At re:Invent 2018 we launched Amazon SageMaker Ground Truth, which can Build Highly Accurate Datasets and Reduce Labeling Costs by up to 70% using machine learning. Amazon SageMaker Ground Truth offers easy access to public and private human labelers and provides them with built-in workflows and interfaces for common labeling tasks. Additionally, Amazon SageMaker Ground Truth lowers your labeling costs by using automated data labeling, which works by training Ground Truth from data labeled by humans so that the service learns to label data independently.
Let’s suppose we have a large corpus of images taken from cameras on a street. Each image might contain many different objects important for developing algorithms for driverless cars (e.g., vehicles or traffic signals). We must first define a hierarchical representation of the information that we want to capture from the images (see below for an example of what such a label taxonomy may look like). We then begin the labeling process by taking these raw, unlabeled images and labeling them with the high-level classes (e.g., ‘vehicles’, ‘traffic-signals’, and ‘pedestrian’.

In this blog post, we’ll show you how to accomplish such hierarchical labeling with Amazon SageMaker Ground Truth by chaining jobs and making use of the augmented manifest functionality.
How is this typically solved?
In supervised machine learning, we typically use a labeled dataset that contains both the raw data and the associated label for each data object. For example, you can have a training dataset of street images and classify them into “traffic-signals” or “no-traffic-signals” (where the label 0 and 1 correspond to the two classes). These labels are usually stored in a formats, such as CSV or JSON with the first column representing the raw data and the second column representing the label.
However, if you want to further label the same set of images (for example, to identify the type of traffic signals in the “traffic-signals” set), we typically create a new dataset by performing a filtering operation on the first dataset to select only those images with traffic signals in them. This reduces the dataset into another subset containing only “traffic-signals” (label 0) in it. Then we can add new label to classify traffic signals as ‘stop-sign’, ‘speed-limit’, and so on.
These kinds of filtering operations might become costly and time-consuming for large datasets. We might also want to mark all the stop signs and pedestrians in an image by an object detection (bounding box) algorithm. This typically requires us to create a third dataset by adding object detection labels around each of the stop signs and pedestrians in it. You can see that, as we continue classifying deep into the taxonomy, the number and complexity of the training datasets increases at approximately same rate as the fanout factor of the taxonomy (exponential in the most complex case).
In short when working with a hierarchical taxonomy, you need to be able to do all of the following:
- Associate multiple layers of labels to an image, and be able to store and retrieve them efficiently and cost effectively.
- Create a filtered dataset containing a given label efficiently and cost effectively.
- Train a model for a given label in the dataset containing multiple labels.
Amazon SageMaker Ground Truth helps you accomplish these tasks easily using the job chaining and augmented manifest functionality.
Job chaining
When you label datasets, often there will be different types of labels (image classification, bounding boxes, semantic segmentation, etc.) that might require a different UI or dramatically different labeling context that would in turn require different instructions for the labelers for optimal quality. In such cases, it can become necessary to split the labeling job up into multiple runs. Amazon SageMaker Ground Truth supports this workflow through job chaining. Job chaining refers to the workflow where the output of one labeling job will feed into the next via the output augmented manifest. At each step we can also apply a filter based on the labels from the previous job.
Job chaining can be a cost-saving measure, if you only run more expensive tasks (for example, semantic segmentation) on images that have already been identified as containing the features that you want to bound. It can also provide the opportunity to mix worker types. Use public workers to perform simple labeling and filtering tasks and use a private and curated workforce to perform tasks that require more precision or domain expertise.
In our street-scenes example, we start with a manifest containing images, then we progressively add each level of the labels. In the process we segment the dataset down with a filter. The workflow will look something like this:
- Collect the initial unlabeled data.
- Job1: Label road-objects (image classification job). The output will be an augmented manifest with labels for vehicles, traffic signals, or pedestrians.
- Job2: Select all images with vehicles and draw bounding boxes around each car in these images.

