At AWS, I regularly speak with AWS customers and AWS Partner Network (APN) partners about how they are using technology to transform human health. These companies often generate large amounts of health data that they use in a variety of applications, such as population health management and electronic health records. Developers need to find ways to use the valuable medical information in these applications while meeting their compliance obligations with regard to sensitive data, such as protected health information (PHI). Some applications where our customers and APN partners are doing this today are clinical decision support, revenue cycle management, and clinical trial management.
There are multiple methods to mask data, and each organization has their own approaches based on internal risk assessments. We recommend that you consult risk assessment specialists for your organization’s specific implementation process. Typically, data is masked in two steps. First, PHI must be identified. Then, an algorithm is used that either anonymizes or de-identifies the data, usually in accordance with Safe Harbor or expert determination. This approach lends itself to using a state machine to apply the business logic your organization requires for each step independently and pass the information between states.
In this blog post, I’ll demonstrate how you can use a combination of Amazon Comprehend Medical, AWS Step Functions, and Amazon DynamoDB to identify sensitive health data and help support your compliance objectives. I’ll then discuss some potential extensions of the architecture that are patterns customers often adopt.
The architecture
This architecture uses the following services:
- Amazon Comprehend Medical to identify entities within a body of text
- AWS Step Functions and AWS Lambda to coordinate and execute the workflow
- Amazon DynamoDB to store the de-identified mapping
This architecture and the code that follows are available as an AWS CloudFormation template.

The individual components
Like many modern applications being built on AWS, the individual components within this architecture are represented as Lambda functions. In this blog post, I’ll show you how to build three Lambda functions:
- IdentifyPHI: Uses the Amazon Comprehend Medical API to detect and identify PHI entities from a body of text, such as a medical note.
- MaskEntities: Takes the entities from IdentifyPHI as input and masks them in the body of text
- DeidentifyEntities: Takes the entities from IdentifyPHI and applies a hash to each entity and stores that mapping in DynamoDB.
Let’s walk through each in turn.
Identify PHI
The following code reads in a JSON body, extracts PHI entities from the message, and returns a list of extracted entities.
from botocore.vendored import requests
import json
import boto3
import logging
import threading
client = boto3.client(service_name='comprehendmedical')
def timeout(event, context):
raise Exception('Execution is about to time out, exiting...')
def extract_entities_from_message(message):
return client.detect_phi(Text=message)
def handler(event, context):
# Add in context for Lambda to exit if needed
timer = threading.Timer((context.get_remaining_time_in_millis() / 1000.00) - 1, timeout, args=[event, context])
timer.start()
print ('Received message payload. Will extract PII')
try:
# Extract the message from the event
message = event['body']['message']
# Extract all entities from the message
entities_response = extract_entities_from_message(message)
entity_list = entities_response['Entities']
print ('PII entity extraction completed')
return entity_list
except Exception as e:
logging.error('Exception: %s. Unable to extract PII entities from message' % e)
raise e
The workhorse in this Lambda function is the Amazon Comprehend Medical DetectPHI API call, which returns a list of entities that Amazon Comprehend Medical identifies. Note that confidence scores are provided with each identified entity – these scores indicate the level of confidence in the accuracy of identified entities. You should take these confidence scores into account and review identified entities output to make sure they are correct. For more information on the returned data structure, see the DetectPHI documentation.
Mask entities
There are multiple approaches to masking a message. In this example, we take each entity and replace it with a series of pound signs (#) corresponding to the length of the entity. The output is the message that has been input with each entity masked. You could choose whichever methods that are most meaningful to and appropriate for your business. For example, if there are multiple NAME PHI entities, you could order them as NAME1, NAME2, and so on.
Here’s the Lambda function:
from botocore.vendored import requests
import json
import boto3
import logging
import threading
import sys
def timeout(event, context):
raise Exception('Execution is about to time out, exiting...')
def mask_entities_in_message(message, entity_list):
for entity in entity_list:
message = message.replace(entity['Text'], '#' * len(entity['Text']))
return message
def handler(event, context):
# Add in context for Lambda to exit if needed
timer = threading.Timer((context.get_remaining_time_in_millis() / 1000.00) - 1, timeout, args=[event, context])
timer.start()
print ('Received message payload')
try:
# Extract the entities and message from the event
message = event['body']['message']
entity_list = event['body']['entities']
# Mask entities
masked_message = mask_entities_in_message(message, entity_list)
print (masked_message)
return masked_message
except Exception as e:
logging.error('Exception: %s. Unable to extract entities from message' % e)
raise e
De-identify entities
There are multiple methods for de-identification. The example described in this blog post is meant to demonstrate one way you can de-identify sensitive entities so that they can be reidentified later on by a user with the appropriate permissions. Here, we do several steps:
- Apply a salt to the entity.
