Over the last three years, DeepMind has built a team to tackle some of healthcare’s most complex problems—developing AI research and mobile tools that are already having a positive impact on patients and care teams. Today, with our healthcare partners, the team is excited to officially join the Google Health family. Under the leadership of Dr. David Feinberg, and alongside other teams at Google, we’ll now be able to tap into global expertise in areas like app development, data security, cloud storage and user-centered design to build products that support care teams and improve patient outcomes.
During my time working in the UK National Health Service (NHS) as a surgeon and researcher, I saw first-hand how technology could help, or hinder, the important work of nurses and doctors. It’s remarkable that many frontline clinicians, even in the world’s most advanced hospitals, are still reliant on clunky desktop systems and pagers that make delivering fast and safe patient care challenging. Thousands of people die in hospitals every year from avoidable conditions like sepsis and acute kidney injury and we believe that better tools could save lives. That’s why I joined DeepMind, and why I will continue this work with Google Health.
We’ve already seen how our mobile medical assistant for clinicians is helping patients and the clinicians looking after them, and we are looking forward to continuing our partnerships with The Royal Free London NHS Foundation Trust, Imperial College Healthcare NHS Trust and Taunton and Somerset NHS Foundation Trust.
On the research side, we’ve seen major advances with Moorfields Eye Hospital NHS Foundation Trust in detecting eye disease from scans as accurately as experts; with University College London Hospitals NHS Foundation Trust on planning cancer radiotherapy treatment; and with the US Department of Veterans Affairs to predict patient deterioration up to 48 hours earlier than currently possible. We see enormous potential in continuing, and scaling, our work with all three partners in the coming years as part of Google Health.
It’s clear that a transition like this takes time. Health data is sensitive, and we gave proper time and care to make sure that we had the full consent and cooperation of our partners. This included giving them the time to ask questions and fully understand our plans and to choose whether to continue our partnerships. As has always been the case, our partners are in full control of all patient data and we will only use patient data to help improve care, under their oversight and instructions.
I know DeepMind is proud of our healthcare work to date. With the expertise and reach of Google behind us, we’ll now be able to develop tools and technology capable of helping millions of patients around the world.
Sella Nevo, Senior Software Engineer, Google Research, Tel Aviv
Several years ago, we identified flood forecasts as a unique opportunity to improve people’s lives, and began looking into how Google’s infrastructure and machine learning expertise can help in this field. Last year, we started our flood forecasting pilot in the Patna region, and since then we have expanded our flood forecasting coverage, as part of our larger AI for Social Good efforts. In this post, we discuss some of the technology and methodology behind this effort.
The Inundation Model A critical step in developing an accurate flood forecasting system is to develop inundation models, which use either a measurement or a forecast of the water level in a river as an input, and simulate the water behavior across the floodplain.
A 3D visualization of a hydraulic model simulating various river conditions.
This allows us to translate current or future river conditions, to highly spatially accurate risk maps – which tell us what areas will be flooded and what areas will be safe. Inundation models depend on four major components, each with its own challenges and innovations:
Real-time Water Level Measurements To run these models operationally, we need to know what is happening on the ground in real-time, and thus we rely on partnerships with the relevant government agencies to receive timely and accurate information. Our first governmental partner is the Indian Central Water Commission (CWC), which measures water levels hourly in over a thousand stream gauges across all of India, aggregates this data, and produces forecasts based on upstream measurements. The CWC provides these real-time river measurements and forecasts, which are then used as inputs for our models.
CWC employees measuring water level and discharge near Lucknow, India.
Elevation Map Creation Once we know how much water is in a river, it is critical that the models have a good map of the terrain. High-resolution digital elevation models (DEMs) are incredibly useful for a wide range of applications in the earth sciences, but are still difficult to acquire in most of the world, especially for flood forecasting. This is because meter-wide features of the ground conditions can create a critical difference in the resulting flooding (embankments are one exceptionally important example), but publicly accessible global DEMs have resolutions of tens of meters. To help address this challenge, we’ve developed a novel methodology to produce high resolution DEMs based on completely standard optical imagery.
