Vision and Language Group, a deep learning group at IIT Roorkee, has made a list of topics of DL with resources which one should be familiar with, and that could come in handy before interviews for briefing up.
Feel free to contribute any amazing resources that have been useful for a quick prep before your interviews, and star the repo if it is helpful to you!
Posted by Neil Houlsby, Research Scientist and Xiaohua Zhai, Research Engineer, Google Research, Zürich
Deep learning has revolutionized computer vision, with state-of-the-art deep networks learning useful representations directly from raw pixels, leading to unprecedented performance on many vision tasks. However, learning these representations from scratch typically requires hundreds of thousands of training examples. This burden can be reduced by using pre-trained representations, which have become widely available through services such as TensorFlow Hub (TF Hub) and PyTorch Hub. But their ubiquity can itself be a hindrance. For example, for the task of extracting features from images, there can be over 100 models from which to choose. It is hard to know which methods provide the best representations, since different sub-fields use different evaluation protocols, which do not always reflect the final performance on new tasks.
The overarching goal of representation research is to learn representations a single time on large amounts of generic data without the need to train them from scratch for each task, thus reducing data requirements across all vision tasks. But in order to reach that goal, the research community must have a uniform benchmark against which existing and future methods can be evaluated.
To address this problem, we are releasing “The Visual Task Adaptation Benchmark” (VTAB, available on GitHub), a diverse, realistic, and challenging representation benchmark based on one principle — a better representation is one that yields better performance on unseen tasks, with limited in-domain data. Inspired by benchmarks that have driven progress in other fields of machine learning (ML), such as ImageNet for natural image classification, GLUE for Natural Language Processing, and Atari for reinforcement learning, VTAB follows similar guidelines: (i) minimal constraints on solutions to encourage creativity; (ii) a focus on practical considerations; and (iii) challenging tasks for evaluation.
The Benchmark VTAB is an evaluation protocol designed to measure progress towards general and useful visual representations, and consists of a suite of evaluation vision tasks that a learning algorithm must solve. These algorithms may use pre-trained visual representations to assist them and must satisfy only two requirements:
i) They must not be pre-trained on any of the data (labels or input images) used in the downstream evaluation tasks.ii) They must not contain hardcoded, task-specific, logic. Alternatively put, the evaluation tasks must be treated like a test set — unseen.
These constraints ensure that solutions that are successful when applied to VTAB will be able to generalize to future tasks.
The VTAB protocol begins with the application of an algorithm (A) to a number of independent tasks, drawn from a broad distribution of vision problems. The algorithm may be pre-trained on upstream data to yield a model that contains visual representations, but it must also define an adaptation strategy that consumes a small training set for each downstream task and return a model that makes task-specific predictions. The algorithm’s final score is its average test score across tasks.
The VTAB protocol. Algorithm A is applied to many tasks T, drawn from a broad distribution of vision problems PT. In the example, pet classification, remote sensing, and maze localization are shown.
VTAB includes 19 evaluation tasks that span a variety of domains, divided into three groups — natural, specialized, and structured. Natural image tasks include images of the natural world captured through standard cameras, representing generic objects, fine-grained classes, or abstract concepts. Specialized tasks utilize images captured using specialist equipment, such as medical images or remote sensing. The structured tasks often derive from artificial environments that target understanding of specific changes between images, such as predicting the distance to an object in a 3D scene (e.g., DeepMind Lab), counting objects (e.g., CLEVR), or detecting orientation (e.g., dSprites for disentangled representations).
While highly diverse, all of the tasks in VTAB share one common feature — people can solve them relatively easily after training on just a few examples. To assess algorithmic generalization to new tasks with limited data, performance is evaluated using only 1000 examples per task. Evaluation using the full dataset can be performed for comparison with previous publications.
Findings Using VTAB We performed a large scale study testing a number of popular visual representation learning algorithms against VTAB. The study included generative models (GANs and VAEs), self-supervised models, semi-supervised models and supervised models. All of the algorithms were pre-trained on the ImageNet dataset. We also compared each of these approaches using no pre-trained representations, i.e., training “from-scratch”. The figure below summarizes the main pattern of results.
