These models also traditionally require a large amount of manual calibration, and tend to underperform in data scarce regions. We are exploring how multi-task learning can be used to address both of these problems — making hydrologic models both more scalable, and more accurate. In research collaboration with JKU Institute For Machine Learning group under Sepp Hochreiter on developing ML-based hydrologic models, Kratzert et al. show how LSTMs perform better than all benchmarked classic hydrologic models.
The distribution of NSE scores on basins across the United States for various models, showing the proposed EA-LSTM consistently outperforming a wide range of commonly used models.
Though this work is still in the basic research stage and not yet operational, we think it is an important first step, and hope it can already be useful for other researchers and hydrologists. It’s an incredible privilege to take part in the large eco-system of researchers, governments, and NGOs working to reduce the harms of flooding. We’re excited about the potential impact this type of research can provide, and look forward to where research in this field will go.
Acknowledgements There are many people who contributed to this large effort, and we’d like to highlight some of the key contributors: Aaron Yonas, Adi Mano, Ajai Tirumali, Avinatan Hassidim, Carla Bromberg, Damien Pierce, Gal Elidan, Guy Shalev, John Anderson, Karan Agarwal, Kartik Murthy, Manan Singhi, Mor Schlesinger, Ofir Reich, Oleg Zlydenko, Pete Giencke, Piyush Poddar, Ruha Devanesan, Slava Salasin, Varun Gulshan, Vova Anisimov, Yossi Matias, Yi-fan Chen, Yotam Gigi, Yusef Shafi, Zach Moshe and Zvika Ben-Haim.
Great processors — and great hardware — won’t be enough to propel the AI revolution forward, Ian Buck, vice president and general manager of NVIDIA’s accelerated computing business, said Wednesday at the AI Hardware Summit.
“We’re bringing AI computing way down in cost, way up in capability and I fully expect this trend to continue not just as we advance hardware, but as we advance AI algorithms, AI software and AI applications to help drive the innovation in the industry,” Buck told an audience of hundreds of press, analysts, investors and entrepreneurs in Mountain View, Calif.
Buck — known for creating the CUDA computing platform that puts GPUs to work powering everything from supercomputing to next-generation AI — spoke at a showcase for some of the most iconic computers of Silicon Valley’s past at the Computer History Museum.
NVIDIA’s Ian Buck speaking Wednesday at the AI Hardware Summit, in Silicon Valley.
AI Training Is a Supercomputing Challenge
The industry now has to think bigger — much bigger — than the boxes that defined the industry’s past, Buck explained, weaving together software, hardware,and infrastructure designed to create supercomputer-class systems with the muscle to harness huge amounts of data.
Training, or creating new AIs able to tackle new tasks, is the ultimate HPC challenge – exposing every bottleneck in compute, networking, and storage, Buck said.
“Scaling AI training poses some hard challenges, not only do you have to build the fast GPU, but optimize for the full data center as the computer,” Buck said. “You have to build system interconnections, memory optimizations, network topology, numerics.”
That’s why NVIDIA is investing in a growing portfolio of data center software and infrastructure, from interconnect technologies such as NVLink and NVSwitch to NVIDIA Collective Communications Library, or NCCL, which optimizes the way data moves across vast systems.
From ResNet-50 to BERT
Kicking off his brisk, half-hour talk, Buck explained that GPU computing has long served the most demanding users — scientists, designers, artists, gamers. More recently that’s included AI. Initial AI applications focused on understanding images, a capability measured by benchmarks such as ResNet-50.
“Fast forward to today, with models like BERT and Megatron that understand human language – this goes way beyond computer vision but actually intelligence,” Buck said. “When I said something, what did I mean? This is a much more challenging problem, it’s really true intelligence that we’re trying to capture in the neural network.”
To help tackle such problems, NVIDIA yesterday announced the latest version of NVIDIA’s inference platform, TensorRT 6. On the T4 GPU, it runs BERT-Large, a model with super-human accuracy for language understanding tasks, in only 5.8 milliseconds, nearly half the 10 ms threshold for smooth interaction with humans. It’s just one part of our ongoing effort to accelerate the end-to-end pipeline.
