Machine learning (ML) workflows orchestrate and automate sequences of ML tasks by enabling data collection and transformation. This is followed by training, testing, and evaluating a ML model to achieve an outcome. For example, you might want to perform a query in Amazon Athena or aggregate and prepare data in AWS Glue before you train a model on Amazon SageMaker and deploy the model to production environment to make inference calls. Automating these tasks and orchestrating them across multiple services helps build repeatable, reproducible ML workflows. These workflows can be shared between data engineers and data scientists.
Introduction
ML workflows consist of tasks that are often cyclical and iterative to improve the accuracy of the model and achieve better results. We recently announced new integrations with Amazon SageMaker that allow you to build and manage these workflows:
- AWS Step Functions automates and orchestrates Amazon SageMaker related tasks in an end-to-end workflow. You can automate publishing datasets to Amazon S3, training an ML model on your data with Amazon SageMaker, and deploying your model for prediction. AWS Step Functions will monitor Amazon SageMaker and other jobs until they succeed or fail, and either transition to the next step of the workflow or retry the job. It includes built-in error handling, parameter passing, state management, and a visual console that lets you monitor your ML workflows as they run.
- Many customers currently use Apache Airflow, a popular open source framework for authoring, scheduling, and monitoring multi-stage workflows. With this integration, multiple Amazon SageMaker operators are available with Airflow, including model training, hyperparameter tuning, model deployment, and batch transform. This allows you to use the same orchestration tool to manage ML workflows with tasks running on Amazon SageMaker.
This blog post shows how you can build and manage ML workflows using Amazon Sagemaker and Apache Airflow. We’ll build a recommender system to predict a customer’s rating for a certain video based on the customer’s historical ratings of similar videos, as well as the behavior of other similar customers. We’ll use historical star ratings from over 2 million Amazon customers on over 160,000 digital videos. Details on this dataset can be found at its AWS Open Data page.
High-level solution
We’ll start by exploring the data, transforming the data, and training a model on the data. We’ll fit the ML model using an Amazon SageMaker managed training cluster. We’ll then deploy to an endpoint to perform batch predictions on the test data set. All of these tasks will be plugged into a workflow that can be orchestrated and automated through Apache Airflow integration with Amazon SageMaker.
The following diagram shows the ML workflow we’ll implement for building the recommender system.

The workflow performs the following tasks:
- Data pre-processing: Extract and pre-process data from Amazon S3 to prepare the training data.
- Prepare training data: To build the recommender system, we’ll use the Amazon SageMaker built-in algorithm, Factorization machines. The algorithm expects training data only in recordIO-protobuf format with Float32 tensors. In this task, pre-processed data will be transformed to RecordIO Protobuf format.
- Training the model:Train the Amazon SageMaker built-in factorization machine model with the training data and generate model artifacts. The training job will be launched by the Airflow Amazon SageMaker operator.
- Tune the model hyperparameters:A conditional/optional task to tune the hyperparameters of the factorization machine to find the best model. The hyperparameter tuning job will be launched by the Amazon SageMaker Airflow operator.
- Batch inference:Using the trained model, get inferences on the test dataset stored in Amazon S3 using the Airflow Amazon SageMaker operator.
Note: You can clone this GitHub repo for the scripts, templates and notebook referred to in this blog post.
Airflow concepts and setup
Before implementing the solution, let’s get familiar with Airflow concepts. If you are already familiar with Airflow concepts, skip to the Airflow Amazon SageMaker operators section.
Apache Airflow is an open-source tool for orchestrating workflows and data processing pipelines. Airflow allows you to configure, schedule, and monitor data pipelines programmatically in Python to define all the stages of the lifecycle of a typical workflow management.
Airflow nomenclature
- DAG (Directed Acyclic Graph): DAGs describe how to run a workflow by defining the pipeline in Python, that is configuration as code. Pipelines are designed as a directed acyclic graph by dividing a pipeline into tasks that can be executed independently. Then these tasks are combined logically as a graph.
- Operators: Operators are atomic components in a DAG describing a single task in the pipeline. They determine what gets done in that task when a DAG runs. Airflow provides operators for common tasks. It is extensible, so you can define custom operators. Airflow Amazon SageMaker operators are one of these custom operators contributed by AWS to integrate Airflow with Amazon SageMaker.
- Task: After an operator is instantiated, it’s referred to as a “task.”
- Task instance: A task instance represents a specific run of a task characterized by a DAG, a task, and a point in time.
- Scheduling: The DAGs and tasks can be run on demand or can be scheduled to be run at a certain frequency defined as a cron expression in the DAG.