Performance of different classes of representation learning algorithms across different task groups: natural, specialized and structured. Each bar shows the average performance of all methods in that class across all tasks in the group.
Overall we find that generative models do not perform as well as the other methods, even worse than from-scratch training. However, self-supervised models perform much better, significantly outperforming from-scratch training. Better still is supervised learning using the ImageNet labels. Interestingly, while supervised learning is significantly better on the Natural group of tasks, self-supervised learning is close on the other two groups whose domains are more dissimilar to ImageNet.
The best performing representation learning algorithm, of those we tested, is S4L, which combines both supervised and self-supervised pre-training losses. The figure below contrasts S4L with standard supervised ImageNet pre-training. S4L appears to improve performance particularly on the Structured tasks. However, representation learning yields a much smaller benefit over training from-scratch groups other than the Natural tasks, indicating that there is much progress required to attain a universal visual representation.
Top: Performance of S4L versus from-scratch training. Each bar corresponds to a task. Positive-valued bars indicate tasks where S4L outperforms from-scratch. Negative bars indicate that from-scratch performed better. Bottom: S4L versus Supervised training on ImageNet. Positive bars indicate that S4L performs better. The bar colour indicates the task group: Red=Natural, Green=Specialized, Blue=Structured. We can see that additional self-supervision tends to help on structured tasks beyond just using ImageNet labels.
Summary The code to run VTAB is available on GitHub, including the 19 evaluation datasets and exact data splits. Having a publicly available set of benchmarks ensures the reproducibility of results. Progress is tracked with the public leaderboard, and the models evaluated are uploaded to TF Hub for public use and reproduction. A shell script is provided to perform adaptation and evaluation on all the tasks, with a standardized evaluation protocol making VTAB readily accessible across the industry. Since VTAB can be executed on both TPU and GPU, it is highly efficient. One can obtain comparable results with a single NVIDIA Tesla P100 accelerator in a few hours.
The Visual Task Adaptation Benchmark has helped us better understand which visual representations generalize to the broad spectrum of vision tasks, and provides direction for future research. We hope these resources are useful in driving progress toward general and practical visual representations, and as a result, affords deep learning to the long tail of vision problems with limited labelled data.
Acknowledgements The core team behind this work includes Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, Lucas Beyer, Olivier Bachem, Michael Tschannen, Marcin Michalski, Olivier Bousquet, and Sylvain Gelly.
The thing is, Model1 and Model2 predict on different values (e.g. Male vs Female). I tried using the SQLTransformer to filter the data on each type, but I drop everything, so the output of Model1 throws away all the data I need to predict in Model2.
Is there a way to filter data to be fed into Model1, then filter data to be fed into Model2, and then concatenate the dataframes to be returned?
We wanted to share with you all about some embedded and low-cost hardware we’ve been working on that combines disparity depth and AI via Intel’s Myriad X VPU. We’ve developed a SoM that’s not much bigger than a US quarter which takes direct image inputs from 3 cameras (2x OV9282, 1x IMX378), processes it, and spits the result back to the host via USB3.1.
We wanted disparity + AI so we could get object localization outputs – an understanding of where and what objects are in our field of view, and we wanted this done fast, with as little latency as possible. Oh, and at the edge. And for low power. Our ultimate goal is actually to develop a rear-facing AI vision system that will alert cyclists of potential danger from distracted drivers. An ADAS for bikes!
There are some Myriad X solutions on the market already, but most use PCIe, so the data pipeline isn’t as direct as Sensor–>Myriad–>Host, and the existing solutions also don’t offer a three camera solution for RGBd. So, we built it!
Hope the shameless plug is OK here (sorry mods!), and if anyone has any questions or comments, we’d love to hear it!