Accelerating the Full Workflow
Inference tasks, or putting trained AI models to work, are diverse, and usually part of larger applications application that obeys Amdhahl’s Law — if you accelerate only one piece of the pipeline, for example matrix multipliers, you’ll still be limited by the rest of the processing steps.
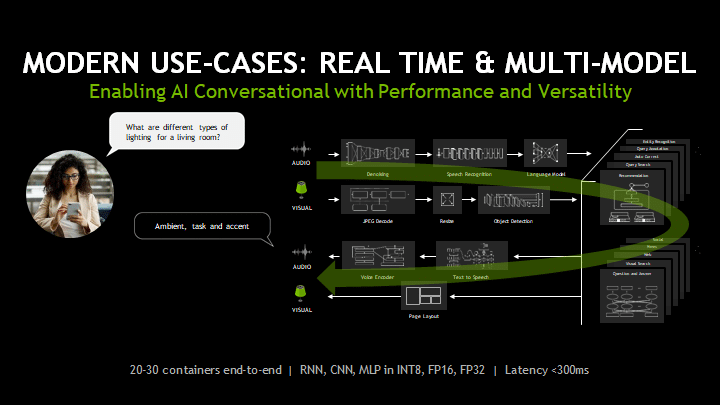
Making an AI that’s truly conversational will require a fully accelerated speech pipeline able to bounce from one crushingly compute-intensive task to another, Buck said.
Such a system could require 20 to 30 containers end to end, harnessing assorted convolutional neural networks and recurrent neural networks made up of multilayer perceptrons working at a mix of precisions, including INT8, FP16 and FP32. All at a latency of less than 300 milliseconds, leaving only 10 ms for a single model.
Data Center TCO Is Driven by Its Utilization
Such performance is vital as investments in data centers will be judged by the amount of utility that can be wrung from their infrastructures, Buck explained. “Total cost of ownership for the hyperscalers is all about utilization,” Buck said. ”NVIDIA having one architecture for all the AI powered use cases drives down the TCO.”
Performance — and flexibility — is why GPUs are already widely deployed in data centers today, Buck said. Consumer internet companies use GPUs to deliver voice search, image search, recommendations, home assistants, news feeds, translations and ecommerce.
Hyperscalers are adopting NVIDIA’s fast, power-efficient T4 GPUs — available on major cloud service providers such as Alibaba, Amazon, Baidu, Google Cloud and Tencent Cloud. And inference is now a double-digit percentage contributor to NVIDIA’s data center revenue.
Vertical Industries Require Vertical Platforms
In addition to delivering supercomputing-class computing power for training, and scalable systems for data centers serving hundreds of millions, AI platforms will need to grow increasingly specialized, Buck said.
Today AI research is concentrated in a handful of companies, but broader industry adoption needs verticalized platform, he continued.
“Who is going to do the work,” of building out all those applications? Buck asked. “We need to build domain-specific, verticalized AI platforms, giving them an SDK that gives them a platform that is already tuned for their use cases,” Buck said.
Buck highlighted how NVIDIA is building verticalized platforms for industries such as automotive, healthcare, robotics, smart cities, and 3D rendering, among others.
Zooming in on the auto industry as an example, Buck touched on a half dozen of the major technologies NVIDIA is developing. They include the NVIDIA Xavier system on a chip, NVIDIA Constellation automotive simulation software, NVIDIA DRIVE IX software for in-cockpit AI and NVIDIA DRIVE AV software to help vehicles safely navigate streets and highways.
Wrapping up, Buck offered a simple takeaway: the combination of AI hardware, AI software, and AI infrastructure promise to make more powerful AI available to more industries and, ultimately, more people
“We’re driving down the cost of computing AI, making it more accessible, allowing people to build powerful AI systems and I predict that cost reduction and improved capability will continue far into the future.”
We’ve all chosen the self-checkout stand over the human cashier, thinking it’ll take less time.
But somehow, things take a terrible turn. The barcodes aren’t scanning, there’s a pop-up scolding you for not placing the product in the bagging area (though you did, of course), and an employee is coming over to fix the chaos.
It would’ve taken less time to go to the cashier.
Focal Systems is applying deep learning and computer vision to automate portions of retail stores to streamline operations and get customers in and out more efficiently, without the pitfalls of the traditional self-checkout.