Airflow architecture
The following diagram shows the typical components of Airflow architecture.
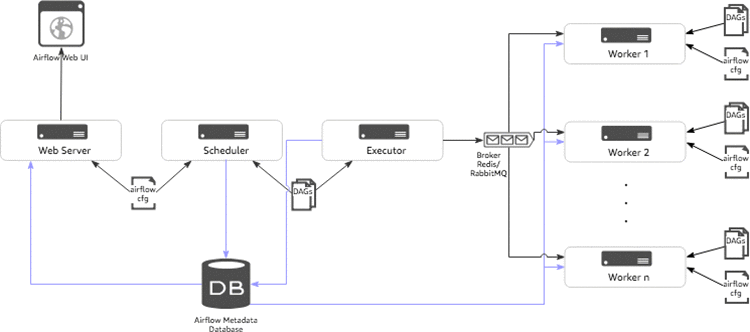
- Scheduler: The scheduler is a persistent service that monitors DAGs and tasks, and triggers the task instances whose dependencies have been met. The scheduler is responsible for invoking the executor defined in the Airflow configuration.
- Executor: Executors are the mechanism by which task instances get to run. Airflow by default provides different types of executors and you can define custom executors, such as a Kubernetes executor.
- Broker: The broker queues the messages (task requests to be executed) and acts as a communicator between the executor and the workers.
- Workers: The actual nodes where tasks are executed and that return the result of the task.
- Web server: A web server to render the Airflow UI.
- Configuration file: Configure settings such as executor to use, airflow metadata database connections, DAG, and repository location. You can also define concurrency and parallelism limits, etc.
- Metadata database: Database to store all the metadata related to the DAGS, DAG runs, tasks, variables, and connections.
Airflow Amazon SageMaker operators
Amazon SageMaker operators are custom operators available with Airflow installation allowing Airflow to talk to Amazon SageMaker and perform the following ML tasks:
- SageMakerTrainingOperator: Creates an Amazon SageMaker training job.
- SageMakerTuningOperator: Creates an AmazonSageMaker hyperparameter tuning job.
- SageMakerTransformOperator: Creates an Amazon SageMaker batch transform job.
- SageMakerModelOperator: Creates an Amazon SageMaker model.
- SageMakerEndpointConfigOperator: Creates an Amazon SageMaker endpoint config.
- SageMakerEndpointOperator: Creates an Amazon SageMaker endpoint to make inference calls.
We’ll review usage of the operators in the Building a machine learning workflow section of this blog post.
Airflow setup
We will set up a simple Airflow architecture with a scheduler, worker, and web server running on a single instance. Typically, you will not use this setup for production workloads. We will use AWS CloudFormation to launch the AWS services required to create the components in this blog post. The following diagram shows the configuration of the architecture to be deployed.

The stack includes the following:
- An Amazon Elastic Compute Cloud (EC2) instance to set up the Airflow components.
- An Amazon Relational Database Service (RDS) Postgres instance to host the Airflow metadata database.
- An Amazon Simple Storage Service (S3) bucket to store the Amazon SageMaker model artifacts, outputs, and Airflow DAG with ML workflow. The template will prompt for the S3 bucket name.
- AWS Identity and Access Management (IAM) roles and Amazon EC2 security groups to allow Airflow components to interact with the metadata database, S3 bucket, and Amazon SageMaker.
The prerequisite for running this CloudFormation script is to set up an Amazon EC2 Key Pair to log in to manage Airflow, for example, if you want to troubleshoot or add custom operators.

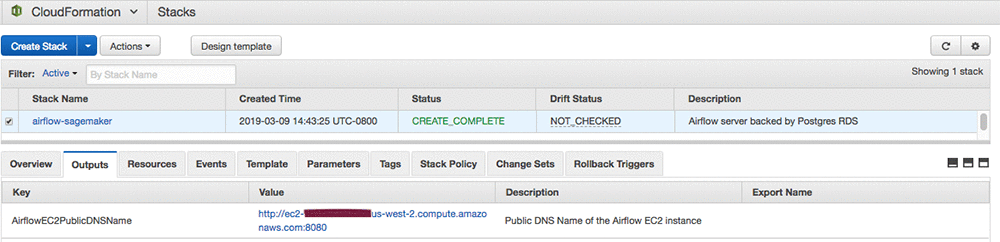
It might take up to 10 minutes for the CloudFormation stack to create the resources. After the resource creation is completed, you should be able to log in to Airflow web UI. The Airflow web server runs on port 8080 by default. To open the Airflow web UI, open any browser, and type in the http://ec2-public-dns-name:8080. The public DNS name of the EC2 instance can be found on the Outputs tab of CloudFormation stack on the AWS CloudFormation console.