- For each entity, generate a sha3-256 hash of the salted entity. Store this entity in a dictionary.
- Replace each entity in the message with the hash generated in step 1.
- Generate a sha3-256 hash of the de-identified message.
- Store the entities in DynamoDB with the hashed message as the hash key and the entity hash as the range key.
Here is the Lambda function for this step. The EntityMap, which is a DynamoDB table, is read in as an environment variable:
from botocore.vendored import requests
import json
import boto3
import hashlib
import base64
import logging
import threading
import uuid
import os
ddb = boto3.client('dynamodb')
def timeout(event, context):
raise Exception('Execution is about to time out, exiting...')
def store_deidentified_message(message, entity_map, ddb_table):
hashed_message = hashlib.sha3_256(message.encode()).hexdigest()
for entity_hash in entity_map:
ddb.put_item(
TableName=ddb_table,
Item={
'MessageHash': {
'S': hashed_message
},
'EntityHash': {
'S': entity_hash
},
'Entity': {
'S': entity_map[entity_hash]
}
}
)
return hashed_message
def deidentify_entities_in_message(message, entity_list):
entity_map = dict()
for entity in entity_list:
salted_entity = entity['Text'] + str(uuid.uuid4())
hashkey = hashlib.sha3_256(salted_entity.encode()).hexdigest()
entity_map[hashkey] = entity['Text']
message = message.replace(entity['Text'], hashkey)
return message, entity_map
def handler(event, context):
# Add in context for Lambda to exit if needed
timer = threading.Timer((context.get_remaining_time_in_millis() / 1000.00) - 1, timeout, args=[event, context])
timer.start()
print ('Received message payload')
try:
# Extract the entities and message from the event
message = event['body']['message']
entity_list = event['body']['entities']
# Mask entities
deidentified_message, entity_map = deidentify_entities_in_message(message, entity_list)
hashed_message = store_deidentified_message(deidentified_message, entity_map, os.environ['EntityMap'])
return {
"deid_message": deidentified_message,
"hashed_message": hashed_message
}
except Exception as e:
logging.error('Exception: %s. Unable to extract entities from message' % e)
raise e
Building the Boto3 Lambda layer
Next, we’ll create a Lambda layer containing Boto3. This is a common best practice when deploying Lambda functions in production.
Copy and paste the following code into a terminal. Feel free to change boto3env to a folder of your choice. The following example uses Python 3.6.
pip install boto3 --target python/.
# install botocore
pip install botocore --target python/.
# zip to four layer
zip boto3layer.zip -r python/
aws lambda publish-layer-version --layer-name boto3-layer --zip-file fileb://boto3layer.zip
Note the LayerVersionArn in the output. We’ll use this shortly.
Building the state machine
The multiple steps within this workflow, such as data passed between steps and forking paths based on user input, can be best represented as a state machine. We’ll use AWS Step Functions to define the state machines and execute the individual Lambda functions.
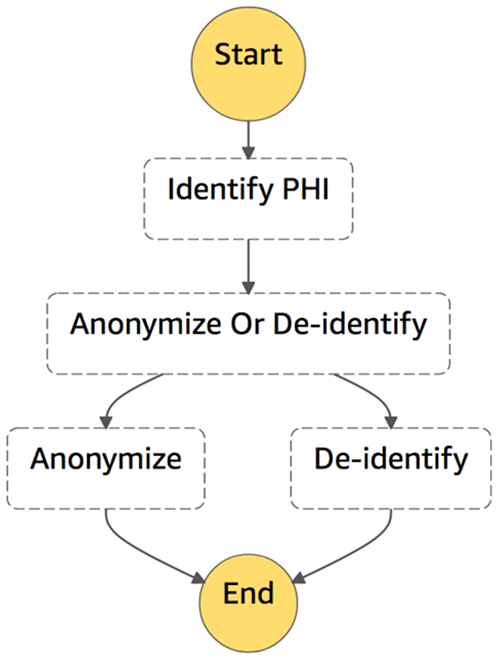
The state machine reads in a JSON blob containing the message text to process as well as whether to mask or de-identify the message. The overall steps are:
- Identify PHI entities using Amazon Comprehend Medical APIs.