CEO Francois Chaubard sat down with AI Podcast host Noah Kravitz to talk about how the company is changing retailers.
As labor costs increase, the traditional solution is twofold: automation and human staff reduction. But Chaubard explains that self-checkout systems don’t actually compensate for fewer employees. Instead, “you get more out-of-stocks, because you’ve got less people,” he says.
Focal Systems started by applying AI to a different area of the store: shelves. Chaubard notes that, for store employees, one of the first tasks every day is checking what items are out of stock, and “knowing that answer takes about four hours a day.”
To prevent this, Focal Systems installs small, inexpensive cameras throughout the store, with a focus on high-moving areas like the soda aisle. The cameras “take an image once every half hour” and produce a chart that notes either “in” or “out.”
“Every single hour that you don’t have a product on the shelf is lost sales,” Chaubard emphasizes. This aspect of Focal Systems alerts employees that they need to restock, and helps identify common “out-of-stock hours” so that stores can recognize the pattern and avoid it altogether.
This shelf camera system is already in 11 major retailers across the world.
The other component to Focal Systems is the Focal Scan. While barcode scanning takes three seconds an item, on average, Focal Systems installs a camera on top of the conveyor belt. “You’re just using deep learning and computer vision to detect amongst a hundred thousand different SKUs in 0.1 seconds with 99.9 percent precision recall,” Chaubard explains.
The cashier can just focus on bagging, reducing the total time of the transaction by 60 percent.
Chaubard thinks that the future holds even more automation, but only where it would be cheaper than human labor. “People are hard to beat in certain tasks,” he laughs.
Visit Focal Systems’ website for more information and to find videos of their technology in action.
Help Make the AI Podcast Better
Have a few minutes to spare? Fill out this short listener survey. Your answers will help us make a better podcast.
NVIDIA-developed AI — and NVIDIA GPUs — plays a starring role in the opening this month in New York City of a permanent venue for new media art.
“Machine Hallucination” made its debut this month in the 6,000-square-foot Chelsea Market boiler room — an expansive space beneath the Manhattan landmark’s main concourse.
“People have never seen something like this before. It’s not hyperbole to say it’s the future of cinema,” said Anadol.
These servers — paired with 18 4K projectors — splash stunning digital images based on some of New York’s most iconic architecture across the cavernous space’s brick walls and terracotta ceiling.
The story behind the immersive spectacle involves even more NVIDIA technology.
Starting with more than 110 million images of New York — collected, prepared and sorted by an NVIDIA DGX Station — Anadol modified an NVIDIA-developed deep learning algorithm known as a StyleGAN.
“We wrote a latent space browser, a custom program to work with StyleGAN that has the capacity to animate every layer of the neural network and be able to choose latent coordinates to narrate our AI. Basically, we put a camera inside StyleGAN and allowed us to navigate latent space purposefully,” he said.
The exhibit — the inaugural exhibition for ARCTECHOUSE in New York — runs through Nov. 17. Admission is $24..
Posted by Iulia-Maria Comșa and Krzysztof Potempa, Research Engineers, Google Research, Zürich
The discoveries being made regularly in neuroscience are an ongoing source of inspiration for creating more efficient artificial neural networks that process information in the same way as biological organisms. These networks have recently achieved resounding success in domains ranging from playing board and videogames to fine-grained understanding of video. However, there is one fundamental aspect of biological brains that artificial neural networks are not yet fully leveraging: temporal encoding of information. Preserving temporal information allows a better representation of dynamic features, such as sounds, and enables fast responses to events that may occur at any moment. Furthermore, despite the fact that biological systems can consist of billions of neurons, information can be carried by a single signal (‘spike’) fired by an individual neuron, with information encoded in the timing of the signal itself.
Based on this biological insight, project Ihmehimmeli explores how artificial spiking neural networks can exploit temporal dynamics using various architectures and learning settings. “Ihmehimmeli” is a Finnish tongue-in-cheek word for a complex tool or a machine element whose purpose is not immediately easy to grasp. The essence of this word captures our aim to build complex recurrent neural network architectures with temporal encoding of information. We use artificial spiking networks with a temporal coding scheme, in which more interesting or surprising information, such as louder sounds or brighter colours, causes earlier neuronal spikes. Along the information processing hierarchy, the winning neurons are those that spike first. Such an encoding can naturally implement a classification scheme where input features are encoded in the spike times of their corresponding input neurons, while the output class is encoded by the output neuron that spikes earliest.