We start with the large and varied collection of satellite images used in Google Maps. Correlating and aligning the images in large batches, we simultaneously optimize for satellite camera model corrections (for orientation errors, etc.) and for coarse terrain elevation. We then use the corrected camera models to create a depth map for each image. To make the elevation map, we optimally fuse the depth maps together at each location. Finally, we remove objects such as trees and bridges so that they don’t block water flow in our simulations. This can be done manually or by training convolutional neural networks that can identify where the terrain elevations need to be interpolated. The result is a roughly 1 meter DEM, which can be used to run hydraulic models.
Hydraulic Modeling Once we have both these inputs – the riverine measurements and forecasts, and the elevation map – we can begin the modeling itself, which can be divided into two main components. The first and most substantial component is the physics-based hydraulic model, which updates the location and velocity of the water through time based on (an approximated) computation of the laws of physics. Specifically, we’ve implemented a solver for the 2D form of the shallow-water Saint-Venant equations. These models are suitably accurate when given accurate inputs and run at high resolutions, but their computational complexity creates challenges – it is proportional to the cube of the resolution desired. That is, if you double the resolution, you’ll need roughly 8 times as much processing time. Since we’re committed to the high-resolution required for highly accurate forecasts, this can lead to unscalable computational costs, even for Google!
To help address this problem, we’ve created a unique implementation of our hydraulic model, optimized for Tensor Processing Units (TPUs). While TPUs were optimized for neural networks (rather than differential equation solvers like our hydraulic model), their highly parallelized nature leads to the performance per TPU core being 85x times faster than the performance per CPU core. For additional efficiency improvements, we’re also looking at using machine learning to replace some of the physics-based algorithmics, extending data-driven discretization to two-dimensional hydraulic models, so we can support even larger grids and cover even more people.
A snapshot of a TPU-based simulation of flooding in Goalpara, mid-event.
As mentioned earlier, the hydraulic model is only one component of our inundation forecasts. We’ve repeatedly found locations where our hydraulic models are not sufficiently accurate – whether that’s due to inaccuracies in the DEM, breaches in embankments, or unexpected water sources. Our goal is to find effective ways to reduce these errors. For this purpose, we added a predictive inundation model, based on historical measurements. Since 2014, the European Space Agency has been operating a satellite constellation named Sentinel-1 with C-band Synthetic-Aperture Radar (SAR) instruments. SAR imagery is great at identifying inundation, and can do so regardless of weather conditions and clouds. Based on this valuable data set, we correlate historical water level measurements with historical inundations, allowing us to identify consistent corrections to our hydraulic model. Based on the outputs of both components, we can estimate which disagreements are due to genuine ground condition changes, and which are due to modeling inaccuracies.
Flood warnings across Google’s interfaces.
Looking Forward We still have a lot to do to fully realize the benefits of our inundation models. First and foremost, we’re working hard to expand the coverage of our operational systems, both within India and to new countries. There’s also a lot more information we want to be able to provide in real time, including forecasted flood depth, temporal information and more. Additionally, we’re researching how to best convey this information to individuals to maximize clarity and encourage them to take the necessary protective actions.
Computationally, while the inundation model is a good tool for improving the spatial resolution (and therefore the accuracy and reliability) of existing flood forecasts, multiple governmental agencies and international organizations we’ve spoken to are concerned about areas that do not have access to effective flood forecasts at all, or whose forecasts don’t provide enough lead time for effective response. In parallel to our work on the inundation model, we’re working on some basic research into improved hydrologic models, which we hope will allow governments not only to produce more spatially accurate forecasts, but also achieve longer preparation time.
Hydrologic models accept as inputs things like precipitation, solar radiation, soil moisture and the like, and produce a forecast for the river discharge (among other things), days into the future. These models are traditionally implemented using a combination of conceptual models approximating different core processes such as snowmelt, surface runoff, evapotranspiration and more.
The core processes of a hydrologic model. Designed by Daniel Klotz, JKU Institute for Machine Learning.
These models also traditionally require a large amount of manual calibration, and tend to underperform in data scarce regions. We are exploring how multi-task learning can be used to address both of these problems — making hydrologic models both more scalable, and more accurate. In research collaboration with JKU Institute For Machine Learning group under Sepp Hochreiter on developing ML-based hydrologic models, Kratzert et al. show how LSTMs perform better than all benchmarked classic hydrologic models.
The distribution of NSE scores on basins across the United States for various models, showing the proposed EA-LSTM consistently outperforming a wide range of commonly used models.