- Determine whether to mask entities or de-identify.
- Based on results of Step 2, act accordingly.
Here is the Amazon States Language code defining this state machine:
{
"Comment": "State Machine that anonymizes or deidentifies PHI",
"StartAt": "Identify PHI",
"States": {
"Identify PHI": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:IdentifyPHILambda",
"InputPath": "$",
"ResultPath": "$.body.entities",
"Next": "Anonymize Or De-identify"
},
"Anonymize Or De-identify": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.body.anonymizeOrDeidentify",
"StringEquals": "anonymize",
"Next": "Anonymize"
},
{
"Variable": "$.body.anonymizeOrDeidentify",
"StringEquals": "deidentify",
"Next": "De-identify"
}
],
"Default": "Anonymize"
},
"Anonymize": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:MaskEntitiesLambda",
"InputPath": "$",
"ResultPath": "$.maskedMessage",
"OutputPath": "$.maskedMessage",
"End": true
},
"De-identify": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:DeidentifyLambda",
"InputPath": "$",
"ResultPath": "$.maskedMessage",
"OutputPath": "$.maskedMessage",
"End": true
}
}
}
Testing the state machine
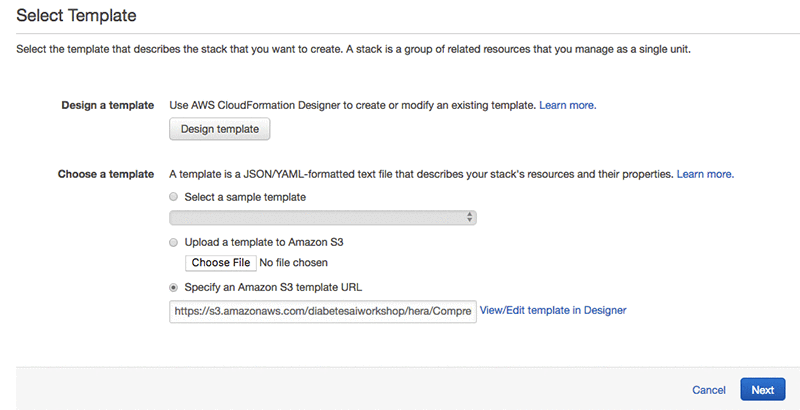
As mentioned in the introduction, you can deploy the entire architecture using AWS CloudFormation. Launch the CloudFormation template now:

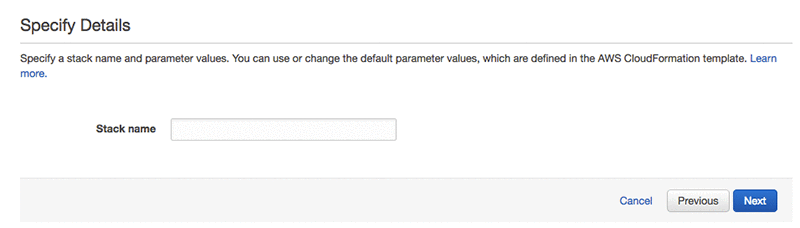
Use the LayerVersionArn output that you noticed previously in the Boto3LayerArn CloudFormation parameter.
After the CloudFormation stack deploys, you should have the following resources:
- The three Lambda functions
- A DynamoDB table containing mappings to the re-identified entities
- A Step Functions state machine
- AWS Identity and Access Management (IAM) resources
Let’s take a fictional medical note, or rather a combination of what would be several notes, which was provided by the Amazon Comprehend Medical team. Notice that it’s filled with typos, which would present challenges for rules-based approaches for entity identification.