The Ihmehimmeli project team holding a himmeli, a symbol for the aim to build recurrent neural network architectures with temporal encoding of information.
We recently published and open-sourced a model in which we demonstrated the computational capabilities of fully connected spiking networks that operate using temporal coding. Our model uses a biologically-inspired synaptic transfer function, where the electric potential on the membrane of a neuron rises and gradually decays over time in response to an incoming signal, until there is a spike. The strength of the associated change is controlled by the “weight” of the connection, which represents the synapse efficiency. Crucially, this formulation allows exact derivatives of postsynaptic spike times with respect to presynaptic spike times and weights. The process of training the network consists of adjusting the weights between neurons, which in turn leads to adjusted spike times across the network. Much like in conventional artificial neural networks, this was done using backpropagation. We used synchronization pulses, whose timing is also learned with backpropagation, to provide a temporal reference to the network.
We trained the network on classic machine learning benchmarks, with features encoded in time. The spiking network successfully learned to solve noisy Boolean logic problems and achieved a test accuracy of 97.96% on MNIST, a result comparable to conventional fully connected networks with the same architecture. However, unlike conventional networks, our spiking network uses an encoding that is in general more biologically-plausible, and, for a small trade-off in accuracy, can compute the result in a highly energy-efficient manner, as detailed below.
While training the spiking network on MNIST, we observed the neural network spontaneously shift between two operating regimes. Early during training, the network exhibited a slow and highly accurate regime, where almost all neurons fired before the network made a decision. Later in training, the network spontaneously shifted into a fast but slightly less accurate regime. This behaviour was intriguing, as we did not optimize for it explicitly. Thus spiking networks can, in a sense, be “deliberative”, or make a snap decision on the spot. This is reminiscent of the trade-off between speed and accuracy in human decision-making.
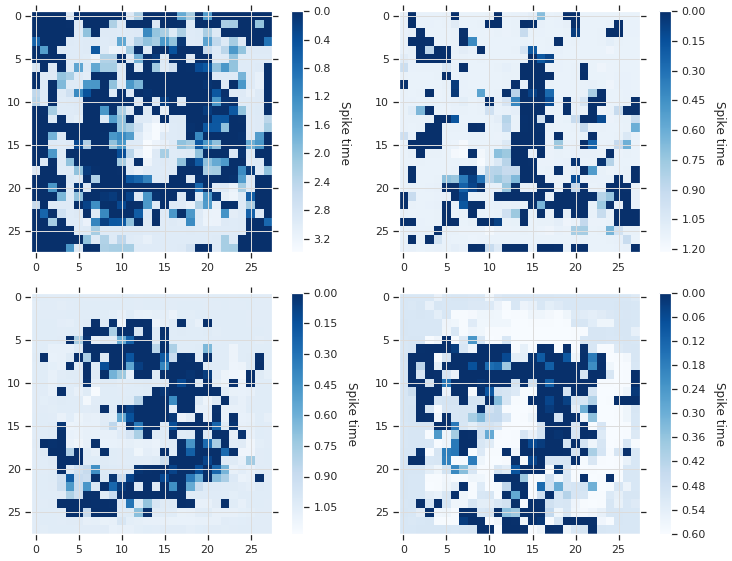
A slow (“deliberative”) network (top) and a fast (“impulsive”) network (bottom) classifying the same MNIST digit. The figures show a raster plot of spike times of individual neurons in individual layers, with synchronization pulses shown in orange. In this example, both networks classify the digit correctly; overall, the “slow” network achieves better accuracy than the “fast” network.
We were also able to recover representations of the digits learned by the spiking network by gradually adjusting a blank input image to maximize the response of a target output neuron. This indicates that the network learns human-like representations of the digits, as opposed to other possible combinations of pixels that might look “alien” to people. Having interpretable representations is important in order to understand what the network is truly learning and to prevent a small change in input from causing a large change in the result.
