Conversational interfaces are transforming the way people interact with software applications and services. They are untethering people from keyboards and smartphone gestures by replacing those interfaces with a more natural style of interaction: the spoken word. Increasingly, people are opting to interact with a bot when they need an answer to a question, to set a reminder, or to obtain a product or service.
With Amazon Lex, we can bring this same level of convenience to data. By allowing users to explore datasets by asking a series of questions, and maintaining a conversational context, we can provide a whole new experience and relationship with data.
This blog post shows you how to use Amazon Lex to implement a business intelligence (BI) chatbot, which we refer to as “BIBot,” although you can customize it to use a different name. BIBot can respond to user questions about data in a database, by converting the questions into backend database queries, and transforming the result sets into natural language responses. For example, the request “tell me the increase in inventory last month” could be translated to “select sum(item_qty) from inventory where month(received_date) = 10”.
BIBot has been integrated with a typical relational database intended for business intelligence and reporting applications. The sample database is the Amazon Redshift TICKIT database, which tracks sales activity for a fictional website where users buy and sell tickets online for music concerts and theater shows. The database is a star schema with two fact tables (sales, listings) and five dimension tables (events, dates, venues, categories, and users). See Amazon Redshift » Sample Database for details.
Here are some sample interactions with BIBot:
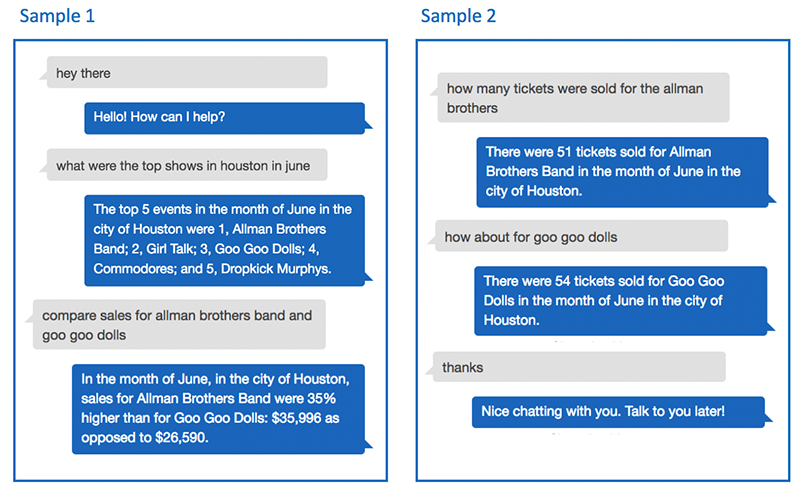
As you can see from these examples, BIBot is able to keep track of the context of your questions, by remembering that you asked about Houston in June, and that you asked how many tickets were sold. The conversation uses the “language” of the data, which in this case is ticket sales, cities, months, events, and so on. These are the facts and dimensions of the sample ticket sales database. If you adapt BIBot to use your reporting database, conversations with the bot will be in the language of your data.
Architecture
BIBot’s architecture is simple. A Lex bot directs each of the user’s questions to an intent, which parses the question into slots. The Amazon Lex bot then passes the intent and slot data to an AWS Lambda function, which uses the data to construct a SQL query, and execute it against an Amazon Athena database. Athena retrieves the query results from a set of CSV files stored in an Amazon S3 bucket, and returns the result set back to the Lambda function, which converts it into a natural language response.

Athena was used for simplicity and convenience, but this architecture will work with any SQL-based database, and can be adapted to other types of data sources, such as NoSQL databases.
Installing BIBot
To get started, let’s install the sample Amazon Lex bot in your AWS account. To make it easy to install BIBot, and for you to make subsequent changes, we’ve implemented a pipeline using AWS CodePipeline that uses AWS CodeBuild to create and update the Amazon Lex bot, the Lambda intent handler functions, and the Athena database.
Step 1: Fork the public amazon-lex-bi-bot into your own GitHub account.
By creating your own copy of the BIBot codebase, you can experiment by making changes to the bot, and even modify it to use your data. Any time you commit a change to your repo, the pipeline will rebuild your bot for you.
Note: if you don’t already have a GitHub account, you can create one for free at https://github.com.