Stay Free Medical Center
Emergency Department
Clinical Summary
12341 W. Bohannon Rd, Grantville, GA
Phone: (770) 922-9800
PERSON INFORMATION
Name: SALAZAR, CARLOS
MRN: RQ36114734
ED Arrival Time: 11/12/2011 18:15
Sex: Male
DOB: 2/11/1961
Age: 50 Years
Visit Reason: New onset A Fib, SOB
Acuity: 2 Emergent Disposition: Home/Self-Care
Address: 186 VALETINE, NE 69201
Phone: 402 213-2221
SUBJECTIVE:
Carlos came to the ED via ambulance accompanied by son, Jorge. He is a 50 yo male who was working at Food Corp when he had sudden onset of palpitations. Carlos stated his fater, Diego, also had palpitations through his life.
Provider Contact Time: 11/12/2011 19:00
Decision to Admit: Not entered
ED Departure Time: 11/23/2011 00:07
DIAGNOSIS: Hyperthyroidism
Attending Provider:
Saanvi Sarkar, MD
Primary Nurse(s):
Jackson; Mateo
Fill New Prescriptions:
nepafenac (nepafenac 1 mg / 1mL Ophthalmic Suspension) 1 drop left eye every 12 hours 14 day(s)
zofran (Ondansetron 4 mg oral tablet) 4 mg ORAL PRN
atropine sulfate 0.05 mcg / hyopscyamine sulfate 3.1 mcg / phenobartbital 48.6 MG / scopolamine hydrobromide 0.0195 mg ( Donnata ER oral tablet) 1 table PO PRN
acetaminophen – hydrocodone ( Vicodin 5 mg – 500 mg oral tablet ) 2 tablet(s) by Mouth every 6 hours as needed for pain
docusate sodium 100 mg oral capsule 100 mg by Mouth twice daily as needed for constipation
Allergies:
penicillins
ibuprofen
bee pollen
Patient Education and Follow-up Information
Instructions:
ED, Nausea (Custom)
Follow up:
With:
Address:
When:
Return to Emergency Department
Comments:
Nausea Vomiting
Nausea persists without control from anti-nausea medications Projectile vomiting Uncontrolled , consistent nausea & vomiting Blood or “coffee grounds” appearing material in vomit Medicine not kept down because of vomiting Weakness or dizziness along with nausea/vomiting Severe stomach pain while vomiting
Pain
Severe Chest / Arm pain Severe squeezing or pressure in chest Severe sudden headache
New or uncontrolled pain New headache Chest discomfort Pounding heart Heart “flip – flop” feeling Painful Central Line site or area of “tunnel” Burning in chest or stomach Pain or burning while urinating Pain with infusion of medications or fluids into Central Line
Diarrhea
Constant or uncontrolled diarrhea New onset diarrhea Diarrhea with fever and abdominal cramping Whole pills passed in stool Greater than 5 times each day Stool which is bloody , burgundy or black Abdominal cramping
Fatigue
Unable to wake
Dizziness Fatigue is getting worse Too tired to get out of bed or walk to the bathroom Staying in bed all day
Fever / Chills
Shaking chills , temperature may be normal Temperature greater than 38.3° C or 100.9° F by mouth Fever greater than 1 degree above usual if on steroids 24 Cold symptoms ( runny nose , watery eyes , sneezing , coughing )
With:
Address:
When:
Follow up with primary care provider
Comments:
Call tomorrow to make an appointment for the next 1-2 days and to start arranging PCP follow-up
Thank you for visiting the Stay Free Medical Center.
Comments:
Call tomorrow to make an appointment for the next 1-2 days and to start arranging PCP follow-up
Thank you for visiting the Stay Free Medical Center.
