Good machine learning models are built with large volumes of high-quality training data. But creating this kind of training data is expensive, complicated, and time-consuming. To help a model learn how to make the right decisions, you typically need a human to manually label the training data.
Amazon SageMaker Ground Truth provides labeling workflows for humans to work on image and text classification, object detection, and semantic segmentation labeling jobs. You can also build custom workflows to define the user interface (UI) for data labeling jobs. To help you get started, Amazon SageMaker provides custom templates for image, text, and audio data labeling jobs. These templates use the Amazon SageMaker Ground Truth crowd HTML elements, which simplify building data labeling UIs. You can also specify your own HTML for the UI.
You might want to build a custom workflow for the following reasons:
- You have custom data labeling requirements.
- Your input data is complex, with multiple elements (for example, images, text, or custom metadata) per task.
- You want to prevent sending certain items to labelers when you create tasks.
- You require custom logic to consolidate labeling output and improve accuracy.
Science conferences, like those sponsored by IEEE, receive thousands of abstracts that are manually reviewed. A typical abstract for a science paper includes the following information: Background, objectives, methods, results, limitations, and conclusions. Reviewing these sections or entities for thousands of abstracts can be burdensome.
What if there were a natural language processing (NLP) model that could help reviewers by automatically tagging all of the required entities? What if text labeling tools could extract entities from published abstracts?
Amazon Comprehend is Natural language processing (NLP) service that uses machine learning to find insights and relationships in text. But in this post, I walk you through building a custom text labeling workflow that extracts named entities from science paper abstracts to build a training dataset for a named entity recognition (NER) model. It will demonstrate how to easily bring your own existing Web templates to Amazon SageMaker Ground Truth.
Solution overview
To build a custom workflow, I used input images from the first page of 10 science papers courtesy of arxiv.org.
To extract text from the papers, I used the Amazon Textract SDK. I used another script to generate an augmented manifest, which I fed into Amazon SageMaker Ground Truth later. The scripts are located in this GitHub repository. You can use this augmented manifest to create the labeling job.
To build the custom UI, use the React framework and the WebStorm integrated development environment (IDE). You can use any framework and IDE.
Everything you need is available in a template.
How the custom web template works
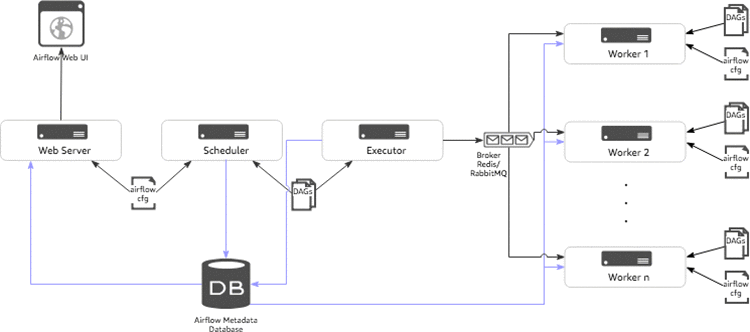
This solution uses server-side AWS Lambda functions for pre-labeling and post-labeling processing. The following diagram shows the high-level workflow. Explanations follow.

- Build custom web template.
- Deploy pre-labeling task Lambda function to your AWS account.
- Deploy post-labeling consolidation task Lambda function to your AWS account.
- Create input manifest and upload to your Amazon S3 bucket.
- Create workforce team and add members to the team.
- Launch SageMaker Ground Truth labeling job with custom template from the Ground Truth console.
- After labeling job finishes, consolidated labels are persisted in Amazon S3 output location.
The custom template
To build the labeling UI that displays a .jpg image, text for annotation, a free-form text field for additional notes, and a yes/no element to classify the quality of the abstract, you create a single-page Web app using React. The static JavaScript and CSS files are hosted on Amazon S3 at s3://smgtannotation/web/static. If you are curious about how I built the web app, refer to the GitHub repository for instructions.
With this app, a worker performing labeling can annotate the abstracts by labeling selected text. The worker can choose the type of entity (Background, Objectives, Methods, Results, Conclusions, and Limitations) from a dropdown list, as shown in the following screenshot. The worker can also add notes and label the quality of the abstract.