What is an augmented manifest?
An augmented manifest is a UTF-8 encoded JSON Lines file where each line is a complete and valid JSON object. Each line is delimited by a standard line break, n or rn. Since each line must be a valid JSON object, you can’t have unescaped line break characters within JSON. For more information about the data format, see JSON Lines.
Augmented manifests must contain a source field that defines a dataset object and also optionally includes attribute fields. Each labeling job outputs 2 additional attribute fields: one containing the label and another containing metadata associated with the label. The term augmented comes from the fact that the ground truth labels for the dataset objects are augmented inline. A new label for a dataset object is augmented as a new attribute field to the corresponding JSON line in the augmented manifest.
Normally with Amazon SageMaker training jobs there is one channel for training the actual image and an additional channel for the label. With augmented manifest one channel can stream both image and label. This cuts the number of channels in half, and it reduces the complexity of associating a label file with its corresponding image file.
This single, consistent format can be used as input to labeling jobs and input to training jobs without any additional transformation or reformatting. The format is transitive because the output of the labeling job is also the same format. This means that the output of a labeling job can be fed as input to another labeling job, thus facilitating the chaining of labeling jobs without any transformation or reformatting.
Let’s build an example augmented manifest to solve the taxonomy problem we described earlier.
Ok, let’s do this!
Let’s assume there are millions of images taken from cameras mounted in cars driving the public roadways. These images are stored in an Amazon S3 bucket location called s3://mybucket/datasets/streetscenes/. To start a labeling job to classify the images into vehicles, traffic signals, or pedestrian, we first need to create a manifest to be fed to Amazon SageMaker Ground Truth. The only mandatory field for a manifest is a field defining the dataset object. A dataset object can be an object in an Amazon S3 bucket, such as an image represented by a field “source-ref” pointing to s3Uri of the object or text that can be directly represented as “source” in the manifest. In this example, we’ll use the “source-ref” to point to our street scenes images. See the input section of Amazon SageMaker Ground Truth for more details.
Step 1: Downloading the example dataset
For this example, I’m going to use the CBCL StreetScenes dataset. This dataset has over 3000 images, but we’ll just use a selection of 10 images. The full dataset is approximately 2 GB. You can choose to upload all of the images to Amazon S3 for labeling, or just a selection of them.
- Download the images.zip from here: Download.
- Extract the zip archive to a folder. (By default the folder will be “Output.”)
- Create a small sample dataset to work with:
$ mkdir streetscenes
$ cp Original/SSDB00001.JPG ./streetscenes/
$ cp Original/SSDB00006.JPG ./streetscenes/
$ cp Original/SSDB00016.JPG ./streetscenes/
$ cp Original/SSDB00021.JPG ./streetscenes/
$ cp Original/SSDB00042.JPG ./streetscenes/
$ cp Original/SSDB00003.JPG ./streetscenes/
$ cp Original/SSDB00011.JPG ./streetscenes/
$ cp Original/SSDB00020.JPG ./streetscenes/
$ cp Original/SSDB00025.JPG ./streetscenes/
$ cp Original/SSDB00279.JPG ./streetscenes/
- Go to the Amazon S3 console and create the ‘streetscenes’ folder in your bucket. (Note: Amazon S3 is a key-value store, so there is no concept of folders. However, the AmazonS3 console gives a sense of folder structure by using forward slashes in the key. So we use the console to create the folder.)
- Upload the following files to your Amazon S3 bucket (s3://mybucket/datasets/streetscenes/). You can use the Amazon S3 console or this AWS CLI command:
aws s3 sync streetscenes/ s3://cnidus-ml-iad/datasets/streetscenes/
upload: streetscenes/.DS_Store to s3://cnidus-ml-iad/datasets/streetscenes/.DS_Store
upload: streetscenes/SSDB00011.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00011.JPG
upload: streetscenes/SSDB00020.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00020.JPG
upload: streetscenes/SSDB00042.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00042.JPG
upload: streetscenes/SSDB00001.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00001.JPG
upload: streetscenes/SSDB00016.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00016.JPG
upload: streetscenes/SSDB00006.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00006.JPG
upload: streetscenes/SSDB00021.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00021.JPG
upload: streetscenes/SSDB00025.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00025.JPG
upload: streetscenes/SSDB00279.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00279.JPG
upload: streetscenes/SSDB00003.JPG to s3://cnidus-ml-iad/datasets/streetscenes/SSDB00003.JPG
Step 2: Creating an input manifest
In the Amazon SageMaker console for Ground Truth, there is a crawling tool (see the “create manifest file” link in the input to labeling job) you can use for Ground Truth. This tool helps us create the manifest by crawling an Amazon S3 location containing raw data (image or text). For images, the crawler takes an input s3Prefix and crawls all of the image files (with extensions .jpg, .jpeg, .png) in that prefix and creates a manifest with each line as {“source-ref”:”<s3-location-of-crawled-image>”}. For text, the crawler takes an input s3Prefix and crawls all text files (with extensions .txt, .csv) in that prefix and reads each line of each of the text files in the prefix, and creates a manifest with each line as {“source”:”<one-line-of-text>”}.
In the Amazon SageMaker console, start the process by creating a labeling job. First choose Labeling jobs in the left navigation pane, and then choose the Create labeling job button:

Next choose Create manifest file.

This opens the create manifest file page. Enter the s3 path that you uploaded the files to (be sure to include the trailing slash). Next choose Create and then Use this manifest. (It will take a few seconds to create the manifest.)

For our taxonomy example, the objects are images in Amazon S3, so we can use the crawling to create the initial manifest with each line of JSON containing a field “source-ref” pointing to the s3Uri of an image.
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00001.JPG"}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00006.JPG"}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00016.JPG"}
...
...
Job 1: Labeling road objects

Now, from the console we can start a labeling job using the image classification task type to classify images as containing vehicles, traffic signals, or pedestrians. We use this file as input and “streetscenes-road-objects1” as the job name (or you can start using the AWS API with the LabelAttributeName set to “streetscenes-road-objects1”). See this previous article on how to start a labeling job.

The output of the labeling job is an augmented manifest with the corresponding label augmented in each of the previous JSON lines. See the output data documentation for details on the format for different modalities. Note that if we enable automated data labeling we will also get a model as another output artifact (see this blog post for more details on automated data labeling).
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00001.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles" ,"human-annotated":"yes","creation-date":"2018-12-12T01:30:14.449763","type":"groundtruth/image-classification"}}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00006.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles" ,"human-annotated":"yes","creation-date":"2018-12-12T01:26:08.019726","type":"groundtruth/image-classification"}}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00011.JPG","streetscenes-road-objects1":1,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"no-vehicles" ,"human-annotated":"yes","creation-date":"2018-12-12T01:26:08.019714","type":"groundtruth/image-classification"}}
...
...
Job 2: Adding a bounding box around ‘cars’
Now that I have a dataset with labels for the road objects that are present in each image, I can define a job to add the next layer of the taxonomy. The next layer is to add bounding boxes around the individual objects in the images.
Note: I could run an intermediate second classification job to split vehicles into cars, bicycles, trucks, etc., but for this example, I’ll just create a bounding box job for cars and feed all images with vehicles. In practice, with larger datasets you can choose to perform the intermediate classification because it will reduce the number of objects for each job and also provide the opportunity to run the jobs in parallel.
In the following screenshot, you can see that I’m following a naming scheme for the second job that is similar to the first job. I’ve also selected the output.manifest from Job1.