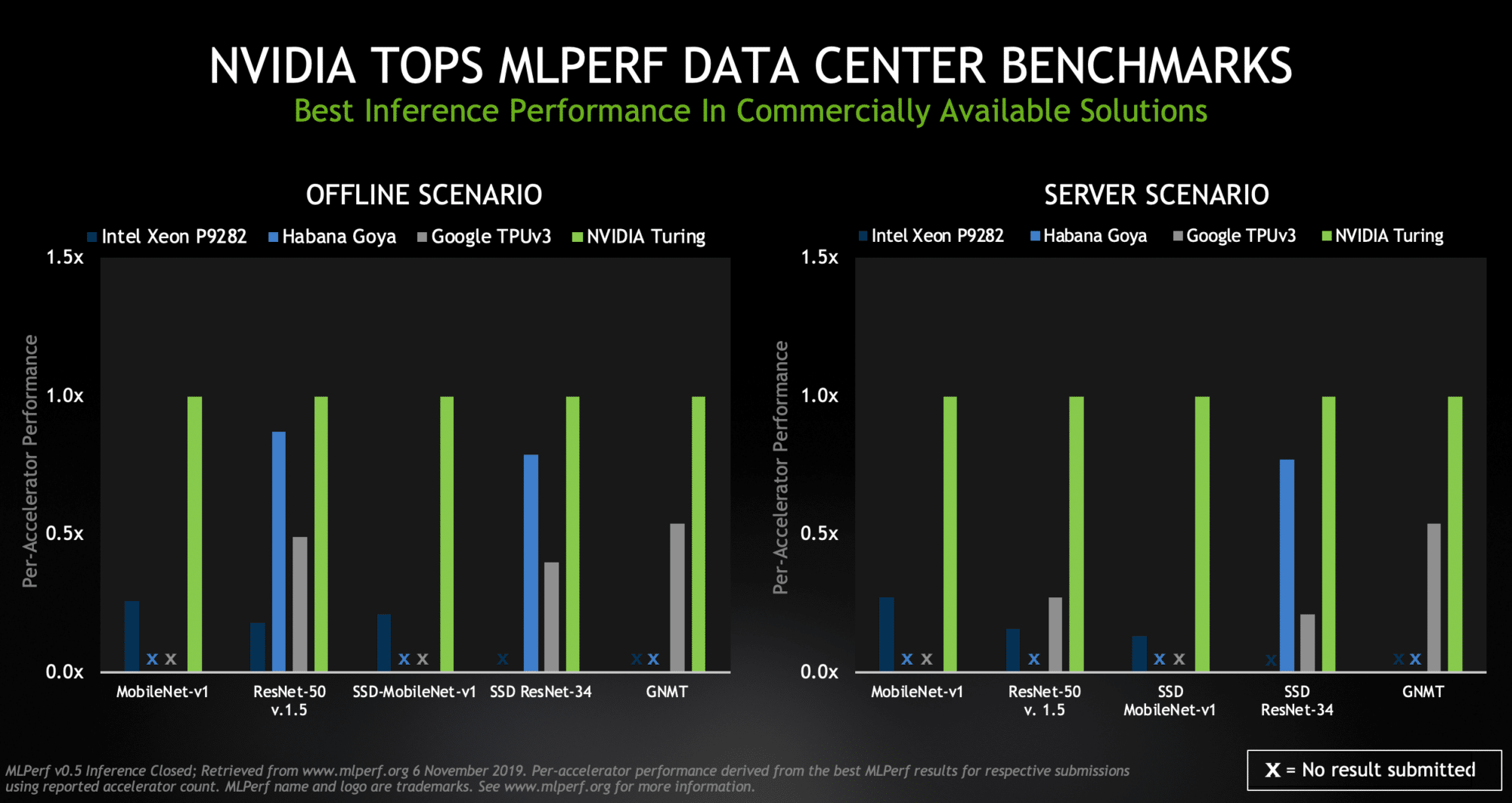
Those who are keeping score in AI know that NVIDIA GPUs set the performance standards for training neural networks in data centers in December and again in July. Industry benchmarks released today show we’re setting the pace for running those AI networks in and outside data centers, too.
NVIDIA Turing GPUs and our Xavier system-on-a-chip posted leadership results in MLPerf Inference 0.5, the first independent benchmarks for AI inference. Before today, the industry was hungry for objective metrics on inference because its expected to be the largest and most competitive slice of the AI market.
Among a dozen participating companies, only the NVIDIA AI platform had results across all five inference tests created by MLPerf, an industry benchmarking group formed in May 2018. That’s a testament to the maturity of our CUDA-X AI and TensorRT software. They ease the job of harnessing all our GPUs that span uses from data center to the edge.