Though this work is still in the basic research stage and not yet operational, we think it is an important first step, and hope it can already be useful for other researchers and hydrologists. It’s an incredible privilege to take part in the large eco-system of researchers, governments, and NGOs working to reduce the harms of flooding. We’re excited about the potential impact this type of research can provide, and look forward to where research in this field will go.
Acknowledgements There are many people who contributed to this large effort, and we’d like to highlight some of the key contributors: Aaron Yonas, Adi Mano, Ajai Tirumali, Avinatan Hassidim, Carla Bromberg, Damien Pierce, Gal Elidan, Guy Shalev, John Anderson, Karan Agarwal, Kartik Murthy, Manan Singhi, Mor Schlesinger, Ofir Reich, Oleg Zlydenko, Pete Giencke, Piyush Poddar, Ruha Devanesan, Slava Salasin, Varun Gulshan, Vova Anisimov, Yossi Matias, Yi-fan Chen, Yotam Gigi, Yusef Shafi, Zach Moshe and Zvika Ben-Haim.
what if you fed all the Joe Rogan lines from every single episode and trained an AI to speak like joe rogan idk I’m not a programmer just throwing out an idea
Great processors — and great hardware — won’t be enough to propel the AI revolution forward, Ian Buck, vice president and general manager of NVIDIA’s accelerated computing business, said Wednesday at the AI Hardware Summit.
“We’re bringing AI computing way down in cost, way up in capability and I fully expect this trend to continue not just as we advance hardware, but as we advance AI algorithms, AI software and AI applications to help drive the innovation in the industry,” Buck told an audience of hundreds of press, analysts, investors and entrepreneurs in Mountain View, Calif.
Buck — known for creating the CUDA computing platform that puts GPUs to work powering everything from supercomputing to next-generation AI — spoke at a showcase for some of the most iconic computers of Silicon Valley’s past at the Computer History Museum.
NVIDIA’s Ian Buck speaking Wednesday at the AI Hardware Summit, in Silicon Valley.
AI Training Is a Supercomputing Challenge
The industry now has to think bigger — much bigger — than the boxes that defined the industry’s past, Buck explained, weaving together software, hardware,and infrastructure designed to create supercomputer-class systems with the muscle to harness huge amounts of data.
Training, or creating new AIs able to tackle new tasks, is the ultimate HPC challenge – exposing every bottleneck in compute, networking, and storage, Buck said.
“Scaling AI training poses some hard challenges, not only do you have to build the fast GPU, but optimize for the full data center as the computer,” Buck said. “You have to build system interconnections, memory optimizations, network topology, numerics.”
That’s why NVIDIA is investing in a growing portfolio of data center software and infrastructure, from interconnect technologies such as NVLink and NVSwitch to NVIDIA Collective Communications Library, or NCCL, which optimizes the way data moves across vast systems.
From ResNet-50 to BERT
Kicking off his brisk, half-hour talk, Buck explained that GPU computing has long served the most demanding users — scientists, designers, artists, gamers. More recently that’s included AI. Initial AI applications focused on understanding images, a capability measured by benchmarks such as ResNet-50.
“Fast forward to today, with models like BERT and Megatron that understand human language – this goes way beyond computer vision but actually intelligence,” Buck said. “When I said something, what did I mean? This is a much more challenging problem, it’s really true intelligence that we’re trying to capture in the neural network.”
To help tackle such problems, NVIDIA yesterday announced the latest version of NVIDIA’s inference platform, TensorRT 6. On the T4 GPU, it runs BERT-Large, a model with super-human accuracy for language understanding tasks, in only 5.8 milliseconds, nearly half the 10 ms threshold for smooth interaction with humans. It’s just one part of our ongoing effort to accelerate the end-to-end pipeline.
Accelerating the Full Workflow
Inference tasks, or putting trained AI models to work, are diverse, and usually part of larger applications application that obeys Amdhahl’s Law — if you accelerate only one piece of the pipeline, for example matrix multipliers, you’ll still be limited by the rest of the processing steps.