Filter: selecting vehicles
After classifying the images into those containing three types of road objects (first level of the taxonomy), we now intend to filter the dataset to contain only vehicles, so that we can start another labeling job to identify objects (bounding boxes) representing cars. The Amazon SageMaker console is equipped with a query engine powered by S3 Select to facilitate the filtering of the dataset to clean up or create subset of data.
In this case, we can apply the following query in the query box to filter the augmented manifest and create a subset containing only images with “vehicles” in it.
select * from s3Object s where s."streetscenes-road-objects1-metadata"."class-name" = 'vehicles';
Next choose Create subset and then Use this subset. This will produce a new manifest (in this example, 7 rows) as follows:

The new augmented manifest will look something like this:
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00001.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles" ,"human-annotated":"yes","creation-date":"2018-12-12T01:30:14.449763","type":"groundtruth/image-classification"}}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00003.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles" ,"human-annotated":"yes","creation-date":"2018-12-12T01:21:57.370330","type":"groundtruth/image-classification"}}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00006.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles", "human-annotated":"yes","creation-date":"2018-12-12T01:26:08.019726","type":"groundtruth/image-classification"}}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00016.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles" ,"human-annotated":"yes","creation-date":"2018-12-12T01:19:53.472224","type":"groundtruth/image-classification"}}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00020.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles" ,"human-annotated":"yes","creation-date":"2018-12-12T01:26:08.019736","type":"groundtruth/image-classification"}}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00021.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.95,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles" ,"human-annotated":"yes","creation-date":"2018-12-12T01:19:53.472244","type":"groundtruth/image-classification"}}
{"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00042.JPG","streetscenes-road-objects1":0,"streetscenes-road-objects1-metadata":{"confidence":0.94,"job-name":"labeling-job/streetscenes-road-objects1","class-name":"vehicles",
"human-annotated":"yes","creation-date":"2018-12-12T01:25:03.089097","type":"groundtruth/image-classification"}}
Job2 settings
After we have our filtered augmented manifest, we need to again select a workforce and write instructions for the job. In this case, I’m going to select a private workforce consisting of me, myself, and I.
As with Job1, we could have selected a public workforce, but this is to demonstrate that you can use a different workforce with more domain expertise on a smaller dataset. For a simple task like bounding cars, likely any workforce option would work well with good instructions. However, in another example, like medical imaging, you might want to have trained radiologists classify cancerous cells after a more simple filtering/classification has been performed by a less expensive workforce.

After defining the job parameters, I’ll need to write some sensible instructions. Ideally you would draw bounding boxes around the objects to show how you expect them to be in the output. However, in this case, since I will be the annotator, I’ll use the default image to describe the task.

Results
When the job is complete, you can see what the bounding boxes look like in the console job output.