Step 2: Store your AWS API credentials in AWS Systems Manager Parameter Store
The CodeBuild project will make AWS API calls to build the Amazon Lex bot, Lambda function, and Athena database. To do this, it will require your AWS API credentials. If you don’t already have the AWS CLI set up in your environment, follow the directions here: Configuring the AWS CLI. In the AWS Management Console, go to the AWS Systems Manager console, and choose Shared Resources, then choose Parameter Store. Create two parameters with the following parameter names and values:
- ACCESS_KEY_ID – paste in the value of your aws_access_key_id from your AWS credentials file
- SECRET_ACCESS_KEY – paste in the value of your aws_secret_access_key from your credentials file
To protect these sensitive keys, make sure to select the Secure String type for each parameter, so that the values are encrypted in Parameter Store.
Step 3: Create the pipeline using AWS CloudFormation
Use this button to launch the AWS CloudFormation stack in the us-east-1 AWS Region (N. Virginia):

Enter bibot for the Stack Name. Enter your GitHub username in the Owner field, and for Personal Access Token you can generate a token with Repo scope on GitHub.

Accept the default values for the other parameters, and choose Next twice to display the Review page. Select the acknowledgement check box, and choose Create.
The CloudFormation template will take a minute or two to finish, and it will create the following resources:
| CodePipeline |
A “bibot-pipeline” AWS CodePipeline, which retrieves the source from your GitHub repository any time you do a commit, and calls CodeBuild |
| CodeBuildProject |
A CodeBuild project “bibot-build”, which builds (or rebuilds) the Amazon Lex bot |
| ArtifactStore |
An S3 bucket where CodePipeline deposits the code for CodeBuild |
| AthenaBucket |
An S3 bucket where you will store a copy of the TICKIT sample data |
| AthenaOutputLocation |
An S3 bucket for Athena to store output from queries |
| CodePipelineRole |
An IAM service role that allows CodePipeline to access S3 and CodeBuild |
| CodeBuildServiceRole |
An IAM service role that allows CodeBuild to access S3 and CloudWatch Logs |
| LambdaExecutionRole |
An IAM service role required for the Lambda function |
In the AWS Management Console, go to the CodePipeline console and open “bibot-pipeline”. You should see two stages, Source and Build. When both stages have succeeded, your Amazon Lex bot is built.
Next, go to the CodeBuild console and choose Build history. You should see an entry for the “bibot-build” project. Choose the Build run link and inspect the Build details, Environment variables, and Build logs.
Step 4: Copy the sample TICKIT data to your AthenaBucket S3 bucket
When your CloudFormation stack has finished launching, the Output tab will contain AWS CLI commands to copy the data files from the Amazon Redshift sample TICKIT database to your new AthenaBucket S3 bucket. For example:
$ aws s3 cp s3://awssampledbuswest2/tickit/allevents_pipe.txt s3://bibot-athenabucket-xxxxxxxxxxxxx/event/allevents_pipe.txt --source-region us-west-2
Copy each of these AWS CLI commands and execute them to make a copy of the sample data. The Athena database created by CloudFormation uses this data. In the AWS Management Console, go to the Athena console, select the “tickit” database, and try a SQL query. For example:
SELECT DISTINCT event_name from event ORDER BY event_name
Step 5: Test the Lex bot, and refresh its “event_name” slot from the database
Next, got to Amazon Lex, and open BIBot. You will see a warning that you are about to give Amazon Lex permission to invoke your Lambda function, which is expected, so choose OK.
Choose the “event_name” Slot type, and you will see that there are only two entries for this slot (“Sample Event 1” and “Another Sample Event”). Now choose Test Chatbot to open the Lex simulator, and type (or say) “refresh yourself”. BIBot will read the list of events from the database and update the “event_name” Slot type. Choose the “event_name” Slot type again to see the events – you should see a list of event names such as “Joshua Radin,” “Jessica Simpson,” “Nine Inch Nails,” etc.
You will now need to rebuild your bot. Return to the Amazon Lex console, select the BIBot Lex bot, and choose Build. BIBot is now ready for testing – open the Lex simulator and ask BIBot some questions!
