Transformer-XL: Unleashing the Potential of Attention Models
To correctly understand an article, sometimes one will need to refer to a word or a sentence that occurs a few thousand words back. This is an example of long-range dependence — a common phenomenon found in sequential data — that must be understood in order to handle many real-world tasks. While people do this naturally, modeling long-term dependency with neural networks remains a challenge. Gating-based RNNs and the gradient clipping technique improve the ability of modeling long-term dependency, but are still not sufficient to fully address this issue.
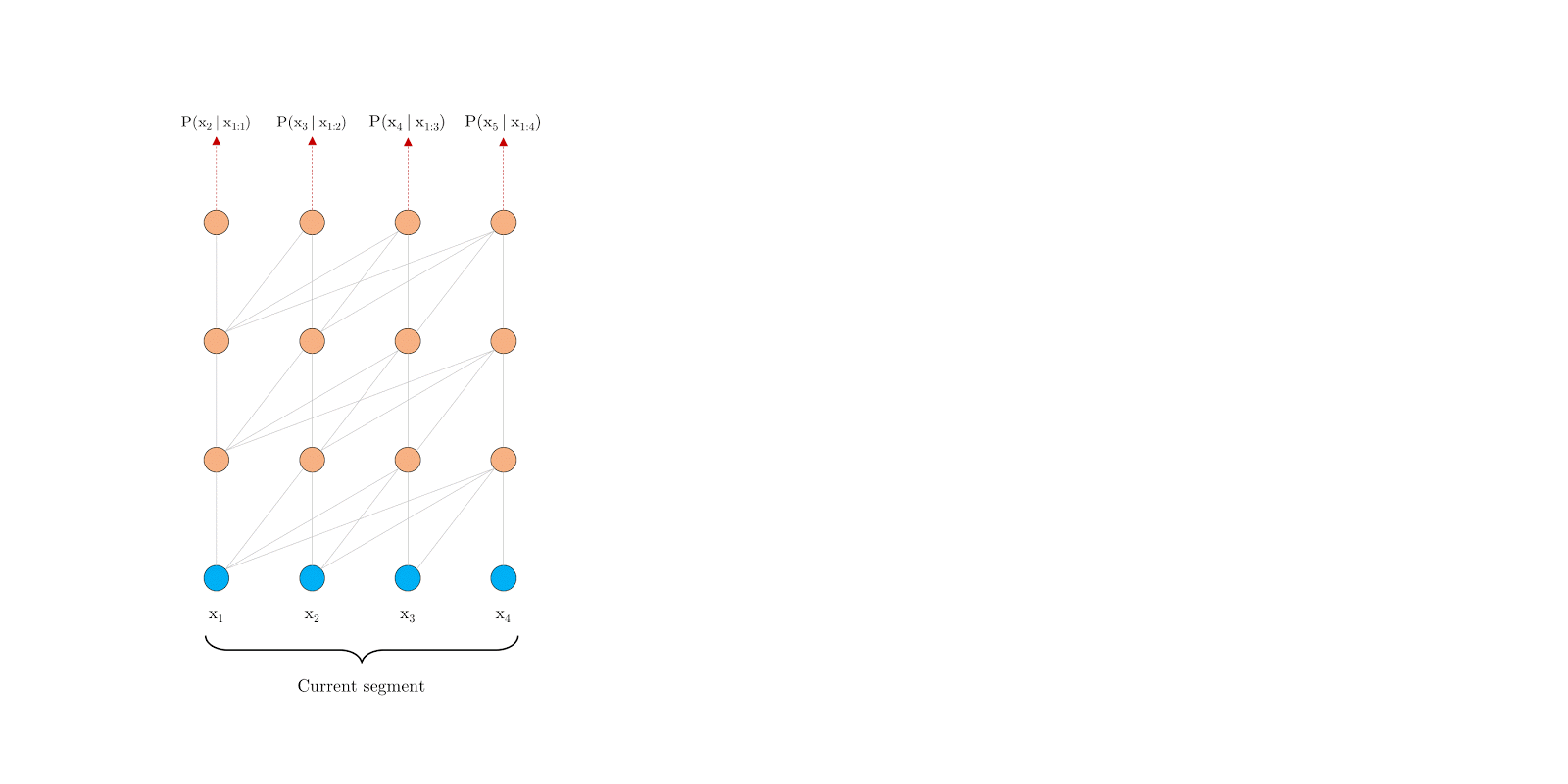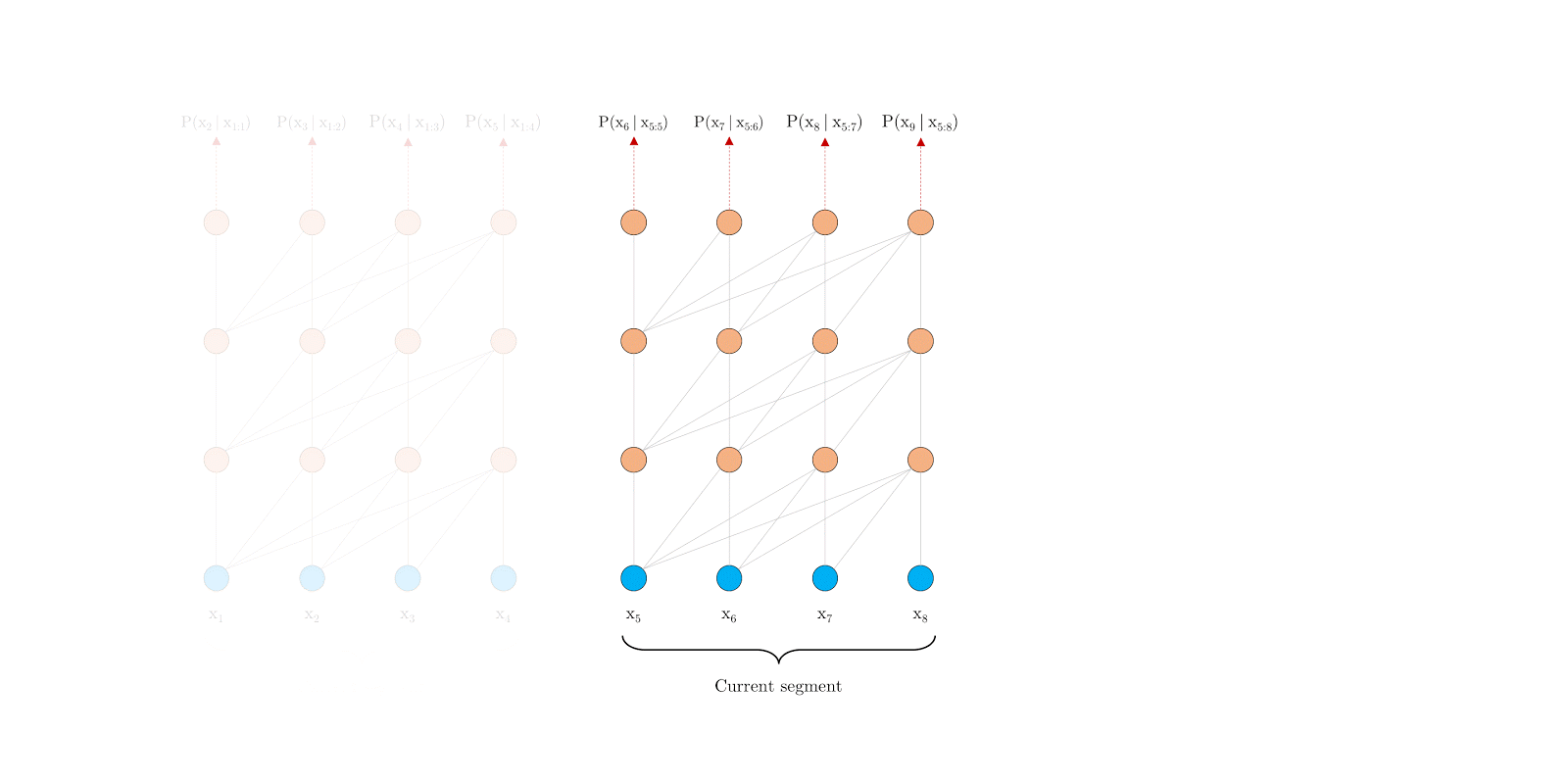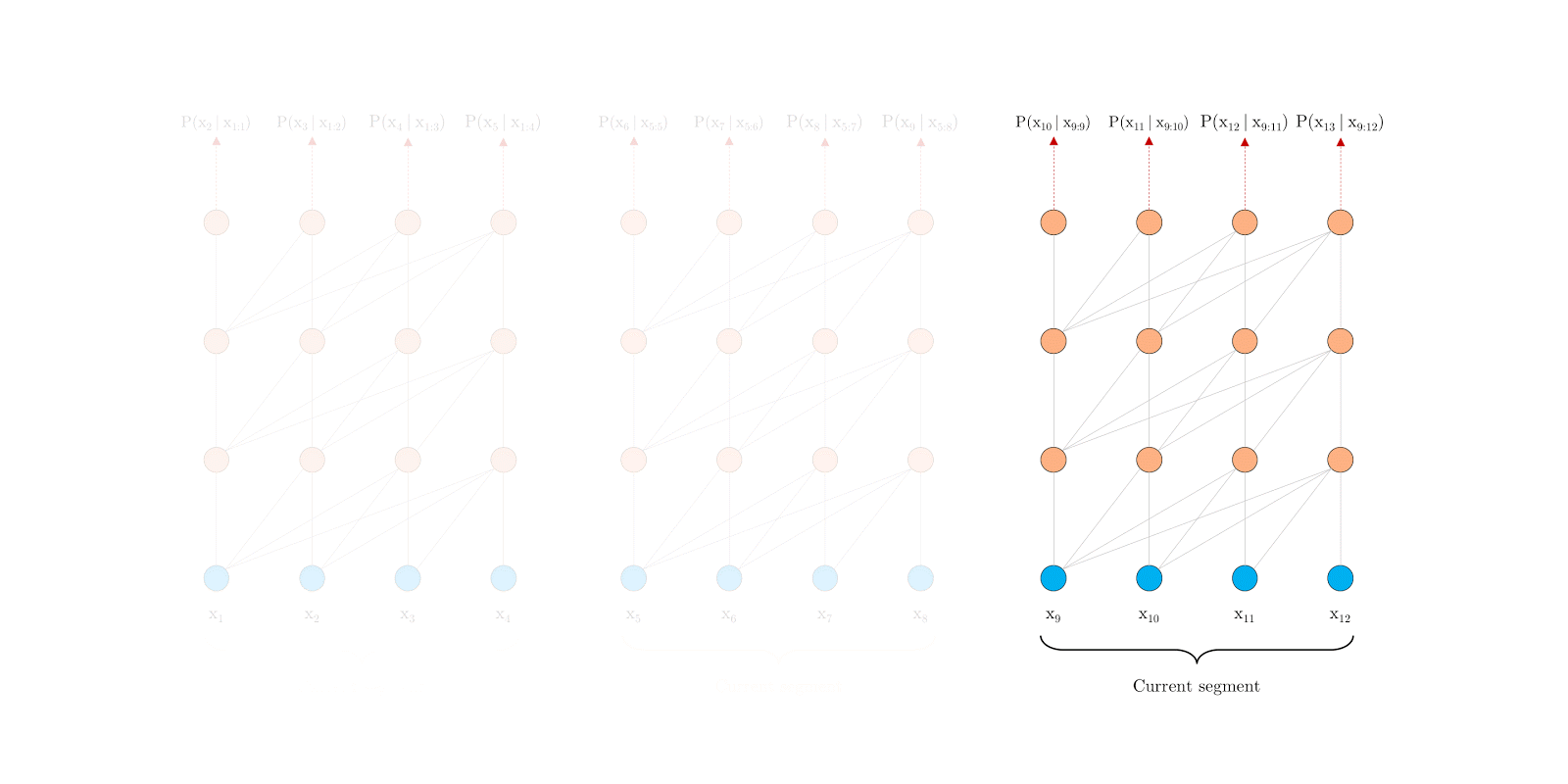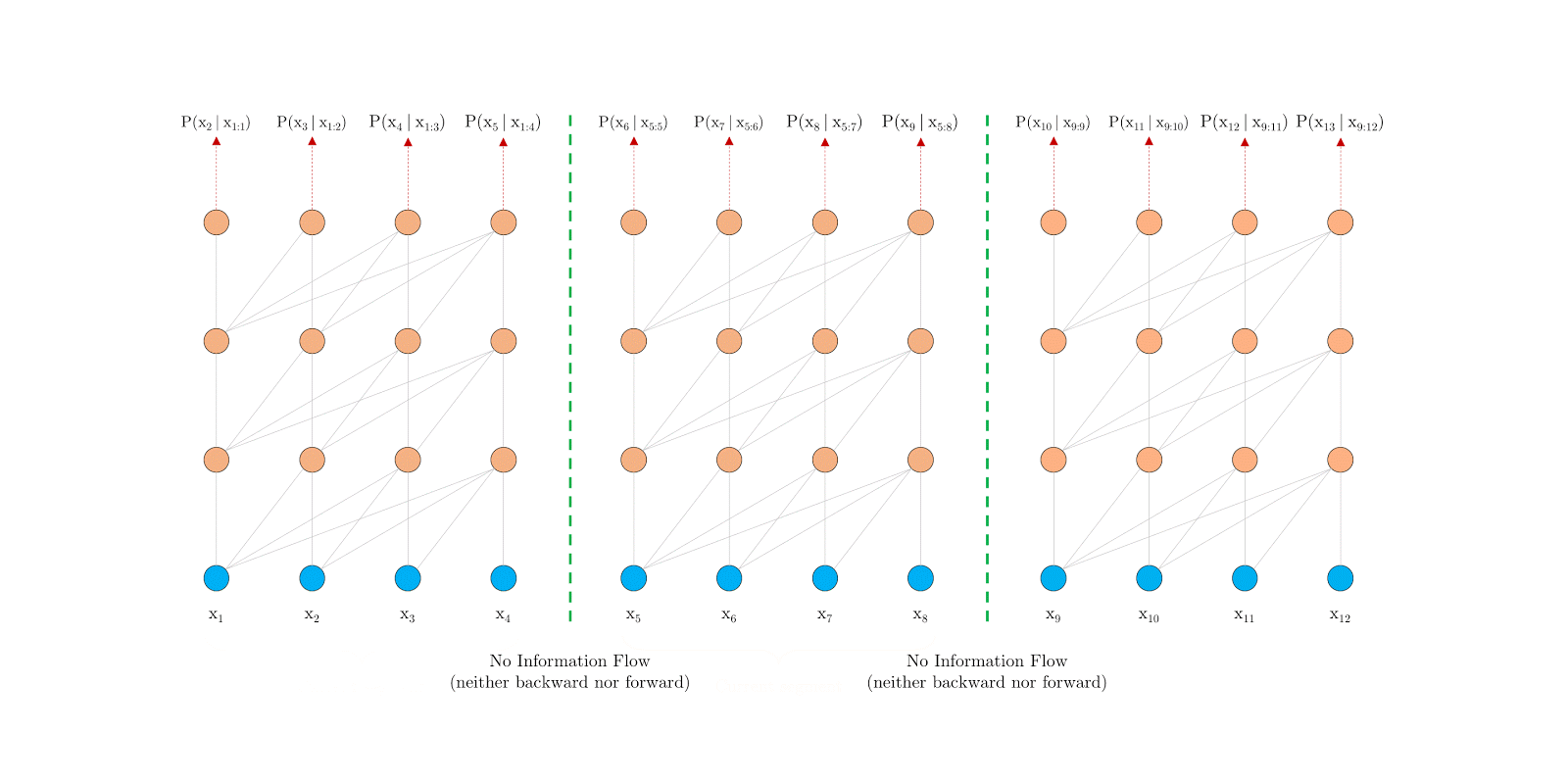
One way to approach this challenge is to use Transformers, which allows direct connections between data units, offering the promise of better capturing long-term dependency. However, in language modeling, Transformers are currently implemented with a fixed-length context, i.e. a long text sequence is truncated into fixed-length segments of a few hundred characters, and each segment is processed separately.