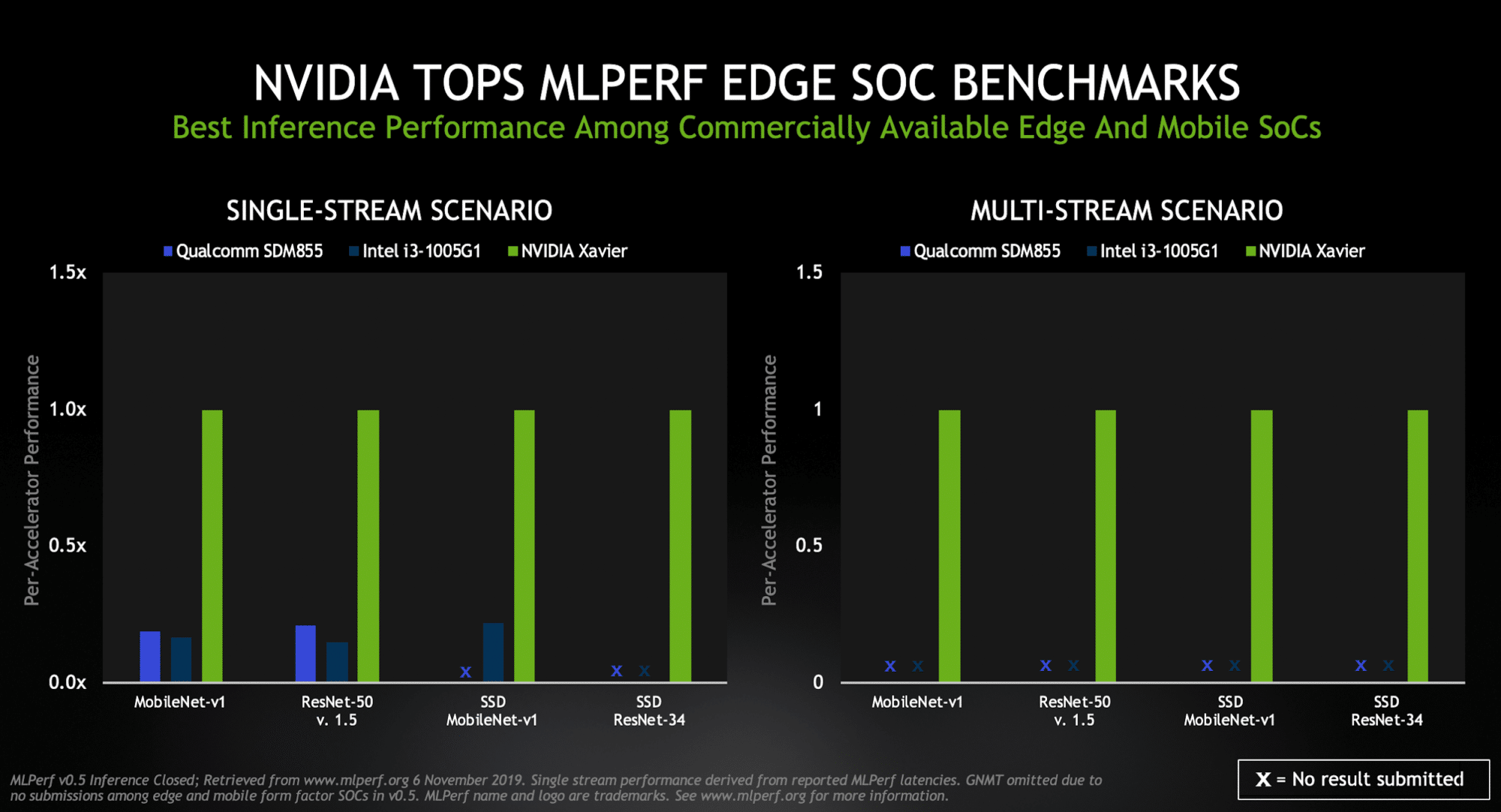
MLPerf defined five inference benchmarks that cover three established AI applications — image classification, object detection and translation. Each benchmark has four aspects. Server and offline scenarios are most relevant for data center uses cases, while single- and multi-stream scenarios speak to the needs of edge devices and SoCs.