The input to the state machine takes two values. First, the note. Second, a choice of whether to anonymize the note or de-identify it. In this example we’ll de-identify the message. Here’s what that looks like:
{
"body": {
"message": " Stay Free Medical Center nEmergency Department nClinical Summary n12341 W. Bohannon Rd, Grantville, GAnPhone: (770) 922-9800 nnnPERSON INFORMATIONnName: SALAZAR, CARLOSnMRN: RQ36114734 nED Arrival Time: 11/12/2011 18:15n nSex: Male nDOB: 2/11/1961n Age: 50 Years nVisit Reason: New onset A Fib, SOBn Acuity: 2 Emergent Disposition: Home/Self-Care nAddress: 186 VALETINE, NE 69201nPhone: 402 213-2221 n nSUBJECTIVE:nCarlos came to the ED via ambulance accompanied by son, Jorge. He is a 50 yo male who was working at Food Corp when he had sudden onset of palpitations. Carlos stated his fater, Diego, also had palpitations through his life.n nProvider Contact Time: 11/12/2011 19:00n Decision to Admit: Not enteredn ED Departure Time: 11/23/2011 00:07n nDIAGNOSIS: Hyperthyroidism n Attending Provider: nSaanvi Sarkar, MDn n Primary Nurse(s): nJackson; Mateon nn Fill New Prescriptions:nnepafenac (nepafenac 1 mg / 1mL Ophthalmic Suspension) 1 drop left eye every 12 hours 14 day(s)nzofran (Ondansetron 4 mg oral tablet) 4 mg ORAL PRNnatropine sulfate 0.05 mcg / hyopscyamine sulfate 3.1 mcg / phenobartbital 48.6 MG / scopolamine hydrobromide 0.0195 mg ( Donnata ER oral tablet) 1 table PO PRNnacetaminophen - hydrocodone ( Vicodin 5 mg - 500 mg oral tablet ) 2 tablet(s) by Mouth every 6 hours as needed for painndocusate sodium 100 mg oral capsule 100 mg by Mouth twice daily as needed for constipationnn nAllergies:n penicillinsn ibuprofenn bee pollenn nPatient Education and Follow-up Informationn Instructions:n ED, Nausea (Custom) n Follow up:n n With:nAddress:nWhen:nnReturn to Emergency DepartmentnnnnComments:nnNausea VomitingnnNausea persists without control from anti-nausea medications Projectile vomiting Uncontrolled , consistent nausea & vomiting Blood or “coffee grounds” appearing material in vomit Medicine not kept down because of vomiting Weakness or dizziness along with nausea/vomiting Severe stomach pain while vomitingnnPain nSevere Chest / Arm pain Severe squeezing or pressure in chest Severe sudden headachenNew or uncontrolled pain New headache Chest discomfort Pounding heart Heart “flip - flop” feeling Painful Central Line site or area of “tunnel” Burning in chest or stomach Pain or burning while urinating Pain with infusion of medications or fluids into Central LinennnDiarrhea nnConstant or uncontrolled diarrhea New onset diarrhea Diarrhea with fever and abdominal cramping Whole pills passed in stool Greater than 5 times each day Stool which is bloody , burgundy or black Abdominal crampingnnFatiguenUnable to wakenDizziness Fatigue is getting worse Too tired to get out of bed or walk to the bathroom Staying in bed all daynnFever / Chills nnShaking chills , temperature may be normal Temperature greater than 38.3° C or 100.9° F by mouth Fever greater than 1 degree above usual if on steroids 24 Cold symptoms ( runny nose , watery eyes , sneezing , coughing ) nnnnWith:nAddress:nWhen:nnFollow up with primary care providernnnnComments:nnCall tomorrow to make an appointment for the next 1-2 days and to start arranging PCP follow-upnnnThank you for visiting the Stay Free Medical Center.n n",
"anonymizeOrDeidentify": "deidentify"
}
}
In the AWS CloudFormation console, navigate to the output page and note the state machine Amazon Resource Name (ARN), you will be using it later to invoke a state machine execution.
You can test using the AWS CLI, your AWS SDK of choice, or the AWS Step Functions console. The following command shows what it would be like if you used the CLI. However, before you type the following command, copy the previous JSON and save it to example_note.json. Also replace the AWS Step Functions state machine ARN with the ARN in the CloudFormation output.
aws stepfunctions start-execution --state-machine-arn YOUR_STATEMACHINE_ARN --input file://example_note.json
The overall execution should take only a couple of seconds. Let’s navigate to the AWS Step Functions console to see what happened.
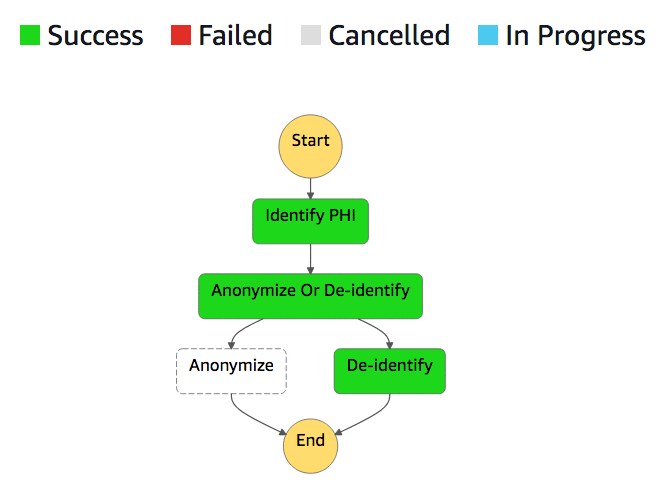
When you ran the previous command, several things happened.