 |
| Vanilla Transformer with a fixed-length context at training time. |
This introduces two critical limitations:
- The algorithm is not able to model dependencies that are longer than a fixed length.
- The segments usually do not respect the sentence boundaries, resulting in context fragmentation which leads to inefficient optimization. This is particularly troublesome even for short sequences, where long range dependency isn’t an issue.
To address these limitations, we propose Transformer-XL a novel architecture that enables natural language understanding beyond a fixed-length context. Transformer-XL consists of two techniques: a segment-level recurrence mechanism and a relative positional encoding scheme.
Segment-level Recurrence
During training, the representations computed for the previous segment are fixed and cached to be reused as an extended context when the model processes the next new segment. This additional connection increases the largest possible dependency length by N times, where N is the depth of the network, because contextual information is now able to flow across segment boundaries. Moreover, this recurrence mechanism also resolves the context fragmentation issue, providing necessary context for tokens in the front of a new segment.
 |
| Transformer-XL with segment-level recurrence at training time. |
Relative Positional Encodings
Naively applying segment-level recurrence does not work, however, because the positional encodings are not coherent when we reuse the previous segments. For example, consider an old segment with contextual positions [0, 1, 2, 3]. When a new segment is processed, we have positions [0, 1, 2, 3, 0, 1, 2, 3] for the two segments combined, where the semantics of each position id is incoherent through out the sequence. To this end, we propose a novel relative positional encoding scheme to make the recurrence mechanism possible. Moreover, different from other relative positional encoding schemes, our formulation uses fixed embeddings with learnable transformations instead of learnable embeddings, and thus is more generalizable to longer sequences at test time. When both of these approaches are combined, Transformer-XL has a much longer effective context than a vanilla Transformer model at evaluation time.
