AI Goes to Washington: Top 5 Things to See at GTC DC
The center of the AI ecosystem shifts to D.C. this fall, when the GPU Technology Conference arrives at the Reagan Center in Washington, from Nov. 4-6.
GTC DC will bring together some 3,000 attendees from government and industry for three days of networking and more than 100 sessions, including presentations, panel talks and workshops focused on implementing AI in government and business.
Here are five of the top reasons to attend:
Keynote
Ian Buck, vice president of accelerated computing at NVIDIA, will be giving this year’s keynote at GTC DC.
This is a rare chance to receive concrete advice on how organizations can use AI to boost competitiveness and improve services from the man who invented CUDA, the world’s leading platform for accelerated parallel computing.
Buck has devoted his career to helping many of the world’s leading organizations accelerate critical compute workloads. He’s testified before Congress on AI and advised the White House.
100+ Sessions
Leading thinkers from the White House Office of Science and Technology, National Institute of Standards and Technology, NASA Langley Research Center, the Pacific Northwest National Laboratory and more will be discussing their technology and the future of AI in a series of over 100 sessions.
With a heavy focus on autonomous machines, cybersecurity and disaster relief, there will be panels on “The National AI Strategy: What’s Happening, What to Expect and How to Engage” and “AI and Cybersecurity: Opportunities and Threats to Businesses, Government and Individuals,” among others.
A few of the confirmed speakers include:
- Suzette Kent, U.S. chief information officer — U.S. Office of Management and Budget
- Lynne E. Parker, assistant director for AI — White House Office of Science and Technology Policy
- Gregg Cohen, CTO and staff scientist — National Institutes of Health
- Elham Tabassi, chief of staff in the Information Technology Laboratory — National Institute of Standards and Technology
- Kimberly Powell, vice president of healthcare — NVIDIA
- Sertac Karaman, associate professor of aeronautics and astronautics — MIT
- John Ferguson, CEO — Deepwave Digital
- Joshua Patterson, director of AI infrastructure — NVIDIA
- Moira Bergin, subcommittee director — U.S. House of Representatives Committee on Homeland Security
Exhibits
GTC DC won’t be all talk and no action, though — attendees will have access to demos of the latest innovations in AI. Over 50 companies will be exhibiting their technology in AI, robotics and high performance computing, including Booz Allen Hamilton, Lockheed Martin and Dell.