NVIDIA topped all five benchmarks for both data center scenarios (offline and server), with Turing GPUs providing the highest performance per processor among commercially available products.
NVIDIA Turing topped among the commercially available processors in MLPerf scenarios geared for the data center.1
The offline scenario represents data center tasks such as tagging photos, where all the data is available locally. The server scenario reflects jobs such as online translation services, where data and requests are arriving randomly in bursts and lulls.
For its part, Xavier ranked as the highest performer under both edge-focused scenarios (single- and multi-stream) among commercially available edge and mobile SoCs.
An industrial inspection camera identifying defects in a fast-moving production line is a good example of a single-stream task. The multi-stream scenario tests how many feeds a chip can handle — a key capability for self-driving cars that might use a half-dozen cameras or more.
NVIDIA’s Xavier topped the group of commercially available edge and mobile SoCs in MLPerf scenarios geared for the edge.2
The results reveal the power of our CUDA and TensorRT software. They provide a common platform that enables us to show leadership results across multiple products and use cases, a capability unique to NVIDIA.
We competed in data center scenarios with two GPUs. Our TITAN RTX demonstrated the full potential of our Turing-class GPUs, especially in demanding tasks such as running a GNMT model used for language translation.
The versatile and widely used NVIDIA T4 Tensor Core GPU showed strong results across several scenarios. These 70-watt GPUs are designed to easily fit into any server with PCIe slots, enabling users to expand their computing power as needed for inference jobs known to scale well.
MLPerf has broad backing from industry and academia. Its members include Arm, Facebook, Futurewei, General Motors, Google, Harvard University, Intel, MediaTek, Microsoft, NVIDIA and Xilinx. To its credit, the new benchmarks attracted significantly more participants than two prior training competitions.
NVIDIA demonstrated its support for the work by submitting results in 19 of 20 scenarios, using three products in a total of four configurations. Our partner Dell EMC and our customer Alibaba also submitted results using NVIDIA GPUs. Together, we gave users a broader picture of the potential of our product portfolio than any other participant.
Fresh Perspectives, New Products
Inference is the process of running AI models in real-time production systems to filter actionable insights from a haystack of data. It’s an emerging technology that’s still evolving, and NVIDIA isn’t standing still.
Today we announced a low-power version of the Xavier SoC used in the MLPerf tests. At full throttle, Jetson Xavier NX delivers up to 21 TOPS while consuming just 15 watts. It aims to drive a new generation of performance-hungry, power-pinching robots, drones and other autonomous devices.
In addition to the new hardware, NVIDIA released new TensorRT 6 optimizations used in the MLPerf benchmarks as open source on GitHub. You can learn more about the optimizations in this MLPerf developer blog. We continuously evolve this software so our users can reap benefits from increasing AI automation and performance.
Making Inference Easier for Many
One big takeaway from today’s MLPerf tests is inference is hard. For instance, in actual workloads inference is even more demanding than in the benchmarks because it requires significant pre- and post-processing steps.
In his keynote address at GTC last year, NVIDIA founder and CEO Jensen Huang compressed the complexities into one word: PLASTER. Modern AI inference requires excellence in Programmability, Latency, Accuracy, Size-of-model, Throughput, Energy efficiency and Rate of Learning, he said.
That’s why users are increasingly embracing high-performance NVIDIA GPUs and software to handle demanding inference jobs. They include a who’s who of forward-thinking companies such as BMW, Capital One, Cisco, Expedia, John Deere, Microsoft, PayPal, Pinterest, P&G, Postmates, Shazam, Snap, Shopify, Twitter, Verizon and Walmart.
This week, the world’s largest delivery service — the U.S. Post Service— joined the ranks of organizations using NVIDIA GPUs for both AI training and inference.
Hard-drive maker Seagate Technology expects to realize up to a 10 percent improvement in manufacturing throughput thanks to its use of AI inference running on NVIDIA GPUs. It anticipates up to a 300 percent return on investment from improved efficiency and better quality.