 |
| Vanilla Transformer with a fixed-length context at evaluation time. |
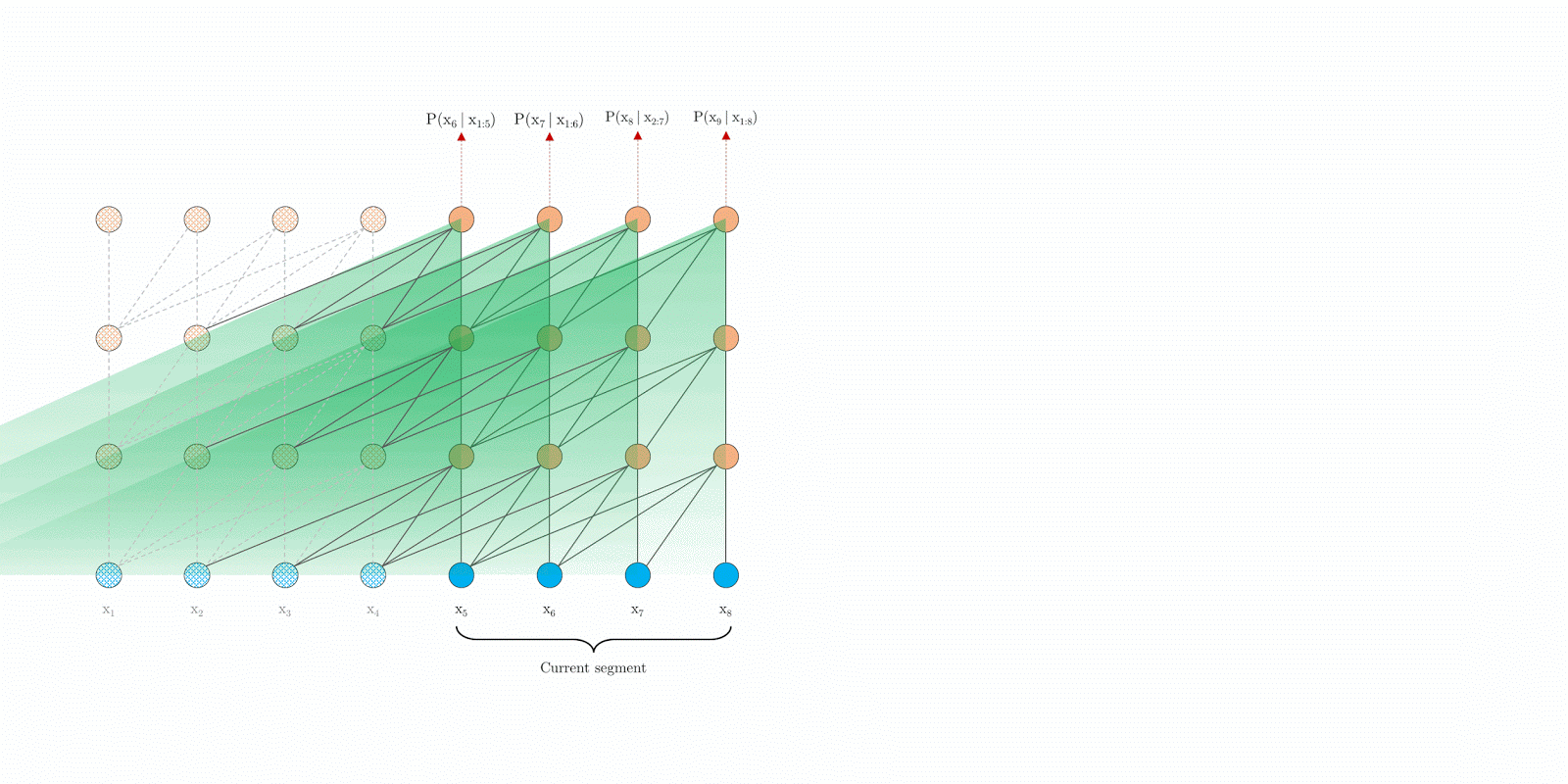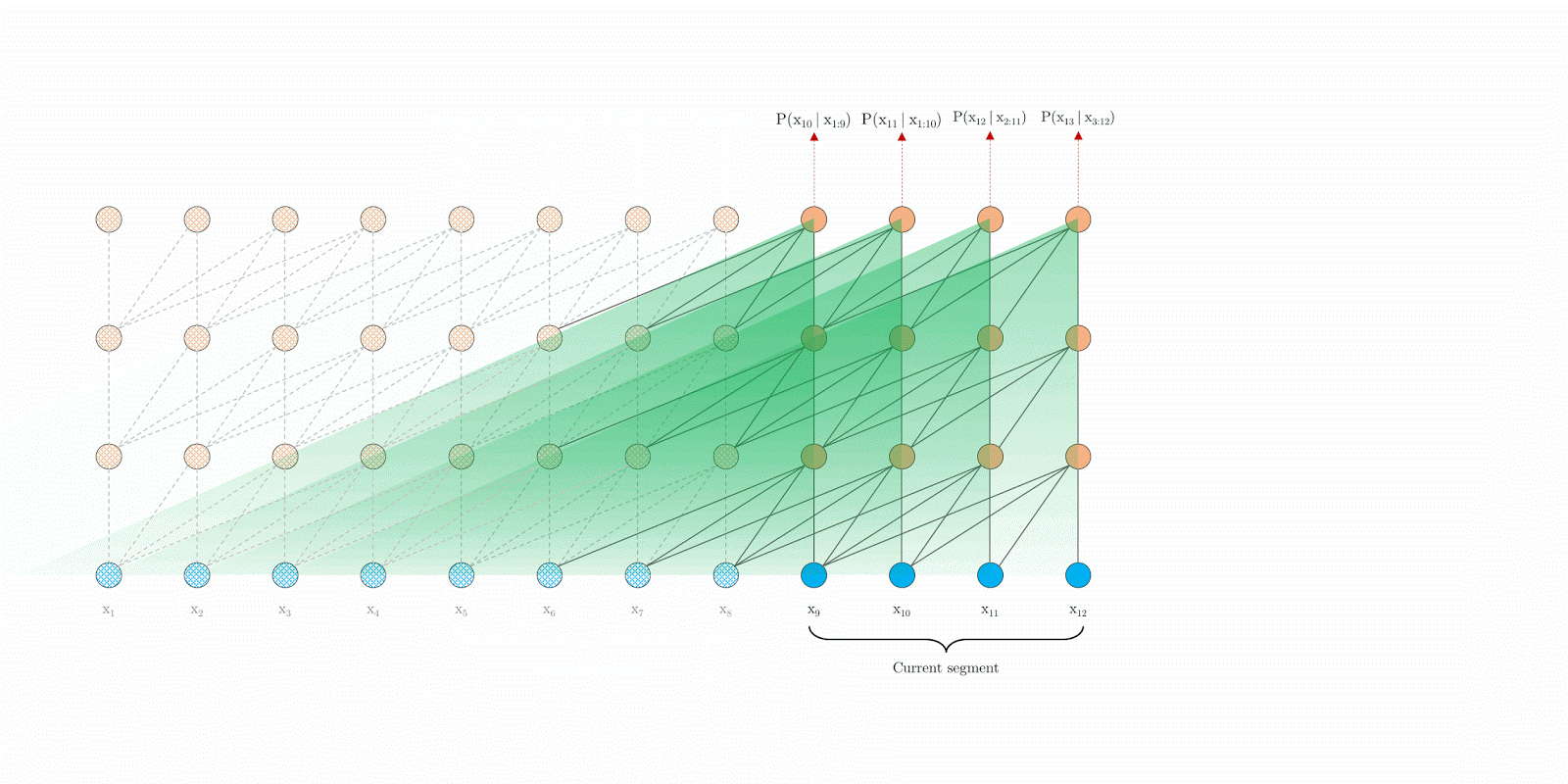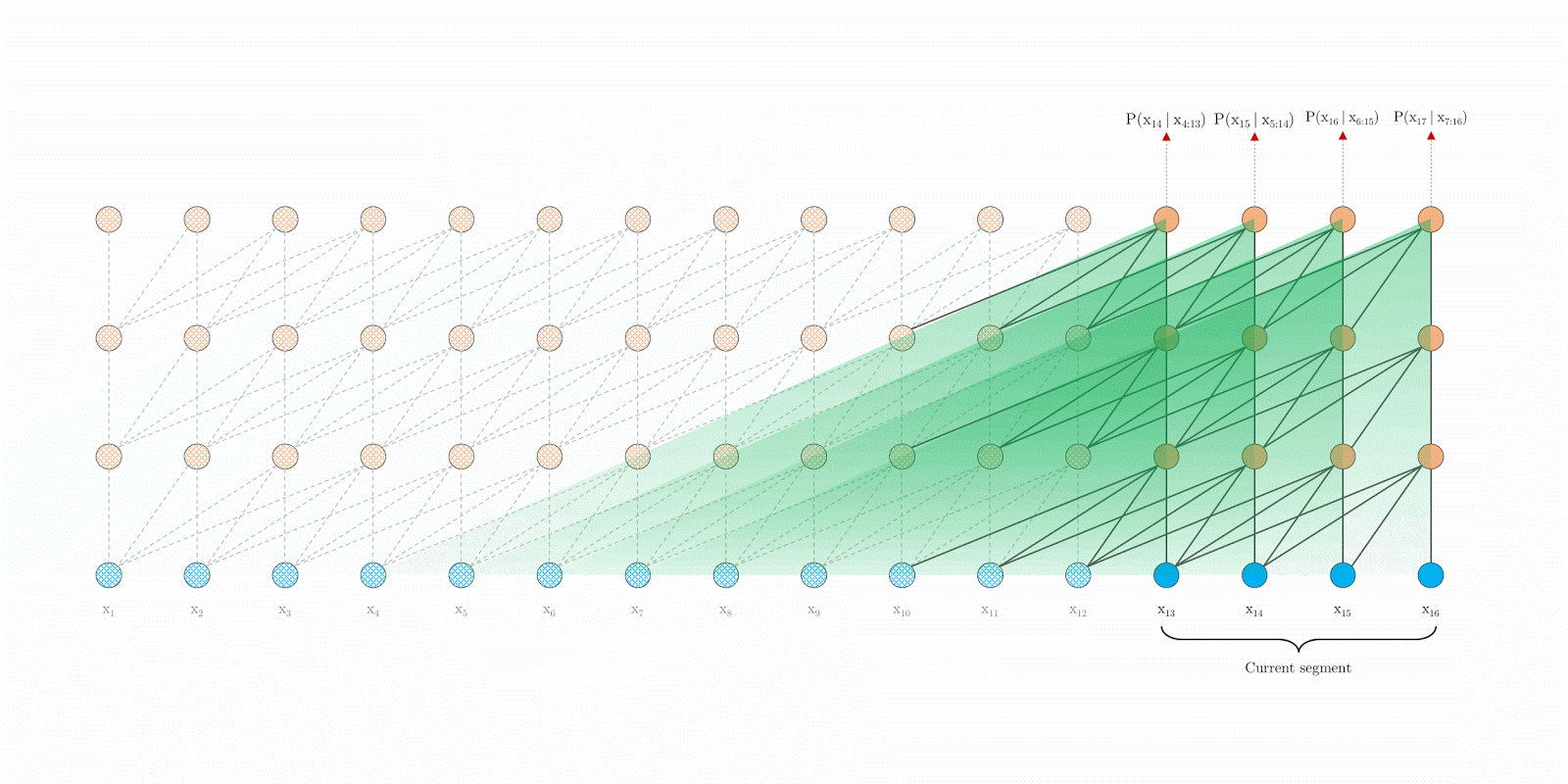 |
| Transformer-XL with segment-level recurrence at evaluation time./td> |
Furthermore, Transformer-XL is able to process the elements in a new segment all together without recomputation, leading to a significant speed increase (discussed below).
Results
Transformer-XL obtains new state-of-the-art (SoTA) results on a variety of major language modeling (LM) benchmarks, including character-level and word-level tasks on both long and short sequences. Empirically, Transformer-XL enjoys three benefits:
- Transformer-XL learns dependency that is about 80% longer than RNNs and 450% longer than vanilla Transformers, which generally have better performance than RNNs, but are not the best for long-range dependency modeling due to fixed-length contexts (please see our paper for details).
- Transformer-XL is up to 1,800+ times faster than a vanilla Transformer during evaluation on language modeling tasks, because no re-computation is needed (see figures above).
- Transformer-XL has better performance in perplexity (more accurate at predicting a sample) on long sequences because of long-term dependency modeling, and also on short sequences by resolving the context fragmentation problem.
Transformer-XL improves the SoTA bpc/perplexity from 1.06 to 0.99 on enwiki8, from 1.13 to 1.08 on text8, from 20.5 to 18.3 on WikiText-103, from 23.7 to 21.8 on One Billion Word, and from 55.3 to 54.5 on Penn Treebank (without fine tuning). We are the first to break through the 1.0 barrier on char-level LM benchmarks.
We envision many exciting potential applications of Transformer-XL, including but not limited to improving language model pretraining methods such as BERT, generating realistic, long articles, and applications in the image and speech domains, which are also important areas in the world of long-term dependency. For more detail, please see our paper.
The code, pretrained models, and hyperparameters used in our paper are also available in both Tensorflow and PyTorch on GitHub.