- A Lambda function identified potential PHI entities within the note.
- These entities were salted and the resulting combination was hashed using SHA3-256.
- The hashes replaced the original entities in the message and the updated message was then hashed.
- The mappings were stored in DynamoDB.
- The hashed message is returned as the output of the execution.
You can view the output from the steps in the AWS Step Functions console. The previous message should now look like the following (formatted for ease of reading). The de-identified message still contains valuable information that can be used, but the sensitive data has been masked using the previous masking example.
8db49f8fdfc0a003402dd68439d2a848635d6c60a2719020c7b922916aafbdf0
c027ee7d7992ea804c589c2c2777fc646e2f394d5db900177246f9d7bd8d762d
Clinical Summary
5d0276605f49fa2c8e010b9781cb348d9efca84dd7a49e0ce6fb845e156f3331
Phone: 988c20b763f3b60b83aa64f48ce3184642dcf15707eeaead9d24c266e8967680
PERSON INFORMATION
Name: ba1a8b9ba885c1b867b0fda332845d2c4435a921cdbf849a86b4e5768b00972395cbf6c9eda8afecd3a8a454a28774512f78cd9d03ae7f2670433bc0217379
MRN: 45dd4310f18cddb1f37c4e11b36b12e77fc64001229a2632333d1e0f379f5847
2e0fbaa0c9008457c15f9306a9cd588ec09402f8db12194ec705b3f058e3eff6 Arrival Time: 712caefd59fd2015172ef9cb560dad2852c652368a618d446b472958db6a288b 18:15
Sex: Male
DOB: 88d76b85ad3e7cc2b1d06ea99a8a13df842fdd7ab0986ae3c747a3993944f91d
Age: b9ba885c1b867b0fda332845d2c4435a921cdbf849a86b4e5768b00972395cbf Years
Visit Reason: New onset A Fib, SOB
Acuity: 2 Emergent Disposition: Home/Self-Care
Address: aff3537058e53a9de01a4689cf1c3109584370e98ec31241a3ae4c07eceb0cbb
Phone: 35cda8ec6c456bdf120843e0a1302f0aef1bab003a51353a02fe41e56baa92f03a465fe2bac1c23d18cacdb3576a84aa5c0aeee3fb8aafb61bd18a6970610d
SUBJECTIVE:
1093369cc39bcae926a41719947e202ba749ff91691777321dcec52d34eb9296 came to the 2e0fbaa0c9008457c15f9306a9cd588ec09402f8db12194ec705b3f058e3eff6 via ambulance accompanied by son, abaefc3557e1c7577a16c658126d74cf8ae36857737c22eb587bc414bd926936. He is a b9ba885c1b867b0fda332845d2c4435a921cdbf849a86b4e5768b00972395cbf yo male who was working at f64136468ffae173d7eb43e4735e0bb9940d1718723dc0f42e0ffeb9053756cf when he had sudden onset of palpitations. 1093369cc39bcae926a41719947e202ba749ff91691777321dcec52d34eb9296 stated his fater, 23f255a3e4ec38a0fd094f3d96f30cb1a4787f269913aa890fb3a68058bd44fb, also had palpitations through his life.