How the network “imagines” the digits 0, 1, 3 and 7.
This work is one example of an initial step that project Ihmehimmeli is taking in exploring the potential of time-based biology-inspired computing. In other on-going experiments, we are training spiking networks with temporal coding to control the walking of an artificial insect in a virtual environment, or taking inspiration from the development of the neural system to train a 2D spiking grid to predict words using axonal growth. Our goal is to increase our familiarity with the mechanisms that nature has evolved for natural intelligence, enabling the exploration of time-based artificial neural networks with varying internal states and state transitions.
Acknowledgements The work described here was authored by Iulia Comsa, Krzysztof Potempa, Luca Versari, Thomas Fischbacher, Andrea Gesmundo and Jyrki Alakuijala. We are grateful for all discussions and feedback on this work that we received from our colleagues at Google.
Amazon SageMaker is a fully managed platform that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at any scale. When you deploy an ML model, Amazon SageMaker leverages ML hosting instances to host the model and provides an API endpoint to provide inferences. It may also use AWS IoT Greengrass.
However, thanks to Amazon SageMaker’s flexibility, which allows deployment to different targets, there are situations when hosting the model on AWS Lambda can provide some advantages. Not every model can be hosted on AWS Lambda, for instance, when a GPU is needed. Also, there are other limits, like the size of AWS Lambda’s deployment package, which can prevent you from using this method. When using AWS Lambda is possible, this architecture has advantages like lower cost, event triggering, seamless scalability, and spike requests. For example, when the model is small and not often invoked, it may be cheaper to use AWS Lambda.
In this post, I create a pipeline to build, test, and deploy an Lambda function that provides inferences.
Prerequisites
I assume that the reader has experience with Amazon SageMaker, AWS CloudFormation, AWS Lambda, and the AWS Code* suite.
Architecture description
To create the pipeline for CI/CD, use AWS Developer Tools. The suite uses AWS CodeDeploy, AWS CodeBuild, and AWS CodePipeline. Following is a diagram of the architecture:
When I train the model with Amazon SageMaker, the output model is saved into an Amazon S3 bucket. Each time a file is put into the bucket, AWS CloudTrail triggers an Amazon CloudWatch event. This event invokes a Lambda function to check whether the file uploaded is a new model file. It then moves this file to a different S3 bucket. This is necessary because Amazon SageMaker saves other files, like checkpoints, in different folders, along with the model file. But to trigger AWS CodePipeline, there must be a specific file in a specific folder of an S3 bucket.
Therefore, after the model file is moved from the Amazon SageMaker bucket to the destination bucket, AWS CodePipeline is triggered. First, AWS CodePipeline invokes AWS CodeBuild to create three items:
The deployment package of the Lambda function.
The AWS Serverless Application Model (AWS SAM) template to create the API.
The Lambda function to serve the inference.
After this is done, AWS CodePipeline executes the change set to transform the AWS SAM template into an AWS CloudFormation template. When the template executes, AWS CodeDeploy is triggered. AWS CodeDeploy invokes a Lambda function to test whether the Lambda function that was newly created in the latest version of your model is working as expected. If so, AWS CodeDeploy shifts the traffic from the old version to the new version of the Lambda function with the newest version of the model. Then, the deployment is done.
How the Lambda function deployment package is created
In the AWS CloudFormation template that I created to generate the pipelines, I included a section where I indicate how AWS CodeBuild should create this package. I also outlined how to create the AWS SAM template to generate the API and the Lambda function itself.
In the BuildSpec, I use a GitHub repository to download the necessary files. These files are the Lambda function code, the Lambda function checker (which AWS CodeDeploy uses to check whether the new model works as expected), and the AWS SAM template. In addition, AWS CodeBuild copies the latest model.tar.gz file from S3.
To work, the Lambda function also must have Apache MXNet dependencies. The AWS CloudFormation template that you use creates a Lambda layer that contains the MXNet libraries necessary to run inferences in Lambda. I have not created a pipeline to build the layer, as that isn’t the focus of this post. You can find the steps I used to compile MXNet from Lambda in the following section.