The completed manifest is augmented with “streetscenes-road-objects2” and “streetscenes-road-objects2-metadata” fields in the above manifest. For example, the first JSON line in this manifest will become:
{
"source-ref":"s3://cnidus-ml-iad/datasets/streetscenes/SSDB00001.JPG",
"streetscenes-road-objects1":0,
"streetscenes-road-objects1-metadata":
{
"confidence":0.95,
"job-name":"labeling-job/streetscenes-road-objects1",
"class-name":"vehicles",
"human-annotated":"yes",
"creation-date":"2018-12-12T01:30:14.449763",
"type":"groundtruth/image-classification"
},
"streetscenes-road-objects2": { "annotations":[ {"class_id":0,"width":38,"top":490,"height":24,"left":351}, {"class_id":0,"width":85,"top":505,"height":53,"left":450}, {"class_id":0,"width":65,"top":489,"height":43,"left":592}, {"class_id":0,"width":59,"top":480,"height":43,"left":524}, {"class_id":0,"width":354,"top":471,"height":150,"left":567} ], "image_size":[{"width":1280,"depth":3,"height":960}]}, "streetscenes-road-objects2-metadata": { "job-name":"labeling-job/streetscenes-road-objects2", "class-map":{"0":"car"}, "human-annotated":"yes", "objects":[ {"confidence":0.09}, {"confidence":0.09}, {"confidence":0.09}, {"confidence":0.09}, {"confidence":0.09} ], "creation-date":"2018-12-12T18:40:15.710919", "type":"groundtruth/object-detection" }
}
Multi-label?
You might notice in the results or in the labeler UI that only a single label can be selected for Job1: Labeling Road objects. This will manifest as each image containing only a single label (vehicle, traffic signal or pedestrian). For this dataset, it’s perfectly valid for a given image to contain multiple labels, for example, there could be a car, pedestrian, AND a stop sign in a single image.
Currently the image-classifier in Ground Truth only supports labeling an image with a single label. For the purpose of this example, I opted to keep it simple and use the default image classifier. To extend to multi-label there are a couple of options:
- Image classification jobs per label: Vehicles, pedestrians and traffic signals would be separate jobs. Each image would be run using all jobs (in parallel if desired).
- Create a custom labeling workflow: Ground Truth provides a workflow where the customer can provide the HTML for worker input. Using this method, you could create a workflow that allows for multiple labels to be applied to a single image in a single pass.
Next steps: Training with an augmented manifest that contains multiple labels
A key feature of the augmented manifest is that the same manifest can contain labels from many different labeling jobs using the chaining method described in this blog post. We can use the augmented manifest to train a model for any desired label in it. For example, the manifest in this blog post contains labels from two jobs: “streetscenes-road-objects1” and “streetscenes-road-objects2”.
We can train an image classification model to classify road objects by directly using this output manifest without any transformation to start an Amazon SageMaker training job using S3DataType to AugmentedManifestFile and AttributeNames to [“source-ref”, “streetscenes-road-objects1″].
The same manifest can be used to train an object detection model to identify cars by directly using this output manifest without any transformation to start an Amazon SageMaker training job using S3DataType to AugmentedManifestFile and AttributeNames to [“source-ref”, “streetscenes-road-objects2”].
See this sample notebook to start an Amazon SageMaker training job using Augmented Manifest.
Conclusion
The blog post shows you how job chaining and augmented manifest can be used to associate multiple labels across your hierarchical label taxonomy. The augmented manifest contains all of the labels inline in a single manifest, and you can use this manifest directly in Amazon SageMaker training jobs. In addition, you learned how to create a subset of the dataset based on labels or metadata using the Ground Truth filtering and sampling capabilities.
We hope this post was informative, and we have just scratched the surface of what Amazon SageMaker Ground Truth can do. The service is available today in the following AWS Regions: US East (Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo). Please let us know what you think!
About the authors
 Doug Youd is a Solutions Architect with AWS covering strategic accounts. He has a background in networking and virtualization, but more recently has been working on ML projects for his customers. In his spare time he enjoys tinkering with classic cars & motorsport.
Doug Youd is a Solutions Architect with AWS covering strategic accounts. He has a background in networking and virtualization, but more recently has been working on ML projects for his customers. In his spare time he enjoys tinkering with classic cars & motorsport.
 Zahid Rahman is a SDE in AWS AI where he builds large scale distributed systems to solve complex machine learning problems . He is primarily focused on innovating technologies that can ‘Divide and Conquer’ Big Data problem.
Zahid Rahman is a SDE in AWS AI where he builds large scale distributed systems to solve complex machine learning problems . He is primarily focused on innovating technologies that can ‘Divide and Conquer’ Big Data problem.
 Woo Kim is a Product Marketing Manager for AWS machine learning services. He spent his childhood in South Korea and now lives in Seattle, WA. In his spare time, he enjoys playing volleyball and tennis.
Woo Kim is a Product Marketing Manager for AWS machine learning services. He spent his childhood in South Korea and now lives in Seattle, WA. In his spare time, he enjoys playing volleyball and tennis.