Provider Contact Time: 712caefd59fd2015172ef9cb560dad2852c652368a618d446b472958db6a288b 19:00
Decision to Admit: Not entered
2e0fbaa0c9008457c15f9306a9cd588ec09402f8db12194ec705b3f058e3eff6 Departure Time: c078acc1b42e5eda560ec66cbabcddc16fde9ba0758ef73f095a11b87cda87b5 00:07
DIAGNOSIS: Hyperthyroidism
Attending Provider:
9437ca325df16c59a18c57c52194cc344ea3a3e4155a9b8decb7caf453b93c10, MD
Primary Nurse(s):
30ed768bd50007158ddd6ca6e71bc3e5d8bf411cb7597692c7aa729b53a13527
Fill New Prescriptions:
nepafenac (nepafenac 1 mg / 1mL Ophthalmic Suspension) 1 drop left eye every 12 hours 14 day(s)
zofran (Ondansetron 4 mg oral tablet) 4 mg ORAL PRN
atropine sulfate 0.05 mcg / hyopscyamine sulfate 3.1 mcg / phenobartbital 48.6 MG / scopolamine hydrobromide 0.0195 mg ( Donnata ER oral tablet) 1 table PO PRN
acetaminophen - hydrocodone ( Vicodin 5 mg - b9ba885c1b867b0fda332845d2c4435a921cdbf849a86b4e5768b00972395cbf0 mg oral tablet ) 2 tablet(s) by Mouth every 6 hours as needed for pain
docusate sodium 100 mg oral capsule 100 mg by Mouth twice daily as needed for constipation
Allergies:
penicillins
ibuprofen
bee pollen
Patient Education and Follow-up Information
Instructions:
2e0fbaa0c9008457c15f9306a9cd588ec09402f8db12194ec705b3f058e3eff6, Nausea (Custom)
Follow up:
With:
Address:
When:
Return to c027ee7d7992ea804c589c2c2777fc646e2f394d5db900177246f9d7bd8d762d
Comments:
Nausea Vomiting
Nausea persists without control from anti-nausea medications Projectile vomiting Uncontrolled , consistent nausea & vomiting Blood or “coffee grounds” appearing material in vomit Medicine not kept down because of vomiting Weakness or dizziness along with nausea/vomiting Severe stomach pain while vomiting
Pain
Severe Chest / Arm pain Severe squeezing or pressure in chest Severe sudden headache
New or uncontrolled pain New headache Chest discomfort Pounding heart Heart “flip - flop” feeling Painful Central Line site or area of “tunnel” Burning in chest or stomach Pain or burning while urinating Pain with infusion of medications or fluids into Central Line
Diarrhea
Constant or uncontrolled diarrhea New onset diarrhea Diarrhea with fever and abdominal cramping Whole pills passed in stool Greater than 5 times each day Stool which is bloody , burgundy or black Abdominal cramping
Fatigue
Unable to wake
Dizziness Fatigue is getting worse Too tired to get out of bed or walk to the bathroom Staying in bed all day
Fever / Chills
Shaking chills , temperature may be normal Temperature greater than 38.3° C or 100.9° F by mouth Fever greater than 1 degree above usual if on steroids 24 Cold symptoms ( runny nose , watery eyes , sneezing , coughing )
With:
Address:
When:
Follow up with primary care provider
Comments:
Call tomorrow to make an appointment for the next 1-2 days and to start arranging PCP follow-up
Thank you for visiting the 8db49f8fdfc0a003402dd68439d2a848635d6c60a2719020c7b922916aafbdf0.
Here’s what the table looks like after two runs with the same message.

Because each entity is salted, there’s no way of mapping that hash back to the original entity without using the DynamoDB mapping table, which you can notice by repeated entities having different hashes due to salting. Additionally, since you can manage DynamoDB access using IAM, you can control who has access to the items in your table. You can then use AWS CloudTrail to audit reads from your table containing sensitive information.
Conclusion and next steps
Protecting sensitive data is always job zero for healthcare organizations. In this blog post, I demonstrated how you can use Amazon Comprehend Medical to work with and identify protected health information. While organizations have different approaches to protect sensitive data, they follow the same architectural pattern: (1) identify the sensitive entities, and (2) apply the appropriate protection strategy for the sensitive entities as defined by your organization. A state machine is well-suited to orchestrate the two steps.
There are additional modifications you can make to this architecture to suit your needs. Here are a few ideas:
- Put the state machine behind Amazon API Gateway to add an authorization layer to process your text, as well as a gateway to the individual Lambda functions.
- Filter by the confidence of the DetectPHI call. Amazon Comprehend Medical entities have a
Score field in addition to Text. You can apply a threshold to filter the calls by, depending on your business requirements.
- Use DetectPHI in conjunction with DetectEntities to help you detect and identify PHI, and also extract non-PHI entity relationships, which can be used for downstream analytics.
Interested in learning more about Amazon Comprehend Medical?
- Check out the documentation
- Explore related blog posts discussing Amazon Comprehend Medical
Coming to HIMSS? Meet the AWS Healthcare team live at HIMSS19 Booth #5058!