Testing the pipeline
Before proceeding, create a new S3 bucket into which to move the model file:
In the S3 console, choose Create bucket.
For Bucket Name, enter a custom name.
For Region, choose the Region in which to create the pipeline and choose Next.
Enable versioning by selecting Keep all versions of an object in the same bucket and choose Next.
Choose Create bucket.
In this bucket, add three files:
An empty file in a zip file called empty.zip. This is necessary because AWS CodeBuild must receive a file when invoked in order to work—although, you do not use this file in this case.
The zip function, which copies the file from the Amazon SageMaker bucket to the AWS CodePipeline triggering bucket.
To upload these files:
Open the S3
Choose your bucket.
On the Upload page, click on Add files and select the zip file.
Choose Next until you can select Upload.
Now that you have created this new bucket, you can launch the AWS CloudFormation template after downloading the template.
Open the AWS CloudFormation
Choose Create Stack.
For Choose a template, select Upload a template to Amazon S3 and select the file.
Choose Next.
Add a Stack name.
Change SourceS3Bucket to the bucket name you have previously created.
Choose Next, then Next
Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
Choose Create.
This creates the pipeline on your behalf and deploys everything necessary. When you train the model in Amazon SageMaker, you must indicate that the S3 bucket created by your AWS CloudFormation template is the bucket in which you should host the output model. To find the name of your S3 bucket:
Open the AWS CloudFormation
Select your Stack Name.
Choose Resources and find ModelS3Location.
To simulate that a new model has been trained by Amazon SageMaker and uploaded to S3, download a model that I previously trained and uploaded here on GitHub.
After that’s downloaded, you can upload the file to the S3 bucket that you created. The model has been trained from the SMS Spam Collection dataset provided by the University of California. You can also view the workshop from re:Invent 2018 that covers how to train this model. This simple dataset was trained with a neural network using Gluon, based on Apache MXNet.
Open the S3
Choose your ModelS3Location bucket.
Choose Upload, Add files, and select the zip file.
Choose Next, and choose Upload.
From the AWS CodeDeploy console, you should be able to see that the process has been initiated, as shown in the following image.
After the process has been completed, you can see that a new AWS CloudFormation stack called AntiSpamAPI has been created. As previously explained, this new stack has created the Lambda function and the API to serve the inference. You can invoke the endpoint directly. First, find the endpoint URL.
In the AWS CloudFormation console, choose your AntiSpamAPI.
Choose Resources and find ServerlessRestApi.
Choose the ServerlessRestApi resource, which opens the API Gateway console.
From the API Gateway console, select AntiSpamAPI.
Choose Stages, Prod.
Copy the Invoke URL.
After you have the endpoint URL, you can test it using this simple page that I’ve created:
For example, you can determine that the preceding sentence has a 99% probability of being spam, as you can see from the raw output.
Conclusion
I hope this post proves useful for understanding how you can automatically deploy your model into a Lambda function using AWS developer tools. Having a pipeline can reduce the overhead associated with using a model with a serverless architecture. With minor changes, you can use this pipeline to deploy a model that can be trained anywhere, like Amazon Deep Learning AMIs, AWS Deep Learning Containers, or on premises.
If you have questions or suggestions, please share them on GitHub or in the comments.
About the Author
Diego Natali is a solutions architect for Amazon Web Services in Italy. With several years engineering background, he helps ISV and Start up customers designing flexible and resilient architectures using AWS services. In his spare time he enjoys watching movies and riding his dirt bike.


 Tara Shankar Jana is a Senior Product Marketing Manager for AWS Machine Learning. Currently he is working on building unique and scalable educational offerings for the aspiring ML developer communities- to help them expand their skills on ML. Outside of work he loves reading books, travelling and spending time with his family.
Tara Shankar Jana is a Senior Product Marketing Manager for AWS Machine Learning. Currently he is working on building unique and scalable educational offerings for the aspiring ML developer communities- to help them expand their skills on ML. Outside of work he loves reading books, travelling and spending time with his family.