Lex bot design
The BIBot Lex bot has eight intents:
| Intent |
Purpose |
| Hello |
Say hello to BIBot |
| Top |
Ask for the top n aggregate values for a given dimension (e.g., shows, venues, cities, months) |
| Compare |
Ask for a comparison of two dimension aggregate values (e.g., March versus April) |
| Count |
Ask for the total quantity of a fact (e.g., tickets sold in March) for the current set of dimensions |
| Switch |
Switch to a new dimension value for a prior query (e.g., how about in May) |
| Reset |
Clear some or all of the query parameters to broaden the search results, or to start over |
| Refresh |
Refresh a slot type using dimension data from the database, and retrain the NLU engine |
| GoodBye |
Say goodbye, and end the session |
The Hello and GoodBye intents are simple, and included mainly just to add character. You can say “Hello,” “hey there,” “hi,” and so on, and BIBot will respond. When you’re done, if you want, you can say “thanks,” “bye,” “good job,” “catch you later,” etc., and BIBot will end the session.
Top, Compare, Count, Switch, and Reset are more interesting. These intents are designed to implement a conversational, natural language interface for specific types of database queries. They’re flexible, because they can work with any of the dimensions in the database, and they’re coordinated, because they remember and share context as the user asks a series of questions as part of a larger conversation.
The Refresh intent updates the definition of a Lex slot type with dimension data from the database (in this case, the list of event names from the EVENT table in the sample TICKIT database).
Let’s take a look at the Top intent:

This intent allows you to ask questions like, “Tell me the top 3 events in Boston,” or “What were the top cities for Dave Matthews Band in March.”
This intent uses the following slots:
- {count} – uses the built-in AMAZON.NUMBER slot type.
- {dimension} – a custom slot type, identifying dimensions from the sample database: “events,” “months,” “venues,” “cities,” “states,” and “categories.” This slot type also uses synonyms, so that you can say “locations” instead of “venues,” for example.
Each of the dimensions in the sample database are also represented as slots:
- {event_name} – a custom slot type, identifying the set of events that exist in the sample TICKIT database “EVENT” table. This slot type is updated via the Refresh
- {event_month} – uses the built-in AMAZON.Month slot type.
- {venue_name} – uses the built-in AMAZON.MusicVenue slot type.
- {venue_city} – uses the built-in AMAZON.US_CITY slot type.
- {venue_state} – uses the built-in AMAZON.US_STATE slot type
- {cat_desc} – a custom slot type, identifying the set of categories that exist in the sample TICKIT database “CATEGORY” table.
Building a domain-specific natural language
BIBot’s query intents – Top, Compare, Count, Switch, and Reset – all work in this way: they use slots as the “vocabulary” needed to build sentence structures relevant to the underlying dataset. In effect, BIBot’s intents implement a domain-specific natural language. The Amazon Lex powerful natural language understanding capabilities make this easy to do.
As an example, take a look at some sample utterances from the Count intent:

When you ask BIBot “How many tickets were sold for the Allman Brothers in Arlington in February?” the Lex natural language processing engine is able to parse the question correctly, by using components from several of the sample utterances. You don’t need to specify every permutation of every question in the sample utterances.
Maintaining conversational context
When you ask BIBot a question, the Lambda fulfillment function responds with an answer, but also retains some of the slot values in session attributes, which are shared across intents. This allows BIBot to carry on a conversation, in effect remembering what was previously asked. Maintaining conversational context in this way is key to providing a more natural user experience, and for simplifying the ability for users to explore a dataset by asking a series of related questions.
For example, in the sample interaction at the beginning of this blog, the user asked about the top shows in Houston in June, and BIBot identified the top five events. When the user asked to compare sales for the Allman Brothers and the Goo Goo Dolls, BIBot “understood” that this was a follow-on question, and that the user really wanted to compare the sales for those events in Houston, in June. This approach enables the user to drill down on their results until they find the information they need.
Sometimes a user may want to back up, switch gears, broaden the search results, or just start over. BIBot’s Top, Compare, and Count query intents support this, with some additional help from the Reset intent. For example:
| Interaction |
Intent – Result |
|
what were the top shows in houston in june?
The top 5 events in the month of June in the city of Houston are 1, Allman Brothers Band; 2, Girl Talk; 3, Goo Goo Dolls; 4, Commodores; and 5, Dropkick Murphys.
|
Top – BIBot remembers city: Houston and month: June as query parameters |
|
top cities for goo goo dolls
There are only 2. The top 2 cities for Goo Goo Dolls in the month of June are 1, Houston; and 2, Cincinnati.
|
Top – BIBot remembers event: Goo Goo Dolls, but forgets the city: Houston query parameter |
|
forget about june
OK, I have reset June.
|
Reset – BIBot forgets the month: June |
|
top cities
The top 5 cities for Goo Goo Dolls are 1, Toronto; 2, Houston; 3, Boston; 4, Oakland; and 5, Cincinnati.
|
Top – BIBot uses the remembered event: Goo Goo Dolls to complete the request. |
|
how many tickets were sold in Boston?