NVIDIA will demonstrate its RTX-powered lunar landing demo, which stole the show at SIGGRAPH earlier this year.
A celebration of the Apollo 11 moon landing, the demo uses a single camera to capture a participant’s movement and match it using AI pose estimation technology to a 3D-rendered astronaut in real time.
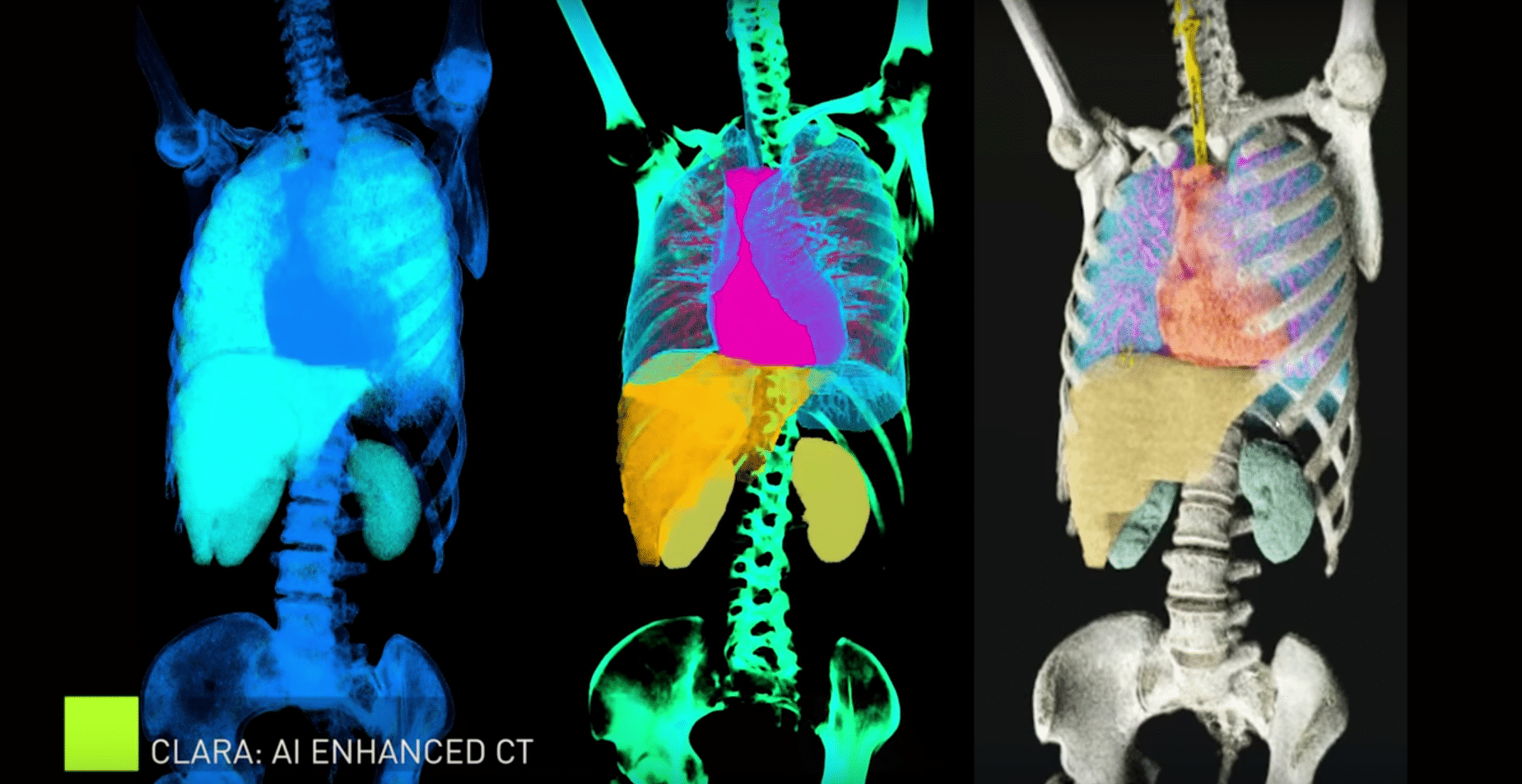
Also in the spotlight will be NVIDIA Clara AI, in a demo called “Enhancing Radiology with Cinematic Rendering and AI.” Clara uses NVIDIA GPUs and AI to enable views of the body that traditional medical imaging techniques cannot produce. These cinematic 3D renderings of medical images can transform the way we diagnose and recommend treatment.
Training
GTC DC is offering both AI beginners and experts the chance to work on their skills with seven day-long NVIDIA Deep Learning Institute workshops that will take place on Nov. 4. Led by certified DLI instructors, participants can earn a certificate of competency by completing the built-in assessment at the end of each session. Workshops include: “Getting Started with AI on Jetson Nano,” “Deep Learning for Intelligent Video Analytics” and “Deep Learning for Healthcare Image Analysis.”
There will also be dozens of two-hour hands-on training sessions throughout GTC DC. Instructors will train participants in the application of data science and accelerated computing to address the most difficult governmental and industrial challenges. Popular sessions available for registration are “Accelerating Data Science Workflows with RAPIDS” and “Introduction to CUDA Python with Numba.”
Networking
For many, the biggest benefit of GTC DC is being able to talk with a unique cross-section of technical experts, elected representatives, agency and department heads, staffers, corporate executives and academic leaders.
Attendees can engage with representatives from the White House, Department of Energy, Oak Ridge National Laboratory, Microsoft, Carnegie Mellon University, Amazon Web Services and many others in government, research and business.
The conference also hosts an annual Women in AI breakfast, bringing together women speakers from a variety of industries and research fields.
After hours, evening receptions offer attendees the chance to continue networking.
To see all of this and more, come join us at GTC DC from Nov. 4 to Nov. 6.
The post AI Goes to Washington: Top 5 Things to See at GTC DC appeared first on The Official NVIDIA Blog.