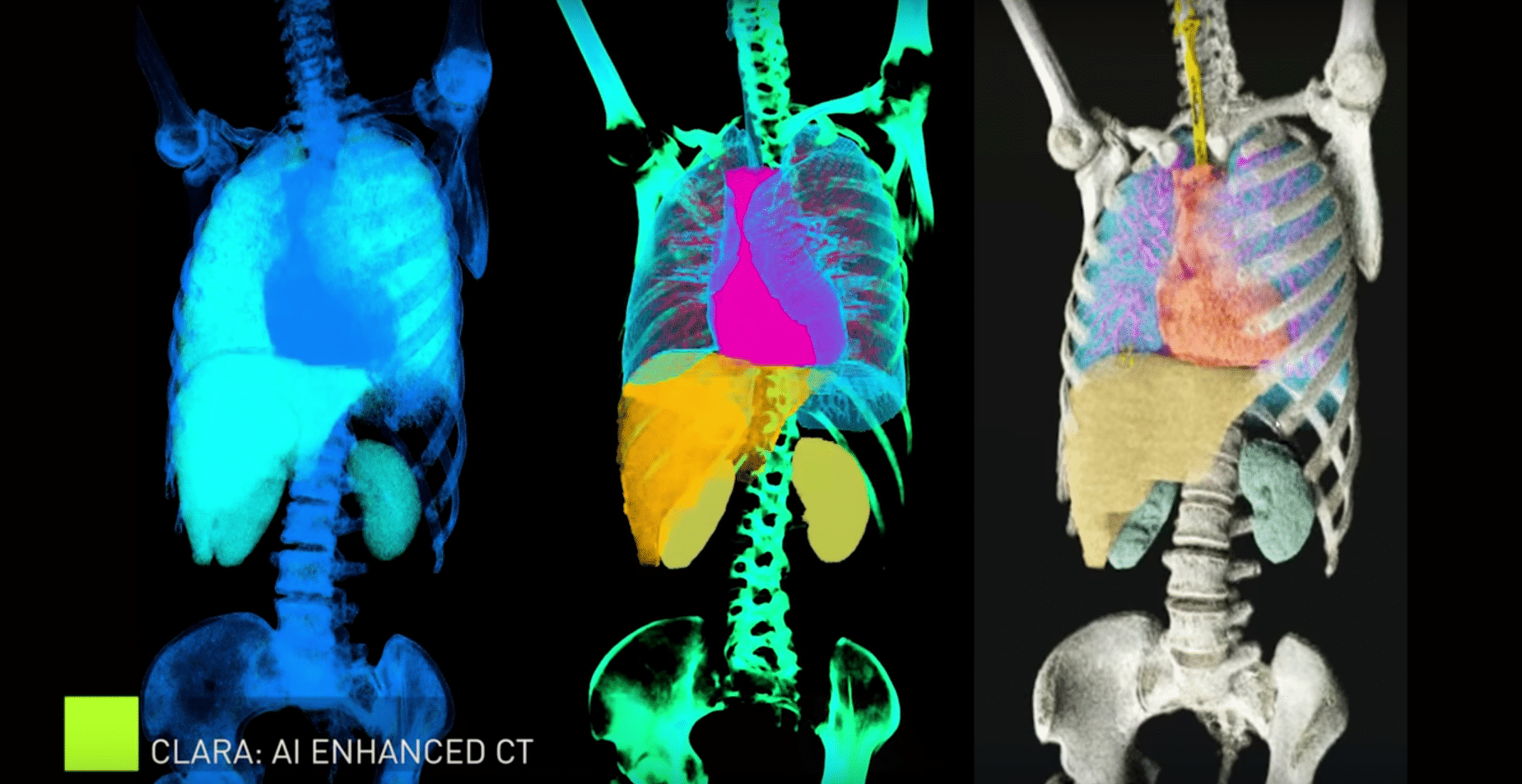

















 Diego Natali is a solutions architect for Amazon Web Services in Italy. With several years engineering background, he helps ISV and Start up customers designing flexible and resilient architectures using AWS services. In his spare time he enjoys watching movies and riding his dirt bike.
Diego Natali is a solutions architect for Amazon Web Services in Italy. With several years engineering background, he helps ISV and Start up customers designing flexible and resilient architectures using AWS services. In his spare time he enjoys watching movies and riding his dirt bike.