Pinterest relies on NVIDIA GPUs for training and evaluating its recognition models and for performing real-time inference across its 175 billion pins.
Snap uses NVIDIA T4 accelerators for inference on the Google Cloud Platform, increasing advertising effectiveness while lowering costs compared to CPU-only systems.
A Twitter spokesman nailed the trend: “Using GPUs made it possible to enable media understanding on our platform, not just by drastically reducing training time, but also by allowing us to derive real-time understanding of live videos at inference time.”
The AI Conversation About Inference
Looking ahead, conversational AI represents a giant set of opportunities and technical challenges on the horizon — and NVIDIA is a clear leader here, too.
NVIDIA already offers optimized reference designs for conversational AI services such as automatic speech recognition, text-to-speech and natural-language understanding. Our open-source optimizations for AI models such as BERT, GNMT and Jasper give developers a leg up in reaching world-class inference performance.
Top companies pioneering conversational AI are already among our customers and partners. They include Kensho, Microsoft, Nuance, Optum and many others.
There’s plenty to talk about. The MLPerf group is already working on enhancements to its current 0.5 inference tests. We’ll work hard to maintain the leadership we continue to show on its benchmarks.
MLPerf v0.5 Inference results for data center server form factors and offline and server scenarios retrieved from www.mlperf.org on Nov. 6, 2019, from entries Inf-0.5-15,Inf-0. 5-16, Inf-0.5-19, Inf-0.5-21. Inf-0.5-22, Inf-0.5-23, Inf-0.5-25, Inf-0.5-26, Inf-0.5-27. Per-processor performance is calculated by dividing the primary metric of total performance by number of accelerators reported.
MLPerf v0.5 Inference results for edge form factors and single-stream and multi-stream scenarios retrieved from www.mlperf.org on Nov. 6, 2019, from entries Inf-0.5-24, Inf-0.5-28, Inf-0.5-29.
Hey Guys, Looking for some feedback – Delete if not allowed.
We’re a data science company that runs competitions (like kaggle for finance). We’re about to run our first competition that requires ML approaches to do well. The competition is for students in the UK where the problems are an Optimisation (e.g. using reinforcement learning) and an NLP (e.g. by fine-tuning pre-trained neural networks)
The problems are sourced from top firms and are real problems that their data scientists and quants are working on. There are three problems covering different aspects of data science with a focus on the finance space.
Cash Prizes of up to $5000 AWS Credits up to $1000 10x Genuine Impact Investment Research Subscriptions
Does this sound like an interesting project or challenge? Would you as a student be interested?
Accenture has a rich history of helping customers all over the world build artificial intelligence (AI) and machine learning (ML) powered solutions with AWS services. In doing so, they always look for new and engaging ways to develop their teams with the appropriate level of enablement and hands-on training. Accenture’s next ML initiative is rolling out their version of an AWS DeepRacer League, which is the world’s first global autonomous racing league launched by AWS at re:Invent in 2018. Accenture’s league spans 30 global locations and 17 countries, with each location featuring both a physical and virtual track to compete on for the title of Accenture AWS DeepRacer Champion.
Why an AWS DeepRacer League and why now?
Machine learning is one of the fastest growing areas in the market. IDC predicted that by 2021, global spending on AI and cognitive technologies will exceed $50M; companies are exploring how they can best take advantage of the technology, no matter the industry. However, the opportunities heavily outweigh the skills present in the workforce to make an AI strategy a reality, and although the breadth of ML-skilled data scientists is growing, companies cannot afford to hire at the scale needed to succeed, leading them to explore ways to upskill their existing talent. AWS DeepRacer and the implementation of the league is a mechanism for Accenture to help their customers take advantage of new ML technologies at scale by democratizing the development of these ML skills throughout their global organization. This unique program provides employees and customers with creative ways to explore machine learning. Participants have the opportunity to learn through hands-on labs followed instantly with practical application—deploying their models to an AWS DeepRacer car and watching it perform. Coupled with the element of competition, it gives teams something to rally around, while helping their organizations learn and grow.