You can use the template provided at this GitHub location while launching a Ground Truth job. I’ll walk through the custom HTML template that I built. If you choose to build your own template from the source, replace the generated JavaScript and CSS URLs as appropriate.
First, I added the crowd-htm-element.js script at the top of the template so you can use the crowd HTML elements.
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
Then I added static CSS content.
<link rel="stylesheet" href="https://s3.amazonaws.com/smgtannotation/web/static/css/1.3fc3007b.chunk.css">
<link rel="stylesheet" href="https://s3.amazonaws.com/smgtannotation/web/static/css/main.9504782e.chunk.css">
I used the Liquid templating language to inject the text to annotate, the URL of the image document, and the associated metadata to the user interface.
In the following snippet, you can see a variable “task.input.taskObject” from the pre-labeling task AWS Lambda function between double curly brackets. The grant_read_access variable is an additional filter that takes an S3 URI and encodes it into a signed S3 HTTPs URL. For more information, see the Ground Truth documentation in the Amazon SageMaker Developer Guide.
<div id='document-text' style="display: none;">
{{ task.input.text }}
</div>
<div id='document-image' style="display: none;">
{{ task.input.taskObject | grant_read_access }}
</div>
<div id="metadata" style="display: none;">
{{ task.input.metadata }}
</div>
I used the <crowd-form /> element, which submits the annotations to Amazon SageMaker Ground Truth. I also included an invisible <crowd-button /> element within the form, so that <crowd-form /> does not include one on its own buttons. This gives you flexibility to add a button at the end of form. Of course, if the app didn’t contain its own Submit button, I could just use the default <crowd-button /> provided by <crowd-form />.
<crowd-form>
<input name="annotations" id="annotations" type="hidden">
<!-- Prevent crowd-form from creating its own button -->
<crowd-button form-action="submit" style="display: none;"></crowd-button>
</crowd-form>
<!-- Custom annotation user interface is rendered here -->
<div id="root"></div>
I used a JavaScript app to build the UI, instead of using a crowd HTML element. This is why I included a small script to integrate the app with <crowd-form />. Essentially, I make a Submit button submit the <crowd-form />, and inject whatever data I want to submit into the form.
<crowd-button id="submitButton">Submit</crowd-button>
<script>
document.querySelector('crowd-form').onsubmit = function() {
document.getElementById('annotations').value = JSON.stringify(JSON.parse(document.querySelector('pre').innerText));
};
document.getElementById('submitButton').onclick = function() {
document.querySelector('crowd-form').submit();
};
</script>
I added the JavaScript scripts for the React app at the end of the template.
<script src="https://s3.amazonaws.com/smgtannotation/web/static/js/1.3e5a6849.chunk.js"></script>
<script src="https://s3.amazonaws.com/smgtannotation/web/static/js/main.96e12312.chunk.js"></script>
<script src="https://s3.amazonaws.com/smgtannotation/web/static/js/runtime~main.229c360f.js"></script>
The input data for the labeling job is a set of data objects that you send to your workforce for labeling. Each object in the input data is described in a manifest file. Each line in the manifest file is a valid JSON Lines object to be labeled and any other custom metadata. Each line is delimited by a standard line break.
The input data and manifest are stored in an S3 bucket. Each JSON line in the manifest has:
- A
source-ref JSON object that contains the S3 object URI for the image.
- The
text-file-s3-uri JSON object containing the S3 object URI for the text.
- A
metadata JSON object containing additional metadata.