 Vandana Kannan is a Software Developer for AWS Deep Learning focusing on building scalable deep learning systems. In her spare time, she enjoys painting, learning Indian classical dance, and spending time with family and friends.
Vandana Kannan is a Software Developer for AWS Deep Learning focusing on building scalable deep learning systems. In her spare time, she enjoys painting, learning Indian classical dance, and spending time with family and friends. Hagay Lupesko is an Engineering Manager for AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys reading, hiking and spending time with his family.
Hagay Lupesko is an Engineering Manager for AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys reading, hiking and spending time with his family. Maysam Ali is Global Content Lead for the Amazon Web Services Institute. She writes about the impact of technology on society. She helps governments, nonprofits and educational leaders better understand how they can use new technologies, including machine learning and artificial intelligence, to address major societal challenges.
Maysam Ali is Global Content Lead for the Amazon Web Services Institute. She writes about the impact of technology on society. She helps governments, nonprofits and educational leaders better understand how they can use new technologies, including machine learning and artificial intelligence, to address major societal challenges. Leonardo Quattrucci is the Lead for Europe, Middle East and Africa for the Amazon Web Services Institute. He works with government executives to accelerate public sector transformation. By innovating on policy processes and building digital competencies, he is helping leaders use technology to deliver better citizen services.
Leonardo Quattrucci is the Lead for Europe, Middle East and Africa for the Amazon Web Services Institute. He works with government executives to accelerate public sector transformation. By innovating on policy processes and building digital competencies, he is helping leaders use technology to deliver better citizen services. Brent Rabowsky focuses on data science at AWS, and leverages his expertise to help AWS customers with their own data science projects.
Brent Rabowsky focuses on data science at AWS, and leverages his expertise to help AWS customers with their own data science projects.







 Tomasz Stachlewski is a Solutions Architect at AWS, where he helps companies of all sizes (from startups to enterprises) in their cloud journey. He is a big believer in innovative technology, such as serverless architecture, which allows companies to accelerate their digital transformation.
Tomasz Stachlewski is a Solutions Architect at AWS, where he helps companies of all sizes (from startups to enterprises) in their cloud journey. He is a big believer in innovative technology, such as serverless architecture, which allows companies to accelerate their digital transformation.