There were 46 tickets sold for Goo Goo Dolls in the city of Boston.
|
Count – BIBot uses the remembered event: Goo Goo Dolls to complete the request, and remembers the city: Boston |
|
start over
OK, I have reset everything.
|
Reset – BIBot forgets event: Goo Goo Dolls and city: Boston |
Sourcing slots from the data
As noted previously, BIBot uses built-in Amazon slot types to represent some of the dimensions, including the month, city, state, and venue name. For the event name dimension, the Refresh intent reads the data from the database and updates the corresponding slot types using the aws.lex-models.put-slot-type API call. This trains the Amazon Lex NLU engine to recognize event names specific to the TICKIT database. For frequently changing datasets, the Refresh intent logic could be triggered automatically on a scheduled basis.
Amazon Lex can correctly identify the intended slots even when they include values that might also exist in other slot types, as shown in the following examples. Lex is able to recognize “Boston” and “Chicago” as bands, as well as cities, even in the same request.

AWS Lambda implementation and extensibility
BIBot’s Python-based Lambda fulfillment functions consist of intent handlers, helper functions, configuration data, and user exit functions. There are eight intent handler functions:
- hello_intent.py
- count_intent.py
- compare_intent.py
- top_intent.py
- switch_intent.py
- reset_intent.py
- refresh_intent.py
- goodbye_intent.py
Helper functions include:
- get_slot_values(slot_values, intent_request)
- remember_slot_values(slot_values, session_attributes)
- get_remembered_slot_values(slot_values, session_attributes)
- execute_athena_query(query_string)
- close(session_attributes, fulfillment_state, message)
All of these functions are database agnostic, and can be configured to work for different database schemas.
Configuration parameters include slot configuration, dimension information, and SQL query strings, which are specific to the underlying database. Slots are configured to match the slot types defined for the intents:
SLOT_CONFIG = {
'event_name': {'type': TOP_RESOLUTION, 'remember': True,
'error': 'I did not find an event called "{}".'},
'event_month': {'type': ORIGINAL_VALUE, 'remember': True},
'venue_name': {'type': ORIGINAL_VALUE, 'remember': True},
'venue_city': {'type': ORIGINAL_VALUE, 'remember': True},
'venue_state': {'type': ORIGINAL_VALUE, 'remember': True},
...
}
BIBot also needs to understand the dimensions for the database, and how they map to database columns:
DIMENSIONS = {
'events': {'slot': 'event_name', 'column': 'e.event_name', 'singular': 'event'},
'months': {'slot': 'event_month', 'column': 'd.month', 'singular': 'month'},
'venues': {'slot': 'venue_name', 'column': 'v.venue_name', 'singular': 'venue'},
'cities': {'slot': 'venue_city', 'column': 'v.venue_city', 'singular': 'city'},
'states': {'slot': 'venue_state', 'column': 'v.venue_state', 'singular': 'state'},
'categories': {'slot': 'cat_desc', 'column': 'c.cat_desc', 'singular': 'category'}
}
The query intent handlers need SQL queries that are specific to the database. For example, here are the configuration parameters for the Top intent handler for the sample TICKIT database:
TOP_SELECT = "SELECT {}, SUM(s.amount) ticket_sales FROM sales s, event e, venue v, "
"category c, date_dim d "
TOP_JOIN = " WHERE e.event_id = s.event_id AND v.venue_id = e.venue_id AND "
" c.cat_id = e.cat_id AND d.date_id = e.date_id "
TOP_WHERE = " AND LOWER({}) LIKE LOWER('%{}%') "
TOP_ORDERBY = " GROUP BY {} ORDER BY ticket_sales desc"
The “{ }” parameters are replaced by column names and values at runtime based on the user’s request.
In addition to configuration parameters, there are user exit functions:
- pre_process_query_value(key, value)
- post_process_slot_value(key, value)
- post_process_dimension_output(key, value)
- get_state_name(value)
- get_month_name(value)
- post_process_venue_name(venue)
These functions are called prior to inserting values into query parameters or after extracting them from the result set, in order to allow mappings between human-readable values and the values stored in the database. You can insert custom code in these functions to implement database-specific mappings.