For more information, see Input Data in the Amazon SageMaker Developer Guide.
{'source-ref': 's3://smgtannotation/raw-abstracts-jpgs/1801_00006.jpg', 'text-file-s3-uri': 's3://smgtannotation/text/1801_00006.jpg.csv', 'metadata': {'Author': 'Alejandro Rosalez', 'ISBN': '1-358-98355-0'}}
{'source-ref': 's3://smgtannotation/raw-abstracts-jpgs/1801_00015.jpg', 'text-file-s3-uri': 's3://smgtannotation/text/1801_00015.jpg.csv', 'metadata': {'Author': Mary Major', 'ISBN': '1-242-55362-2'}}
The pre-labeling task Lambda function
The custom labeling workflow provides a hook for the pre-labeling task Lambda function. Before a labeling task is sent to the worker, this Lambda function is invoked with a JSON-formatted request containing a manifest entry in the dataObject object.
The following is an example of a request that is sent to AWS Lambda:
{
"version": "2018-10-06",
"labelingJobArn": <labeling job ARN>,
"dataObject": {
"source-ref": "s3://smgtannotation/raw-abstracts-jpgs/1801_00015.jpg",
"text-file-s3-uri": "s3://smgtannotation/text/1801_00015.jpg.csv",
"metadata": {
"Author": "Mary Major",
"ISBN": "1-242-55362-2"
}
}
}
The pre-labeling Lambda function parses the JSON request to retrieve the dataObject key, retrieves the raw text from the S3 URI for the text-file-s3-uri object, and transforms it into the taskInput JSON format required by Amazon SageMaker Ground Truth as the response.
{
'taskInput': {
'taskObject': 's3://smgtannotation/raw-abstracts-jpgs/1801_00015.jpg',
'metadata': {
'Author': 'Mary Major',
'ISBN': '1-242-55362-2',
'text_file_s3_uri': 's3://smgtannotation/text/1801_00015.jpg.csv'
},
'text': <Raw Text> },
'isHumanAnnotationRequired': 'true'
}
The post-labeling task Lambda function
When all workers complete the labeling task, Amazon SageMaker Ground Truth invokes the post-labeling Lambda function with a pointer to the dataset object and the workers’ annotations. This Lambda function is generally used for annotation consolidation. The request object looks similar to the following:
{
"version": "2018-10-06",
"labelingJobArn": "<labeling job ARN>",
"payload": {
"s3Uri": "‘<s3uri of annotation consolidation request>"
},
"labelAttributeName": "<labeling job name>",
"roleArn": "<Amazon SageMaker Ground Truth Role ARN>",
"outputConfig": "<output s3 prefix uri>"
}
The annotations are stored in a file designated by the s3uri in the payload object. The Lambda function retrieves the S3 object file to read the annotations. Each input annotation looks similar to the following:
[{'datasetObjectId': '0',
'dataObject': {'content': <input manifest task content>},
'annotations': [{
'workerId': <worker Id>,
'annotationData': {'content': <named entity annotations>}
}]
}]
All of the fields from the custom UI form are contained in the content object.
The Lambda function then starts data consolidation to create a consolidated annotation manifest in the S3 bucket that was specified for output when the labeling job was configured. The following example includes the consolidated response in the content object:
{
"source-ref": "s3://smgtannotation/raw-abstracts-jpgs/1801_00006.jpg",
"text-file-s3-uri": "s3://smgtannotation/text/1801_00006.jpg.csv",
"metadata": {
"Author": "Alejandro Rosalez",
"ISBN": "1-358-98355-0"
},
"<labeling jobname": {
"annotationsFromAllWorkers": [{
"workerId": "<internal worker id>",
"annotationData": {
"content": "{"annotations":"{\"value\":[{\"start\":296,\"end..."}"
}]
},
"custom-ner-job-23-metadata": {
"type": "groundtruth/custom",
"job-name": "<labeling jobname>",
"human-annotated": "yes",
"creation-date": "2019-04-18T20:24:18+0000"
}
}
{… }
Deploy the pre-labeling and post-labeling task Lambda functions
Sign in to the AWS console and launch the AWS CloudFormation stack in the US East (N. Virginia) us-east-1 Region. This deploys the pre-labeling and post-labeling task Lambda functions.