Building a machine learning workflow
In this section, we’ll create a ML workflow using Airflow operators, including Amazon SageMaker operators to build the recommender. You can download the companion Jupyter notebook to look at individual tasks used in the ML workflow. We’ll highlight the most important pieces here.

Data preprocessing
- As mentioned earlier, the dataset contains ratings from over 2 million Amazon customers on over 160,000 digital videos. More details on the dataset are here.
- After analyzing the dataset, we see that there are only about 5 percent of customers who have rated 5 or more videos, and only 25 percent of videos have been rated by 9+ customers. We’ll clean this long tail by filtering the records.
- After cleanup, we transform the data into sparse format by giving each customer and video their own sequential index indicating the row and column in our ratings matrix. We store this cleansed data in an S3 bucket for the next task to pick up and process.
- The following
PythonOperator snippet in the Airflow DAG calls the preprocessing function:
# preprocess the data
preprocess_task = PythonOperator(
task_id='preprocessing',
dag=dag,
provide_context=False,
python_callable=preprocess.preprocess,
op_kwargs=config["preprocess_data"])
NOTE: For this blog post, the data preprocessing task is performed in Python using the Pandas package. The task gets executed on the Airflow worker node. This task can be replaced with the code running on AWS Glue or Amazon EMR when working with large data sets.
Data preparation
- We are using the Amazon SageMaker implementation of Factorization Machines (FM) for building the recommender system. The algorithm expects Float32 tensors in recordIO protobuf format. The cleansed data set is a Pandas DataFrame on disk.
- As part of data preparation, the Pandas DataFrame will be transformed to a sparse matrix with one-hot encoded feature vectors with customers and videos. Thus, each sample in the data set will be a wide Boolean vector with only two values set to 1 for the customer and the video.
| Cust 1 |
Cust 2 |
… |
Cust N |
Video 1 |
Video 2 |
… |
Video m |
| 1 |
0 |
… |
0 |
0 |
1 |
… |
0 |
- The following steps are performed in the data preparation task:
- Split the cleaned data set into train and test data sets.
- Build a sparse matrix with one-hot encoded feature vectors (customer + videos) and a label vector with star ratings.
- Convert both the sets to protobuf encoded files.
- Copy the prepared files to an Amazon S3 bucket for training the model.
- The following
PythonOperator snippet in the Airflow DAG calls the data preparation function.
# prepare the data for training
prepare_task = PythonOperator(
task_id='preparing',
dag=dag,
provide_context=False,
python_callable=prepare.prepare,
op_kwargs=config["prepare_data"]
)
Model training and tuning
- We’ll train the Amazon SageMaker Factorization Machine algorithm by launching a training job using Airflow Amazon SageMaker Operators. There are couple of ways we can train the model.
- Use
SageMakerTrainingOperator to run a training job by setting the hyperparameters known to work for your data.
# train_config specifies SageMaker training configuration
train_config = training_config(
estimator=fm_estimator,
inputs=config["train_model"]["inputs"])
# launch sagemaker training job and wait until it completes
train_model_task = SageMakerTrainingOperator(
task_id='model_training',
dag=dag,
config=train_config,
aws_conn_id='airflow-sagemaker',
wait_for_completion=True,
check_interval=30
)
- Use
SageMakerTuningOperator to run a hyperparameter tuning job to find the best model by running many jobs that test a range of hyperparameters on your dataset.
# create tuning config
tuner_config = tuning_config(
tuner=fm_tuner,
inputs=config["tune_model"]["inputs"])
tune_model_task = SageMakerTuningOperator(
task_id='model_tuning',
dag=dag,
config=tuner_config,
aws_conn_id='airflow-sagemaker',
wait_for_completion=True,
check_interval=30
)
- Conditional tasks can be created in the Airflow DAG that can decide whether to run the training job directly or run a hyperparameter tuning job to find the best model. These tasks can be run in synchronous or asynchronous mode.
branching = BranchPythonOperator(
task_id='branching',
dag=dag,
python_callable=lambda: "model_tuning" if hpo_enabled else "model_training")
- The progress of the training or tuning job can be monitored in the Airflow Task Instance logs.
Model inference
- Using the Airflow
SageMakerTransformOperator, create an Amazon SageMaker batch transform job to perform batch inference on the test dataset to evaluate performance of the model.