We welcome your questions and comments. We look forward to hearing from you!
About the Author
 Dr. Aaron Friedman is a Healthcare and Life Sciences Partner Solutions Architect at Amazon Web Services. He works with ISVs and SIs to architect healthcare solutions on AWS, and bring the best possible experience to their customers. His passion is working at the intersection of science, big data, and software. In his spare time, he’s exploring the outdoors, learning a new thing to cook, or spending time with his wife, son, and his dog, Macaroon.
Dr. Aaron Friedman is a Healthcare and Life Sciences Partner Solutions Architect at Amazon Web Services. He works with ISVs and SIs to architect healthcare solutions on AWS, and bring the best possible experience to their customers. His passion is working at the intersection of science, big data, and software. In his spare time, he’s exploring the outdoors, learning a new thing to cook, or spending time with his wife, son, and his dog, Macaroon.






 Priya Ponnapalli is a principal data scientist at Amazon ML Solutions Lab, where she helps AWS customers across different industries accelerate their AI and cloud adoption.
Priya Ponnapalli is a principal data scientist at Amazon ML Solutions Lab, where she helps AWS customers across different industries accelerate their AI and cloud adoption.


 Dominic Divakaruni is the Product Manager for Amazon Elastic Inference. He builds services that help customers scale production machine learning applications. In this spare time he enjoys drumming with his son and working on cars.
Dominic Divakaruni is the Product Manager for Amazon Elastic Inference. He builds services that help customers scale production machine learning applications. In this spare time he enjoys drumming with his son and working on cars. Sukwon Kim is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to use deep learning engines. In his spare time, he enjoys hiking and traveling.
Sukwon Kim is a Senior Product Manager for AWS Deep Learning. He works on products that make it easier for customers to use deep learning engines. In his spare time, he enjoys hiking and traveling. Vin Sharma is a Engineering Leader for AWS Deep Learning. He leads the team building Neo, which helps ML models train once and run anywhere in the cloud and at the edge.
Vin Sharma is a Engineering Leader for AWS Deep Learning. He leads the team building Neo, which helps ML models train once and run anywhere in the cloud and at the edge.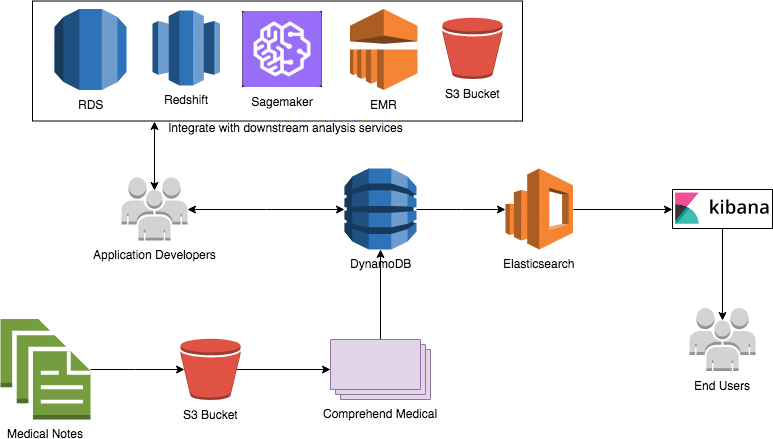

















 Ujjwal Is a Principal Machine Learning Specialist Solution Architect in the Global Healthcare and Lifesciences team at Amazon Web Services. He works on the application of machine learning and deep learning to real world industry problems like medical imaging, unstructured clinical text, genomics, precision medicine, clinical trials and quality of care improvement. He has expertise in scaling machine learning/deep learning algorithms on the AWS cloud for accelerated training and inference. In his free time, he enjoys listening to (and playing) music and taking unplanned road trips with his family.
Ujjwal Is a Principal Machine Learning Specialist Solution Architect in the Global Healthcare and Lifesciences team at Amazon Web Services. He works on the application of machine learning and deep learning to real world industry problems like medical imaging, unstructured clinical text, genomics, precision medicine, clinical trials and quality of care improvement. He has expertise in scaling machine learning/deep learning algorithms on the AWS cloud for accelerated training and inference. In his free time, he enjoys listening to (and playing) music and taking unplanned road trips with his family.