It should take less than a couple of minutes to deploy the Lambda functions and create the required AWS Identity and Access Management (IAM) role.
Open the AWS CloudFormation console, and in the Outputs section, note the Amazon Resource Name (ARN) of the IAM role. You need it later.

Open the AWS Lambda console and navigate to the Functions page to see the Lambda functions.

Launch an Amazon SageMaker Ground Truth labeling job
A workforce is a group of workers that you choose to label your dataset. With Amazon SageMaker Ground Truth, you can choose to use a public Amazon Mechanical Turk workforce, a vendor-managed workforce, or your own private workforce. For this labeling job, you use a private workforce.
Prerequisites
Before you create the labeling job, complete the following steps.
- Upload augmented manifest file to your S3 bucket in N. Virginia region
- A labeling job requires an IAM role that has the SageMakerFullAccess policy attached to it. If you don’t already have such a role, create one by following the steps in Launching the labeling job.
- Attach a trust policy to the IAM role. This policy gives the post-labeling Lambda function access to resources stored in Amazon S3.
- In a new browser tab, open the IAM console. In the navigation pane, choose Roles, and search for the IAM role that you created in Step 2 (the role name typically starts with AmazonSageMaker-ExecutionRole-). For Role name, choose the name.

- On the Summary page, choose Trust relationships, then choose Edit trust relationship to edit the trust policy.

- Replace the trust policy with the following policy. Replace
<Lambda IAM Role ARN> with the role ARN that you copied from the AWS CloudFormation template output.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "sagemaker.amazonaws.com"
},
"Action": "sts:AssumeRole"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "<Lambda IAM Role ARN>",
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- Click “Add inline policy” link to add AWS Lambda invocation policy to the role.

- In “Create Policy” page, on JSON tab, add following json policy and click “Review Policy”

{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": "*"
}
]
}
- On “Review Policy” page, enter Name as “LambdaInvocationPolicy” and click “Create Policy”


Launching the labeling job
- Open the Amazon SageMaker console and ensure N. Virginia Region is selected. In the Labeling jobs menu, choose Create labeling job to launch new labeling job.

- Enter the “Job name”, provide the input manifest S3 location (you have already uploaded the manifest to your S3 bucket during pre-requisite step 1), and provide output dataset s3 prefix location.Ensure that the input manifest and output dataset locations in Amazon S3 are in the same Region as the job that you are launching.Select the existing IAM Role with “SageMakerFullAccess” IAM policy attached or create a new Role if you don’t have one.

- If you have already added the Lambda trust policy to the IAM role for this post, skip this step. If not, open a browser in a new tab and perform the Step 3 in Prerequisites to attach a trust policy to the IAM role.
- For Task type, choose Custom, and choose Next.

- For Worker type, choose Private. If you already have created a work team, select it and go to the next step.If this is the first time you are launching a Ground Truth job with private work team, then enter a team name, add comma-separated email addresses of workers you want to invite, add an organization, and provide contact email for workers to contact you if needed.

- For Templates, choose Custom, and copy and paste the custom template.

- For Pre-labeling task Lambda function and Post-labeling task Lambda function, choose “gt-prelabel-task-lambda” and “gt-postlabel-task-lambda” using respective dropdown and then choose Submit.

- In a few minutes, your private workers can log in to the portal and start labeling.

Conclusion
This blog post showed how to build custom labeling workflows with Amazon SageMaker Ground Truth. The custom workflow preprocessed multiple input attributes from an augmented manifest, used a custom created labeling UI, and then consolidated individual worker annotations into a high fidelity set of labels. Custom workflows enable you to easily meet your own labeling business needs when tapping into public, private, or vendor labeling workforces.
If you have any comments or questions about this blog post, please use the comments section below. Happy labeling!
Related blog posts
About the Authors
 Nitin Wagh is Sr. Business Development Manager for Amazon AI. He likes the opportunity to help customers understand Machine Learning and power of Augmented AI in AWS cloud. In his spare time, he loves spending time with family in outdoors activities.
Nitin Wagh is Sr. Business Development Manager for Amazon AI. He likes the opportunity to help customers understand Machine Learning and power of Augmented AI in AWS cloud. In his spare time, he loves spending time with family in outdoors activities.
 Hareesh Lakshmi Narayanan is a software development engineer working on Sagemaker GroundTruth. He is passionate about building software systems to solve real world problems.
Hareesh Lakshmi Narayanan is a software development engineer working on Sagemaker GroundTruth. He is passionate about building software systems to solve real world problems.
 Ted Lee is a Software Development Engineer for Amazon AI. His focus is helping machine learning and AI customers create user interfaces for human annotators.
Ted Lee is a Software Development Engineer for Amazon AI. His focus is helping machine learning and AI customers create user interfaces for human annotators.




 Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.
Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.



 Rajesh Thallam is a Professional Services Architect for AWS helping customers run Big Data and Machine Learning workloads on AWS. In his spare time he enjoys spending time with family, traveling and exploring ways to integrate technology into daily life. He would like to thank his colleagues David Ping and Shreyas Subramanian for helping with this blog post.
Rajesh Thallam is a Professional Services Architect for AWS helping customers run Big Data and Machine Learning workloads on AWS. In his spare time he enjoys spending time with family, traveling and exploring ways to integrate technology into daily life. He would like to thank his colleagues David Ping and Shreyas Subramanian for helping with this blog post.

 Cheng Tang is an Applied Scientist in the Verticals and Applications Group at AWS AI. Broadly interested in machine learning research and its applications to the natural language processing domain, Cheng finds great inspiration to be part of both research and industrialization of machine learning/deep learning algorithms, and she is thrilled to see them delivered to the customers.
Cheng Tang is an Applied Scientist in the Verticals and Applications Group at AWS AI. Broadly interested in machine learning research and its applications to the natural language processing domain, Cheng finds great inspiration to be part of both research and industrialization of machine learning/deep learning algorithms, and she is thrilled to see them delivered to the customers. Patrick Ng is a Software Development Engineer in the Verticals and Applications Group at AWS AI. He works on building scalable distributed machine learning algorithms, with focus in the area of deep neural networks and natural language processing. Before Amazon, he obtained his PhD in Computer Science from the Cornell University and worked at startup companies building machine learning systems.
Patrick Ng is a Software Development Engineer in the Verticals and Applications Group at AWS AI. He works on building scalable distributed machine learning algorithms, with focus in the area of deep neural networks and natural language processing. Before Amazon, he obtained his PhD in Computer Science from the Cornell University and worked at startup companies building machine learning systems. Ramesh Nallapati is a Principal Applied Scientist in the Verticals and Applications Group at AWS AI. He works on building novel deep neural networks at scale primarily in the natural language processing domain. He is very passionate about deep learning, and enjoys learning about latest developments in AI and is excited about contributing to this field to the best of his abilities.
Ramesh Nallapati is a Principal Applied Scientist in the Verticals and Applications Group at AWS AI. He works on building novel deep neural networks at scale primarily in the natural language processing domain. He is very passionate about deep learning, and enjoys learning about latest developments in AI and is excited about contributing to this field to the best of his abilities. Bing Xiang is a Principal Scientist and Head of Verticals and Applications Group at AWS AI. He leads a team of scientists and engineers working on deep learning, machine learning, and natural language processing for multiple AWS services.
Bing Xiang is a Principal Scientist and Head of Verticals and Applications Group at AWS AI. He leads a team of scientists and engineers working on deep learning, machine learning, and natural language processing for multiple AWS services.
 Marisa Messina is on the AWS AI marketing team, where her job includes identifying the most innovative AWS-using customers and showcasing their inspiring stories. Prior to AWS, she worked on consumer-facing hardware and then university-facing cloud offerings at Microsoft. Outside of work, she enjoys exploring the Pacific Northwest hiking trails, cooking without recipes, and dancing in the rain.
Marisa Messina is on the AWS AI marketing team, where her job includes identifying the most innovative AWS-using customers and showcasing their inspiring stories. Prior to AWS, she worked on consumer-facing hardware and then university-facing cloud offerings at Microsoft. Outside of work, she enjoys exploring the Pacific Northwest hiking trails, cooking without recipes, and dancing in the rain.
 Zach Kimberg is a Software Engineer with AWS Deep Learning working mainly on Apache MXNet for Java and Scala. Outside of work he enjoys reading, especially Fantasy.
Zach Kimberg is a Software Engineer with AWS Deep Learning working mainly on Apache MXNet for Java and Scala. Outside of work he enjoys reading, especially Fantasy. Sam Skalicky is a Software Engineer with AWS Deep Learning and enjoys building heterogeneous high performance computing systems. He is an avid coffee enthusiast and avoids hiking at all costs.
Sam Skalicky is a Software Engineer with AWS Deep Learning and enjoys building heterogeneous high performance computing systems. He is an avid coffee enthusiast and avoids hiking at all costs. Denis Davydenko is an Engineering Manager with AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys spending time with his family, playing poker and video games.
Denis Davydenko is an Engineering Manager with AWS Deep Learning. He focuses on building Deep Learning tools that enable developers and scientists to build intelligent applications. In his spare time he enjoys spending time with his family, playing poker and video games.
 Sally Revell is a Senior Manager, Product Marketing for AWS AI. She loves to work on innovative products that have the potential to impact people’s lives in a positive way. In her spare time, she loves to do yoga, horseback riding and being outdoors in the beauty of the Pacific Northwest.
Sally Revell is a Senior Manager, Product Marketing for AWS AI. She loves to work on innovative products that have the potential to impact people’s lives in a positive way. In her spare time, she loves to do yoga, horseback riding and being outdoors in the beauty of the Pacific Northwest.
 Tristan Li is a Solutions Architect with Amazon Web Services. He works with enterprise customers in the US, helping them adopt cloud technology to build scalable and secure solutions on AWS.
Tristan Li is a Solutions Architect with Amazon Web Services. He works with enterprise customers in the US, helping them adopt cloud technology to build scalable and secure solutions on AWS. Wayne Davis is an Enterprise Solutions Architect for Amazon Web Services. Over the last 24 months he has been helping customers to come up to speed on cloud technologies as fast as possible.
Wayne Davis is an Enterprise Solutions Architect for Amazon Web Services. Over the last 24 months he has been helping customers to come up to speed on cloud technologies as fast as possible. Robert Meagher is a software development engineer for AWS RoboMaker. He enjoys designing and tinkering with robotics systems, both in and out of the office.
Robert Meagher is a software development engineer for AWS RoboMaker. He enjoys designing and tinkering with robotics systems, both in and out of the office.