 Shafreen Sayyed is an AWS Solutions Architect based in London. She helps customers across the UK and Ireland, supporting various industry verticals to transform their businesses and build industry-leading cloud solutions. She has a special interest in Machine Learning and Artificial Intelligence and is passionate about finding ways to help our customers integrate these new and exciting technologies into all aspects of their business.
Shafreen Sayyed is an AWS Solutions Architect based in London. She helps customers across the UK and Ireland, supporting various industry verticals to transform their businesses and build industry-leading cloud solutions. She has a special interest in Machine Learning and Artificial Intelligence and is passionate about finding ways to help our customers integrate these new and exciting technologies into all aspects of their business.
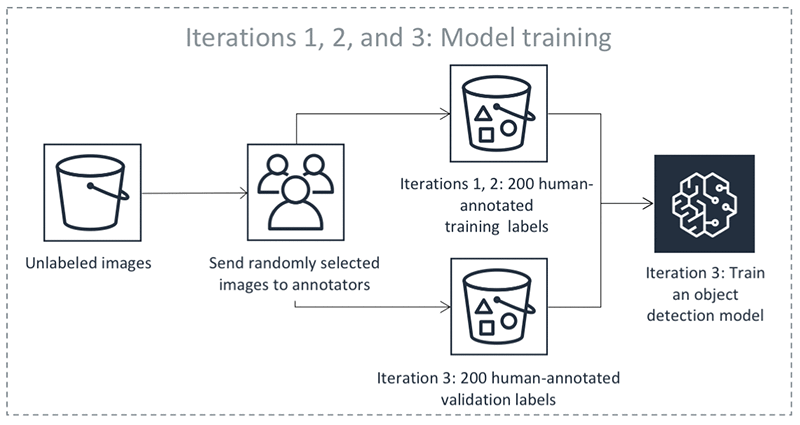
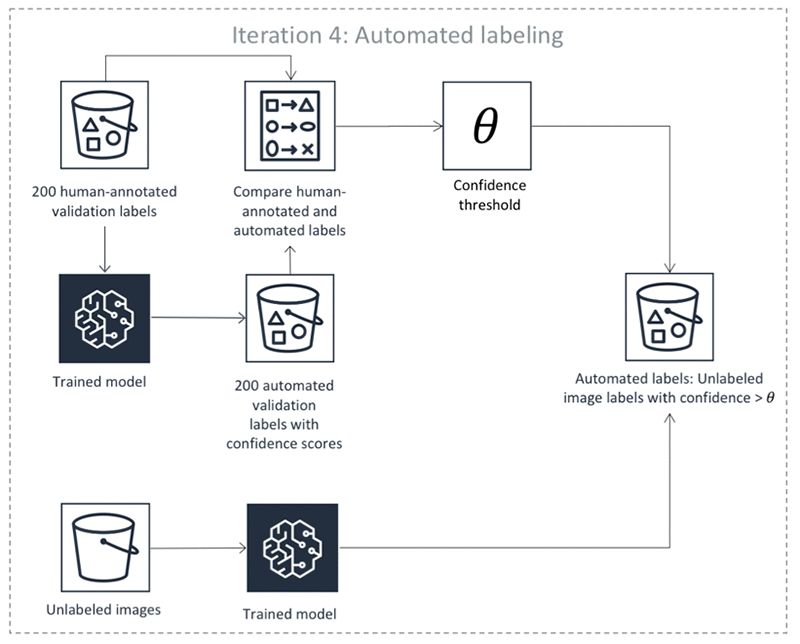
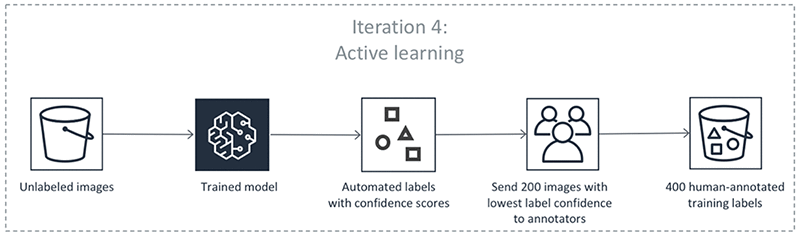
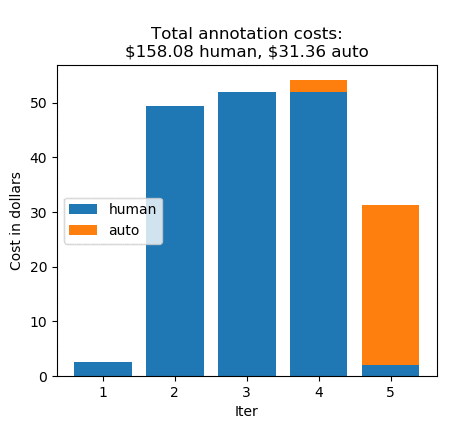


 Krzysztof Chalupka is an applied scientist in the Amazon ML Solutions Lab. He has a PhD in causal inference and computer vision from Caltech. At Amazon, he figures out ways in which computer vision and deep learning can augment human intelligence. His free time is filled with family. He also loves forests, woodworking, and books (trees in all forms).
Krzysztof Chalupka is an applied scientist in the Amazon ML Solutions Lab. He has a PhD in causal inference and computer vision from Caltech. At Amazon, he figures out ways in which computer vision and deep learning can augment human intelligence. His free time is filled with family. He also loves forests, woodworking, and books (trees in all forms). Tristan McKinney is an applied scientist in the Amazon ML Solutions Lab. He recently completed his PhD in theoretical physics at Caltech where he studied effective field theory and its application to high-T_c superconductors. As his father was in the US Army, he lived all over the place when growing up, including Germany and Albania. In his spare time, Tristan loves to ski and play soccer.
Tristan McKinney is an applied scientist in the Amazon ML Solutions Lab. He recently completed his PhD in theoretical physics at Caltech where he studied effective field theory and its application to high-T_c superconductors. As his father was in the US Army, he lived all over the place when growing up, including Germany and Albania. In his spare time, Tristan loves to ski and play soccer. Fedor Zhdanov is a Machine Learning Scientist at Amazon. He works on developing Machine Learning algorithms and tools for our internal and external customers.
Fedor Zhdanov is a Machine Learning Scientist at Amazon. He works on developing Machine Learning algorithms and tools for our internal and external customers.