For example, when the user asks for the top five events in California, preprocess_query_value() converts the value to “CA” which corresponds to the data in the database. The post_process_dimension_output() performs the reverse function, converting the value “CA” returned from the database to back to “California”.
Conclusion
Natural language interfaces will change the way that people interact with data. Traditional business intelligence dashboards, visualizations, and alerts will be augmented with conversational interfaces, in which business users find answers to their questions about their data simply by asking.
BIBot provides an extensible framework for implementing a conversational interface for business data. It’s designed to be integrated with traditional reporting database structures, such as star schemas or snowflake schemas, but can be adapted to other types of data sources, such as NoSQL databases. The sample implementation includes three simple analytics – top aggregates by dimension, compare aggregates for two dimensions, and count an aggregate – which can all participate together seamlessly within a shared conversational context. Additional analytics can be added to this framework, from simple queries to complex simulations and predictive models.
Give BIBot a try with your business data, and let us know how it works for your organization!
About the Author
 Brian Yost is a Senior Consultant with AWS Professional Services. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.
Brian Yost is a Senior Consultant with AWS Professional Services. In his spare time, he enjoys mountain biking, home brewing, and tinkering with technology.



 Cameron Peron is Sr. Developer Marketing Manager for Artificial Intelligence at Amazon Web Services.
Cameron Peron is Sr. Developer Marketing Manager for Artificial Intelligence at Amazon Web Services.


 Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.
Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.
 Erkan Tas is a Senior Product Manager for Amazon SageMaker. He is on a mission to make Artificial Intelligence easy, accessible, and scalable through AWS platforms. He is also a sailor, science and nature admirer, Go and Stratocaster player.
Erkan Tas is a Senior Product Manager for Amazon SageMaker. He is on a mission to make Artificial Intelligence easy, accessible, and scalable through AWS platforms. He is also a sailor, science and nature admirer, Go and Stratocaster player.
 Ragav Venkatesan is a Research Scientist with AWS AI Labs. He has an MS in Electrical Engineering and a PhD in Computer Science from Arizona State University. His current area of research includes Neural Network compression and Computer Vision algorithms for Amazon SageMaker. Outside of work, Ragav is a session bassist and producer at Thaalam Studios.
Ragav Venkatesan is a Research Scientist with AWS AI Labs. He has an MS in Electrical Engineering and a PhD in Computer Science from Arizona State University. His current area of research includes Neural Network compression and Computer Vision algorithms for Amazon SageMaker. Outside of work, Ragav is a session bassist and producer at Thaalam Studios. Saksham Saini did his BS in Computer Engineering from University of Illinois at Urbana-Champaign. He is currently working on building highly optimized and scalable algorithms for Amazon SageMaker. Outside work, he enjoys reading, music and traveling.
Saksham Saini did his BS in Computer Engineering from University of Illinois at Urbana-Champaign. He is currently working on building highly optimized and scalable algorithms for Amazon SageMaker. Outside work, he enjoys reading, music and traveling. Satyaki Chakraborty is an MS student at Carnegie Mellon University studying computer vision. He contributed to Amazon SageMaker Semantic Segmentation during his summer internship.
Satyaki Chakraborty is an MS student at Carnegie Mellon University studying computer vision. He contributed to Amazon SageMaker Semantic Segmentation during his summer internship. Xiong Zhou is an Applied Scientist with AWS AI Labs. He has a PhD in Electrical and Electronics Engineering from University of Houston. His current research focus involves developing domain adaptation and active learning algorithms. He is also working on building computer vision algorithms for Amazon SageMaker.
Xiong Zhou is an Applied Scientist with AWS AI Labs. He has a PhD in Electrical and Electronics Engineering from University of Houston. His current research focus involves developing domain adaptation and active learning algorithms. He is also working on building computer vision algorithms for Amazon SageMaker. Luka Krajcar is a Software Development Engineer on the AWS AI Algorithms team. He received his M.S. in Computer Science at the Faculty of Electrical Engineering and Computing at the University of Zagreb. Outside of work, Luka enjoys reading fiction, running, and video gaming.
Luka Krajcar is a Software Development Engineer on the AWS AI Algorithms team. He received his M.S. in Computer Science at the Faculty of Electrical Engineering and Computing at the University of Zagreb. Outside of work, Luka enjoys reading fiction, running, and video gaming. Hang Zhang is an Applied Scientist with Amazon AI. He has a PhD from Rutgers University. He is currently working with the GluonCV team.