 Sheeraz Ahmad is an applied scientist in the AWS AI Lab. He received his PhD from University of California, San Diego working at the intersection of machine learning and cognitive science, where he built computational models of how biological agents learn and make decisions. At Amazon, he works on improving the quality of crowdsourced data. In his spare time, Sheeraz loves to play board games, read science fiction, and lift weights.
Sheeraz Ahmad is an applied scientist in the AWS AI Lab. He received his PhD from University of California, San Diego working at the intersection of machine learning and cognitive science, where he built computational models of how biological agents learn and make decisions. At Amazon, he works on improving the quality of crowdsourced data. In his spare time, Sheeraz loves to play board games, read science fiction, and lift weights. Lauren Moos is a software engineer with AWS AI. At Amazon, she has worked on a broad variety of machine learning problems, including machine learning algorithms for streaming data, consolidation of human annotations, and computer vision. Her primary interest is in machine learning’s relationship with cognitive science and modern philosophy. In her free time she reads, drinks coffee, and does yoga.
Lauren Moos is a software engineer with AWS AI. At Amazon, she has worked on a broad variety of machine learning problems, including machine learning algorithms for streaming data, consolidation of human annotations, and computer vision. Her primary interest is in machine learning’s relationship with cognitive science and modern philosophy. In her free time she reads, drinks coffee, and does yoga.