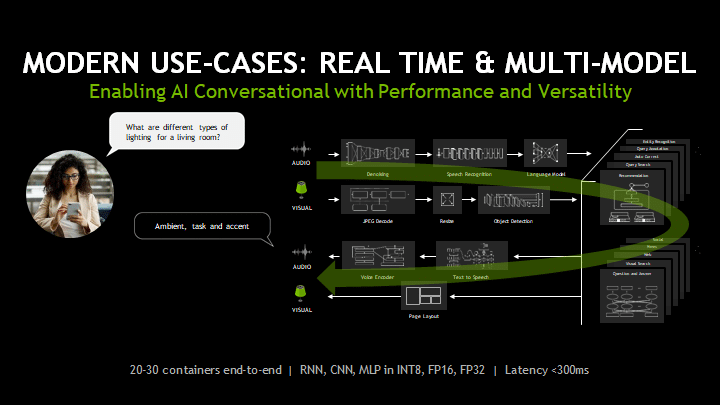
Making an AI that’s truly conversational will require a fully accelerated speech pipeline able to bounce from one crushingly compute-intensive task to another, Buck said.
Such a system could require 20 to 30 containers end to end, harnessing assorted convolutional neural networks and recurrent neural networks made up of multilayer perceptrons working at a mix of precisions, including INT8, FP16 and FP32. All at a latency of less than 300 milliseconds, leaving only 10 ms for a single model.
Data Center TCO Is Driven by Its Utilization
Such performance is vital as investments in data centers will be judged by the amount of utility that can be wrung from their infrastructures, Buck explained. “Total cost of ownership for the hyperscalers is all about utilization,” Buck said. ”NVIDIA having one architecture for all the AI powered use cases drives down the TCO.”
Performance — and flexibility — is why GPUs are already widely deployed in data centers today, Buck said. Consumer internet companies use GPUs to deliver voice search, image search, recommendations, home assistants, news feeds, translations and ecommerce.
Hyperscalers are adopting NVIDIA’s fast, power-efficient T4 GPUs — available on major cloud service providers such as Alibaba, Amazon, Baidu, Google Cloud and Tencent Cloud. And inference is now a double-digit percentage contributor to NVIDIA’s data center revenue.
Vertical Industries Require Vertical Platforms
In addition to delivering supercomputing-class computing power for training, and scalable systems for data centers serving hundreds of millions, AI platforms will need to grow increasingly specialized, Buck said.
Today AI research is concentrated in a handful of companies, but broader industry adoption needs verticalized platform, he continued.
“Who is going to do the work,” of building out all those applications? Buck asked. “We need to build domain-specific, verticalized AI platforms, giving them an SDK that gives them a platform that is already tuned for their use cases,” Buck said.
Buck highlighted how NVIDIA is building verticalized platforms for industries such as automotive, healthcare, robotics, smart cities, and 3D rendering, among others.
Zooming in on the auto industry as an example, Buck touched on a half dozen of the major technologies NVIDIA is developing. They include the NVIDIA Xavier system on a chip, NVIDIA Constellation automotive simulation software, NVIDIA DRIVE IX software for in-cockpit AI and NVIDIA DRIVE AV software to help vehicles safely navigate streets and highways.
Wrapping up, Buck offered a simple takeaway: the combination of AI hardware, AI software, and AI infrastructure promise to make more powerful AI available to more industries and, ultimately, more people
“We’re driving down the cost of computing AI, making it more accessible, allowing people to build powerful AI systems and I predict that cost reduction and improved capability will continue far into the future.”
Hey guys, I just started my Masters Program in AI and our prof threw an assignment at us: Find an IEEE paper and recreate the results… Okay.. I have 0 background in any of this stuff but here goes.
I’ve got one on NLP (with the code, but without the dataset) and I’m trying to scrape twitter data. I researched that there was a python script which allows you to do this, however it requires that you have Twitter Dev Permissions. I made a Dev request, made an App and got Consumer API Keys and Access Token Keys. However, my permissions are set as read and write only. If I want to scrape tweets (with certain #) is read and write enough access for me to export to a CSV file to later use to train the model?
I’ve posted on /r/MLQuestions but haven’t gotten a response there so I’m hoping I’ll have better luck here. Hope someone with more experience can shed some light on the topic.
If we can industrialise and monetise independent software creation, the possibilities seem endless. The applications for heuristic progress in machine learning could be huge. Thoughts?










{kind=link}