Accenture’s AWS DeepRacer journey
As an emerald sponsor at re:Invent 2018, Accenture was present for the AWS DeepRacer announcement. They attended the workshops, learned about ML basics, built and trained a reinforcement learning model via the AWS DeepRacer 3D cloud-based simulator, and raced that model on one of the physical tracks in the MGM Grand Garden Arena. They even took home their own DeepRacer car! It was during this experience that Accenture realized how easy it was to learn such a complex ML technique and apply these new skills in a fun and engaging way.
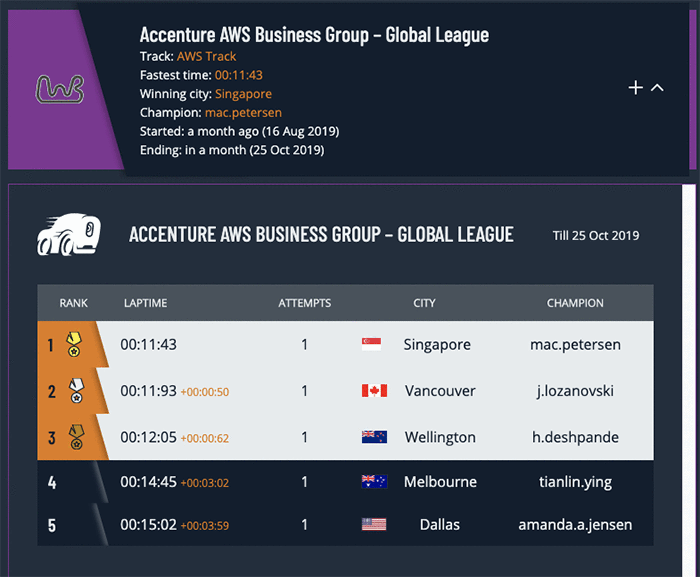
Multiple individuals and groups within Accenture signed up to become private preview customers with access to the AWS DeepRacer console in preparation for the launch of their global competition. They have also begun building their own leaderboard that is integrated into the Accenture single sign on, to use for every site’s competition. Accenture participants in each city can create competitions, track their leaderboard, join competitions in other cities, and upload video recordings from their blazing fast laps to claim victory.
The Accenture AWS Business Group has been the driving force behind the Accenture DeepRacer League competition, assembling teams across the world, and equipping each location with everything they need, including tracks, barriers, and leaderboards. Any Accenture employee can join a competition and start their engines November 14, when the Accenture league will launch with a 24-hour follow-the-sun competition across the globe, bringing the excitement of AWS DeepRacer and machine learning to life.
Showcasing AWS DeepRacer at Accenture’s innovation centers
Accenture’s innovation centers, innovation hubs, and liquid studios are the primary locations hosting the AWS DeepRacer physical tracks. The intention is to showcase Accenture’s ML expertise and accelerate AWS ML around the world, extending the opportunity to upskill clients and the AWS communities in each global city. We encourage you to see how straightforward it is to get hands-on with ML, learn essential ML concepts, and experiment through autonomous driving using AWS DeepRacer. Connect with the teams of technologists from the Accenture AWS Business Group (AABG) to get started on your AWS machine learning journey today!
About the Author
Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.
Is reinforcement learning practical at this point for industry work? The most prominent examples we see are from DeepMind (AlphaStar, AlphaGo), but the team are world-class researchers (over 40 of them) who also worked closely with expert Starcraft 2 players with a ton of computing resources.
As someone who hasn’t had much experience in RL, I see potential applications but am unsure of the amount of work or practicality of it. For example, one potential application for RL is to learn fraudulent behavior in an online retailer system (i.e. Amazon, EBay) and proactively find methods of fraud before they happen. One could imagine all the unintended behavior of misspecified reward function being useful for finding exploits in a system ( https://openai.com/blog/faulty-reward-functions/). But there are a lot of issues to overcome, (some mentioned in this article https://www.alexirpan.com/2018/02/14/rl-hard.html) about sample inefficiency, not to mention having to build your own simulator (and hope it’s representative to some degree).
What are people’s opinion on the practicality of using RL in something like fraud? Does it even make sense to build a simple online retailer simulator? I ask because it while I think RL is quite powerful, it feels it isn’t quite ready to be used. I would love to be shown to be wrong.







 Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.
Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.