# create transform config
transform_config = transform_config_from_estimator(
estimator=fm_estimator,
task_id="model_tuning" if hpo_enabled else "model_training",
task_type="tuning" if hpo_enabled else "training",
**config["batch_transform"]["transform_config"]
)
# launch sagemaker batch transform job and wait until it completes
batch_transform_task = SageMakerTransformOperator(
task_id='predicting',
dag=dag,
config=transform_config,
aws_conn_id='airflow-sagemaker',
wait_for_completion=True,
check_interval=30,
trigger_rule=TriggerRule.ONE_SUCCESS
)
- We can further extend the ML workflow by adding a task to validate model performance by comparing the actual and predicted customer ratings before deploying the model in production environment.
In the next section, we’ll see how all these tasks are stitched together to form a ML workflow in an Airflow DAG.
Putting it all together
Airflow DAG integrates all the tasks we’ve described as a ML workflow. Airflow DAG is a Python script where you express individual tasks with Airflow operators, set task dependencies, and associate the tasks to the DAG to run on demand or at a scheduled interval. The Airflow DAG script is divided into following sections.
- Set DAG with parameters such as schedule interval, concurrency, etc.
dag = DAG(
dag_id='sagemaker-ml-pipeline',
default_args=args,
schedule_interval=None,
concurrency=1,
max_active_runs=1,
user_defined_filters={'tojson': lambda s: JSONEncoder().encode(s)}
)
- Set up training, tuning, and inference configurations for each operator using Amazon SageMaker Python SDK for Airflow
- Create individual tasks with Airflow operators that define trigger rules and associate them with the DAG object. Refer to the previous section for defining these individual tasks.
- Specify task dependencies.
init.set_downstream(preprocess_task)
preprocess_task.set_downstream(prepare_task)
prepare_task.set_downstream(branching)
branching.set_downstream(tune_model_task)
branching.set_downstream(train_model_task)
tune_model_task.set_downstream(batch_transform_task)
train_model_task.set_downstream(batch_transform_task)
batch_transform_task.set_downstream(cleanup_task)
After the DAG is ready, deploy it to the Airflow DAG repository using CI/CD pipelines. If you followed the setup outlined in Airflow setup, the CloudFormation stack deployed to install Airflow components will add the Airflow DAG to the repository on the Airflow instance that has the ML workflow for building the recommender system. Download the Airflow DAG code from here.

After triggering the DAG on demand or on a schedule, you can monitor the DAG in multiple ways: tree view, graph view, Gantt chart, task instance logs, etc. Refer to the Airflow documentation for ways to author and monitor Airflow DAGs.
Clean up
Now to the final step, cleaning up the resources.
To avoid unnecessary charges on your AWS account do the following:
- Destroy all of the resources created by the CloudFormation stack in Airflow set up by deleting the stack after you’re done experimenting with it. You can follow the steps here to delete the stack.
- You have to manually delete the S3 bucket created by the CloudFormation stack because AWS CloudFormation can’t delete a non-empty Amazon S3 bucket.
Conclusion
In this blog post, you have seen that building an ML workflow involves quite a bit of preparation but it helps improve the rate of experimentation, engineering productivity, and maintenance of repetitive ML tasks. Airflow Amazon SageMaker Operators provide a convenient way to build ML workflows and integrate with Amazon SageMaker.
You can extend the workflows by customizing the Airflow DAGs with any tasks that better fit your ML workflows, such as feature engineering, creating an ensemble of training models, creating parallel training jobs, and retraining models to adapt to the data distribution changes.
References
- Refer to the Amazon SageMaker SDK documentation and Airflow documentation for additional details on the Airflow Amazon SageMaker operators.
- Refer to the Amazon SageMaker documentation to learn about the Factorization Machines algorithm used in this blog post.
- Download the resources (Jupyter Notebooks, CloudFormation template, and Airflow DAG code) referred in this blog post from our GitHub repo.
If you have questions or suggestions, please leave them in the following comments section.
About the Author
 Rajesh Thallam is a Professional Services Architect for AWS helping customers run Big Data and Machine Learning workloads on AWS. In his spare time he enjoys spending time with family, traveling and exploring ways to integrate technology into daily life. He would like to thank his colleagues David Ping and Shreyas Subramanian for helping with this blog post.
Rajesh Thallam is a Professional Services Architect for AWS helping customers run Big Data and Machine Learning workloads on AWS. In his spare time he enjoys spending time with family, traveling and exploring ways to integrate technology into daily life. He would like to thank his colleagues David Ping and Shreyas Subramanian for helping with this blog post.







 Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.
Alexandra Bush is a Senior Product Marketing Manager for AWS AI. She is passionate about how technology impacts the world around us and enjoys being able to help make it accessible to all. Out of the office she loves to run, travel and stay active in the outdoors with family and friends.