Hang Zhang is an Applied Scientist with Amazon AI. He has a PhD from Rutgers University. He is currently working with the GluonCV team. Yoni Friedman is a Sr. Technical Product Manager in the AWS Artificial Intelligence team where he leads product management for Amazon Translate. He spends his free time reading, running, playing ball, and doing other stuff his two toddlers ask him to.
Yoni Friedman is a Sr. Technical Product Manager in the AWS Artificial Intelligence team where he leads product management for Amazon Translate. He spends his free time reading, running, playing ball, and doing other stuff his two toddlers ask him to.

 Vikas Kumar – Vikas is Senior Software Engineer for AWS Deep Learning, focusing on building scalable deep learning systems. Prior to this Vikas has worked on building service discovery systems for microservices and databases. In his spare time he enjoys reading and music.
Vikas Kumar – Vikas is Senior Software Engineer for AWS Deep Learning, focusing on building scalable deep learning systems. Prior to this Vikas has worked on building service discovery systems for microservices and databases. In his spare time he enjoys reading and music. Haibin Lin – Haibin is a Software Development Engineer for AWS Deep Learning, focusing on distributed optimization and natural language processing. In his spare, he enjoys hiking and traveling.
Haibin Lin – Haibin is a Software Development Engineer for AWS Deep Learning, focusing on distributed optimization and natural language processing. In his spare, he enjoys hiking and traveling. Andrea Olgiati – Andrea is a Principal Engineer for AWS Deep Learning, focusing on building scalable machine learning systems. Prior to this, he worked on databases, compilers, and microchips. In his spare time he enjoys playing the piano and lifting heavy things.
Andrea Olgiati – Andrea is a Principal Engineer for AWS Deep Learning, focusing on building scalable machine learning systems. Prior to this, he worked on databases, compilers, and microchips. In his spare time he enjoys playing the piano and lifting heavy things. Mu Li – Mu Li is a principal scientist for machine learning at AWS. Before joining AWS, he was the CTO of Marianas Labs, an AI start-up. He also served as a principal research architect at the Institute of Deep Learning at Baidu. He obtained his PhD in computer science from Carnegie Mellon University. He enjoys spending time with his family.
Mu Li – Mu Li is a principal scientist for machine learning at AWS. Before joining AWS, he was the CTO of Marianas Labs, an AI start-up. He also served as a principal research architect at the Institute of Deep Learning at Baidu. He obtained his PhD in computer science from Carnegie Mellon University. He enjoys spending time with his family. Hagay Lupesko – Hagay is an Engineering Leader for AWS Deep Learning. He focuses on building deep learning systems that enable developers and scientists to build intelligent applications. In his spare time, he enjoys reading, hiking, and spending time with his family.
Hagay Lupesko – Hagay is an Engineering Leader for AWS Deep Learning. He focuses on building deep learning systems that enable developers and scientists to build intelligent applications. In his spare time, he enjoys reading, hiking, and spending time with his family.







 Ranju Das has been with Amazon for almost five years and leads Amazon Rekognition, a deep learning-based image recognition service which allows you to search, verify and organize millions of images. Before joining Amazon, Ranju worked at Barnes and Noble leading Nook Cloud engineering. His team was responsible for strategy, design, development and SaaS operation of Nook mobile services and Digital Asset Management Services.
Ranju Das has been with Amazon for almost five years and leads Amazon Rekognition, a deep learning-based image recognition service which allows you to search, verify and organize millions of images. Before joining Amazon, Ranju worked at Barnes and Noble leading Nook Cloud engineering. His team was responsible for strategy, design, development and SaaS operation of Nook mobile services and Digital Asset Management Services. Venkatesh Bagaria is a Senior Product Manager for Amazon Rekognition. He focuses on building powerful but easy-to-use deep learning-based image and video analysis services for AWS customers. In his spare time, you’ll find him watching way too many stand-up comedy specials and movies, cooking spicy Indian food, and trying to pretend that he can play the guitar.
Venkatesh Bagaria is a Senior Product Manager for Amazon Rekognition. He focuses on building powerful but easy-to-use deep learning-based image and video analysis services for AWS customers. In his spare time, you’ll find him watching way too many stand-up comedy specials and movies, cooking spicy Indian food, and trying to pretend that he can play the guitar.