Managing Amazon Lex session state using APIs on the client
Anyone who has tried building a bot to support interactions knows that managing the conversation flow can be tricky. Real users (people who obviously haven’t rehearsed your script) can digress in the middle of a conversation. They could ask a question related to the current topic or take the conversation in an entirely new direction. Natural conversations are dynamic and often cover multiple topics.
In this post, we review how APIs can be used to manage a conversation flow that contains switching to a new intent or returning to a prior intent. The following screenshot shows an example with a real user and a human customer service agent.

In the example above, the user query regarding the balance (“Wait – What’s the total balance on the card?”) is a digression from the main goal of making a payment. Changing topics comes easy to people. Bots have to store the state of the conversation when the digression occurs, answer the question, and then return to the original intent, reminding the user of what they’re waiting on.
For example, they have to remember that the user wants to make a payment on the card. After they store the data related to making a payment, they switch contexts to pull up the information on the total balance on the same card. After responding to the user, they continue with the payment. Here’s how the conversation can be broken down into two separate parts:

Figure 2: Digress and Resume
For a tastier example, consider how many times you’ve said, “Does that come with fries?” and think about the ensuing conversation.
Now, let’s be clear: you could detect a digression with a well-constructed bot. You could switch intents on the server-side using Lambda functions, persist conversation state with Amazon ElastiCache or Amazon DynamoDB, or return to the previous intent with pre-filled slots and a new prompt. You could do all of this today. But you’d have to write and manage code for a real bot that does more than just check the weather, which is no easy task. (Not to pick on weather bots here, I find myself going on tangents just to find the right city!)
So, what are you saying?
Starting today, you can build your Amazon Lex bots to address these kinds of digressions and other interesting redirects using the new Session State API. With this API, you can now manage a session with your Amazon Lex bot directly from your client application for granular control over the conversation flow.
To implement the conversation in this post, you would issue a GetSession API call to Amazon Lex to retrieve the intent history for the previous turns in the conversation. Next, you would direct the Dialog Manager to use the correct intent to set the next dialog action using the PutSession operation. This would allow you to manage the dialog state, slot values, and attributes to return the conversation to a previous step.
In the earlier example, when the user queries about the total balance, the client can handle the digression by placing calls to GetSession followed by PutSession to continue the payment. The response from the GetSession operation includes a summary of the state of the last three intents that the user interacted with. This includes the intents MakePayment (accountType: credit, amount: $100), and AccountBalance. The following diagram shows the GetSession retrieval of the intent history.
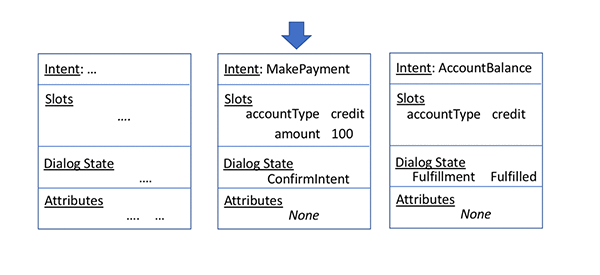
A GetSession request object in Python contains the following attributes:
A GetSession response object in Python contains the following attributes:
Then, the application selects the previous intent and calls PutSession for MakePayment followed by Delegate. The following diagram shows that PutSession resumes the conversation.

A PutSession request object in Python for the MakePayment intent contains the following attributes:
A PutSession response object in Python contains the following attributes:
You can also use the Session State API operations to start a conversation. You can have the bot start the conversation. Create a “Welcome” intent with no slots and a response message that greets the user with “Welcome. How may I help you?” Then call the PutSession operation, set the intent to “Welcome” and set the dialog action to Delegate.

A PutSession request object in Python for the “Welcome” intent contains the following attributes:
A PutSession response object in Python contains the following attributes:
Session State API operations are now available using the SDK.
For more information about incorporating these techniques into real bots, see the Amazon Lex documentation and FAQ page. Want to learn more about designing bots using Amazon Lex? See the two-part tutorial, Building Better Bots Using Amazon Lex! Check out the Alexa Design Guide for tips and tricks. Got .NET? Fret not. We’ve got you covered with Bots Just Got Better with .NET and the AWS Toolkit for Visual Studio.
About the Authors
 Minaxi Singla works as a Software Development Engineer in Amazon AI contributing to microservices that enable human-like experience through chatbots. When not working, she can be found reading about software design or poring over Harry Potter series one more time.
Minaxi Singla works as a Software Development Engineer in Amazon AI contributing to microservices that enable human-like experience through chatbots. When not working, she can be found reading about software design or poring over Harry Potter series one more time.
 Pratik Raichura is a Software Development Engineer with Amazon Lex team. He works on building scalable distributed systems that enhance Lex customer experience. Outside work, he likes to spend time reading books on software architecture and making his home smarter with AI.
Pratik Raichura is a Software Development Engineer with Amazon Lex team. He works on building scalable distributed systems that enhance Lex customer experience. Outside work, he likes to spend time reading books on software architecture and making his home smarter with AI.









 Vikram Madan is the Product Manager for Amazon SageMaker Ground Truth. He focusing on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys running long distances and watching documentaries.
Vikram Madan is the Product Manager for Amazon SageMaker Ground Truth. He focusing on delivering products that make it easier to build machine learning solutions. In his spare time, he enjoys running long distances and watching documentaries.